






24年1月份,李飞飞教授团队发布了一篇题为《Agent AI: Surveying the Horizons of Multimodal Interaction》的论文。原论文篇幅较长,做了下述论文导读,希望对大家学习了解论文重点有一些些帮助。
这份论文垫子版我已经拿到了,需要的小伙伴可以扫取。


论文首页
1. 摘要
多模态人工智能系统有望在日常生活中广泛普及,而将其具身化为智能体,使其能在物理和虚拟环境中进行交互,是提升其能力的一个有前途的方向。当前,系统多基于现有基础模型构建具身智能体,这有助于模型处理视觉与上下文数据,进而创建更复杂、更具情境感知能力的人工智能系统。例如,一个能感知用户动作、环境对象、音频等多模态信息的系统,可据此在环境中生成更恰当的智能体反应。为推动基于智能体的多模态智能研究,本论文将 “智能体人工智能” 定义为一类能感知多模态输入(如视觉、语言等)并产生有意义具身行动的交互式系统,尤其关注那些结合外部知识、多感官输入和人类反馈来改进行动预测的智能体。作者认为,在实际环境中开发此类系统,有助于减轻大型基础模型的幻觉及输出不合理性问题。智能体人工智能这一新兴领域涵盖了多模态交互中的具身与智能体相关层面,不仅涉及物理世界中的行动交互,还包括在虚拟环境中创建和交互的可能性。本文旨在全面综述智能体人工智能领域,包括其在多模态、游戏、机器人、医疗保健等领域的研究进展,探讨相关技术集成、范式框架、学习策略、分类应用,以及跨模态、跨领域和跨现实的应用挑战与应对策略,同时涉及持续自我改进、数据集与排行榜、伦理考虑和多样性声明等方面,为该领域的进一步发展提供全面的知识基础与研究思路。

原论文摘要截图
2. 导读脑图
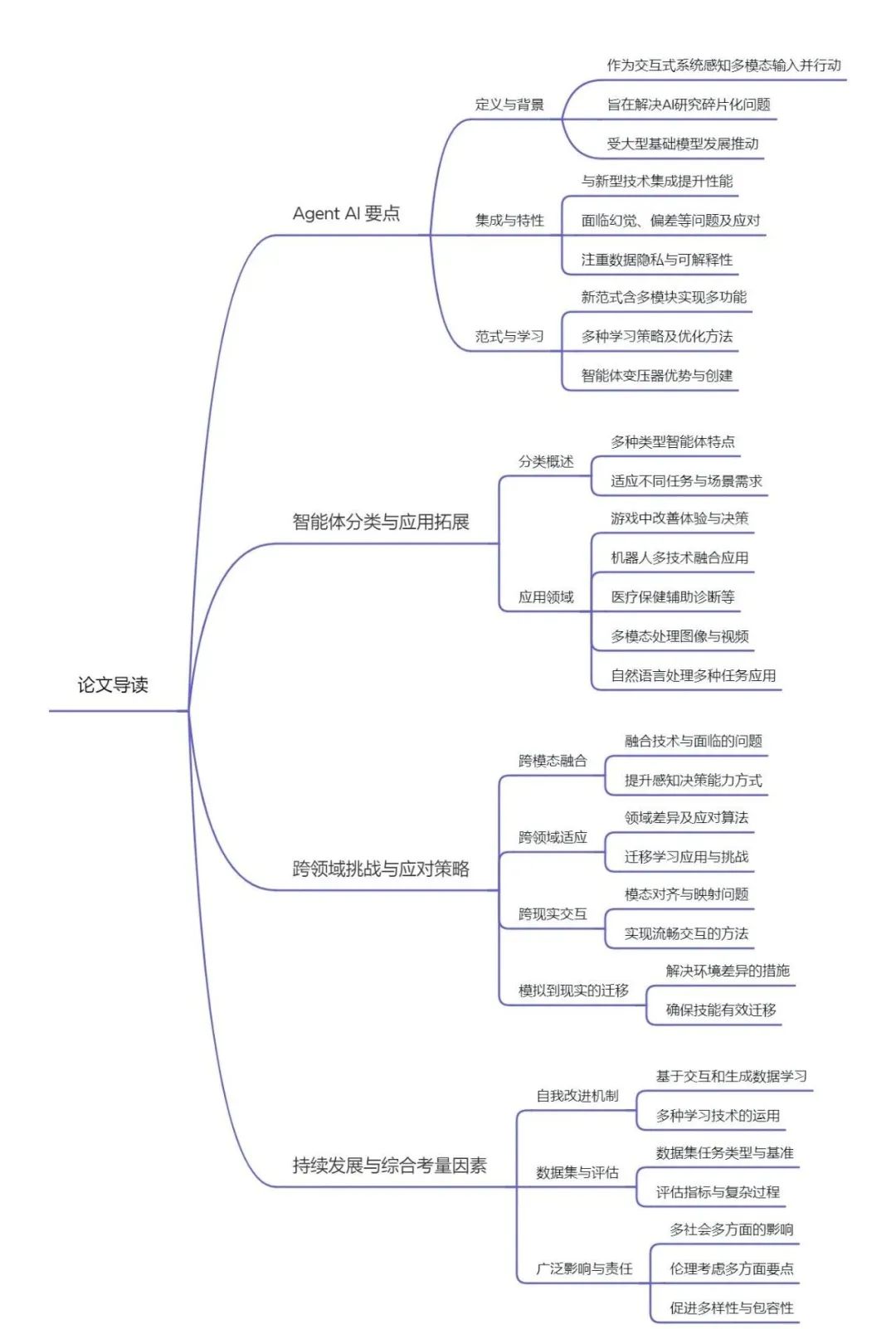
3. 研究方法
本文主要采用文献综述法、案例分析法和对比分析法对智能体人工智能相关内容进行研究。通过对大量相关研究论文的综合分析,梳理智能体人工智能的概念、技术背景、应用等方面的发展脉络;运用实际案例展示智能体在不同领域的具体应用及效果,深入剖析其面临的问题与挑战;对比不同智能体类型、技术方法以及应用场景等之间的差异,明确各自的特点和优势,为智能体人工智能的进一步发展提供全面且深入的理论支持和实践指导。
4. 论文中涉及的方法改进
1.强化学习(RL)中的改进
· 奖励设计优化
利用 LLMs/VLMs 辅助:由于 RL 中策略学习效率高度依赖奖励函数设计,而传统方法设计奖励函数需深入了解任务本质且常依赖专家经验。通过 LLMs/VLMs,可借助其强大的语言理解和知识储备能力,更合理地设计奖励函数,以更好地引导智能体学习最优策略。例如,在复杂的机器人任务规划中,LLMs 可基于对任务目标和环境的理解,为智能体提供更具针对性和适应性的奖励信号,使智能体更快地学习到有效的行动策略。
· 数据收集与效率提升
增强数据生成:鉴于 RL 基于探索性的策略学习对数据量需求大,尤其是在处理长序列或复杂动作任务时,研究人员正努力通过多种方式增强数据生成以支持策略学习。一方面,利用先进的模型(如 VLMs 和 LLMs)来合成更多样化、高质量的数据,以丰富智能体的学习资源;另一方面,开发新的数据生成算法和技术,提高数据生成的效率和准确性,减少对大量实际数据收集的依赖,降低数据获取成本。例如,在模拟环境中,通过改进模拟算法和模型,生成更接近真实场景的数据,使智能体在模拟环境中学习到更具泛化能力的策略,从而更好地应用于实际场景。
模型集成于奖励函数:将 LLMs 和 VLMs 集成到奖励函数中,是提高 RL 策略学习效率的另一研究方向。通过这种方式,使奖励函数能够更好地适应复杂任务和动态环境,根据智能体的行动和环境状态实时调整奖励值,引导智能体更快地收敛到最优策略。例如,在机器人导航任务中,当智能体接近目标且避开障碍物时,结合视觉信息和语言指令的 VLMs 可给予适当的奖励激励,促使智能体更高效地学习导航策略。
2.模仿学习(IL)中的改进
· 结合先进技术改进行为克隆(BC)
融入 LLM/VLM 技术:在基于 IL 的机器人任务学习中,如行为克隆(BC)方法,研究重点在于结合 LLM/VLM 技术改进传统 BC 模型。通过利用 LLMs 的语言理解能力和 VLMs 的视觉感知能力,机器人能够更好地理解和模仿专家的行为。例如,在复杂操作任务中,机器人可以根据专家的语言指令(由 LLM 处理)和视觉示范(由 VLM 处理),更准确地学习和复制专家的动作序列,提高在实际任务中的执行准确性和泛化能力。
提升模型端到端性能:致力于开发更先进的端到端模型,通过改进模型架构和训练算法,使机器人在模仿学习过程中能够更好地处理多模态信息(如视觉和语言信息)的融合。例如,采用基于 Transformer 的模型架构,增强模型对输入信息的编码和解码能力,提高机器人在不同任务和环境下的适应性,实现从观察专家行为到自主执行任务的更有效转换。
3. 数据相关改进
· 多模态数据利用与融合
整合多模态信息:为提升智能体对环境的感知和理解能力,研究人员专注于更好地整合多模态数据(如图像、文本、音频等)。通过设计更有效的多模态编码器 - 解码器架构,使智能体能够从不同模态的信息中提取更丰富、准确的特征,并将其融合用于决策和行动。例如,在智能导览系统中,智能体可以同时处理游客的语音指令(音频模态)、周围环境的图像(视觉模态)以及相关的文字介绍(文本模态),通过多模态融合,更精准地理解游客需求,提供更准确、个性化的导航和信息服务。
提高数据质量与标注:认识到数据质量对智能体性能的关键影响,努力改进数据收集和标注方法。采用更严格的数据质量控制标准,减少数据中的噪声和错误标注,确保智能体学习到正确的模式。同时,探索自动化数据标注技术,结合人工审核,提高标注效率和准确性,降低数据标注成本。例如,在图像分类任务中,通过开发更精确的图像标注工具和算法,以及利用预训练模型进行数据预标注,再由人工进行审核和修正,提高图像数据标注的质量,从而提升智能体在图像识别任务中的准确性。
4. 模型架构改进
· 模型架构改进
定制化任务适应:着重优化智能体变压器模型的可定制性,使其能够更好地适应特定智能体任务。通过设计更灵活的架构和参数设置,智能体可以根据不同任务需求(如机器人控制中的不同动作空间、游戏中的不同规则和目标等)进行定制化训练,提高模型在特定领域的性能。例如,在医疗保健领域的智能诊断任务中,智能体变压器模型可根据医学数据特点和诊断任务要求进行定制,专注于学习疾病相关的特征和模式,提高诊断准确性。
可解释性增强:致力于提高智能体变压器模型的可解释性,解决模型决策过程的 “黑箱” 问题。研究人员探索通过可视化技术、注意力机制分析等方法,揭示模型在处理信息和做出决策时的内部机制,使用户能够理解智能体为何做出特定决策。这在关键应用领域(如医疗、法律等)尤为重要,有助于建立用户对智能体的信任,并在出现问题时进行有效的追溯和改进。例如,在医疗诊断智能体中,通过可视化模型对医学影像数据的关注区域和精彩内容和特征提取过程,医生可以更好地理解智能体的诊断依据,从而对诊断结果进行评估和验证。
5. 交互式学习改进
· 改进反馈机制与学习策略
实时反馈整合优化:在交互式学习方面,研究重点在于优化实时反馈整合机制,使智能体能够更有效地从用户反馈和环境交互中学习。通过改进算法和模型架构,智能体可以更快地响应实时反馈,调整自身行为策略,提高学习效率和适应性。例如,在在线教育智能体中,根据学生的实时学习表现和反馈(如答题正确率、学习进度快慢等),智能体能够立即调整教学内容和方式,提供更有针对性的辅导和建议,帮助学生更好地掌握知识。
探索多样化学习策略:积极探索结合多种学习策略的方法,以提高智能体在复杂环境中的学习能力。例如,将强化学习与模仿学习相结合,智能体在初始阶段通过模仿专家或成功案例快速学习基本技能,然后利用强化学习在实际环境中进行探索和优化,不断改进策略以适应不同任务和环境变化。这种混合学习策略有助于充分发挥不同学习方法的优势,提高智能体的综合性能和灵活性。
…
这份论文垫子版我已经拿到了,需要的小伙伴可以扫取。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









