






这是我在维也纳举行的 ICML 会议上被问到的问题。
在茶歇期间,一位 Jina 用户向我提出了一个 LLM 社区最近热议的问题。他问我们 Jina Embedding 模型能不能判断 9.11 比 9.9 更小,很多大模型在这个小问题上栽了跟头。
我说:“说实话,我也不确定。” 他接着详细阐述了这个问题对于他研究的重要性,并暗示:Tokenizer 可能是问题的根源,我若有所思点点头,脑海里开始构思如何用实验来找到答案。
本文我将通过一系列实验来探索 Embedding、Reranker 模型能否可以准确比较数字。为了验证模型在实际应用中的表现,我还设计了一些具有挑战性的测试用例,包括
- 小数比较(例如 0.001 和 0.0001)
- 货币金额($1.99 和 $2.00)
- 日期比较(例如 2023-12-31 和 2024-01-01)
- 时间比较(例如 23:59 和 00:00)
在这次实验中,我选择了jina-embeddings-v2-base-en(2023 年 10 月发布)和jina-reranker-v2-multilingual的(2024 年 6 月发布)作为研究对象,来评估它们在数字理解和比较方面的优势与局限。
让我们拭目以待。
实验装置
完整的实现可以在下面的 Colab 中找到:https://colab.research.google.com/drive/11kUxYhHMLqYhw5HVKEYdHv0EfdZIyBBy?ref=jina-ai-gmbh.ghost.io#scrollTo=G7Cy9zSb2Ukg
本次实验设计非常直观。举个例子,要检查 Embedding 模型是否理解 1 到 100 之间的数字,步骤如下:
- 构建文档:为每个数字生成“字符串文字”文档。
- 发送至 Embedding API:使用 Embedding API 获取每个文档的 Embedding。
- 计算余弦相似度:计算每两个文档的余弦相似度,创建一个相似度矩阵。
- 绘制散点图:使用散点图可视化结果。相似度矩阵中的每个元素(i, j)映射到一个点,X 轴为(i-j),Y 轴为(i, j)的相似度值。
实验原理是:如果(i-j)的差值为零,即 i 等于 j,那么语义相似度应该是最高的。随着(i-j)的差值增加,相似度应该降低。理想情况下,相似度应该与差值成线性关系。 如果我们观察不到这种线性关系,那么模型可能无法理解数字,并可能产生错误,比如认为 9.11 大于 9.9。
Reranker 模型遵循类似流程。主要区别在于,我们将每个文档逐一设为查询,通过加上 Prompt:“哪一项最接近…”,将所有其他文档作为 documents 进行排名。Reranker API 返回的相关性得分直接作为语义相似度度量。核心实现如下:
def rerank_documents(documents): reranker_url = "https://api.jina.ai/v1/rerank" headers = { "Content-Type": "application/json", "Authorization": f"Bearer {token}" } # 初始化相似度矩阵 similarity_matrix = np.zeros((len(documents), len(documents))) for idx, d in enumerate(documents): payload = { "model": "jina-reranker-v2-base-multilingual", "query": f"what is the closest item to {d}?", "top_n": len(documents), "documents": documents } ...
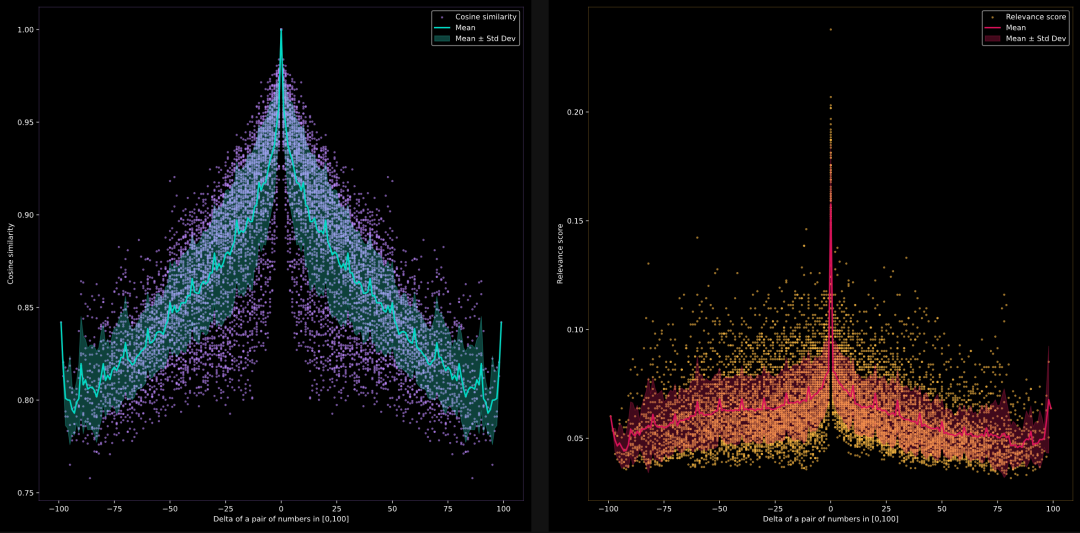
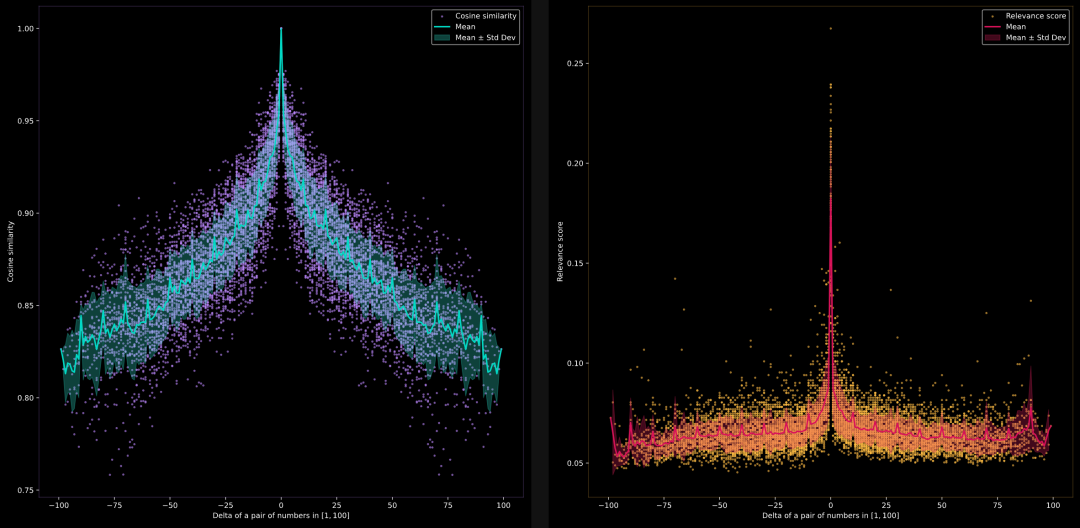
模型能否比较 1 到 100 之间的数字?
左侧是jina-embeddings-v2-base-en的结果,右侧是jina-reranker-v2-multilingual的结果。
如何阅读这些图
在继续实验之前,我先解释一下如何正确解读这些图表。**首先,我观察到 Embedding 模型表现不错,而 Reranker 模型表现稍差。**那么,这些图表到底展示了什么呢?
X 轴代表索引(i, j)的差值,即 i-j,当我们从文档集中均匀采样 di 和 dj 时。这个差值范围是[-100, 100]。由于文档集是按顺序排列的,即|i-j|越小,di 和 dj 在语义上越接近;i 和 j 越远,di 和 dj 之间的相似度越低。这就是为什么你会看到相似度(由 Y 轴表示)在 X=0 处达到峰值,然后随着 X 值的增大或减小而线性下降。
理想情况下,这应该形成一个尖峰或“^”形状。 然而,情况并非总是如此。如果你固定 X 轴某一点,例如 X = 25,并沿 Y 轴查看,你会发现相似度值在 0.80 到 0.95 之间。这意味着 sim(d_27,d_2)可能是 0.81,而 sim(d_42,d_17)可能是 0.91,尽管它们的差值都是 25。也就是说,即使差值相同,不同文档对的相似度也会不同。
青色趋势线显示了每个 X 值的平均相似度及其标准差。要注意,由于文档集是均匀分布的,确保了连续文档间的间隔相等,相似度应该线性下降。
Embedding 模型图总是对称的,X = 0 时,Y 值最大,为 1.0。这是因为对于 di 和 dj,余弦相似度是对称的,且 cos(0) = 1。
相反,Reranker 模型图总是呈现非对称性,这是因为在重排序模型中,查询与文档的角色存在差异。其最大值未必是 1.0,毕竟 X = 0 表示的是我们利用 Reranker 模型去计算“与 4 最接近的一项是什么”和“4”的相关性。倘若深入思考,X = 0 并不一定会致使出现最大的 Y 值。
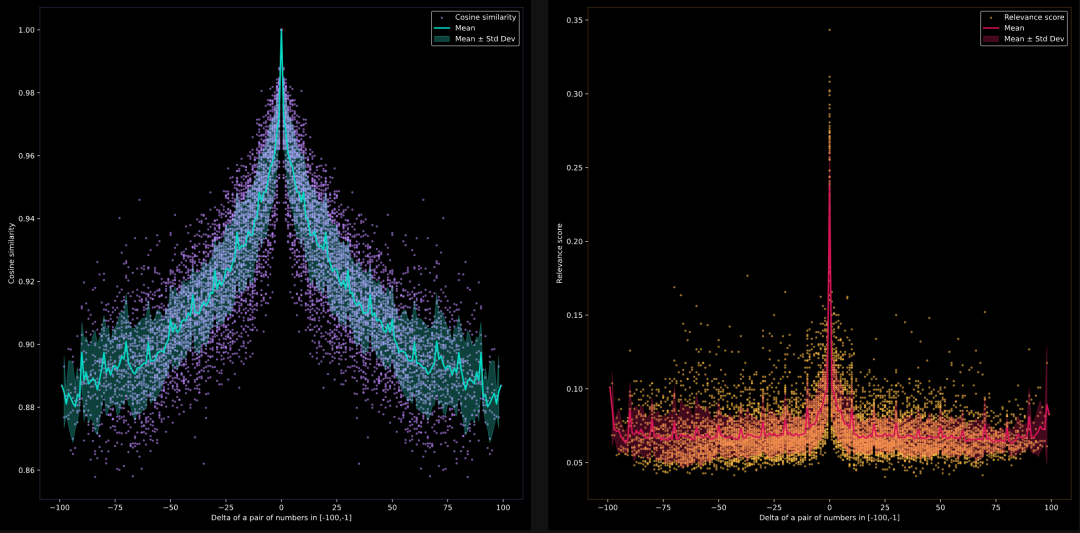
模型能否比较 -100 到 -1 之间的负数?
我们想测试模型在负数空间中是否能够判断语义相似性,测试数据集是从 -1 到 -100 的负整数字符串,即 documents = [str(-i) for i in range(1, 101)]。这是一个散点图,一同显示了平均值和标准差。
左侧是jina-embeddings-v2-base-en的结果,右侧是jina-reranker-v2-multilingual的结果。
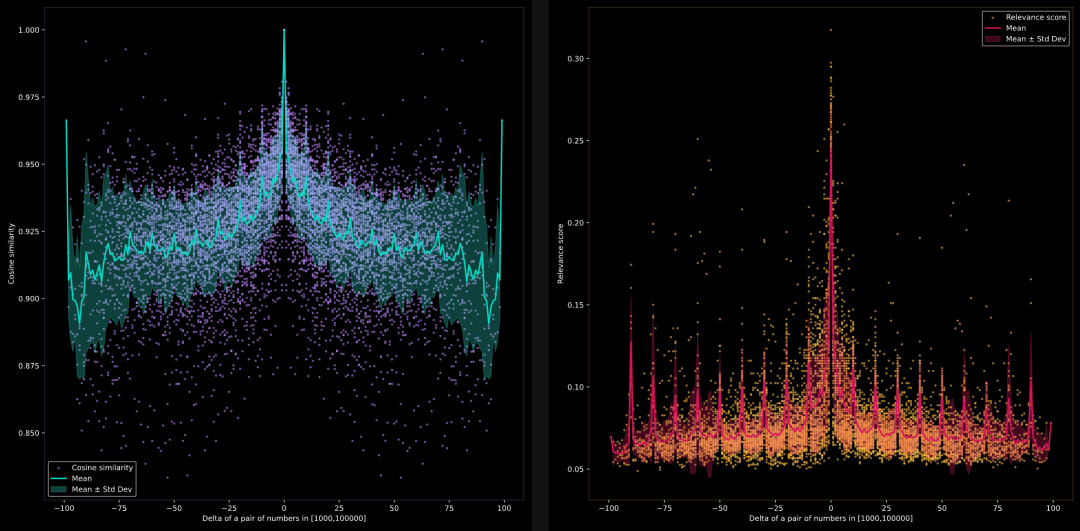
模型能否比较更大间隔的数字 1000, 2000, 3000, …, 100000?
在这里,我们想测试当比较间隔为 1000 的数字时,模型能否识别语义相似性。documents是由 1 到 100 的数字乘以 1000 构成的字符串列表。documents = [str(i*1000) for i in range(1, 101)]。同上,本散点图一并显示了平均值和标准差。
左侧是jina-embeddings-v2-base-en的结果,右侧是jina-reranker-v2-multilingual的结果。
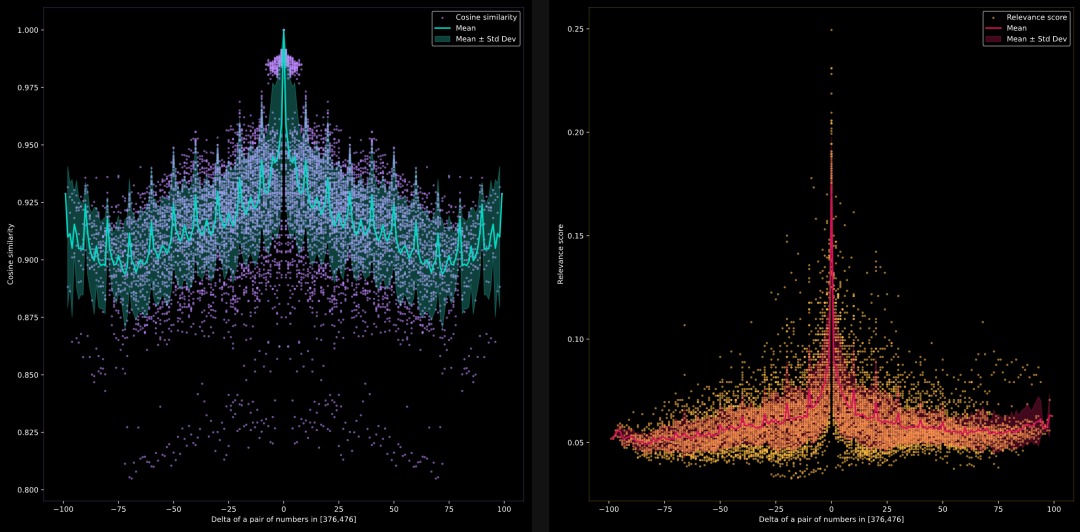
模型能否比较任意范围内的数字,例如 376, 377, 378, …, 476?
我们希望测试当比较任意范围内的数字时,模型能否识别语义相似性。我们将数字移动到一个随机范围,documents是由 0 到 100 的数字加上 375 构成的字符串列表。即 documents = [str(i+375) for i in range(1, 101)]
左侧是jina-embeddings-v2-base-en的结果,右侧是jina-reranker-v2-multilingual的结果。
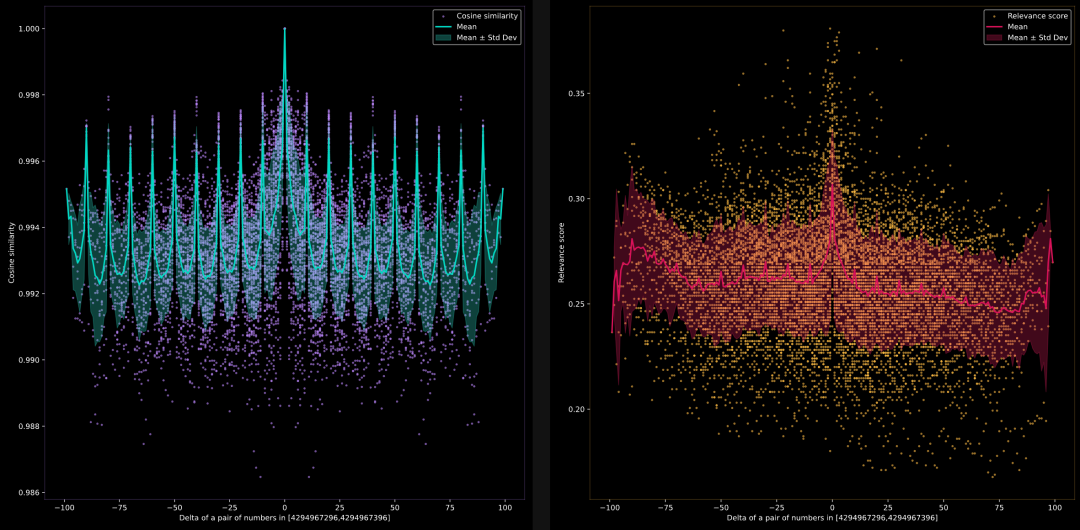
模型能否比较非常大的数字 4294967296, 4294967297, 4294967298, …, 4294967396?
我们想测试当比较大数字时,模型能否识别语义相似性。我们将范围进一步移动到一个大数字,documents是由 0 到 100 的数字加上 4294967296 构成的字符串列表。即 documents = [str(i+4294967296) for i in range(1, 101)]
左侧是jina-embeddings-v2-base-en的结果,右侧是jina-reranker-v2-multilingual的结果。
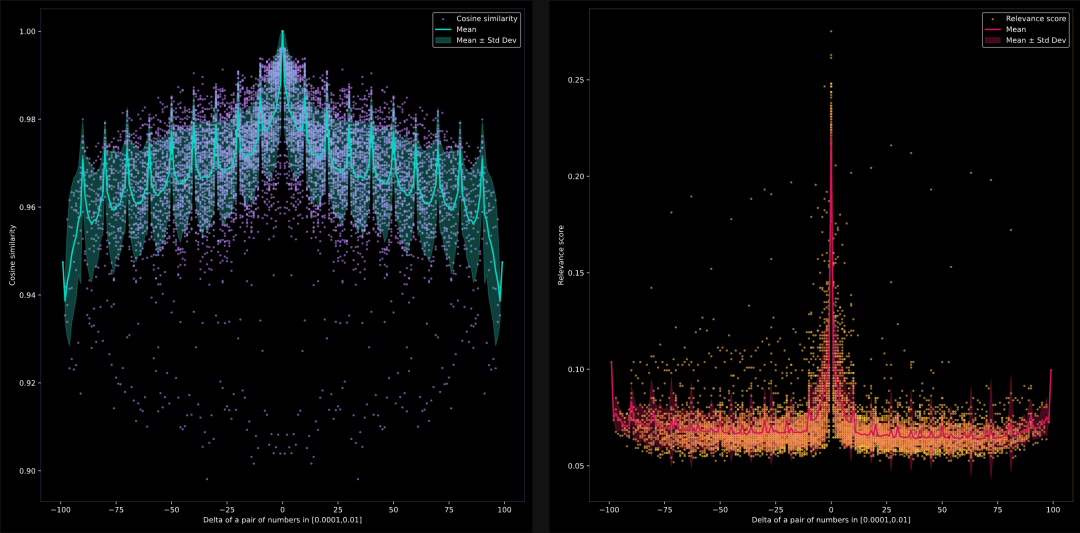
模型能否比较 0.0001, 0.0002, 0.0003, …, 0.1 之间的浮点数?(不固定小数位数)
在这里,我们想测试当比较浮点数时,模型能否识别语义相似性。documents是由 1 到 100 的数字除以 1000 构成的字符串列表。即 documents = [str(i/1000) for i in range(1, 101)]
左侧是jina-embeddings-v2-base-en的结果,右侧是jina-reranker-v2-multilingual的结果。
模型能否比较货币金额 1, 2, 3, …, 100?
在这里我们想看看,在比较货币中的数字时,模型能否识别语义相似性。documents是由 1 到 100 的数字前面加上货币符号 $ 构成的字符串列表。即 documents = ['$'+str(i) for i in range(1, 101)]
模型能否比较日期 2024-07-24, 2024-07-25, 2024-07-26, …, 2024-10-31?
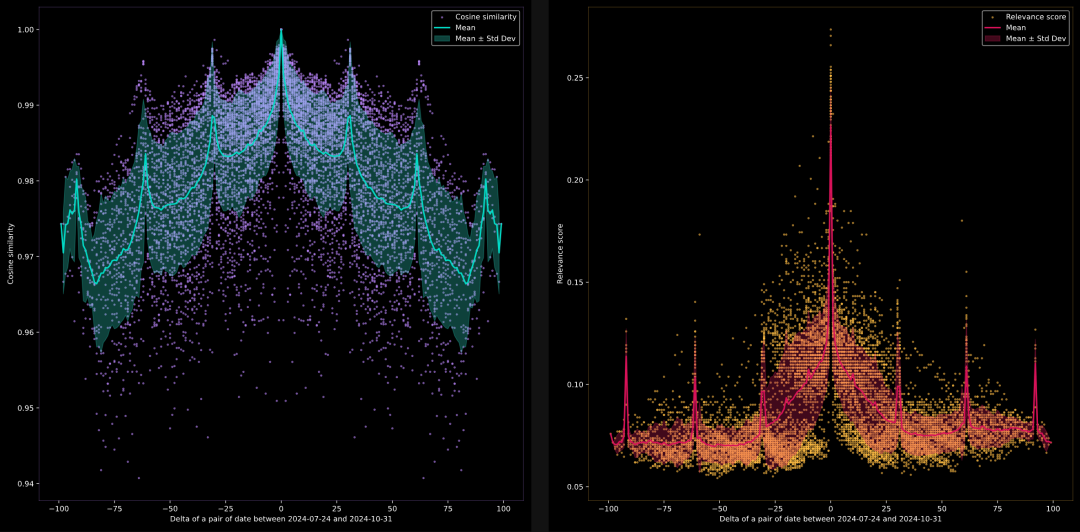
在这里,我们想测试当比较日期格式中的数字时,模型能否识别语义相似性。documents是由当前日期加上 0 到 100 天构成的日期字符串列表。today = datetime.today(); documents = [(today + timedelta(days=i)).strftime('%Y-%m-%d') for i in range(100)]
模型能否比较时间 19:00:07, 19:00:08, 19:00:09,…, 20:39:07?
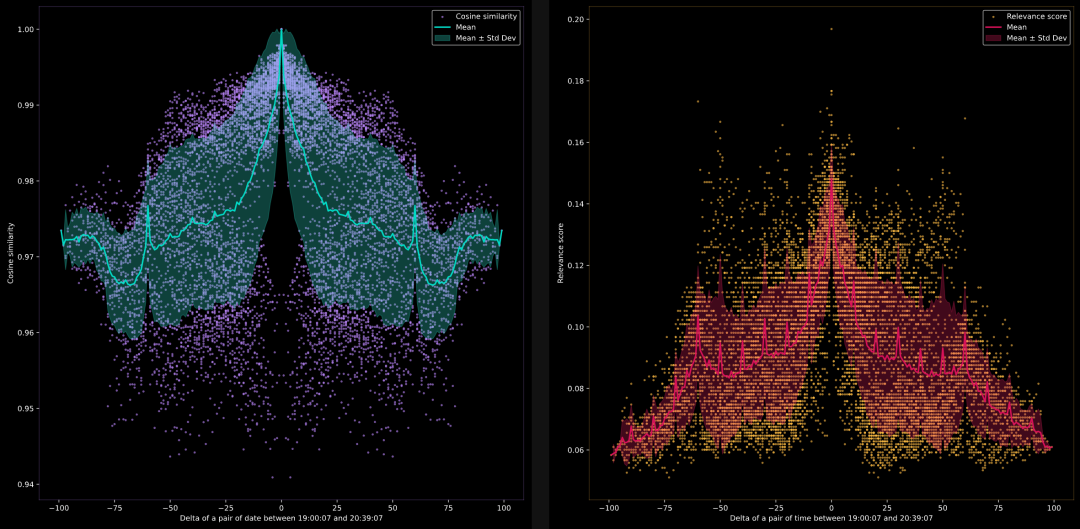
在这里,我们想测试当比较时间格式中的数字时,模型能否识别语义相似性。documents是由当前时间加上 0 到 100 分钟构成的时间字符串列表。now = datetime.now() documents = [(now + timedelta(minutes=i)).strftime('%H:%M:%S') for i in range(100)]
观察结果
从上述图表中,我们得出了一些观察结果:
Reranker 模型
- Reranker 模型在处理数字比较问题时,确实有些力不从心。 哪怕是在 1 到 100 这样简单的数字比较内,它的表现也不尽人意。
- 不过我们在 Reranker 模型测试时,使用了为查询构造的特殊提示词,即
最接近 x 的一项是什么,这也可能影响结果。
Embedding 模型
- Embedding 模型在处理 1 到 100 的小数字或者 -100 到 -1 的负数时,表现还算不错,但一旦数字范围扩大,或者涉及到更复杂的数值区间,如浮点数,它的效果就会大打折扣。
- 我们还会注意到,在每隔 10 的倍数处,算法的表现会出现一些规律性的波动。这可能与分词器将字符串如"10"拆分成"1"和"0"的方式有关。
日期和时间理解
- Embedding 模型对日期和时间有相当不错的理解,大多数情况下都能准确比较它们。 例如,在日期图表里,我们会发现每 30 或 31 天会出现一个高峰,对应一个月的天数。而在时间的图表中,每 60 分钟也会出现一个高峰,这与一小时的分钟数相匹配。
- Reranker 模型也在一定程度上捕捉到了这种理解。
可视化与“零”的相似性
我们还设计了另一个直观有趣的实验:可视化任意数字与零(原点)之间的语义相似性。将参考点固定为零的嵌入,我们想看看数字与零之间的语义相似性是否随数字增大而线性下降。
Google Colab:https://colab.research.google.com/drive/1S9qZQ0jjdKLNUT2GKqPbU4ogpDe6g9Qh#scrollTo=nvAX2GOpCiRt
我们将查询固定为"0"或"与数字零最接近的数字是什么",并对所有数字进行排序,看看它们的相关性得分是否随着数字的增加而下降。结果如下所示:
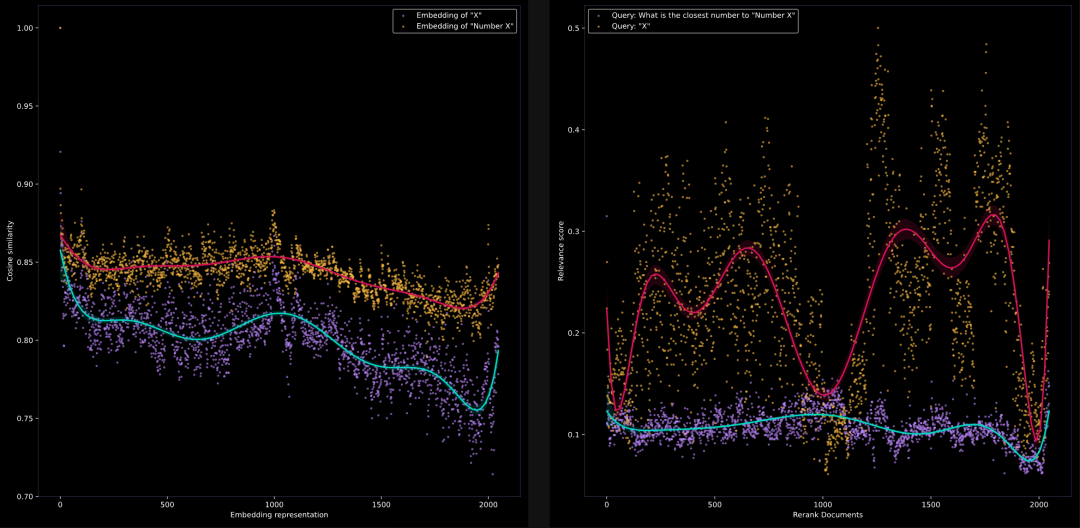
左侧是jina-embeddings-v2-base-en的结果,右侧是jina-reranker-v2-multilingual的结果。
关键发现
尽管本文实验设置相对简单,但它揭示了当前模型在数字处理方面的一些基本问题,为我们后续的模型开发提供了宝贵见解。
影响模型数字比较能力的两大关键因素有 分词策略 和 训练数据。
首先是分词策略: 词汇表的设计直接影响数字的表示。例如,如果词汇表只包括 0-9 的数字,那么 11 可能被分为单独的 1 和 1,或作为整体的 11,不同的分词方式会导致模型对数值的理解差异。
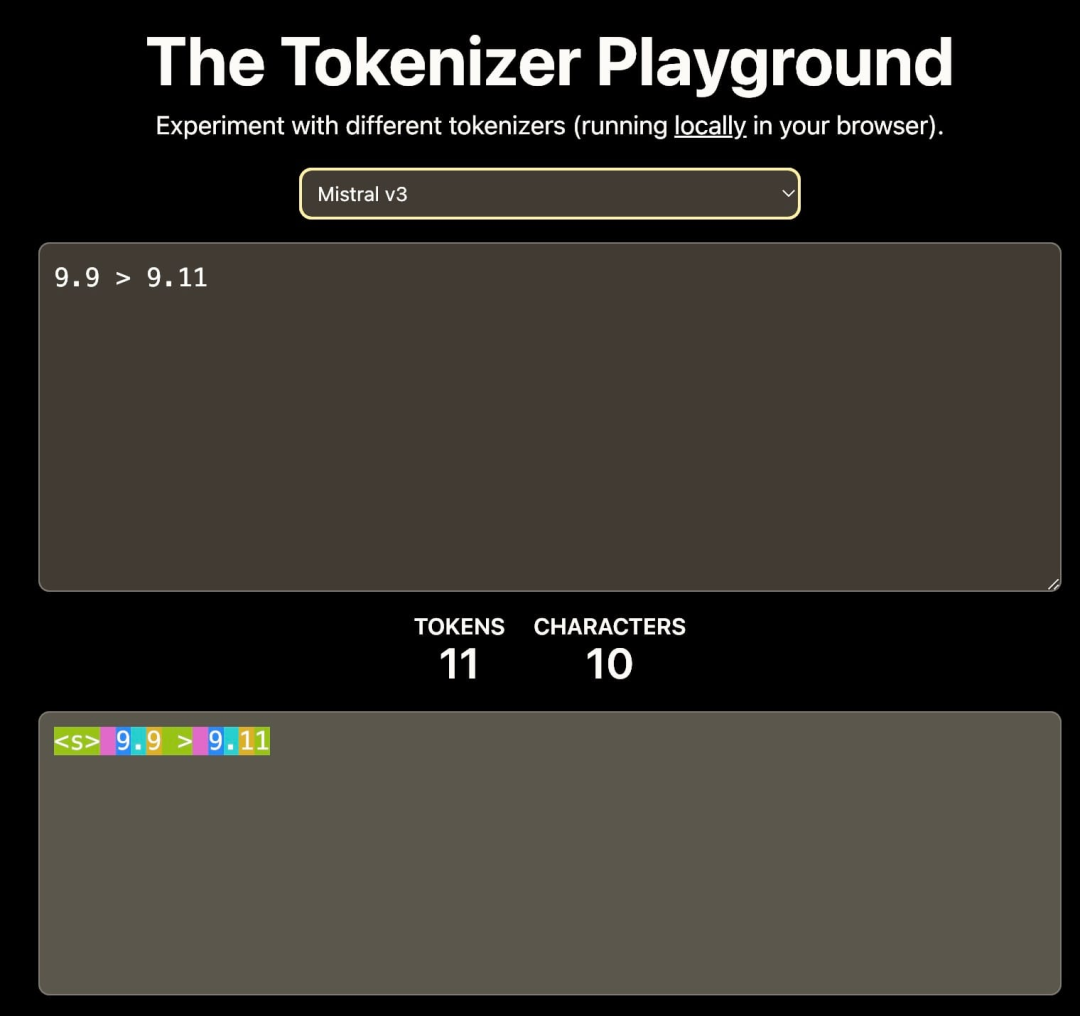
来源:HuggingFace 上的 Tokenizer Playground。
其次是训练数据: 训练语料的选择对模型的数值推理能力影响重大。比如,如果训练数据主要是软件开发文档或 GitHub Repo,那么模型可能会解释 9.11 大于 9.9 (受语义化版本控制的影响)。
密集检索模型(例如 Embedding 和 Reranker)的算术能力对于涉及 RAG 以及高级检索和推理的任务至关重要。强大的数字推理能力可以显著提高搜索质量,尤其是在处理 JSON 这样的结构化数据时。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。















 615
615

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









