







总算是把这本《特征工程入门与实践》的笔记?给整理完了,这一篇是最后一篇了,后续我会把3篇文章都汇总到一起,同时数据集和代码也会在公众号后台共享,大家可以回复 ”特征工程“ 来获取呗。
? 目录
-
? 特征理解
-
? 特征增强
-
? 特征构建
-
✅ 特征选择
-
? 特征转换
-
? 特征学习
? 05 特征转换
经过了上面几个环节的“洗礼”,我们来到特征转换的环节,也就是使用源数据集的隐藏结构来创建新的列,常用的办法有2种:PCA和LDA。
✅ PCA:
PCA,即主成分分析(Principal Components Analysis),是比较常见的数据压缩的办法,即将多个相关特征的数据集投影到相关特征较少的坐标系上。也就是说,转换后的特征,在解释性上就走不通了,因为你无法解释这个新变量到底具有什么业务逻辑了。
PCA的原理这里就不展开来讲了,太多的文章把它讲得十分透彻了。这里主要是复现一下PCA在sklearn上的调用方法,一来继续熟悉下Pipeline的使用,二来理解一下PCA的使用方法。
# 导入相关库
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.decomposition import PCA
# 导入数据集
iris = load_iris()
iris_x, iris_y = iris.data, iris.target
# 实例化方法
pca = PCA(n_components=2)
# 训练方法
pca.fit(iris_x)
pca.transform(iris_x)[:5,]
# 自定义一个可视化的方法
label_dict = {i:k for i,k in enumerate(iris.target_names)}
def plot(x,y,title,x_label,y_label):
ax = plt.subplot(111)
for label,marker,color in zip(
range(3),('^','s','o'),('blue','red','green')):
plt.scatter(x=x[:,0].real[y == label],
y = x[:,1].real[y == label],
color = color,
alpha = 0.5,
label = label_dict[label]
)
plt.xlabel(x_label)
plt.ylabel(y_label)
leg = plt.legend(loc='upper right', fancybox=True)
leg.get_frame().set_alpha(0.5)
plt.title(title)
# 可视化
plot(iris_x, iris_y,"original iris data","sepal length(cm)","sepal width(cm)")
plt.show()
plot(pca.transform(iris_x), iris_y,"Iris: Data projected onto first two PCA components","PCA1","PCA2")
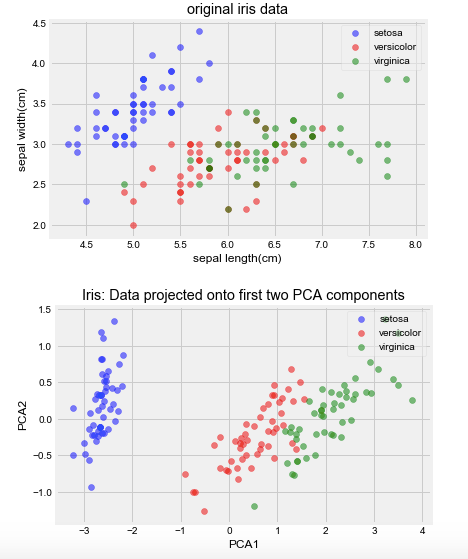
以上是PCA在sklearn上的简单调用和效果展示,另外,作者提出了一个很有意思的问题:
一般而言,对特征进行归一化处理后会对机器学习算法的效果有比较明显的帮助,但为什么在书本的例子却是相反呢?
给出的解释是:在对数据进行缩放后,列与列之间的协方差会更加一致,而且每个主成分解释的方差会变得分散,而不是集中在某一个主成分上。所以,在实际操作的时候,都要对缩放的未缩放的数据进行性能测试才是最稳妥的哦。
✅ LDA:
LDA,即线性判别分析(Linear Discriminant Analysis),它是一个有监督的算法(哦对了, PCA是无监督的),一般是用于分类流水线的预处理步骤。与PCA类似,LDA也是提取出一个新的坐标轴,将原始的高维数据投影到低维空间去,而区别在于LDA不会去专注数据之间的方差大小,而是直接优化低维空间,以获得最佳的类别可分性。
# LDA的使用
# 导入相关库
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
# 实例化LDA模块
lda = LinearDiscriminantAnalysis(n_components=2)
# 训练数据
x_lda_iris = lda.fit_transform(iris_x, iris_y)
# 可视化
plot(x_lda_iris, iris_y, "LDA Projection", "LDA1", "LDA2")
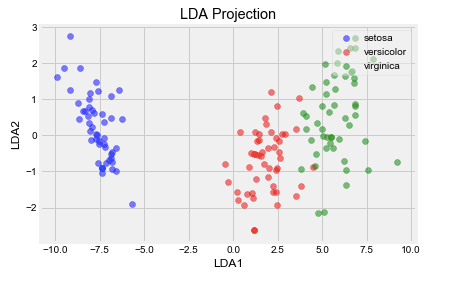
? 06 特征学习
来到最后一章了,这章的主题是“以AI促AI”。看起来还蛮抽象的,反正我是觉得有点奇怪,特征学习算法是非参数方法,也就是不依赖数据结构而构建出来的新算法。
? 数据的参数假设
参数假设指的是算法对数据形状的基本假设。比如上一章的PCA,我们是假设:
原始数据的形状可以被(特征值)分解,并且可以用单个线性变换(矩阵计算)表示。
而特征学习算法,就是要去除这个“假设”来解决问题,因为这算法不会依赖数据的形状,而是依赖于随机学习(Stochastic Learning),指的是这些算法并不是每次输出相同的结果,而是一次次按轮(epoch)去检查数据点以找到要提取的最佳特征,并且可以拟合出一个最优的解决方法。
而在特征学习领域,有两种方法是比较常用的,也是下面来讲解的内容:受限玻尔兹曼机(RBM)和词嵌入。
? 受限玻尔兹曼机(RBM)
RBM是一种简单的深度学习架构,是一组无监督的特征学习算法,根据数据的概率模型学习一定数量的新特征,往往使用RBM之后去用线性模型(线性回归、逻辑回归、感知机等)的效果极佳。
从概念上说,RBM是一个浅层(2层)的神经网络,属于深度信念网络(DBN,deep belief network)算法的一种。它也是一种无监督算法,可以学习到的 特征数量只受限于计算能力,它可能学习到比原始要少或者多的特征,具体要学习的特征数量取决于要解决的问题。
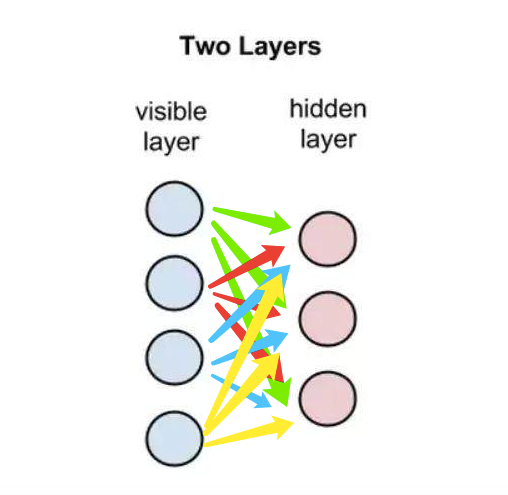
“受限”的说法是因为它只允许层与层之间的连接(层间连接),而不允许同一层内的节点连接(层内连接)。
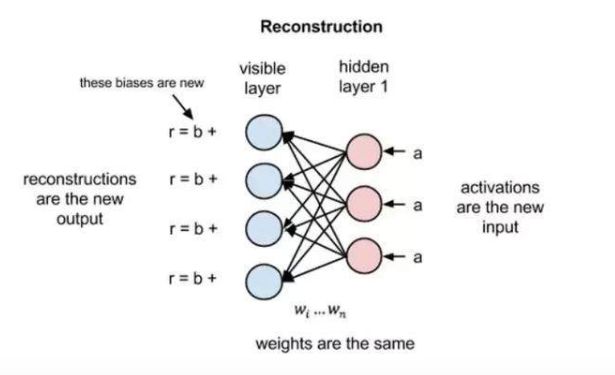
在这里需要理解一下“重建”(Reconstruction),也就是这个操作,使得在不涉及更深层网络的情况下,可见层(输入层)和隐含层之间可以存在数次的前向和反向传播。
在重建阶段,RBM会反转网络,可见层变成了隐含层,隐含层变成了可见层,用相同的权重将激活变量a反向传递到可见层,但是偏差不一样,然后用前向传导的激活变量重建原始输入向量。RBM就是用这种方法来进行“自我评估”的,通过将激活信息进行反向传导并获取原始输入的近似值,该网络可以调整权重,让近似值更加接近原始输入。
在训练开始时,由于权重是随机初始化的(一般做法),近似值与真实值的差异可能会极大的,接下来就会通过反向传播的方法来调整权重,最小化原始输入与近似值的距离,一直重复这个过程,直到近似值尽可能接近原始输入。(这个过程发生的次数叫 迭代次数 )
大致的原理就是上面的说法了,更加详细的解释可以自行百度哦。下面我们来讲讲RBM在机器学习管道中的应用,我们还是使用MNIST数据集,这个数据集在之前讲Keras的时候
# RBM的使用
# 我们使用MNIST数据集来讲解
# 导入相关库
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.linear_model import LogisticRegression
from sklearn.neural_network import BernoulliRBM
from sklearn.pipeline import Pipeline
# 导入数据集
images = np.genfromtxt('./data/mnist_train.csv', delimiter=',')
print(images.shape)
# 划分数据
images_x, images_y = images[:,1:], images[:,0]
# 缩放特征到0-1
images_x = images_x/255.
# 用RBM学习新特征
rbm = BernoulliRBM(random_state=0)
lr = LogisticRegression()
# 设置流水线的参数范围
params = {'clf__C':[1e-1, 1e0, 1e1],
'rbm__n_components':[100, 200]
}
# 创建流水线
pipeline = Pipeline([('rbm', rbm),
('clf', lr)])
# 实例化网格搜索类
grid = GridSearchCV(pipeline, params)
# 拟合数据
grid.fit(images_x, images_y)
# 返回最佳参数
grid.best_params_, grid.best_score_
? 词嵌入
在NLP领域应用极为广泛了,它可以将字符串(单词或短语)投影到n维特征集中,以便理解上下文和措辞的细节,我们可以使用sklearn中的
CountVectorizer 和 TfidfVectorizer 来将这些字符串进行转为向量,但这只是一些单词特征的集合而已,为了理解这些特征,我们更加要关注一个叫 gensim的包。
常用的词嵌入方法有两种:Word2vec和GloVe。
Word2vec: Google发明的一种基于深度学习的算法。Word2vec也是一个浅层的神经网络,含有输入层、隐含层和输出层,其中输入层和输出层的节点个数一样。
GloVe: 来自斯坦福大学的算法,通过一系列矩阵统计进行学习。
词嵌入的应用很多,比如信息检索,意思是当我们输入关键词时,搜索引擎可以回忆并准确返回和关键词匹配的文章或者新闻。
















 397
397











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









