







目录
- 前言
- 1、TextIn文档解析技术
-
- 1.1、文档解析技术
- 1.2、目前存在的问题
-
- 1.2.1、不规则的文档信息示例
- 1.3、合合信息的文档解析
-
- 1.3.1、合合信息的TextIn文档解析技术架构
- 1.3.2、版面分析关键技术 Layout-engine
- 1.3.3、文档树提取关键技术 Catalog-engine
- 1.3.4、双栏
- 1.3.5、非对称双栏
- 1.3.6、双栏+表格
- 1.3.7、无线表格
- 1.3.8、合并单元格表格
- 1.3.9、层级目录
- 1.3.10、更高的文档问答精度
- 2、向量化技术
-
- 2.1、文本向量化模型
- 总结
前言

在人工智能时代,多模态大模型的发展不仅仅是技术创新的产物,它更是对人类交互和信息处理方式的一种模拟。我们的世界是多模态的:我们不仅阅读文字,还观察图像,聆听声音,感受触觉。多模态大模型试图通过模拟这种丰富的信息处理方式来增强机器的理解能力。
这些模型的核心优势在于它们的整合能力。传统的单模态系统在处理单一类型数据时可能表现出色,但它们无法捕捉跨模态的复杂关系。例如,一段视频内容不仅包含视觉元素,还可能包含重要的音频信息,甚至是文字信息(如字幕或场景中的文本)。多模态大模型能够综合这些信息,提供更为全面的分析和理解。
多模态大模型在文档处理平台的应用实现了对复杂文档内容的深层次理解和智能化处理。这些模型不仅能够执行基本的文字识别任务,还能结合上下文信息,识别和解释图表、图像中的数据和关系,甚至从视频中提取关键信息。例如,当处理一个包含图表和图像的报告时,多模态模型可以识别图表中的趋势,将其与文本中的描述相匹配,从而提供一个综合的内容概述。
1、TextIn文档解析技术
1.1、文档解析技术
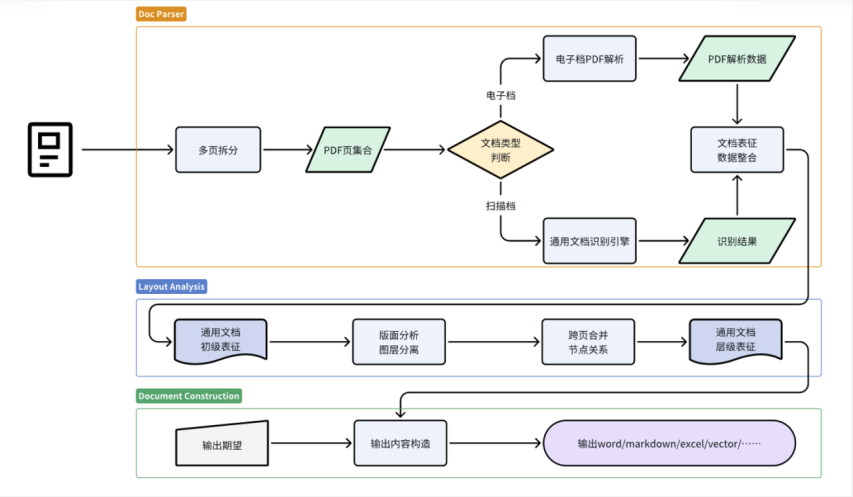
文档解析技术,主要是指提取非结构化的文档内容中的关键信息,解析成结构化的数据。在多模态训练中,不仅能提取文字信息,也能对视频、音频、表格等信息进行处理,同时还能结合上下文,识别和解析文字、图片、音视频等数据中的信息和关系。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









