






随着社会的多元化,越来越多的影视作品走入人们的生活中。但是近年来鲜有几部新制作的电影能俘获观众的心,到底是观众越来越挑剔,还是电影作品本身不够吸引力?如果你是有一个电影公司,你想制作一部电影作品,你有想过拍一部什么样的电影吗?你会选择一名什么样的导演呢?这里由Movie Database网站提供了一份数据集,主要包括1960-2015年上映的部分电影的样本集。这是UdaCity其中一个项目——tableau可视化的提供的数据集(点击链接到我的tableau可视化图形主页,可以点击页面下方元数据查看不同的分析维度),我自己用Python以及统计知识再实现一遍。
数据探索
数据集一共包含了十多个字段:
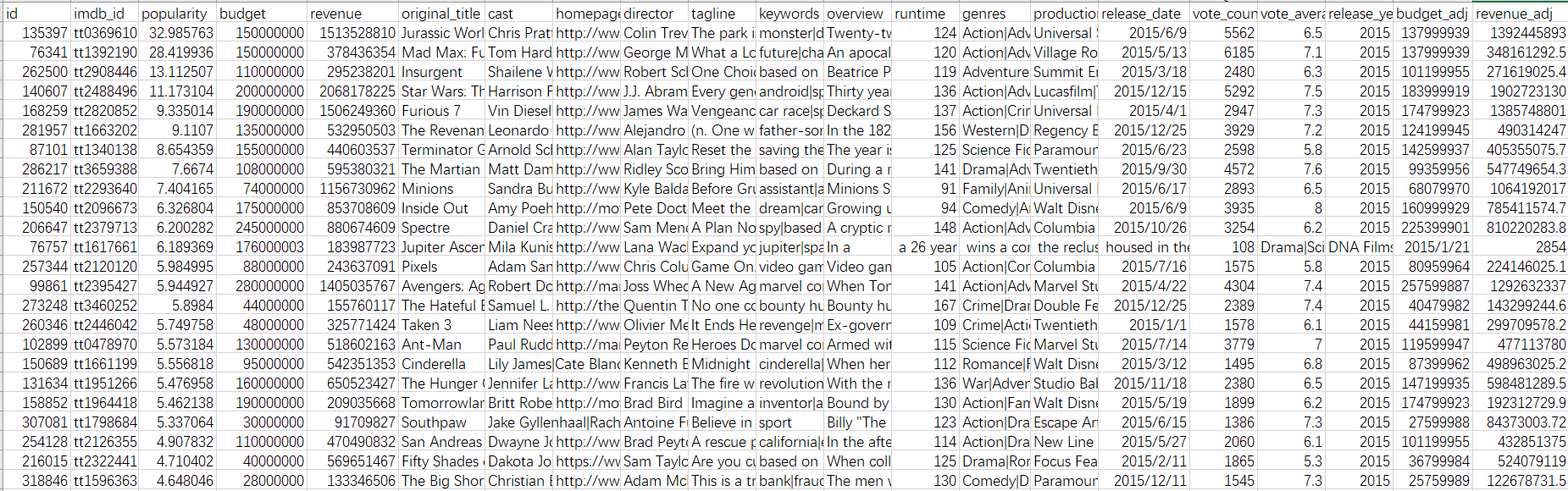
每个字段意义如下:
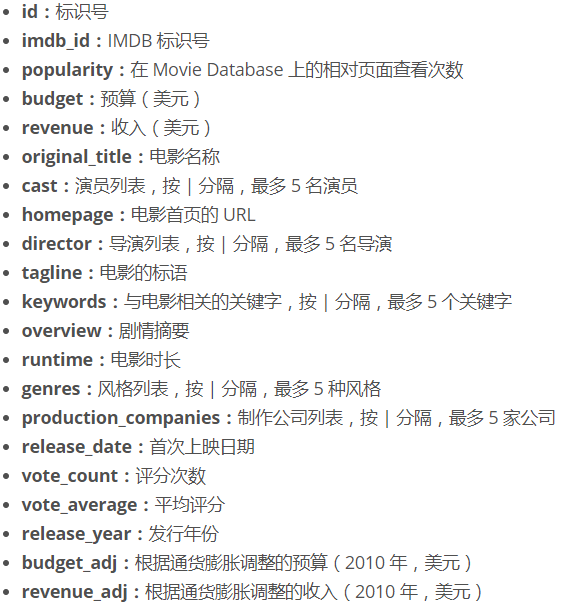
数据清理
首先用pandas库读取数据,然后我发现数据有一行是重复的,因此先要去重,同时筛选出对我们分析过程有意义的字段:
movies= movies.drop_duplicates(subset='id',keep='first')[['id','cast','director','genres','production_companies','vote_average','release_year','revenue_adj','keywords','original_title']] # 42194重复
通过观察数据,会发现director、genres等字段包含了多个分类,并以"|"隔开的,因此先定义两个方法把这些拆分出来,在聚合到原DataFrame。
def def_split(movies,key): ''' key为'genres'、'production_companies'等,按'|'分隔,加上expand=True会根据key聚合到数据框 ''' movies = movies.drop(key, axis=1).join( movies[key].str.split('|', expand=True).stack().reset_index(level=1, drop=True).rename(key)) movies = movies[[key,'id','vote_average','release_year','revenue_adj','original_title']] # 再次过滤我们需要的字段 movies = movies[movies['revenue_adj']>0] # 部分电影收入为0, 给其赋值会影响统计结果,因此过滤掉 if key== 'production_companies': movies= movies[(movies[key]=='Universal Pictures') | (movies[key]=='Paramount Pictures')] # 如果key值为production_companies(制作公司),只选取Universal Pictures # 和Paramount Pictures这两个公司进行对比分析 return movies[[key,'id','vote_average','release_year','revenue_adj','original_title']]
def keywords_split(movies): ''' 当判断影片是否根据小说改编时,需要新增一列,再根据这一列的数据分组分析 ''' movies = movies[['keywords', 'id', 'vote_average', 'release_year', 'revenue_adj']].dropna() movies['novel'] = movies['keywords'].map(lambda x:'based on novel' if 'based on novel' in x else 'not based on novel') # 这方法很无敌,搭配匿名函数lambda,map方法直接将新值映射到Series。也可以使用下面的常规方法,易懂但代码量多些 ''' index=movies['keywords'].index arr=[] for key in movies['keywords']: if 'based on novel' in key: arr.append('based on novel') else: arr.append('not based on novel') movies['novel'] = Series(arr,index=index) ''' movies = movies[movies['revenue_adj'] > 0] return movies[['id', 'vote_average', 'release_year', 'revenue_adj','novel']]
我从四个维度来分析趋势,因此新建四个数据集,后文分析都基于这四个数据集:
movies_genres=def_split(movies,'genres') # 按照电影分类(电影题材) movies_production_companies=def_split(movies,'production_companies') # 按照制作公司,Universal Pictures与Paramount Pictures对比分析 movies_director=def_split(movies,'director') # 按照导演 movies_novel=keywords_split(movies) # 按照剧本分类(按是否由小说改编分为改编和原创剧本)
数据分析过程
1. 电影题材的发展趋势
movies_genres.groupby(['genres','release_year'])['genres'].count().unstack('genres').plot()
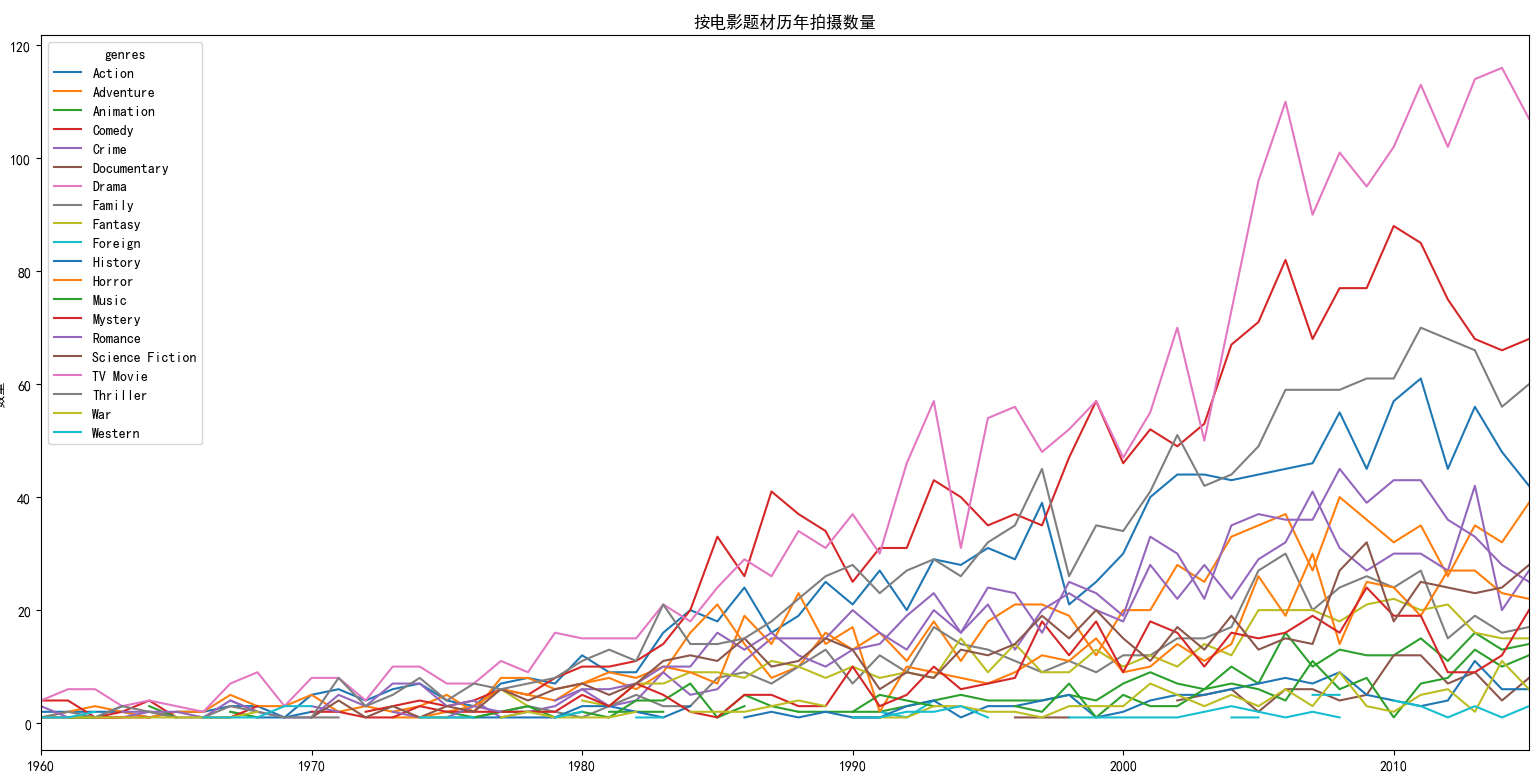
很明显戏剧(Drama)、喜剧(Comedy)和惊悚(Thriller)三种类型的电影越来越受导演青睐,因为这三类电影增长的数量是最快。
movies_genres.groupby(['genres'])['vote_average'].mean().plot(kind='bar')
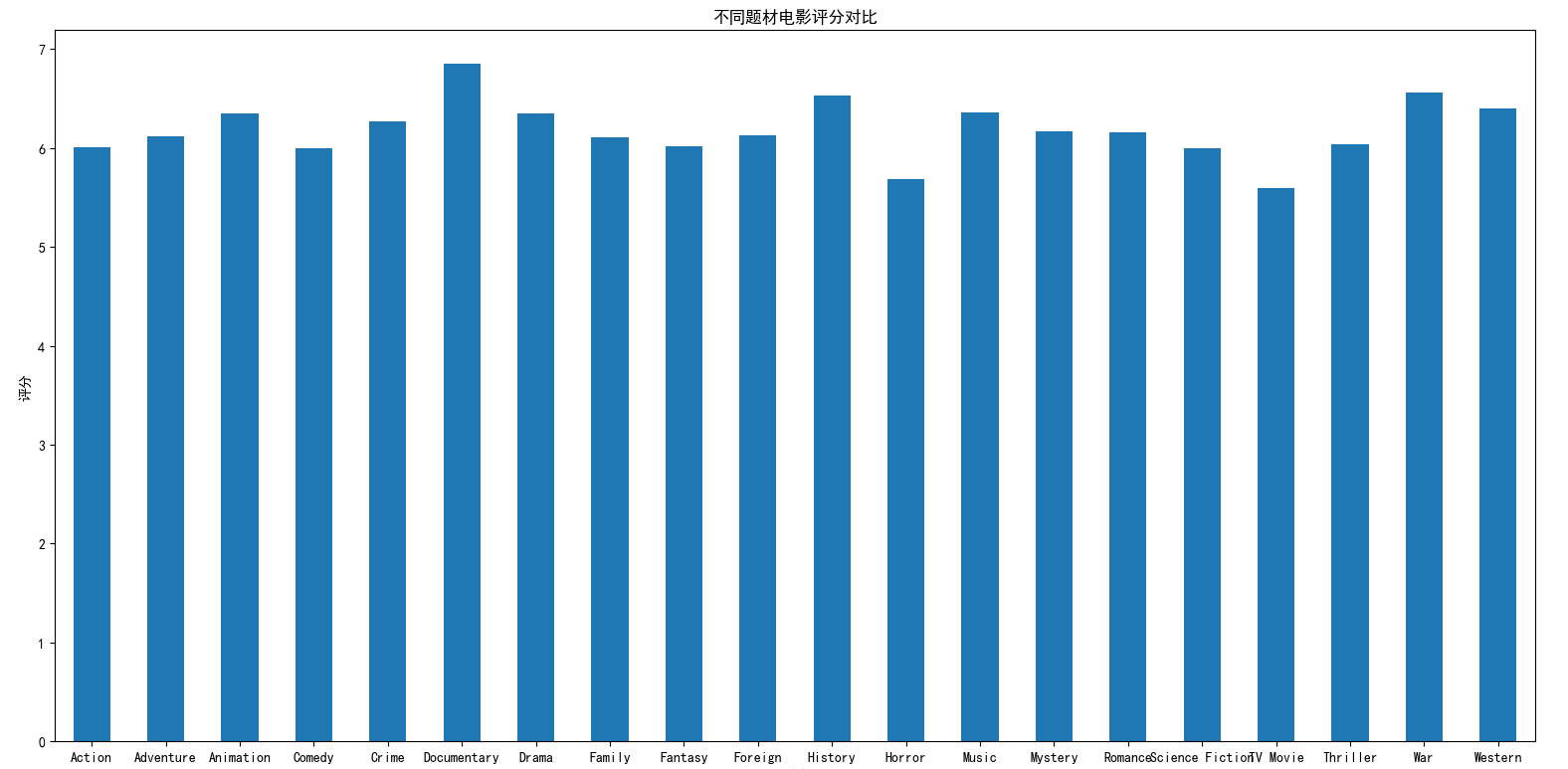
不同题材电影的评分差距不太大,经过平均下来看,都保持在6分左右。
movies_genres.groupby(['genres','release_year'])['revenue_adj'].sum().unstack('genres').plot()
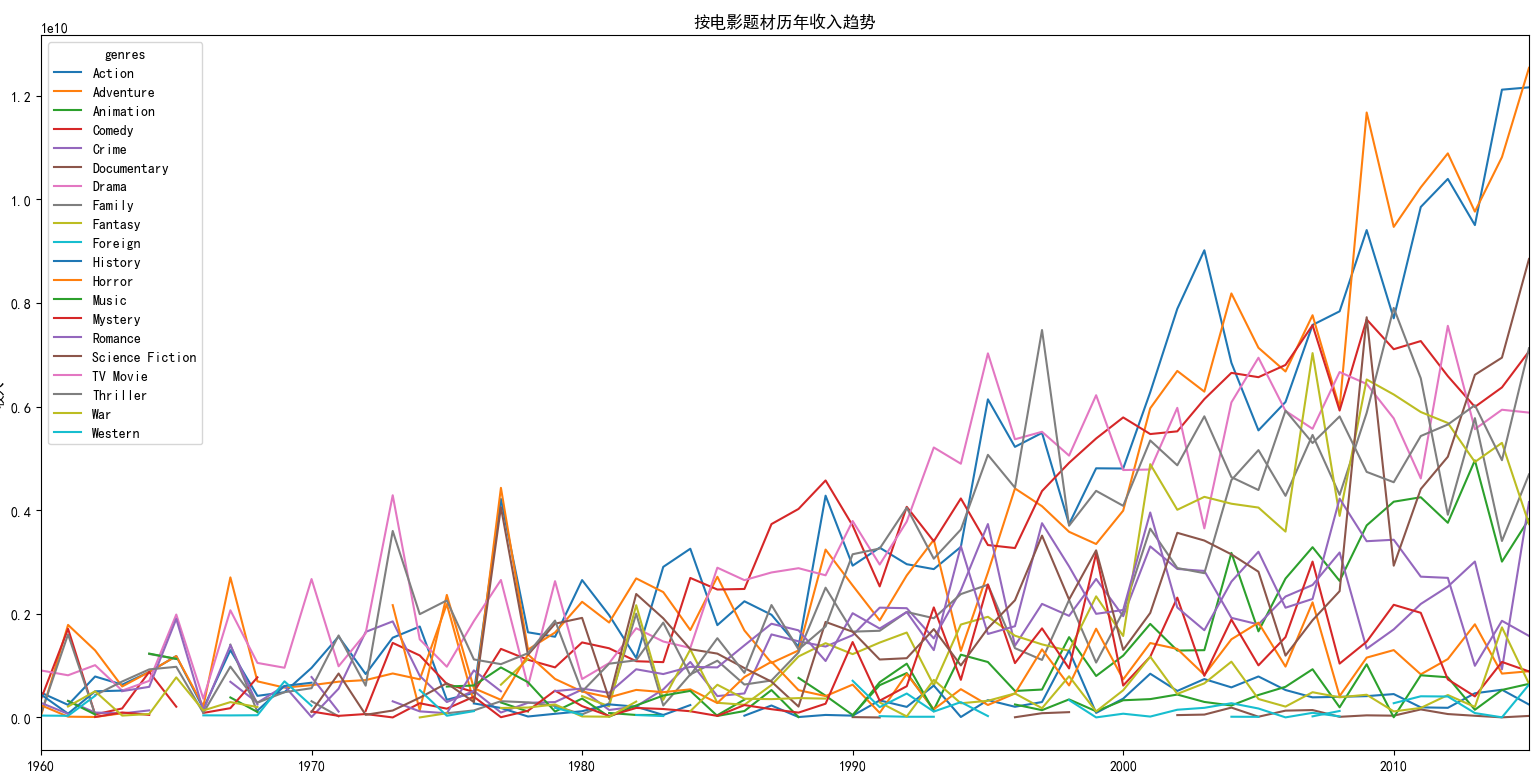
但是对于电影收入来讲,对比则很能说明问题了,动作(Action)和冒险(Adventure)题材类的电影挣钱最多,而这两类电影的拍摄数量不算是最多的,说明这两类电影很卖座,票房都比较高。而类似于战争(War)和西部(Western)两种题材的电影既不卖座,大众接受度也不高,因此有被淘汰的趋势。
2. 电影公司Universal Pictures 与 Paramount Pictures对比
# 需要分析电影制作公司对不同电影题材的喜好,因此将电影分类的数据合并在一起 movies_production_companies=pd.merge(movies_production_companies,movies_genres,how='left')
movies_production_companies.groupby(['production_companies','genres'])['production_companies'].count().unstack('production_companies').plot(kind='bar')
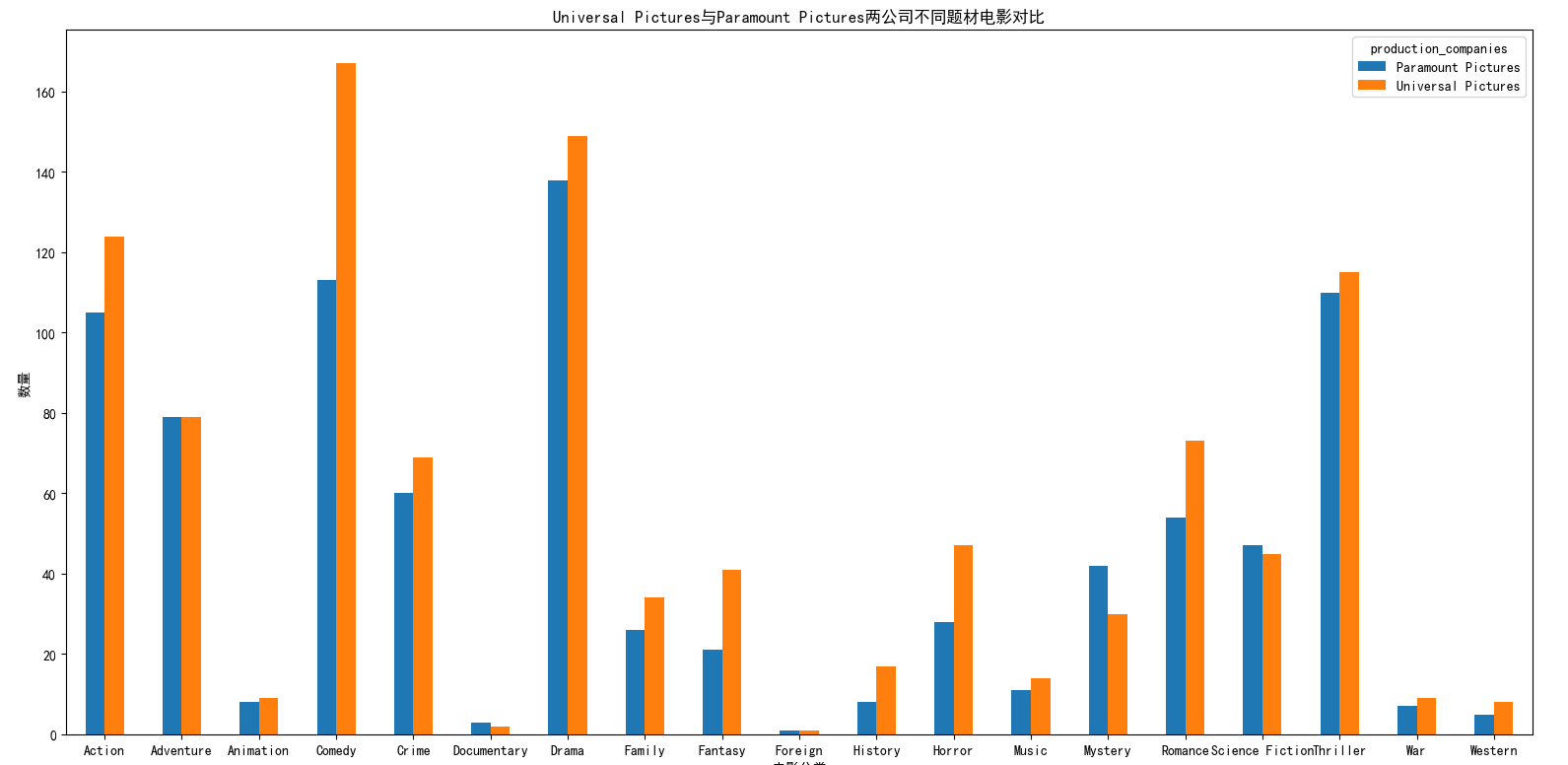
两个公司都在喜剧(Comedy)、动作(Action)、戏剧(Drama)以及惊悚(Thriller)题材投入了较多资源,拍摄的电影数量比其他题材要多很多,但在仔细看一下,发现Universal Pictures总是略胜一筹,几乎每个题材所拍摄的影片都比Paramount Pictures要多,但优势不太大。
movies_production_companies.groupby(['production_companies','genres'])['revenue_adj'].sum().unstack('production_companies').plot(kind='barh')
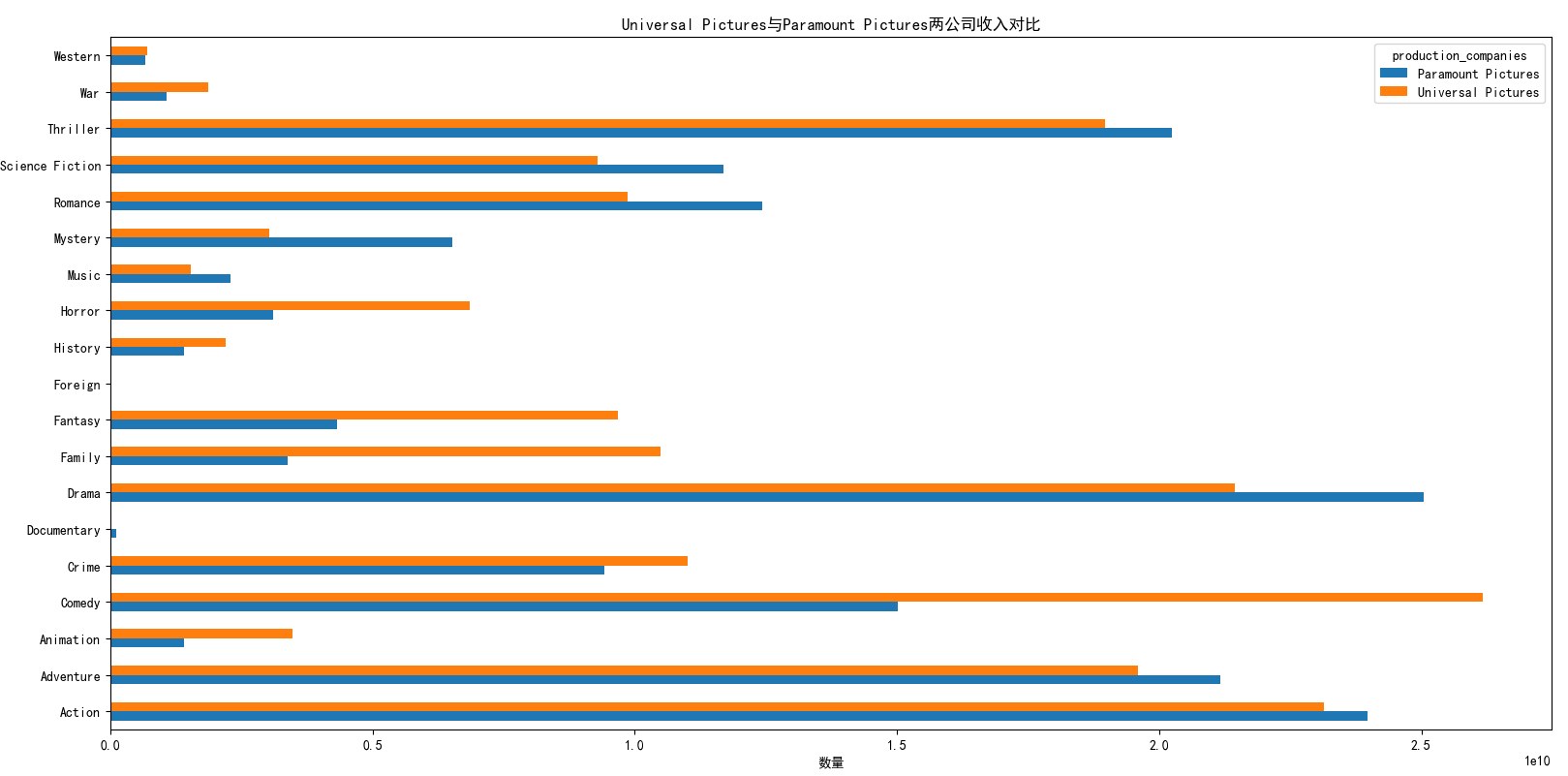
两个公司拍摄的不同题材电影,给公司带来主要收入的依然是动作(Action)、冒险(Adventure)、戏剧(Drama)、喜剧(Comedy)和惊悚(Thriller)这几类主要题材的影片,两个公司的表现情况也是差距不大。Universal Pictures 和 Paramount Pictures两制作公司无论是在尝试制作不同题材的电影方面,还是电影对公司的营收,亦或是观众对两个公司电影的接受程度,都表现出相当的一致性,因此我们有理由认为,两个公司旗鼓相当!
3. 改编电影与原创电影对比
movies_novel.groupby(['novel','release_year'])['novel'].count().unstack('novel').plot()
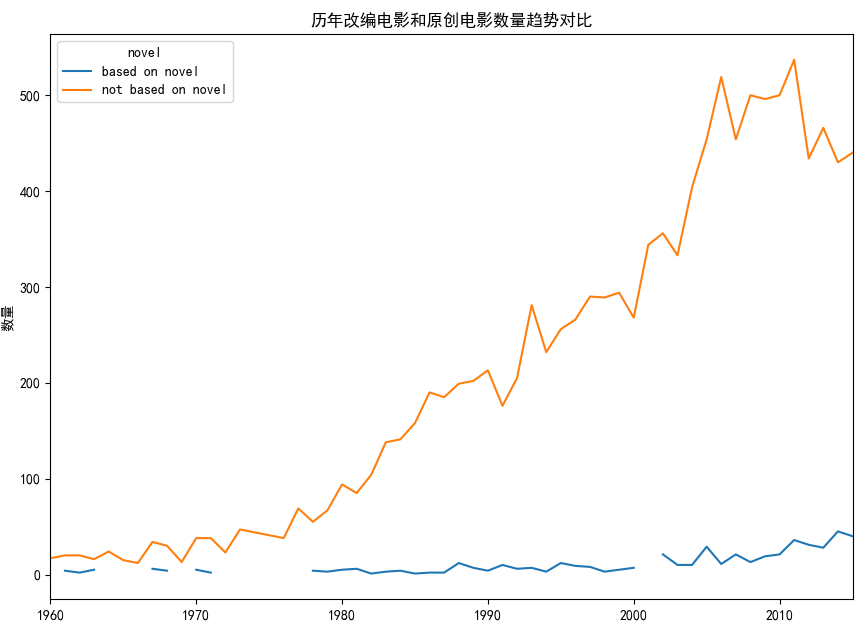
总体来讲,电影公司还是会选择拍摄原创剧本的电影,仅仅会选择少量的小说进行翻拍。由于小说剧本的限制或者是导演对于重现小说情节场景把握不住方向等原因,一般导演不会直接选择已有的小说等剧本,更多的选择是新编剧本。随着时间的推移,这种选择导致的对比效果越来越明显。
movies_novel.groupby(['novel','release_year'])['vote_average'].mean().unstack('novel').plot(kind='line')
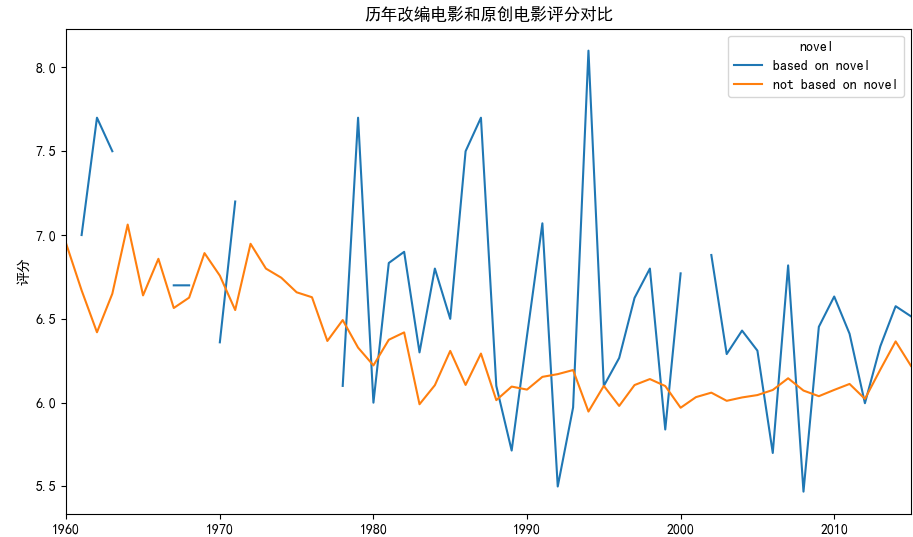
也许是因为小说自身的经典,再加上导演完美的呈现,我们会发现,通过改编的电影评分会比原创电影要高一些。改编电影评分起伏较大,这个应该是跟电影还原小说剧情、内涵有很大关系,但是总体还是比原创的电影略胜一筹。
4. 寻找最佳导演
director={} # 构造字典格式生成云图 movies_director = movies_director.groupby('director')['id'].apply(lambda x:x.count()) # 计算每一位导演执导电影的数量 for i in range(len(movies_director)): director[movies_director.index[i]] = float(movies_director.ix[i]) # {A:xx, B:xx, C:xx} wordcloud=WordCloud(font_path='C:/Users/Nekyo/tools/SOFTWARE/Anaconda2/Library/lib/fonts/songti.ttf', width=1000,height=600,background_color='white') # 云图使用的汉字字体,自带的字体库没有需要下载 wordcloud.fit_words(director) plt.imshow(wordcloud)

云图的优势在于很容易就能看到需要的信息,斯皮尔伯格等几位名导拍摄的电影远多于其他导演。
movies_director = movies_director[(movies_director['director']=='Ridley Scott') | (movies_director['director']=='Steven Spielberg') |
(movies_director['director']=='Clint Eastwood') |(movies_director['director']=='Woody Allen')]
movies_director.groupby(['director','release_year'])['revenue_adj'].sum().unstack('director').plot(kind='bar', stacked=True)
movies_director.groupby(['genres','director','release_year'])['revenue_adj'].sum().unstack(['genres']).plot(kind='bar', stacked=True)
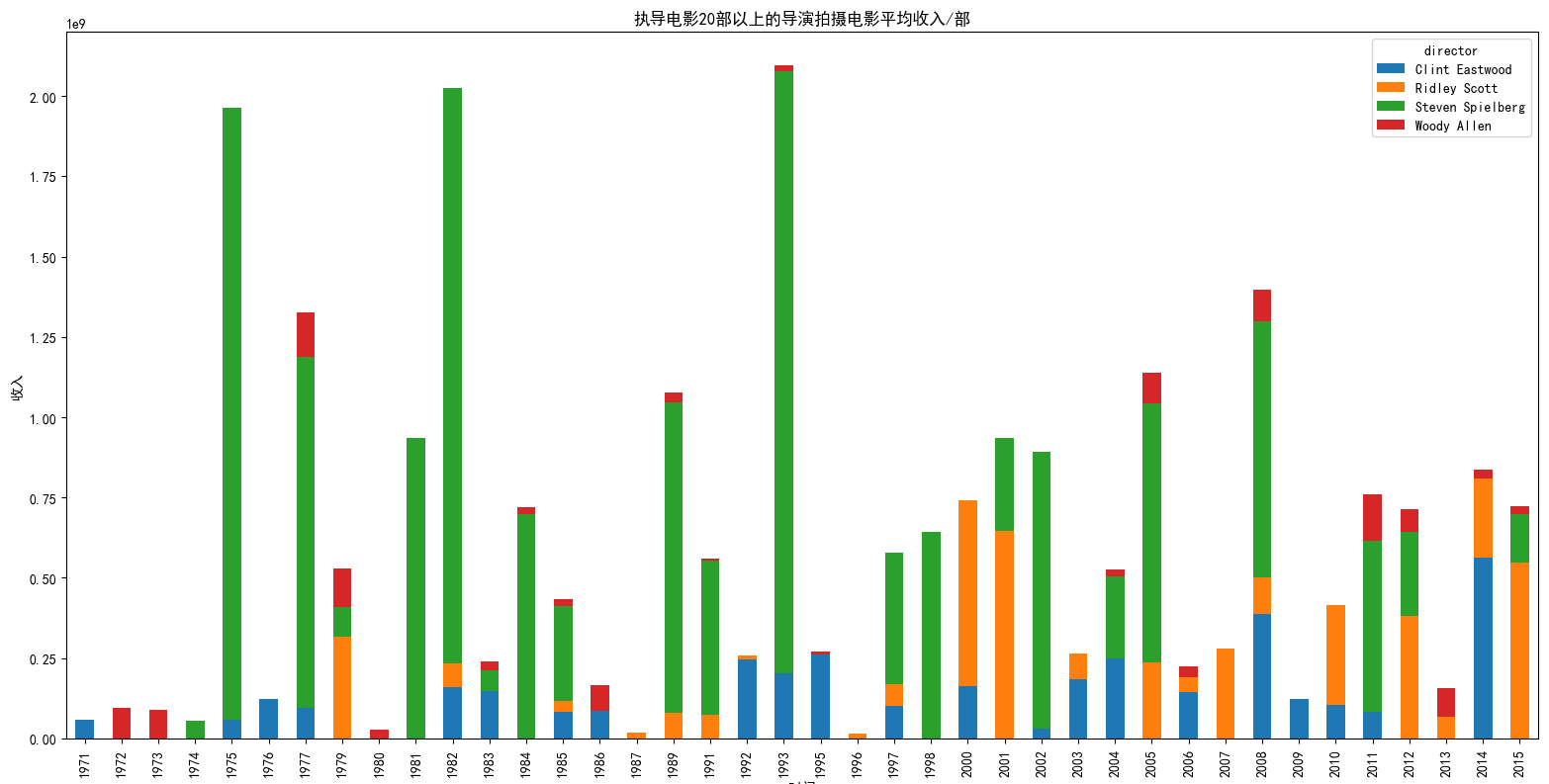
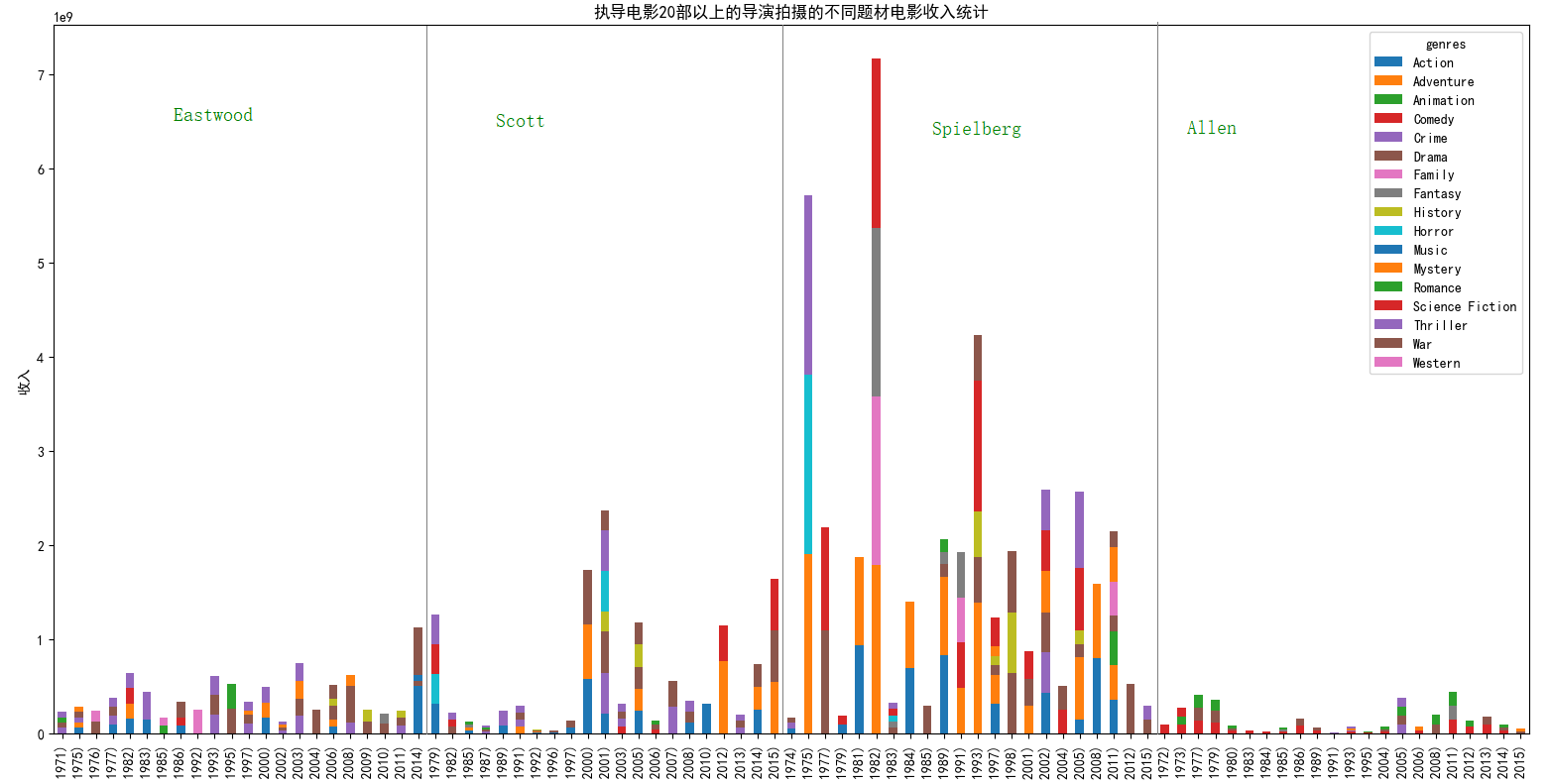
在这个数据集中,我发现有4名导演执导的电影在20部以上,但是相较于其他三位来讲,斯皮尔伯格无异于更出色。如果我们计算历年电影所带来的收入,或者是平均计算每一部影片的收入,斯皮尔伯格确确实实将其他三位远远抛在了后面;至于他们四位涉足的不同题材的电影,通过上面的收入对比,第三幅小图表现出的结果——斯皮尔伯格无疑是碾压性的。也就是说,观众还是更买斯皮尔伯格的账,他绝大部分的电影票房都超过了其他电影,唯一我们能一眼看出来的就只有2001和2015年输给了Ridley Scott的《汉尼拔(Hannibal)》和《火星救援(The Martian)》,但是仍然影响不了斯皮尔伯格在电影票房的霸主地位。
movies_director = movies_director[movies_director['director']=='Steven Spielberg'] # 只看Steven Spielberg movies_director = pd.merge(movies_director,movies_genres,how='left') # 分析Steven Spielberg拍摄的电影题材 movies_spielberg = movies_director[['director','original_title','vote_average','revenue_adj']].drop_duplicates() movies_spielberg.plot(x='vote_average',y='revenue_adj',kind='scatter') for i in range(len(movies_spielberg)): plt.text(movies_spielberg.iloc[i]['vote_average'], movies_spielberg.iloc[i]['revenue_adj'], movies_spielberg.iloc[i]['original_title'], ha='center', va='bottom') # 标记
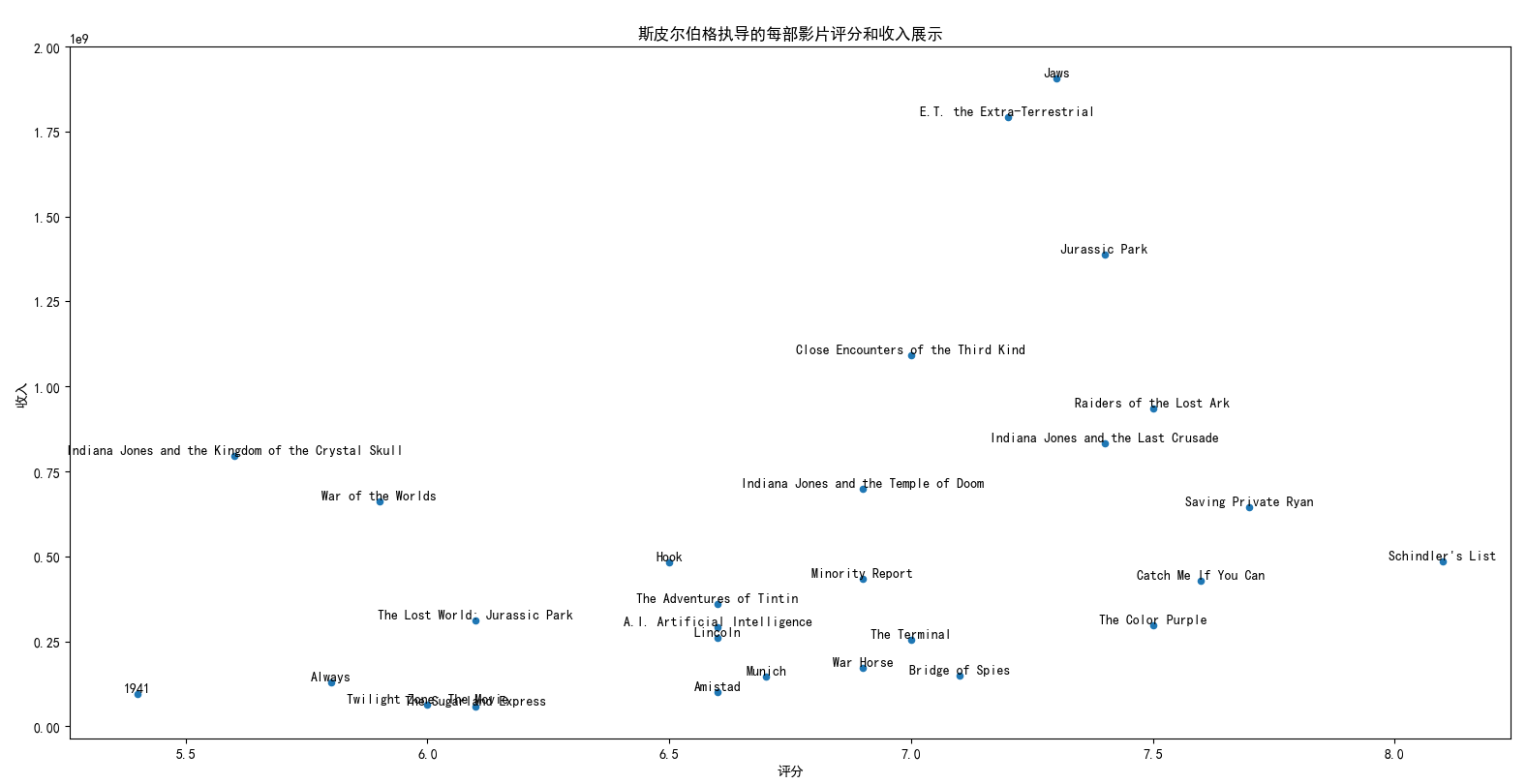
至于斯皮尔伯格执导的电影,当属经典中的经典,无论是票房神话《大白鲨(Jaws)》、《E.T. 外星人(E.T. the Extra-Terrestrial)》、《侏罗纪公园(Jurassic Park)》,还是评分超神的《辛德勒名单(Schindler's List)》都给我们留下了深刻的印象,也是其他导演难以逾越的高峰,更是电影史上灿烂的瑰宝。
统计分析
提个问题,如果单独把斯皮尔伯格执导的电影拿出来分析,他是否代表了这个行业的平均水平?其实这问题很简单,明显高于啊。那么我们用统计的思想从电影评分和收入来分析下。我把整个数据集看作一个整体,斯皮尔伯格执导的电影看作一个独立样本(这里不是随机的哈),我们可以计算出整体的均值,样本的均值、方差,并且样本的数量时28<30,因此我选择单尾t检验来检验上述猜测。
零假设H0:斯皮尔伯格代表了这个行业的平均水平,![]() ;对立假设H1:斯皮尔伯格高于这个行业的平均水平,
;对立假设H1:斯皮尔伯格高于这个行业的平均水平,![]()
movies = movies[movies['revenue_adj']>0] movies_spielberg = movies_director[movies_director['director']=='Steven Spielberg'] sp_mean=movies_spielberg['vote_average'].mean() mo_mean=movies['vote_average'].mean() sd = np.sqrt(((movies_spielberg['vote_average'] - movies_spielberg['vote_average'].mean())**2).sum()/(28-1)) # 求标准偏差,这里不能直接用np.var() t=(sp_mean-mo_mean)/(sd/np.sqrt(28-1))
取显著性水平alpha=0.05,自由度v=28-1=27,查t表格得到t值为1.703,而我们计算出来的结果如下:
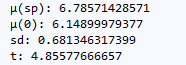
计算得到的t统计量为4.85578>1.703,因此拒绝零假设,认为斯皮尔伯格的电影评分与整个行业的平均水平显著性不同,要高一些。
使用更高级的方法,引入scipy库的统计方法,对评分字段进行单样本检验,得到的结果:
print ttest_1samp(a=movies_spielberg['vote_average'], popmean=mo_mean)
![]()
跟上面方法分析的结果一致,p值要比0.05小,位于拒绝域内,接受对立假设。同样针对电影的收入,也可以用同样的方法检验,这里不再赘述。
结论
尽管这个样本不能代表整个电影数据,但是通过这样的分析我们能够了解大概的趋势。如果你拥有一个电影公司想制作一部电影并且想收获不菲的票房成绩,一些小众题材的剧本就不要选择了,最好选择时下热门的动作、喜剧类电影;尽量选择原创剧本,除非你要改编的剧本本身就特别好,比如复仇者联盟漫画系列,否则还是建议你请一个好的编剧;最后一定要记住,一个优秀的导演至为重要,用现在影视行业流行的话来讲,大IP呀!想好怎么做了吗,Good luck!















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









