






PCA
数据降维
在进行数据挖掘或者机器学习时,我们面临的数据往往是高维数据。相较于低维数据,高维数据为我们提供了更多的信息和细节,也更好的描述了样本;但同时,很多高效且准确的分析方法也将无法使用。处理高维数据和高维数据可视化是数据科学家们必不可少的技能。解决这个问题的方法便是降低数据的维度。在数据降维时,要使用尽量少的维度来表达较多原数据的特性和结构。
PCA
主成分分析(Principal Component Analysis, PCA)是一种线性降维算法,也是一种常用的数据预处理(Pre-Processing)方法。它的目标是是用方差(Variance)来衡量数据的差异性,并将差异性较大的高维数据投影到低维空间中进行表示。绝大多数情况下,我们希望获得两个主成分因子:分别是从数据差异性最大和次大的方向提取出来的,称为PC1(Principal Component 1) 和 PC2(Principal Component 2)。
Scores.xlsx (文末获取文件链接) 包含了约70名学生的全科考试成绩。其中每名学生是一个独立的样本,每门学科的成绩都是一个数据维度(共有13门成绩)。我们的目的是通过分析学生的考试成绩来判断学生的类别(理科、文科生,和体育、艺术特长生)。

上图是在经过PCA降维处理后,得到的浮点图;图中每个点都代表了一名学生,其中文科生为绿色,理科生为红色,体育生和艺术生分别为黄色和蓝色。坐标系的X轴为PC1,Y轴为PC2。从图中我们可以明显地看出同类别学生的聚类(Clustering)趋势,也证明了PCA在降维的同时,尽可能地保留了原数据的特性。那么PCA具体是如何实现的?PC1和PC2又是如何计算的呢?
PCA的具体实现
举个简单的例子,下表为随机选取的六名学生的数学和语文考试成绩:

制作为散点图:

Step 1
图中每个点代表了一个学生,X轴代表语文成绩,Y轴代表数学成绩。然后分别取所有样本的X平均值和Y平均值,并将这两个值变为X、Y坐标,在图中画出这个点(用五角星表示):

Step 2
按照图中箭头所示方向,将整个坐标系平移,使原点与五角星重叠。这样就获得了一个新的平面直角坐标系。

Step 3
尽管此时坐标系和每个点的值都发生了变化,点与点之间的相对位置仍保持一致。找到这些点的最优拟合线(Line of Best Fit),也就找到了PC1,再通过原点做PC1的垂线,就找到了PC2:

Step 4
处理三维数组时便会产生第三个因子(PC3),以此类推,数据的维度越大,因子的数量也就越多。当维度大于等于4的时候,我们是无法想象出图像的,但PC4确实存在;假设有x个维度,便可以做x-1条垂线,就能得到PCx。接下来要做的便是选取最能代表数据差异性的两个因子,作为PC1和PC2。
按照下图所示,将点A投影到PC1上(六角星的位置),并计算其与原点之间的距离称为d1:

Projection
其余的五个点也做同样操作,得出d2至d5,再求这六个距离的平方和,称为PC1的特征值(Eigenvalue)。然后将PC1的特征值除以总样本数量减一(n-1),就计算出了PC1的差异值(Variation)。

Variation Example
以此类推,并选择差异值最大的两个因子作为PC1 和 PC2。假设在某个三维数组中,获得了PC1、PC2和PC3的差异值分别为18,7,5。通过计算(18+7)/ (18+7+5) ≈ 83.3% 得到结论:PC1 和 PC2 代表了这个三维数组83.3%的差异性。在本次分析的13个因子中,PC1和PC2描述了整组数据约81%的差异性:
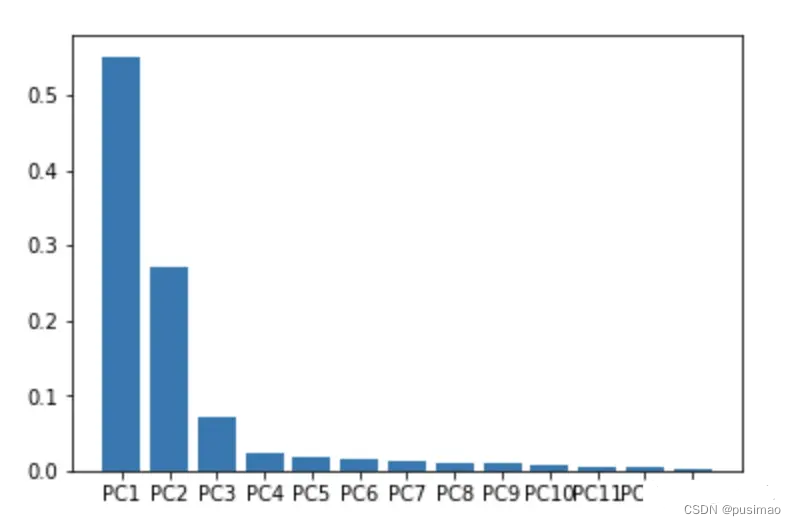
Scree Plot
最后,再通过选中的PC1和PC2将样本映射回本身所在的坐标,就可以得到降维后的图像(PCA Plot)。

PCA Plot
以上便是PCA,主成分分析的实现过程。本文借鉴了Youtube频道StatQuest下的视频:















 785
785











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









