







前言
数据分析的基本流程:
- 提出问题
- 理解数据
- 数据清洗
- 构建模型
- 数据可视化
- 形成报告
一、提出问题
本次报告的主要任务是:根据历史电影数据,分析哪种电影收益能力更好,未来电影的流行趋势,以及为电影拍摄提供建议。细化为以下几个小问题:
- 电影风格随时间变化的趋势;
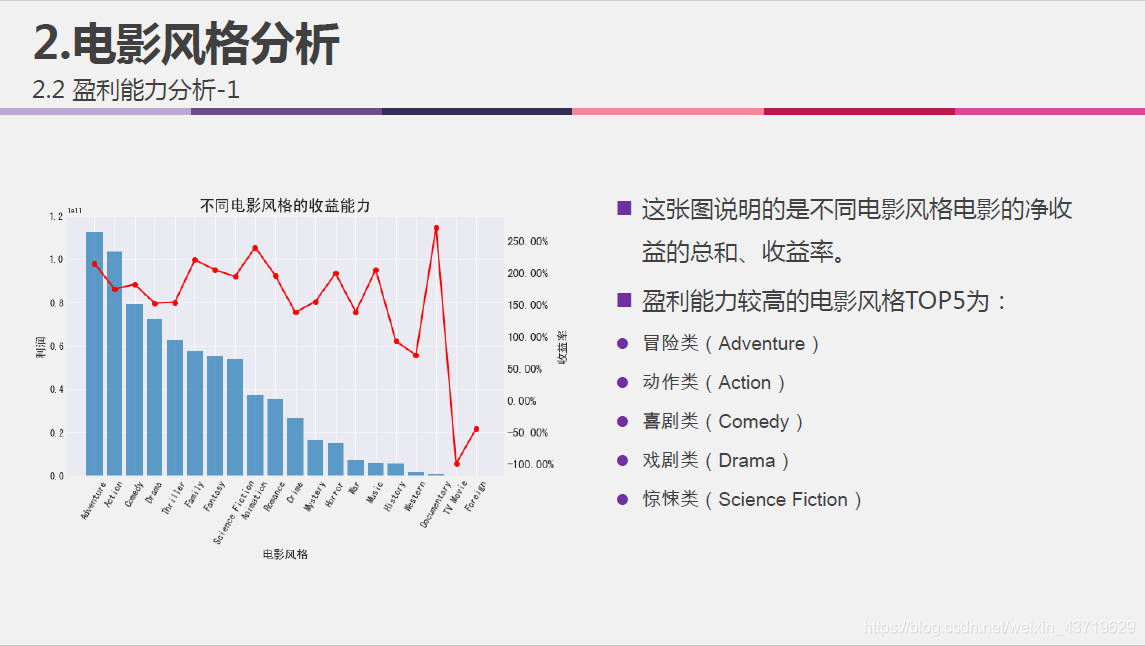
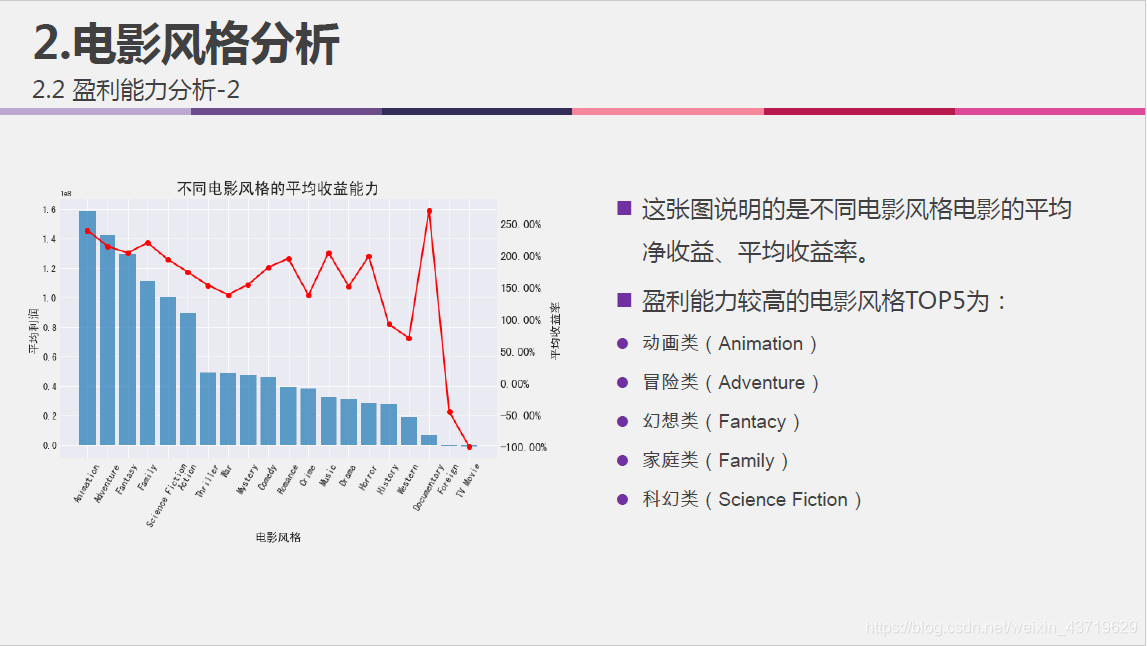
- 不同风格电影的收益能力;
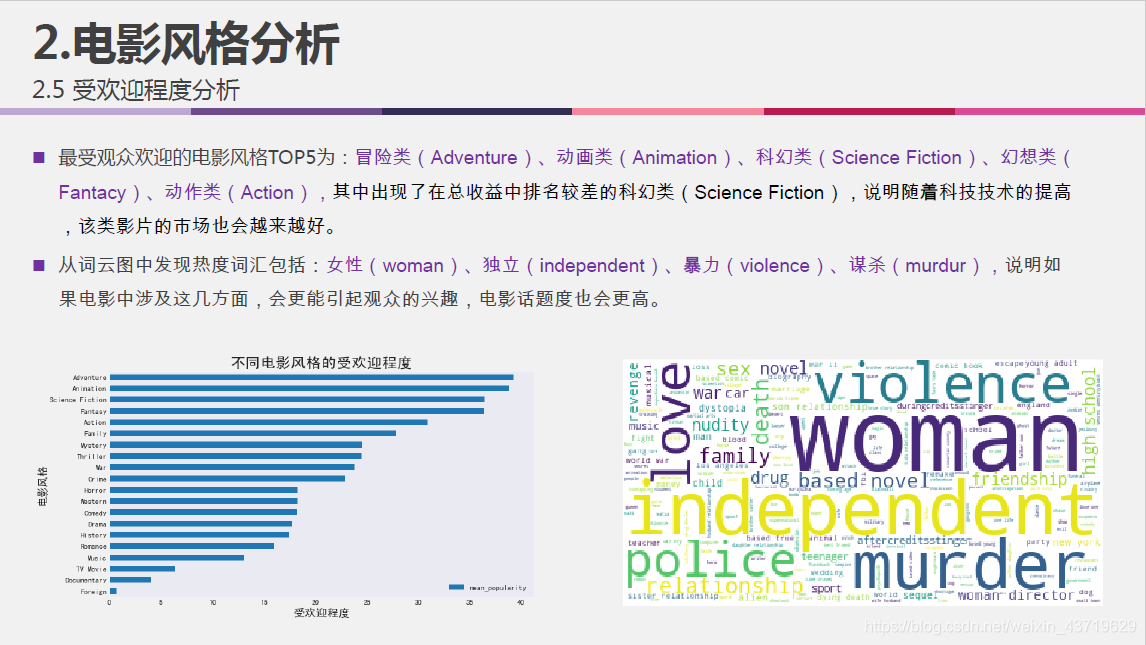
- 不同风格电影的受欢迎程度
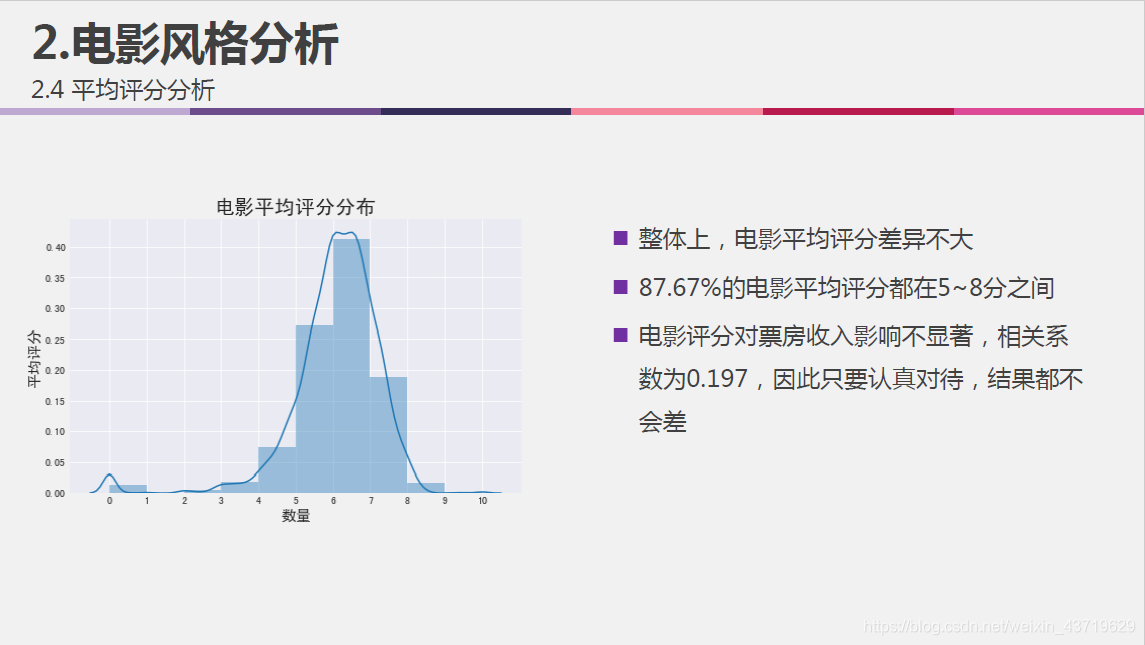
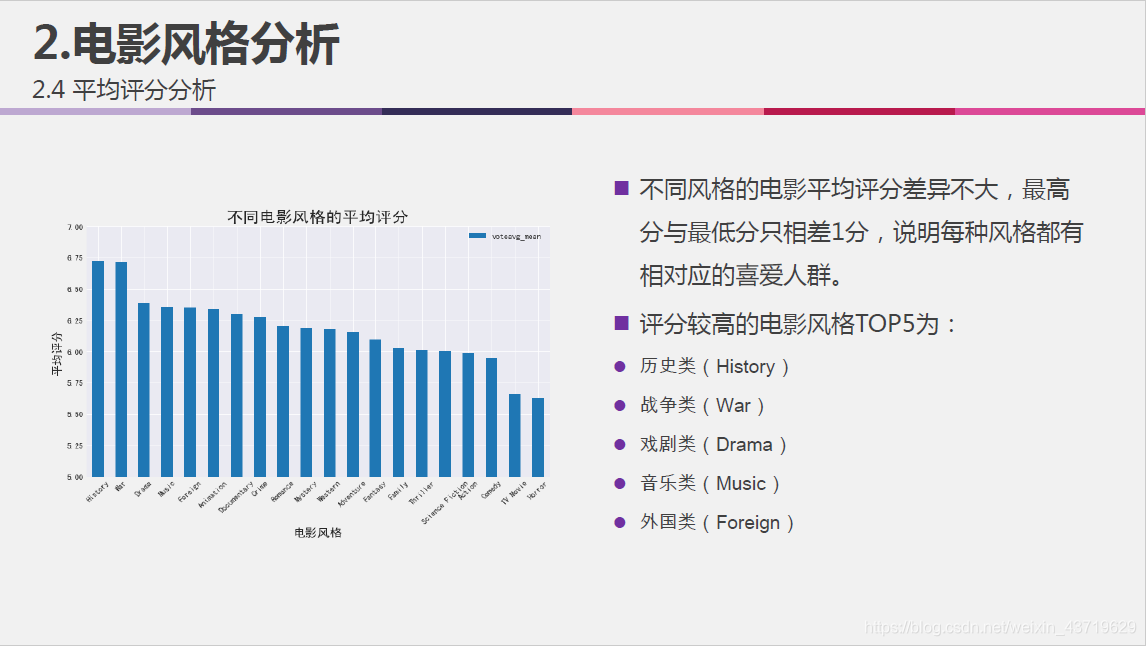
- 不同风格电影的评分比较;
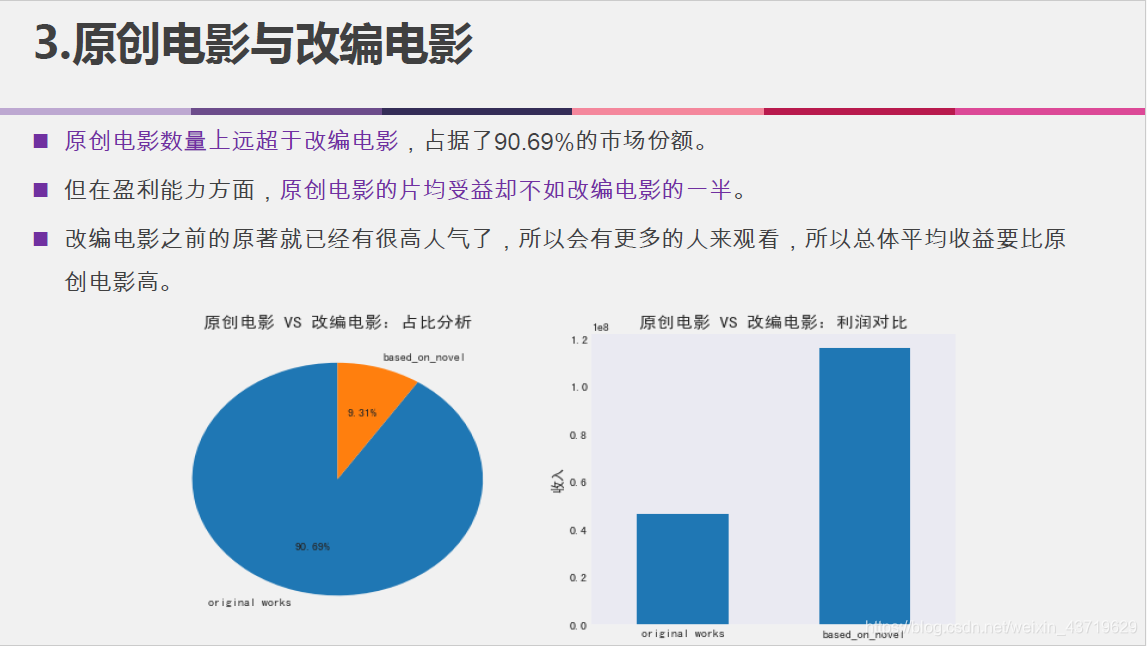
- 原创电影与改编电影对比;
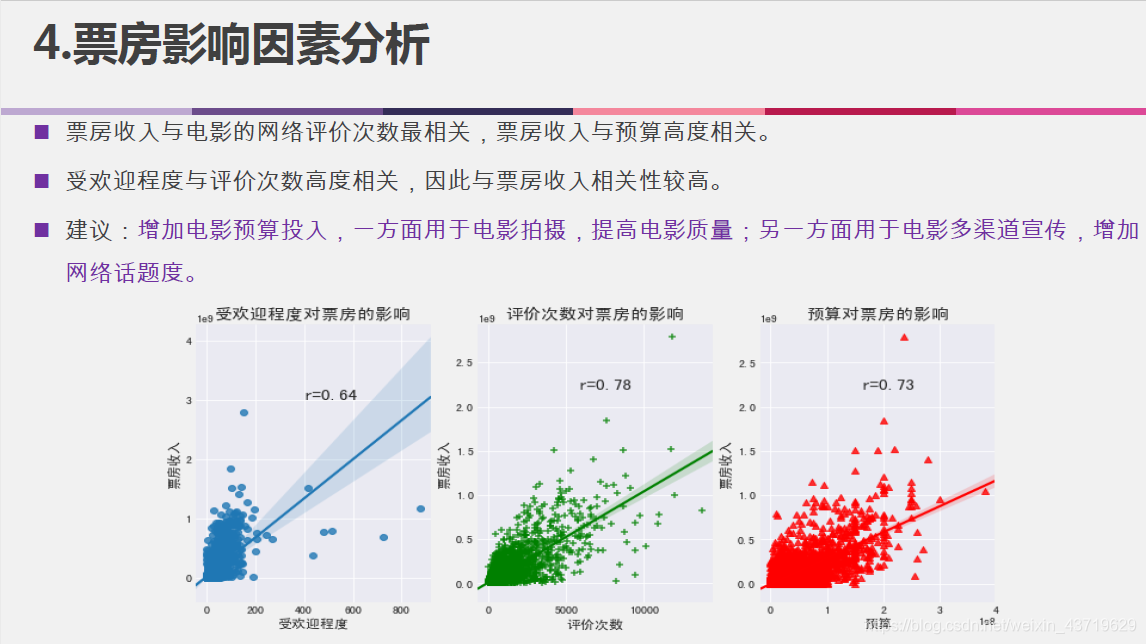
- 影响票房收入的因素;
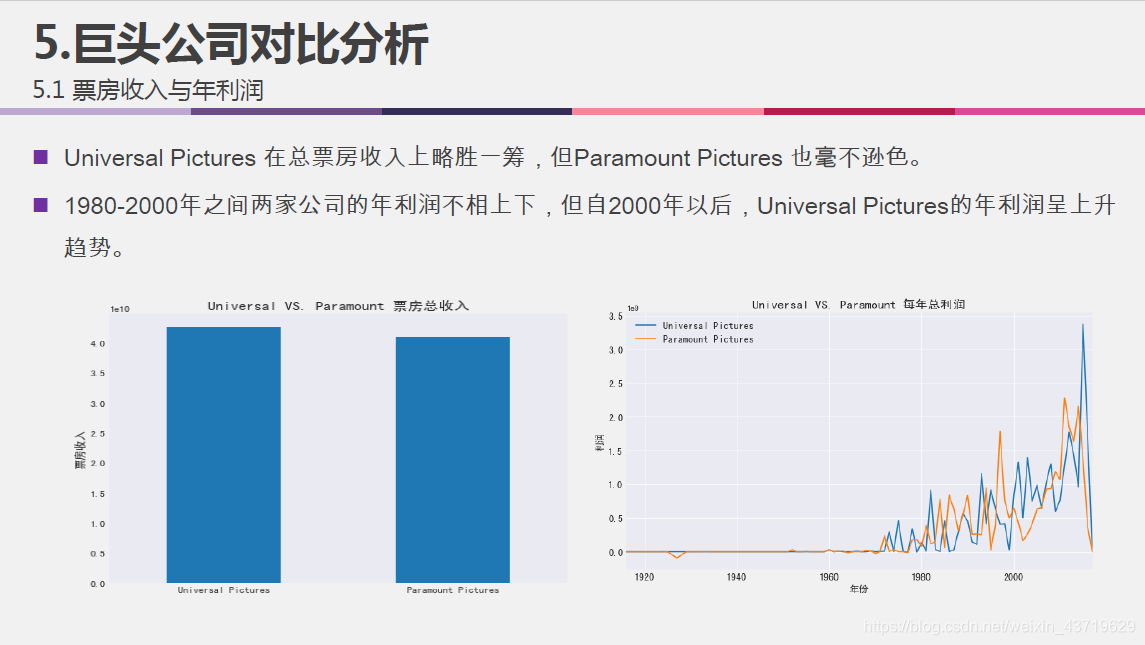
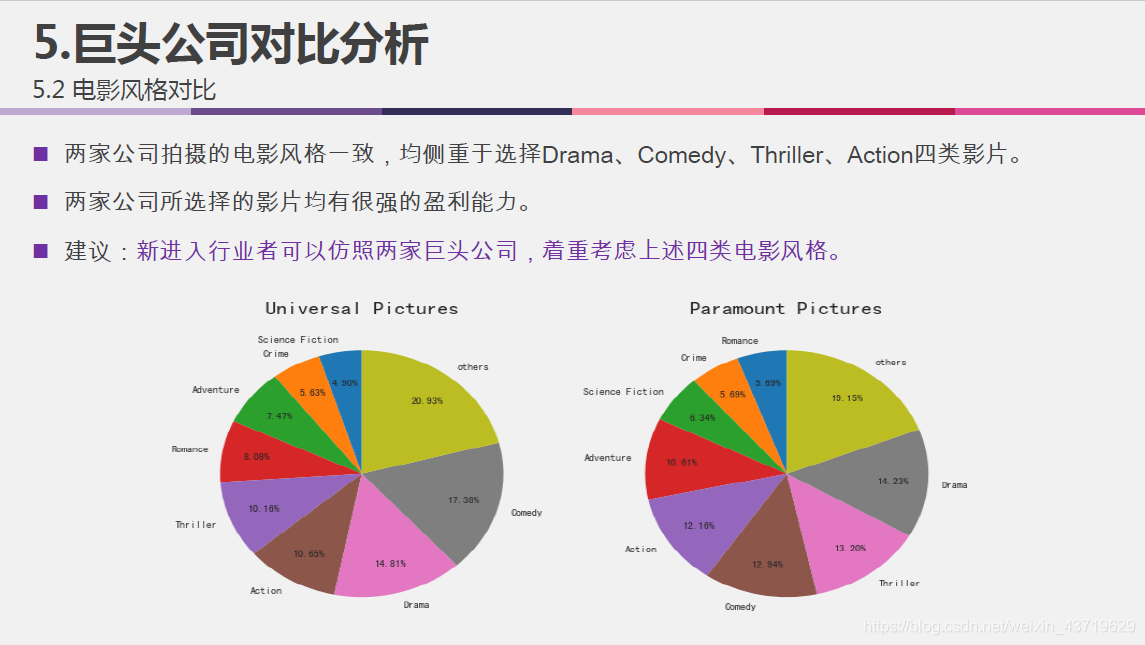
- 比较行业内两家巨头公司Universal Pictures和Paramount Pictures.
二、理解数据
从Kaggle平台上下载原始数据集:tmdb_5000_movies和tmdb_5000_credits,前者为电影基本信息,包含20个变量,后者为演职员信息,包含4个变量。
导入数据集后,通过对数据的查看,并结合要分析的问题,筛选出以下9个要重点分析的变量:
| 序号 | 变量名 | 说明 |
|---|---|---|
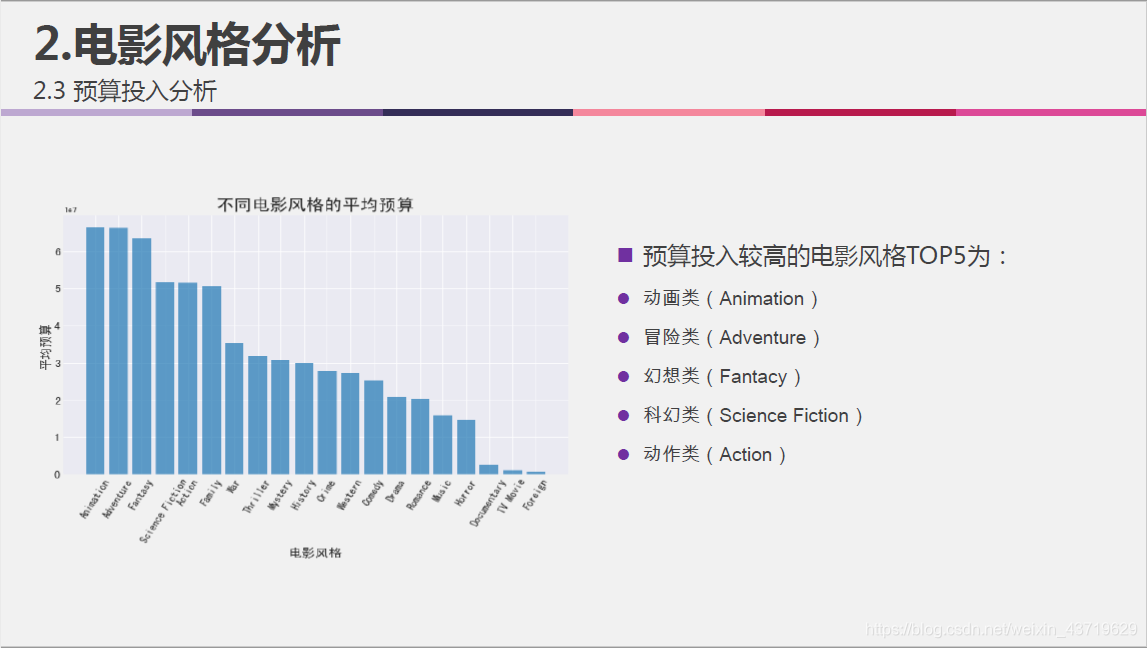
| 1 | budget | 电影预算(单位:美元) |
| 2 | genres | 电影风格 |
| 3 | keywords | 电影关键字 |
| 4 | popularity | 受欢迎程度 |
| 5 | production_companies | 制作公司 |
| 6 | release_year | 上映时间 |
| 7 | revenue | 票房收入(单位:美元) |
| 8 | vote_average | 平均评分 |
| 9 | vote_count | 评分次数 |
三、数据清洗
针对本数据集,数据清洗主要包括三个步骤:1.数据预处理 2.特征提取 3.特征选择
-
数据预处理:
(1)通过查看数据集信息,发现’runtime’列有一条缺失数据,‘release_date’列有一条缺失数据,‘homepage’有30条缺失数据,只对‘release’列和‘runtime’列进行缺失值填补。具体操作方法是:通过索引的方式找到具体是哪一部电影,然后上网搜索准确的数据,将其填补。(详见后续代码)
(2)对‘release_date’列进行格式转化,并从中抽取出“年份”信息。 -
特征提取:
(1)credits数据集中cast,crew这两列都是json格式,需要将演员、导演分别从这两列中提取出来;
movies数据集中的genres,keywords,production_companies都是json格式,需要将其转化为字符串格式。
(2)处理过程:通过json.loads先将json格式转换为字典列表"[{},{},{}]"的形式,再遍历每个字典,取出键(key)为‘name’所对应的值(value),并将这些值(value)用“,”分隔,形成一个“多选题”的结构。在进行具体问题分析的时候,再将“多选题”编码为虚拟变量,即所有多选题的每一个不重复的选项,拿出来作为新变量,每一条观测包含该选项则填1,否则填0。 -
特征选择:
在分析每一个小问题之前,都要通过特征提取,选择最适合分析的变量,即在分析每一个小问题时,都要先构造一个数据框,放入要分析的变量,而不是在原数据框中乱涂乱画。
四、数据可视化
本次数据分析只是对数据集进行了基本的描述性分析和相关性分析,构建模型步骤均与特征选取、新建数据框一起完成,本案例不属于机器学习范畴,因此不涉及构建模型问题。
本次数据可视化用到的图形有:折线图、柱状图、直方图、饼图、散点图、词云图。(详见后续代码)
五、形成数据分析报告




 在这里插入图片描述
在这里插入图片描述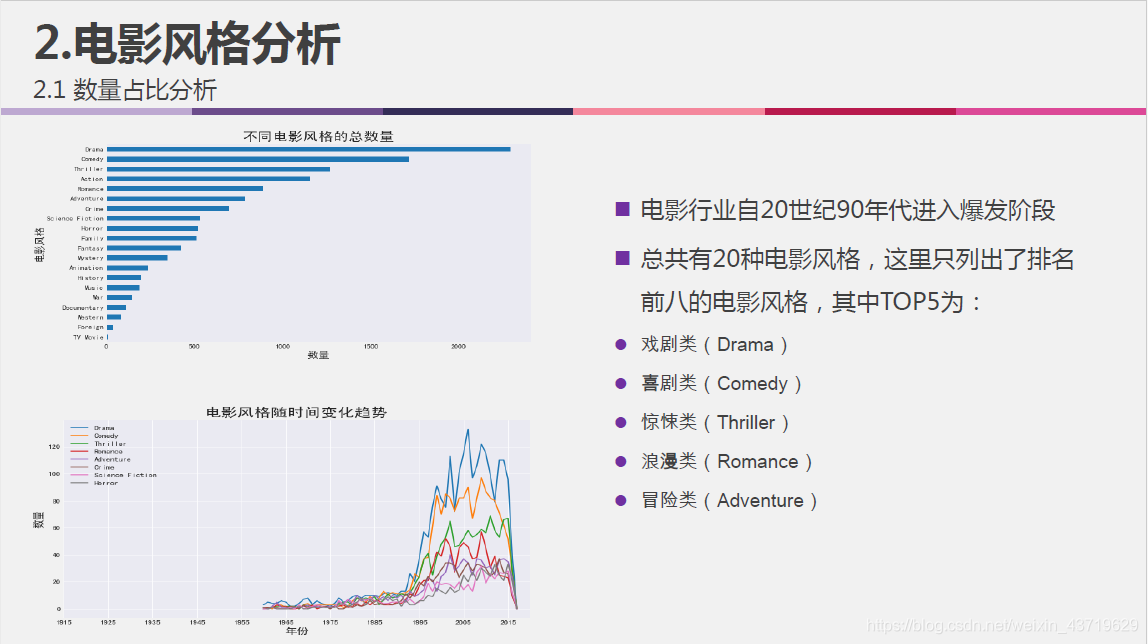






代码部分:
导入包,并读取数据集:
import numpy as np
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style('darkgrid')
from pandas import DataFrame, Series
import json
from wordcloud import WordCloud, STOPWORDS
plt.rcParams['font.sans-serif'] = ['SimHei']
#读取数据集:电影信息、演员信息
movies = pd.read_csv('tmdb_5000_movies.csv',encoding = 'utf_8')
credits = pd.read_csv('tmdb_5000_credits.csv',encoding = 'utf_8')
处理json数据格式,将两张表合并为一张表,并删除不需要的字段:
#将json数据转换为字符串
#credits:json数据解析
json_cols = ['cast', 'crew']
for i in json_cols:
credits[i] = credits[i].apply(json.loads)
#提取演员
def get_names(x):
return ','.join([i['name'] for i in x])
credits['cast'] = credits['cast'].apply(get_names)
credits.head()
#提取导演
def get_directors(x):
for i in x:
if i['job'] == 'Director':
return i['name']
credits['crew'] = credits['crew'].apply(get_directors)
#将字段‘crew’改为‘director’
credits.rename(columns={
'crew':'director'}, inplace = True)
#movies:json数据解析
json_cols = ['genres', 'keywords', 'spoken_languages', 'production_companies', 'production_countries']
for i in json_cols:
movies[i] = movies[i].apply(json.loads)
def get_names(x):
return ','.join([i['name'] for i in x])
movies['genres'] = movies['genres'].apply(get_names)
movies['keywords'] = movies['keywords'].apply(get_names)
movies['spoken_languages'] = movies['spoken_languages'].apply(get_names)
movies['production_countries'] = movies['production_countries'].apply(get_names)
movies['production_companies'] = movies['production_companies'].apply(get_names)
#合并数据
#credits, movies两个表中都有字段id, title,检查两个字段是否相同
(movies['title'] == credits['title']).describe()
#删除重复字段
del movies['title']
#合并两张表,参数代表合并方式
df = credits.merge(right = movies, how = 'inner', left_on = 'movie_id', right_on = 'id')
#删除分析不需要的字段
del df['overview']
del df['original_title']
del df['id']
del df['homepage']
del df['spoken_languages']
del df['tagline']
填补缺失值,并抽取“年份”信息:
#填补缺失值
#首先查找出缺失值记录
df[df.release_date.isnull()]
#然后在网上查询到该电影的发行年份,进行填补
df['release_date'] = df['release_date'].fillna('2014-06-01')
#电影时长也和上面的处理一样
df.loc[2656] = df.loc[2656].fillna(94)
df.loc[4140] = df.loc[2656].fillna(81)
#转换日期格式,只保留年份信息
df['release_year'] = pd.to_datetime(df.release_date, format = '%Y-%m-%d').dt.year
不同电影风格的数量占比分析,以及随时间变化的趋势:
#获取电影类型信息
genre = set()
for i in df['genres'].str.split(','):
genre = set().union(i,genre)
#转化为列表
genre = list(genre)
#移除列表中无用的字段
genre.remove('')
#对电影类型进行one-hot编码
for genr in genre:
df[genr] = df['genres'].str.contains(genr).apply(lambda x: 1 if x else 0)
df_gy = df.loc[:, genre]
df_gy.index = df['release_year']
#各种电影类型的总数量
df_gysum = df_gy.sum().sort_values(ascending = True)
df_gysum.plot.barh(label='genre', figsize=(10,6))
plt.xlabel('数量',fontsize=15)
plt.ylabel 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3583
3583

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









