







GitHub:https://github.com/microsoft/OmniParser
更多AI开源软件:发现分享好用的AI工具、AI开源软件、AI模型、AI变现 - 小众AI
微软发布了革命性的视觉Agent框架OmniParser V2。这个能把DeepSeek-R1、GPT-4o等大模型变成"计算机使用智能体"的黑科技,让AI终于不再只是"脑补"屏幕内容——它现在能像人类一样精准识别UI元素,甚至能发现你都没注意到的隐藏按钮!
OmniParser V2.0代表了AI视觉解析技术的重大进步,它不仅促进了用户与数字界面之间的更好互动,还在各类应用中增强了自动化能力。
OmniParser V2.0有广泛的应用场景:
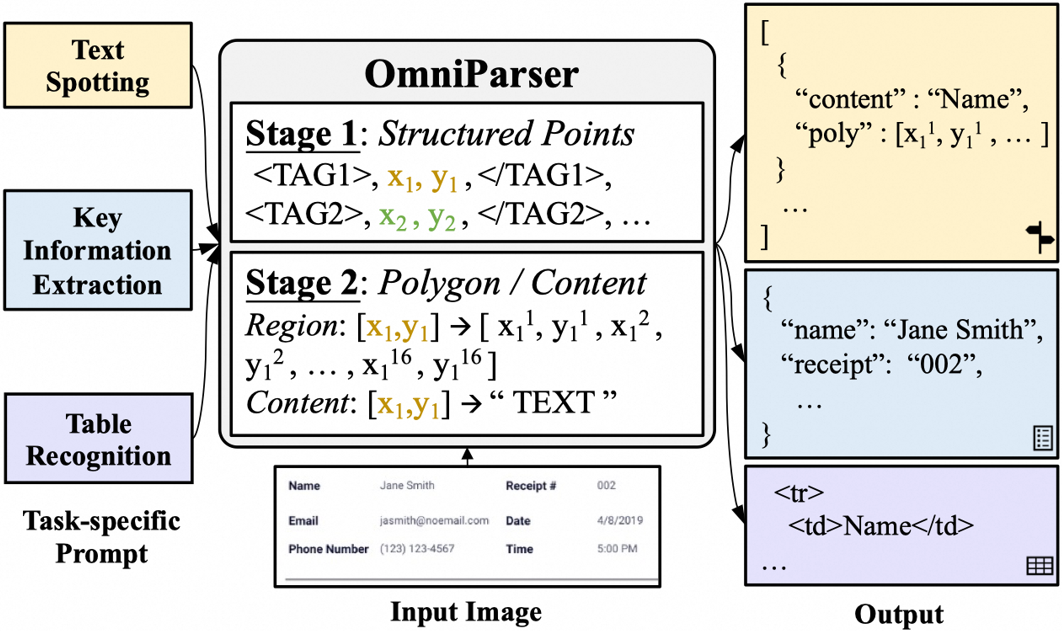
- UI自动化:通过让AI代理与GUI互动来自动化重复任务。
- 辅助技术解决方案:为残障用户提供结构化数据,帮助辅助技术的实现。
- 用户界面分析:根据从截图中提取的数据分析UI设计,提升可用性。
主要功能
- 速度与效率:与其前版本相比,OmniParser V2.0显著减少了约60%的处理延迟,在高端GPU(如A100)上的平均处理时间为0.6秒,在4090型号上为0.8秒。
- 增强的准确性:该工具在检测交互元素方面的平均准确率为39.6%,相比早期版本有了显著提升。这一准确率通过使用精细调优的YOLOv8模型和扩展的训练数据集(涵盖各种UI组件)得以实现。
- 强大的输入/输出能力:OmniParser支持来自多个平台的截图,包括Windows和移动设备。它能够生成UI元素的结构化表示,详细描述可点击区域及其功能。
- 与LLM的无缝集成:该工具通过统一接口OmniTool与多个AI模型集成,如OpenAI的GPT-4o、DeepSeek R1、Qwen 2.5VL和Anthropic Sonnet。这种集成使得创建自动化测试工具和辅助技术解决方案成为可能。
安装和使用
安装OmniParser
pip install omniparser-v2 --prefer-binary
如果pip安装不上,也可以单独访问模型地址使用:https://huggingface.co/microsoft/OmniParser-v2.0
注意:如果卡在Building wheel for...,请泡杯咖啡等待(建议选择云南小粒咖啡,据说能提升编译速度)
下载权重文件和模型
rm -rf weights/icon_detect weights/icon_caption weights/icon_caption_florence
huggingface-cli download microsoft/OmniParser-v2.0 --local-dir weights
mv weights/icon_caption weights/icon_caption_florence
温馨提示:如果下载速度堪比树懒,可以试试把DNS改成114.114.114.114(亲测能快0.5倍)
OCR支持配置
# 安装Tesseract OCR(Windows特供版)
choco install tesseract --params '"/AdditionalLanguages:chi_sim"'
安装完成后记得测试:
tesseract --version
# 应该看到:tesseract 5.3.3... with chi_sim
常见翻车现场:如果报错Error opening data file...,请检查是否安装了中文语言包(就像吃火锅不点毛肚,OCR没中文包就失去灵魂)
实战演练
场景1:解析PDF文件
from omniparser import OmniParser, PdfParser
agent = OmniParser()
result = agent.parse_file("年度亏损报告.pdf", parser_type=PdfParser)
print(result[:500]) # 只打印前500字,防止老板突然出现
效果:AI不仅能提取文字,还能自动识别"财务报表.jpg"里的手写批注(老板的狗爬字有救了!)
场景2:截图转Excel
from omniparser import ImageParser, ExcelWriter
data = agent.parse_file("网页数据截图.png",
parser_type=ImageParser,
lang="chi_sim+eng")
ExcelWriter().save(data, "export.xlsx")
黑科技:自动识别表格线,连合并单元格都能还原(再也不用跪求前端导出数据了!)
场景3:让AI操作你的电脑
# 创建自动化智能体
from omniparser import ActionPlanner
planner = ActionPlanner(model="gpt-4o")
action_sequence = planner.generate_actions("把C盘所有.mp4文件移动到D:\电影")
# 执行操作
for action in action_sequence:
agent.execute_action(action)
警告:执行前请三思!曾有程序员让AI清理桌面,结果连"此电脑"图标都被删了...
DeepSeek 与 OmniParser 2.0 的结合使用
可以实现结构化数据解析与AI能力增强的协同工作。以下是具体结合方式及典型应用场景的详细说明:
场景1:非结构化文档智能处理
流程:
- OmniParser 解析
# 示例:解析复杂PDF合同
from omniparser import DocumentParser
doc = DocumentParser("contract.pdf")
clauses = doc.extract_sections(schema={"parties": "甲方:(.*?)\n乙方:(.*?)\n"})
- DeepSeek 语义分析
from deepseek import LegalAnalyzer
risk_report = LegalAnalyzer.generate_risk_assessment(
text=clauses["payment_terms"],
prompt="识别付款条款中的法律风险点,用Markdown表格输出"
)
输出结果示例:
| 风险点 | 条款原文 | 建议修正方案 |
|---|---|---|
| 违约金比例过高 | "逾期付款需支付日0.5%违约金" | 建议调整为日0.05%(司法保护上限) |
场景2:日志文件异常检测
流程:
- OmniParser 结构化日志
# 使用CLI工具处理服务器日志
omniparser-cli --input server.log --template nginx_error --output errors.json
- DeepSeek 模式识别
from deepseek import AnomalyDetector
detector = AnomalyDetector(model="it_ops_v2")
alerts = detector.analyze_logs(
input_path="errors.json",
rules={"高频500错误": "status=500 count>10/分钟"}
)
智能预警输出:
{
"alert_id": "HTTP_500_CRITICAL",
"timestamp": "2024-03-15T14:23:18Z",
"metric": "status_code=500",
"current_rate": "15次/分钟",
"suggested_action": "立即检查/user-api服务数据库连接池配置"
}

















 212
212

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









