






 本文介绍了Python中pandas和numpy在数据分析中的应用,通过实例演示了一维和二维数据处理,包括数组操作、Series和DataFrame的使用,以及如何进行销售数据清洗、建模和分析。以朝阳医院2018年销售数据为例,详细讲解了数据处理流程和关键指标计算。
本文介绍了Python中pandas和numpy在数据分析中的应用,通过实例演示了一维和二维数据处理,包括数组操作、Series和DataFrame的使用,以及如何进行销售数据清洗、建模和分析。以朝阳医院2018年销售数据为例,详细讲解了数据处理流程和关键指标计算。
本文首先将会介绍Python在数据分析领域最常见的两个包:pandas和numpy的使用,然后通过一个简单的案例巩固前面的内容。
目录
一、pandas和numpy的使用
二、案例解析:销售数据分析
文末领取全套Python系统学习籽料
一、pandas和numpy的使用
#导入numpy包
import numpy as np
#导入pandas包
import pandas as pd
1、一维数据分析
numpy:array
- a = np.array([2,3,4,5]) #定义:一维数组array,参数传入的是一个列表[2,3,4,5]
- a[0] #查询
- a[1:3] #切片访问:获取到的是序号从1到3的元素
- a.dtype #查看数据类型dtype
- a.mean()#统计计算:平均值
- a.std()#统计计算:标准差
- b=a*4#向量化运行:乘以标量

pandas,Series,比numpy多了一个索引功能。
- 定义:stockS=pd.Series([54.74,190.9,173.14,1050.3,181.86,1139.49],index=[‘腾讯’, ‘阿里巴巴’, ‘苹果’, ‘谷歌’, ‘Facebook’, ‘亚马逊’])
- stockS.describe()#获取描述统计信息

- stockS.iloc[0]#iloc属性用于根据索引获取值
- stockS.loc[‘腾讯’]#loc属性用于根据索引获取值

- stockS2=stockS+stockS1#向量化运算:向量相加

- 对于缺失值,可以用
- stockS2.dropna()#方法1:删除缺失值
- stockS2=stockS.add(stockS1,fill_value=0)#方法2:将缺失值进行填充

2、二维数据分析
numpy:array
- 定义:a=np.array([[1,2,3,4],[5,6,7,8],[9,10,11,12]])
- 查询,获取行号是0,列号是2的元素:a[0,2]
- 查询:获取第一行:a[0,:]
- 查询:获取第一列:a[:,0]

- a.mean()#计算整个数组的平均值
- a.mean(axis=1)#计算计算每一行的平均值
- a.mean(axis=0)#计算计算每一列的平均值

pandas:DataFrame
- 定义:先定义有序字典,再将字典传入数据框。或直接定义


直接定义
- iloc属性用于根据位置获取值:
- 查询第1行第2列的元素:salesDf.iloc[0,1]
- 查询第一行所有列:salesDf.iloc[0,:]
- 查询第一列所有行:salesDF.iloc[:,0]
- loc属性用于根据索引获取值:
- salesDf.loc[0,‘商品编码’]
- 查询第一行:sales.Df.loc[0,:]
- 查询第一列:sales.Df.loc[:,0]
- 通过切片功能,获取指定范围的列:salesDf.loc[:,‘购药时间’:‘销售数量’]
- 通过条件判断查询

文末领取全套Python系统学习籽料
- 数据集描述统计信息


二、案例解析:销售数据分析
以朝阳医院2018销售数据为例:
https://pan.baidu.com/link/zhihu/7Vh1zUuNhUiVanZld3T6JWdFcFZYl2XwZY10==(安全链接,放心点击)
这部分,通过实际案例分析应用前面学习的到的内容。
数据分析步骤
- 提出问题:数据分析的目的,为了解决实际问题
- 理解数据:采集数据,导入数据到Python,查看数据集信息了解数据
- 数据清洗:也叫数据预处理,
- 构建模型:对清洗后的数据进行整理
- 数据可视化:用图表方式展示给他人
**1.提出问题:**想知道朝阳医院2018年月均消费次数、月均消费金额、客单价

。需要知道这些数据具体是指什么。
2、理解数据:现在我们已经有了Excel表格,接下来就是要导入到Python中。

1)第一列是购药时间;2)第二列是社保卡号,如果存在几行卡号一样,说明有多次购买记录;3)第三列是商品编码;4)第四列是商品名称;5)第五列是销售数量;6)第六列是应收金额;7)第七列是实收金额(可能有折扣)
3、清洗数据:
一般有六步:选择子集-列名重命名-处理缺失值-数据类型转换-数据排序-异常值处理
- **选择子集:**有时候原始数据太大,有些数据不需要处理,我们可以通过选择子集,筛选出想要处理的部分数据。(本案例不需要选择子集)
**代码:**使用loc切片 subSalesDf=salesDf.loc[0:4,‘购药时间’:‘销售数量’] 选择15行,15列。
- 列名重命名:rename

- 缺失数据处理:dropna
从表格数据可以看到,销售时间和社保卡号不能为空,不然不能定位到具体的客户,因此要将这两列的缺失值删除。删除前后,数据的行列数没有变化,可以看出这两列没有缺失值

删除缺失值,使得索引序号不连续,需要用reset_index重置索引salesDf=salesDf.reset_index(drop=True)
- 数据类型转换:astype 表格中的销售数量、应收金额、实收金额应为数值,但是我们导入的时候,用了字符串类型,需要转换数字类型。

销售时间列中,不需要星期几的内容,只需要日期就行了,需要拆分字符串,使用split


得到了2018-01-01这样的数据,还是一个字符串,我们还想将数据转换成日期格式的数据
文末领取全套Python系统学习籽料

转变数据格式后不要忘记删除重复值,这里可以看到删除重复值后,行数减少了
- 排序:sort_values

- 异常值处理:从上面的排序结果可以看出,销售数量、应收金额、实收金额为负数,这显然是不合理的异常值,首先我们获取每一类的描述统计信息,看看各列是否存在异常值。然后在对异常值进行处理。


首先筛选正常值,再利用筛选出来的数据删除异常值
**4、数据建模:**计算月均消费次数、月均消费金额、客单价。
业务指标1:月均消费次数=总消费次数/月份数


业务指标2:月均消费金额=总消费金额/月份数

业务指标3:客单价=总消费金额 / 总消费次数

以上就是今天的全部内容分享,觉得有用的话欢迎点赞收藏哦!
Python经验分享
学好 Python 不论是用于就业还是做副业赚钱都不错,而且学好Python还能契合未来发展趋势——人工智能、机器学习、深度学习等。
小编是一名Python开发工程师,自己整理了一套最新的Python系统学习教程,包括从基础的python脚本到web开发、爬虫、数据分析、数据可视化、机器学习等。如果你也喜欢编程,想通过学习Python转行、做副业或者提升工作效率,这份【最新全套Python学习资料】 一定对你有用!
小编为对Python感兴趣的小伙伴准备了以下籽料 !
对于0基础小白入门:
如果你是零基础小白,想快速入门Python是可以考虑培训的!
- 学习时间相对较短,学习内容更全面更集中
- 可以找到适合自己的学习方案
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、机器学习、Python量化交易等学习教程。带你从零基础系统性的学好Python!
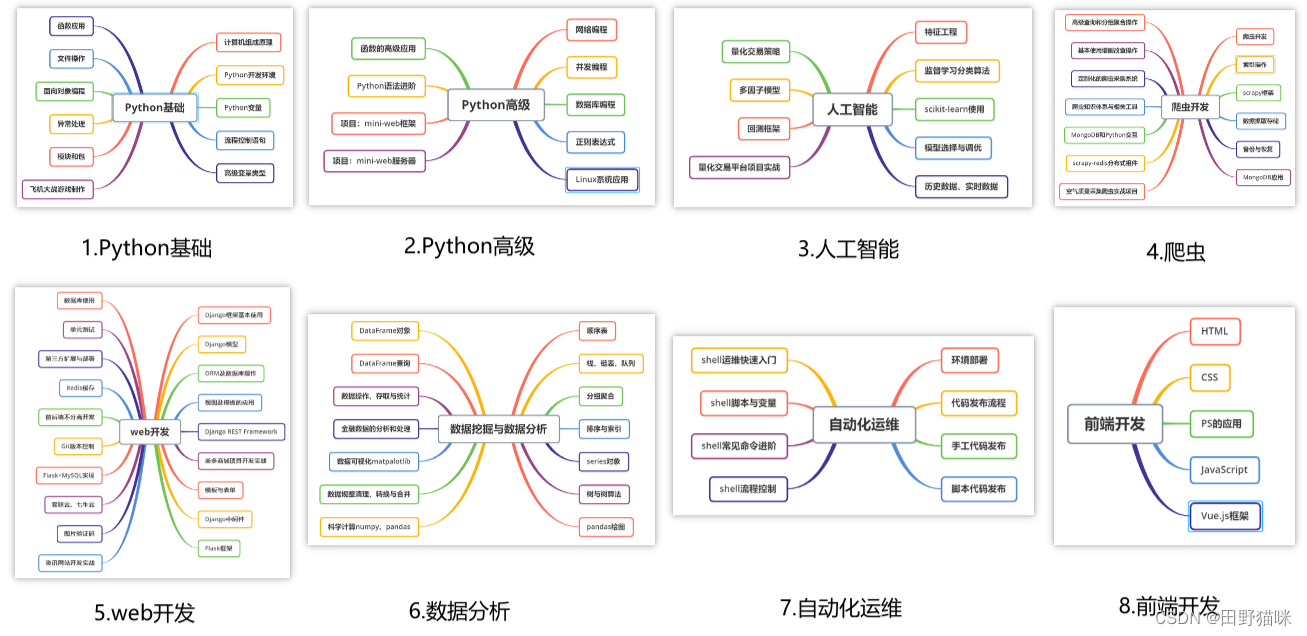
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。
四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

五、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


最新全套【Python入门到进阶资料 & 实战源码 &安装工具】(安全链接,放心点击)
我已经上传至CSDN官方,如果需要可以扫描下方官方二维码免费获取【保证100%免费】

*今天的分享就到这里,喜欢且对你有所帮助的话,记得点赞关注哦~下回见 !















 902
902











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









