







一、二话不说先上一段最简单的代码
python2.7版本
#!/usr/bin/python2.7
#-*- coding=UTF-8 -*-
import urllib
import re
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
page.close
return html
def get_city(html):
reg = r'<title>【(.+?)天气】.+?</title>'
get_list = re.findall(reg,html)
return get_list[0]
html = getHtml("http://www.weather.com.cn/weather/101010100.shtml")
print "所在城市:"+get_city(html)
python3.5版本
#!/usr/bin/python3.5
#-*- coding=UTF-8 -*-
import urllib.request
import re
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read().decode('utf-8')
page.close
return html
def get_city(html):
reg = r'<title>【(.+?)天气】.+?</title>'
get_list = re.findall(reg,html)
return get_list[0]
html = getHtml("http://www.weather.com.cn/weather/101010100.shtml")
print("所在城市:"+get_city(html))
代码从中国天气网中获取了所在城市信息。
python2.7和python3.5主要在print是否加括号,urllib是否有request和decode两个地方有区别,在我们的例子中其他地方都一样。本文主要以2.7代码进行讲解,3.5的读者可以自行对照。
函数getHtml(url)用于打开一个网页url,返回网页的html源码。该函数内主要都是使用urllib中提供的函数,目的只有一个——获取对应网页的html源码,是字符串格式。
函数get_city(html)用于从html源码中解析出所在城市,对于刚刚入门爬虫的朋友们来说,这个很关键。该函数中主要使用re中提供的函数,主要是用于通过正则表达式来实现字符串的匹配查找等操作。具体就是通过字符串匹配找到包含城市信息的字符串。
二、解析出所在城市的具体过程(核心)
如何才能解析出需要的信息呢?我们要做的是先自己用浏览器打开对应网页查看对应的html源码,分析一下html源码特点之后才能设计一种合理的方法,来看看怎么做。
我们使用的url网址是中国天气网http://www.weather.com.cn/weather/101010100.shtml,先用浏览器打开,然后查看源代码,这里先贴一下前面几行的内容:
<!DOCTYPE html>
<html>
<head>
<link rel="dns-prefetch" href="http://i.tq121.com.cn">
<meta charset="utf-8" />
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
<title>【北京天气】北京天气预报,蓝天,蓝天预报,雾霾,雾霾消散,天气预报一周,天气预报15天查询</title>
<meta http-equiv="Content-Language" content="zh-cn">从html源码可以看到,要想获取城市信息很简单,就在
<title>【北京天气】北京天气预报,蓝天,蓝天预报,雾霾,雾霾消散,天气预报一周,天气预报15天查询</title>
这一行内可以获得,并且自己可以用ctrl+F在源码中搜索<title>,发现全文只有这一处,所以就可以用于确定城市名出现的位置了。
于是根据这个特点,我们在函数get_city(html)中使用正则表示如下:
reg = r'<title>【(.+?)天气】.+?</title>'这里简单介绍一下什么意思,r开头表示对后面字符串不进行转义,保持原样,输入正则表达式时基本都要加。
说说正则表达式里面的内容吧,前后的标示<title>和</title>和html中的保持一致,就是要匹配的字符串,主要用于确定所在的位置。
说说.+?的含义吧,.代表任意字符,+表示重复前面的类型1次或多次,所以.+合在一起表示长度大于等于2的任意字符,而.+?表示的是能够成功匹配的情况下返回最短情况的意思。
说了半天,举个例子,对于字符串“aaaaaabb”如果正则表达式是“a.+?b”那么应该返回aaaaaab,如果是“a.+b”匹配就是aaaaaabb。
所以其实聪明的你已经发现,要想找到我们要的那行字符串,正则表示式只需要
reg = r'<title>.+?</title>'
就能找到了,那中间写那么多东西岂不是多此一举?其实也不是,在这里的正则表达式中,用()括起来的区域可以作为返回值,也就是我们可以用括号()把城市所在位置表示出来,括号里是要的城市,我们用(.+?)即可表示,然后把括号前后信息补充好就成了如下
reg = r'<title>【(.+?)天气】.+?</title>'
这样我们就能找到对应的行,并且返回出我们想要的城市信息了。
get_list = re.findall(reg,html)
return get_list[0]上面两行代码re.findall用于字符串的匹配,从html中查找所有满足正则表达式reg的行,返回一个由这些项组成的list,我们只需要取list中的第一个元素(实际上这里也只有一个)。
好了,到此为止,一个最最基本的爬虫就搞定了。是不是很简单。
三、总结一下写爬虫程序的基本思路
从上面的例子你可能也对爬虫的概念有了更直观的了解,其实就是获取html源码,然后用正则表达式进行分析。
步骤基本如下:
确定要抓取的大致信息,选择合适的网址,分析目标网页的html源代码,找到自己感兴趣的信息所在源码位置,设计合理的正则表达式用于匹配,写代码,测试,调试。
所以看得出来,我们写的python爬虫只能针对特定的网页,换了网页可就不行了呢。
四、上个全一点的代码吧
#!/usr/bin/python2.7
#-*- coding=UTF-8 -*-
import urllib
import re
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
page.close
return html
def get_city(html):
reg = r'<title>【(.+?)天气】.+?</title>'
get_list = re.findall(reg,html)
if len(get_list)>0:
return get_list[0]
else:
return "无数据"
def get_start(html):
reg=r'<h1>.+?(今天.+?</h1>'
get_list = re.findall(reg,html)
if len(get_list)>0:
return get_list[0]
else:
return "无数据"
def get_end(html):
reg=r'<h1>.+?(明天.+?</h1>'
get_list = re.findall(reg,html)
if len(get_list)>0:
return get_list[0]
else:
return "无数据"
def get_block(html):
start=html.find(get_start(html))
end=html.find(get_end(html))
block=html[start:end]
return block
def get_block_date(block):
reg=r'<h1>(.+?)(今天.+?</h1>'
get_list = re.findall(reg,block)
if len(get_list)>0:
return get_list[0]
else:
return "无数据"
def get_block_air(block):
reg=r'p class="wea" title="(.+?)".+?'
get_list = re.findall(reg,block)
if len(get_list)>0:
return get_list[0]
else:
return "无数据"
def get_block_day_tmp(block):
reg=r'<span>([0-9]+).+?</span>'
get_list = re.findall(reg,block)
if len(get_list)>0:
return get_list[0]
else:
return "无数据"
def get_block_night_tmp(block):
reg=r'<i>([0-9]+).+?</i>'
get_list = re.findall(reg,block)
if len(get_list)>0:
return get_list[0]
else:
return "无数据"
def get_block_wind(block):
reg=r'<i>([^0-9]+)</i>'
get_list = re.findall(reg,block)
if len(get_list)>0:
return get_list[0]
else:
return "无数据"
html = getHtml("http://www.weather.com.cn/weather/101010100.shtml")
block=get_block(html)
print "所在城市:"+get_city(html)
print "查询日期:"+get_block_date(block)
print "天气情况:"+get_block_air(block)
print "日间温度:"+get_block_day_tmp(block)
print "夜间温度:"+get_block_night_tmp(block)
print "风力指数:"+get_block_wind(block)
通过类比的方法创建了形式差不多的函数,分别读取日期,天气,温度,风力等。
说一下思路吧,还是要根据html源码,看看源码:
<h1>19日(今天)</h1>
<big class="png40"></big>
<big class="png40 n07"></big>
<p class="wea" title="中度霾(南部地区重度霾)或雾转小雨">中度霾(南部地区重度霾)或雾转小雨</p>
<p class="tem">
<span>22℃</span>
<i>13℃</i>
</p>
<p class="win">
<em>
<span title="无持续风向" class=""></span>
</em>
<i>微风</i>
</p>
<div class="slid"></div>
</li>
<li class="sky skyid lv3">
<h1>20日(明天)</h1>通过查看html源码,就发现我们感兴趣的信息都在这么一个区域内,所以先把这个区域抓下来,再对这个区域的内容进行分析就能实现了。所以函数get_start(html)通过“今天”确定截取字符串的开始位置,而get_end(html)用于通过“明天”确定截取字符串结尾位置,get_block(html)就能通过开始和结束位置将这个区域的数据保存下来。以后分析就不用对整个html进行分析,就只需要分析这么一小段了,是不是更简单。
def get_start(html):
reg=r'<h1>.+?(今天.+?</h1>'
get_list = re.findall(reg,html)
if len(get_list)>0:
return get_list[0]
else:
return "无数据"
def get_end(html):
reg=r'<h1>.+?(明天.+?</h1>'
get_list = re.findall(reg,html)
if len(get_list)>0:
return get_list[0]
else:
return "无数据"
def get_block(html):
start=html.find(get_start(html))
end=html.find(get_end(html))
block=html[start:end]
return block其他的函数就从我们刚刚保存的这个小区域block中提取数据即可。分析方法就是设计合理的正则表达式来匹配。
这里就简单对照一下就好了。(还有更简洁的写法,可以自己试试看)
获取日期
<h1>19日(今天)</h1>
def get_block_date(block):
reg=r'<h1>(.+?)(今天.+?</h1>'
……获取天气
<p class="wea" title="中度霾,南部地区重度霾转中度霾转小雨">中度霾,南部地区重度霾转中度霾转小雨</p>
def get_block_air(block):
reg=r'<p class="wea" title="(.+?)".+?'
……获取日间温度
<span>22℃</span>/
def get_block_day_tmp(block):
reg=r'<span>([0-9]+).+?</span>'获取夜间温度
<i>14℃</i>
def get_block_night_tmp(block):
reg=r'<i>([0-9]+).+?</i>'
……获取风力指数
<i>微风</i>
def get_block_wind(block):
reg=r'<i>([^0-9]+)</i>'
……由于实测发现并不是每一次都能有数据返回,也就是说有些情况下有些项目是没有的,比如晚上就没有白天的气温,无风的时候就没有风力指数等,所以我们每次都对返回结构长度进行了判断,如果有才显示,没有的话就显示无数据。
傍晚测试效果如下
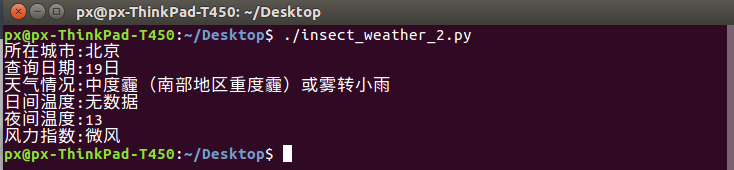
第二天白天测试效果如下
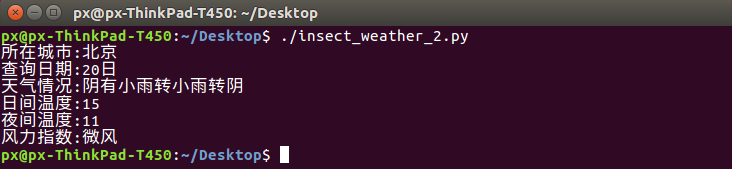
不喜欢复制粘贴可以直接下载源码
点击下载源码python2.7版本
点击下载源码python3.5版本















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









