









算法介绍
Softmax 回归(或多项逻辑回归)是将逻辑回归推广到我们想要处理多个类的情况。 在逻辑回归中,我们假设标签是二元的: y ( i ) ∈ { 0 , 1 } y^{(i)} \in \{0,1\} y(i)∈{0,1},我们使用这样的分类器来区分两种手写数字。 Softmax 回归允许我们处理 y ( i ) ∈ { 0 , 1 , . . . , C } y^{(i)} \in \{0,1,...,C\} y(i)∈{0,1,...,C}其中 C C C是类的数量。
数据集格式

模型
多组回归配合Softmax函数
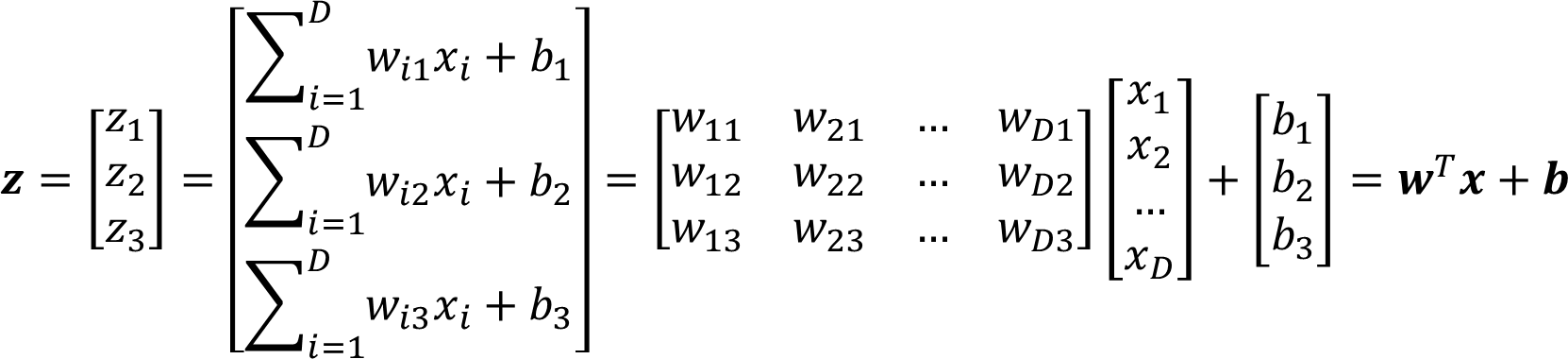
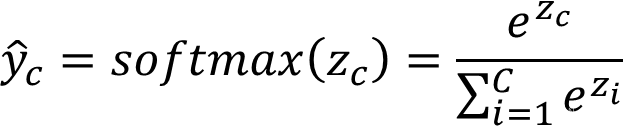
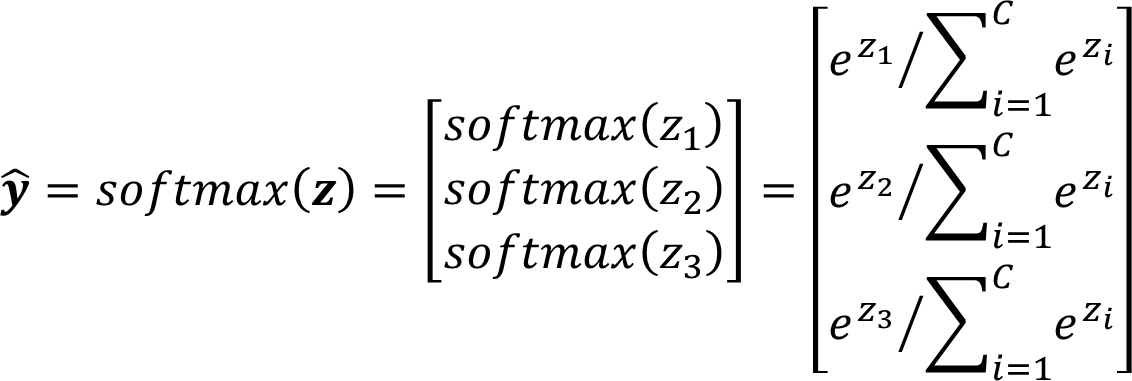
Softmax 函数定义
def softmax(z):
hat_z = [0]*len(z)
for i in range(len(z)):
hat_z[i] = np.exp(z[i])/np.sum(np.exp(z))
return hat_z
y 函数计算
z = np.dot(W[:,1:],x[1:]) + np.dot(W[:,0],x[0])
hat_y = softmax(z)
Loss 和 Cost 函数
Loss Function(Cross Entropy):
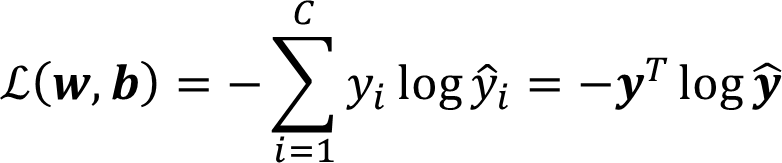
Cost Function:
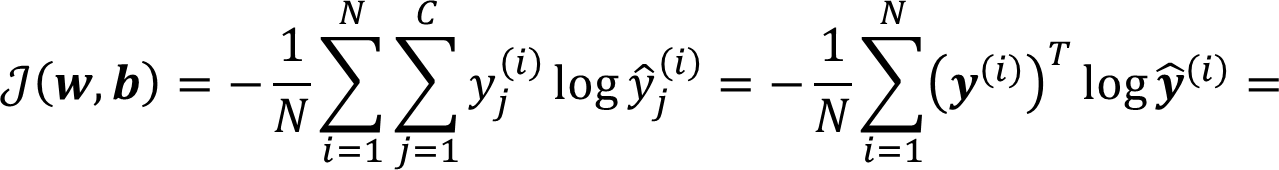
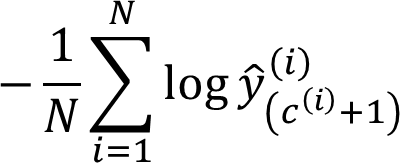
Cost 代码部分
j = j - np.dot(Y[i],np.log(hat_y).T)
梯度
W矩阵梯度计算:
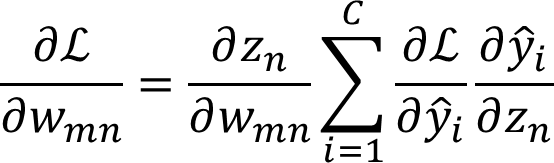
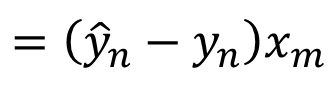
常数项梯度计算:
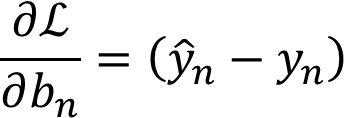
梯度代码部分
G 初始为 [C,D+1]的0矩阵,包含W和b的所有参数:
G[:,1:] = G[:,1:] + np.array(hat_y - Y[i]).reshape((3,1)).dot(np.array(x[1:]).reshape((1,3))) ###### Gradient
G[:,0] = G[:,0] + (hat_y - Y[i])
代码汇总
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
def softmax(z):
hat_z = [0]*len(z)
for i in range(len(z)):
hat_z[i] = np.exp(z[i])/np.sum(np.exp(z))
return hat_z
def cost_gradient(W, X, Y, n):
G = np.zeros(W.shape)
j = 0
for i in range(n):
x = X[i]
z = np.dot(W[:,1:],x[1:]) + np.dot(W[:,0],x[0])
hat_y = softmax(z)
G[:,1:] = G[:,1:] + np.array(hat_y - Y[i]).reshape((3,1)).dot(np.array(x[1:]).reshape((1,3))) ###### Gradient
G[:,0] = G[:,0] + (hat_y - Y[i])
j = j - np.dot(Y[i],np.log(hat_y).T)###### cost with respect to current W
G = G/n
j = j/n
return (j, G)
def train(W, X, Y, n, lr, iterations):
J = np.zeros([iterations, 1])
for i in range(iterations):
(J[i], G) = cost_gradient(W, X, Y, n)
W = W - lr*G
print("epoch:",i,"error:",error(W, X, Y))
return (W,J)
def error(W, X, Y):
Y_hat = []
for i in range(n):
x = X[i]
z = np.dot(W[:, 1:],x[1:]) + np.dot(W[:, 0], x[0])
Y_hat.append(softmax(z))###### Output Y_hat by the trained model
pred = np.argmax(Y_hat, axis=1)
label = np.argmax(Y, axis=1)
return (1-np.mean(np.equal(pred, label)))
iterations = 500###### Training loops
lr = 1e-1###### Learning rate
data = np.loadtxt('SR.txt', delimiter=',')
n = data.shape[0]
X = np.concatenate([np.ones([n, 1]),
np.expand_dims(data[:,0], axis=1),
np.expand_dims(data[:,1], axis=1),
np.expand_dims(data[:,2], axis=1)],
axis=1)
Y = data[:, 3].astype(np.int32)
c = np.max(Y)+1
Y = np.eye(c)[Y]
W = np.random.random([c,X.shape[1]])
b = np.random.random(X.shape[1])
(W,J) = train(W, X, Y, n, lr, iterations)
plt.figure()
plt.plot(range(iterations), J)
plt.show()
print(error(W,X,Y))
需要数据集的同学私我
















 3696
3696











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











