






QAnything (Question and Answer based on Anything) 是致力于支持任意格式文件或数据库的本地知识库问答系统,可断网安装使用。
您的任何格式的本地文件都可以往里扔,即可获得准确、快速、靠谱的问答体验。
目前已支持格式: PDF,Word(doc/docx),PPT,Markdown,Eml,TXT,图片(jpg,png等),网页链接,更多格式,敬请期待…
-
特点
-
- 数据安全,支持全程拔网线安装使用。
- 支持跨语种问答,中英文问答随意切换,无所谓文件是什么语种。
- 支持海量数据问答,两阶段向量排序,解决了大规模数据检索退化的问题,数据越多,效果越好。
- 高性能生产级系统,可直接部署企业应用。
- 易用性,无需繁琐的配置,一键安装部署,拿来就用。
- 支持选择多知识库问答。
-
架构
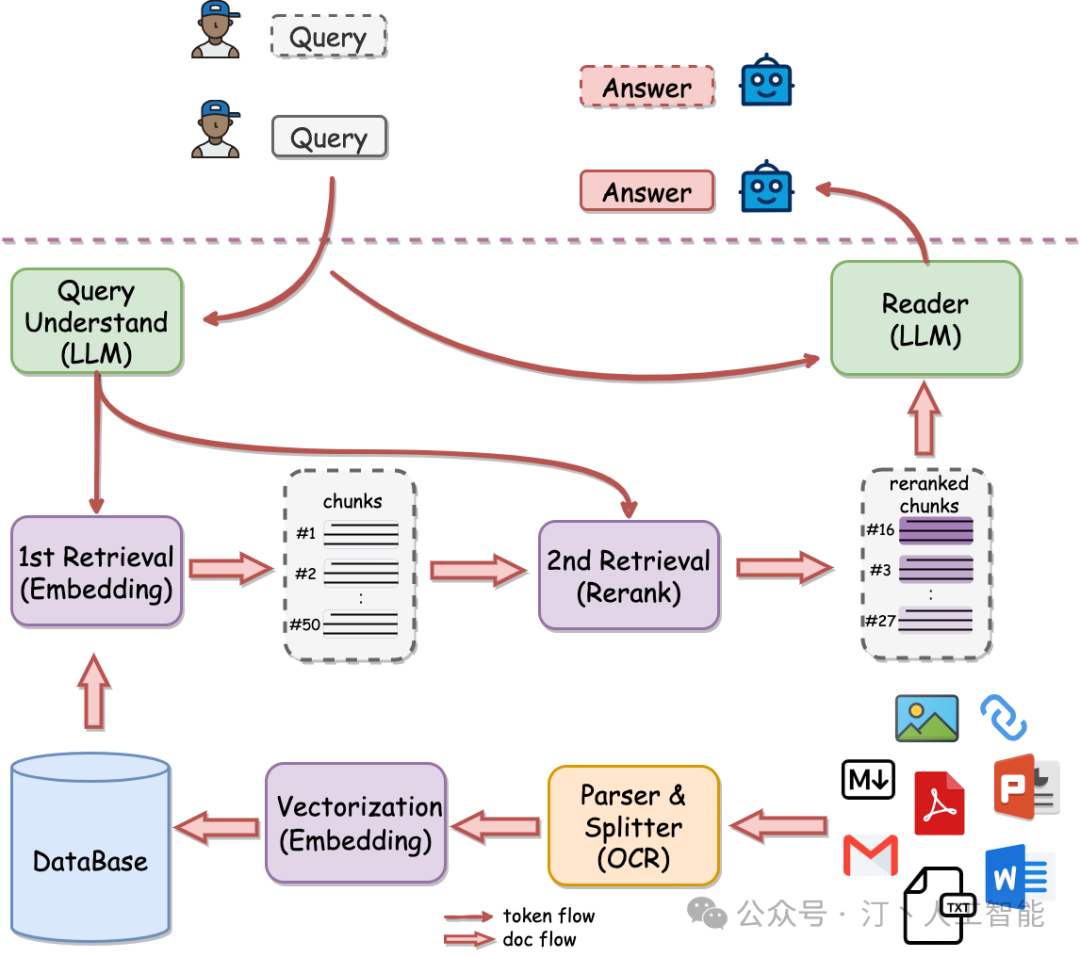
1.两阶段检索优势
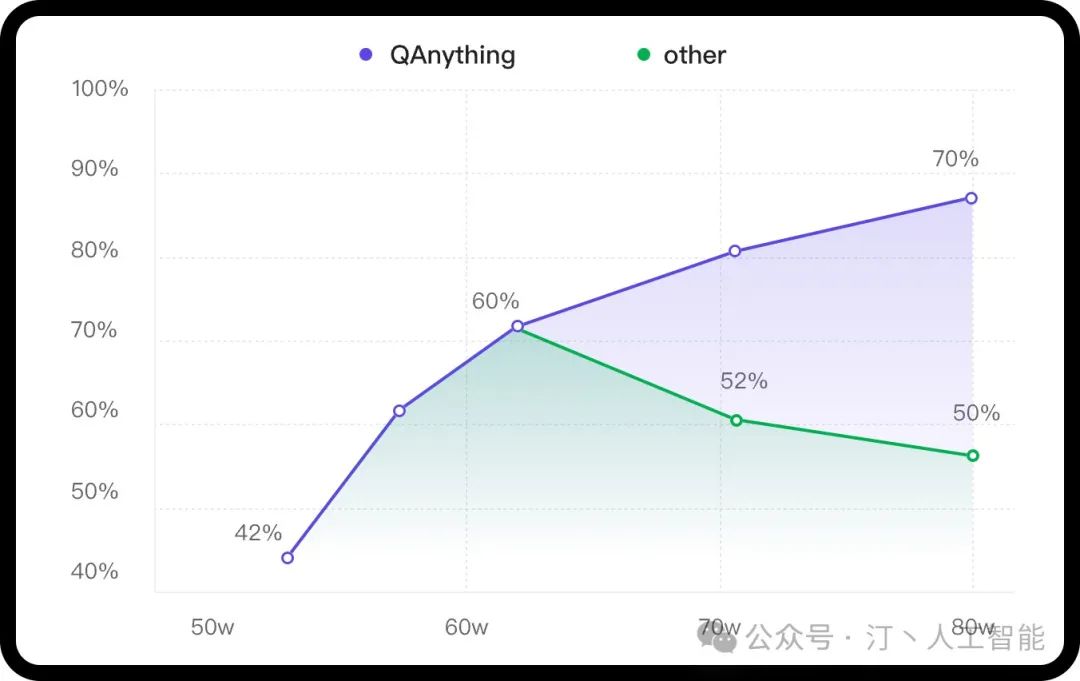
知识库数据量大的场景下两阶段优势非常明显,如果只用一阶段embedding检索,随着数据量增大会出现检索退化的问题,如下图中绿线所示,二阶段rerank重排后能实现准确率稳定增长,即数据越多,效果越好。
BCEmbedding是由网易有道开发的中英双语和跨语种语义表征算法模型库,其中包含 EmbeddingModel和 RerankerModel两类基础模型。EmbeddingModel专门用于生成语义向量,在语义搜索和问答中起着关键作用,而 RerankerModel擅长优化语义搜索结果和语义相关顺序精排。
BCEmbedding作为有道的检索增强生成式应用(RAG)的基石,特别是在QAnything [github]中发挥着重要作用。QAnything作为一个网易有道开源项目,在有道许多产品中有很好的应用实践,比如有道速读和有道翻译。
QAnything使用的检索组件BCEmbedding有非常强悍的双语和跨语种能力,能消除语义检索里面的中英语言之间的差异, 从而实现:
-
强大的双语和跨语种语义表征能力【基于MTEB的语义表征评测指标】。
-
基于LlamaIndex的RAG评测,表现SOTA【基于LlamaIndex的RAG评测指标】。
-
双语和跨语种优势
-
- 现有的单个语义表征模型在双语和跨语种场景中常常表现不佳,特别是在中文、英文及其跨语种任务中。BCEmbedding充分利用有道翻译引擎的优势,实现只需一个模型就可以在单语、双语和跨语种场景中表现出卓越的性能。
EmbeddingModel支持中文和英文(之后会支持更多语种);RerankerModel支持中文,英文,日文和韩文。
1.1 一阶段检索(embedding)
| 模型名称 | Retrieval | STS | PairClassification | Classification | Reranking | Clustering | 平均 |
|---|---|---|---|---|---|---|---|
| bge-base-en-v1.5 | 37.14 | 55.06 | 75.45 | 59.73 | 43.05 | 37.74 | 47.20 |
| bge-base-zh-v1.5 | 47.60 | 63.72 | 77.40 | 63.38 | 54.85 | 32.56 | 53.60 |
| bge-large-en-v1.5 | 37.15 | 54.09 | 75.00 | 59.24 | 42.68 | 37.32 | 46.82 |
| bge-large-zh-v1.5 | 47.54 | 64.73 | 79.14 | 64.19 | 55.88 | 33.26 | 54.21 |
| jina-embeddings-v2-base-en | 31.58 | 54.28 | 74.84 | 58.42 | 41.16 | 34.67 | 44.29 |
| m3e-base | 46.29 | 63.93 | 71.84 | 64.08 | 52.38 | 37.84 | 53.54 |
| m3e-large | 34.85 | 59.74 | 67.69 | 60.07 | 48.99 | 31.62 | 46.78 |
| bce-embedding-base_v1 | 57.60 | 65.73 | 74.96 | 69.00 | 57.29 | 38.95 | 59.43 |
- 更详细的评测结果详见Embedding模型指标汇总。
1.2二阶段检索(rerank)
| 模型名称 | Reranking | 平均 |
|---|---|---|
| bge-reranker-base | 57.78 | 57.78 |
| bge-reranker-large | 59.69 | 59.69 |
| bce-reranker-base_v1 | 60.06 | 60.06 |
-
更详细的评测结果详见Reranker模型指标汇总
-
Reranker Evaluation Results
-
-
Task Type: Reranking
Model T2RerankingZh2En MMarcoRerankingZh2En AVG bge-reranker-base 63.94 63.79 63.87 bge-reranker-large 64.13 67.89 66.01 bce-reranker-base_v1 65.38 67.23 66.31 -
Summary on
zh-enModel Reranking AVG bge-reranker-base 63.87 63.87 bge-reranker-large 66.01 66.01 bce-reranker-base_v1 66.31 66.31 -
Summary on all langs:
['en', 'zh', 'en-zh', 'zh-en']Model Reranking (12) AVG (12) bge-reranker-base 59.04 59.04 bge-reranker-large 60.86 60.86 bce-reranker-base_v1 61.29 61.29 -
Task Type: Reranking
Model T2RerankingEn2Zh MMarcoRerankingEn2Zh AVG bge-reranker-base 60.45 64.41 62.43 bge-reranker-large 61.64 67.17 64.41 bce-reranker-base_v1 63.63 67.92 65.78 -
Summary on
en-zhModel Reranking AVG bge-reranker-base 62.43 62.43 bge-reranker-large 64.41 64.41 bce-reranker-base_v1 65.78 65.78 -
Task Type: Reranking
Model T2Reranking MMarcoReranking CMedQAv1 CMedQAv2 AVG bge-reranker-base 67.28 35.46 81.27 84.10 67.03 bge-reranker-large 67.60 37.64 82.14 84.18 67.89 bce-reranker-base_v1 70.25 34.13 79.64 81.31 66.33 -
Summary on
zhModel Reranking AVG bge-reranker-base 67.03 67.03 bge-reranker-large 67.89 67.89 bce-reranker-base_v1 66.33 66.33 -
Task Type: Reranking
Model AskUbuntuDupQuestions MindSmallReranking SciDocsRR StackOverflowDupQuestions AVG bge-reranker-base 54.70 28.48 67.09 37.55 46.96 bge-reranker-large 58.73 28.84 71.30 39.04 49.48 bce-reranker-base_v1 56.54 30.73 75.79 42.88 51.48 -
Summary on
enModel Reranking AVG bge-reranker-base 46.96 46.96 bge-reranker-large 49.48 49.48 bce-reranker-base_v1 51.48 51.48
-
-
- Language:
en - Language:
zh - Language:
en-zh - Language:
zh-en
- Language:
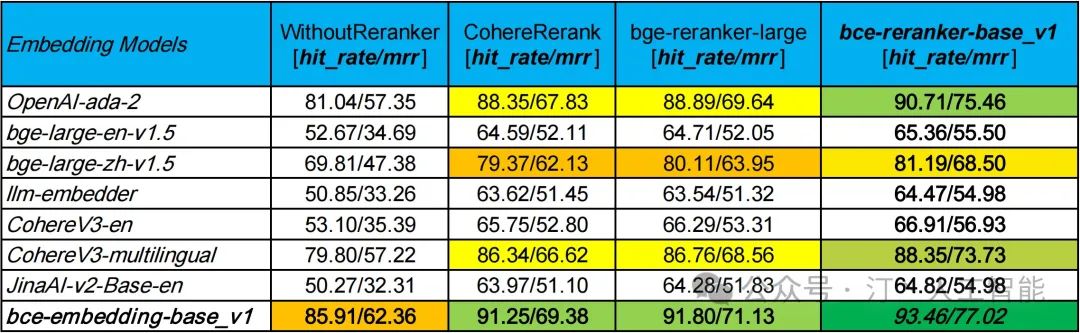
1.3 基于LlamaIndex的RAG评测(embedding and rerank)
NOTE:
- 在WithoutReranker列中,我们的bce-embedding-base_v1模型优于所有其他embedding模型。
- 在固定embedding模型的情况下,我们的bce-reranker-base_v1模型达到了最佳表现。
- bce-embedding-base_v1和bce-reranker-base_v1的组合是SOTA。
- 如果想单独使用embedding和rerank请参阅:BCEmbedding
2.LLM
开源版本QAnything的大模型基于通义千问,并在大量专业问答数据集上进行微调;在千问的基础上大大加强了问答的能力。 如果需要商用请遵循千问的license,具体请参阅:通义千问
- 🏄 在线试用QAnything
- 📚 在线试用有道速读
- 🛠️ 想只使用BCEmbedding(embedding & rerank)
- 📖 常见问题
2.1快速开始
必要条件
- For Linux|System| Required item | Minimum Requirement | Note | |---------------------------|--------------------------|---------------------------|-------------------------------------------------------------------------| |Linux | Single NVIDIA GPU Memory
or Double NVIDIA GPU Memory | >= 16GB
>= 11GB + 5G | NVIDIA 3090 x 1 recommended
NVIDIA 2080TI × 2 recommended | | | NVIDIA Driver Version | >= 525.105.17 | | | | CUDA Version | >= 12.0 | | | | Docker version | >= 20.10.5 | Docker install | | | docker compose version | >= 2.23.3 | docker compose install | - For Winodws 11 with WSL 2|System| Required item | Minimum Requirement | Note | |---------------------------|--------------------------|---------------------------|-----------------------------------------------------------------------------------------------| |Windows 11 with WSL 2| Single NVIDIA GPU Memory
or Double NVIDIA GPU Memory | >= 16GB
>= 11GB + 5G | NVIDIA 3090
NVIDIA 2080TI × 2 | | | | GEFORCE EXPERIENCE | >= 546.33 |GEFORCE EXPERIENCE download | | | | Docker Desktop | >= 4.26.1(131620) | Docker Desktop for Windows |
下载安装
- step1: 下载本项目
git clone https://github.com/netease-youdao/QAnything.git
- step2: 进入项目根目录执行启动脚本 如果在Windows系统下请先进入wsl环境
cd QAnything
bash run.sh # 默认在0号GPU上启动
- 指定单GPU启动
cd QAnything
bash run.sh 0 # 指定0号GPU启动 GPU编号从0开始 windows机器一般只有一张卡,所以只能指定0号GPU
- 指定多GPU启动
cd QAnything
bash run.sh 0,1 # 指定0,1号GPU启动,请确认有多张GPU可用,最多支持两张卡启动
开始体验
-
前端页面 运行成功后,即可在浏览器输入以下地址进行体验。
-
前端地址: http://
your_host:5052/qanything/ -
API 如果想要访问API接口,请参考下面的地址:
-
API address: http://
your_host:8777/api/ -
For detailed API documentation, please refer to QAnything API 文档
-
关闭服务
bash close.sh
3.demo展示
视频链接:https://blog.csdn.net/sinat_39620217/article/details/135743659
信息抽取

网页问答

文件大杂烩
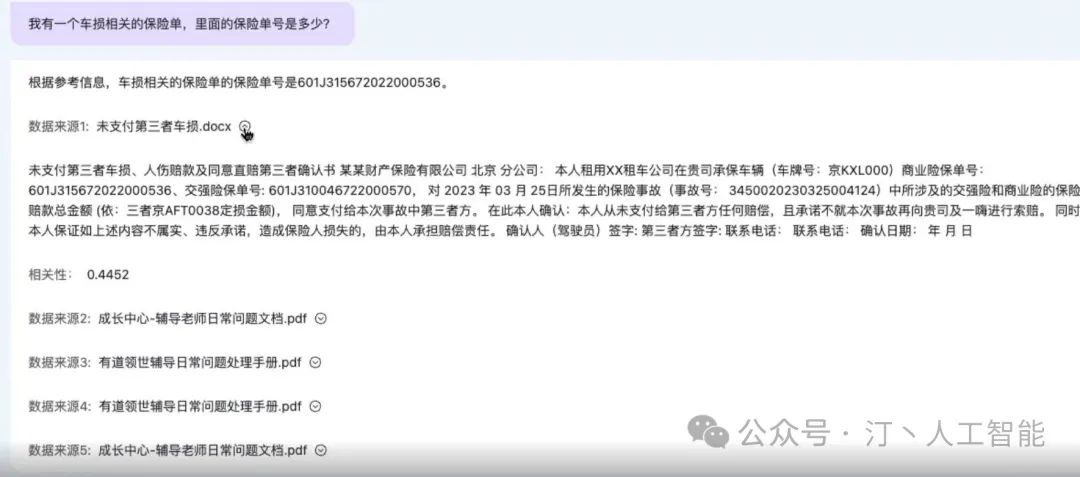
4.常见问题
-
在windows上执行docker-compose命令启动时报错:/bin/bash^M: bad interpreter: No such file or directory
-
- 原因:在windows下创建编辑的shell脚本是dos格式的,而linux却是只能执行格式为unix格式的脚本,所以在windows上编辑过的文件在linux上(windows下执行wsl后的环境通常也是linux)执行时会报错。
- 解决方案:将回车符替换为空字符串

-
在前端页面输入问题后,返回结果报错:Triton Inference Error (error_code: 4)
-
- 将docker-compose-xxx.yaml中的freeren/qanyxxx:v1.0.9改为freeren/qanyxxx:v1.0.8
- git clone https://www.wisemodel.cn/Netease_Youdao/qanything.git
- cd qanything
- git reset --hard 79b3da3bbb35406f0b2da3acfcdb4c96c2837faf
- unzip models.zip
- 替换掉现有的models目录
- echo “v2.1.0” > models/version.txt # 手动避过版本检查
- 原因:显存不够了,目前在问答过程中大模型和paddleocr占用的显存会逐渐上升且不释放,可能造成显存不够。
- 解决方案:重启服务,优化显存的工作已在计划中
- 原因2:如果发现显存够用,那是因为新版模型与部分显卡型号不兼容。
- 解决方案:请更换为兼容模型和镜像,手动下载模型文件解压并替换models目录,然后重启服务即可。
-
在前端页面输入问题后,返回结果是类似后面的乱码:omiteatures贶.scrollHeight㎜eaturesodo Curse.streaming pulumi窟IDI贶沤贶.scrollHeight贶贶贶eatures谜.scrollHeight她是
-
- 原因:显卡型号不支持,例如V100,请使用3080,3090,4080,4090等显卡,显存需要大于16G
-
服务启动报错,在api.log中显示:mysql.connector.errors.DatabaseError: 2003 (HY000): Can’t connect to MySQL server on ‘mysql-container-local:3306’ (111)
-
- 原因:将之前的QAnything代码拉取下来后,复制了一份代码到其他的地址,其中有一个volumes是mivlus和mysql默认的本地数据卷,复制后可能导致了mysql的数据卷冲突,导致mysql无法启动。
- 解决方案:删除冲突的数据卷volumes,重新启动服务
-
服务启动报错:ERROR: for qanything-container-local Cannot start service qanything_local: could not select device driver “nvidia” with capabilities: [[gpu]]
-
- 原因:查看nvidia显卡驱动版本是否满足要求,windows下建议直接更新到最新版;另外检查下是否安装了NVIDIA Container Toolkit, windows下需要进入wsl2环境,再参考linux下安装方法:https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html#docker
-
服务启动报错:nvidia-container-cli: mount error: file creation failed: /var/lib/docker/overlay2/xxxxxx/libnvidia-ml.s0.1: file exists: unknown
-
- 原因:在windows系统上使用docker-compose-linux.yaml启动
- 解决方案:使用docker-compose-windows.yaml启动
参考链接:
https://github.com/netease-youdao/QAnything/blob/master
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。















 462
462

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









