






多件衣服按指定穿法一键虚拟试穿!
中山大学&字节智创数字人团队提出了一个名为MMTryon的虚拟试穿框架,可以通过输入多个服装图像及指定穿法的文本指令来生成高质量的组合试穿结果。
比如选中一件大衣、一条裤子,再配一个包,用语言描述穿法,“啪”的一键就穿到了人像上:

无论是真人图像又或是漫画人物,都能一键按照搭配试穿衣服:

对于单图换装,MMTryon有效利用了大量的数据设计了一个表征能力强大的服装编码器,使得该方案能处理复杂的换装场景及任意服装款式;

对于组合换装,MMTryon消除了传统虚拟换装算法中对服装精细分割的依赖,可依靠一条文本指令从多张服装参考图像中选择需要试穿的服装及对应的穿法,生成真实自然的组合换装效果。

在基准测试中,MMTryon拿下新SOTA。
多模态多参考注意机制加持,效果更精确灵活
虚拟换装技术旨在将模特所穿服饰或者衣服的平铺图穿到目标人物身上,达到换装的效果,但是之前虚拟试穿的方案存在一些技术难点没有解决。
首先,现有的方法通常是为单件试穿任务(上衣/下衣、连衣裙)而设计的,并且无法自定义着装风格,例如,外套拉上/拉开拉链、上衣塞入/塞出等。
另外,之前的方案严重依赖特定于类别的分割模型来识别试穿区域,如下图所示如果分割错误则将直接导致试穿结果中出现明显的试穿错误或者伪影等情况。
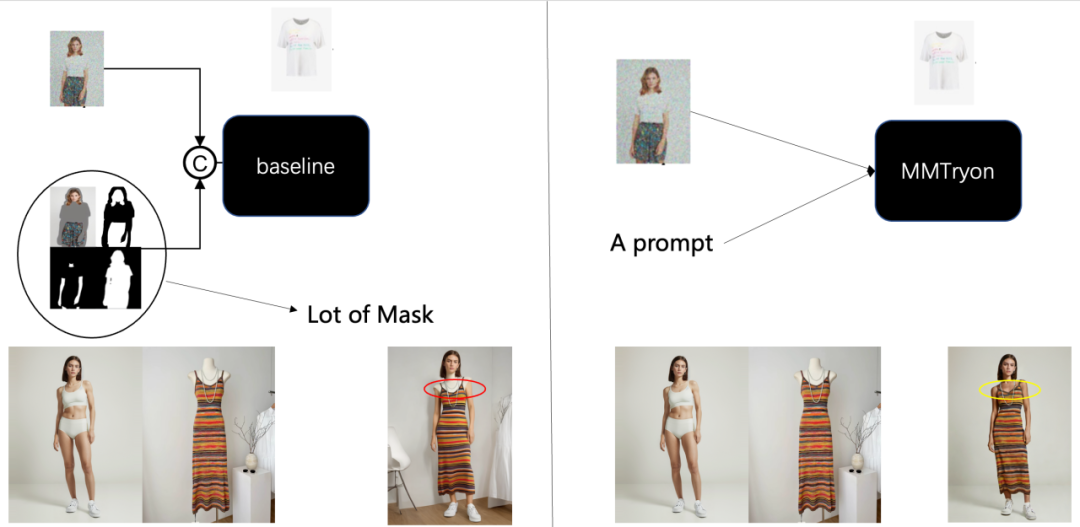
为了解决这些问题,研究团队提出了MMTryon,将参考图像中的服装信息与文本指令中的着装风格信息通过一种新颖的多模态和多参考注意机制来进行表示,这使得该方案支持组合式换装以及多样的试穿风格。
此外,为了消除对分割的依赖性,MMTryon使用了表征能力丰富的服装编码器,并利用新颖的可扩展的数据生成流程增强现有的数据集,这样在推理阶段,MMtryon无需任何分割,仅仅通过文本以及多个试穿对象即可实现高质量虚拟换装。
在开源的数据集以及复杂场景下进行的大量实验在定性和定量上证明了MMTryon优于现有SOTA方法。
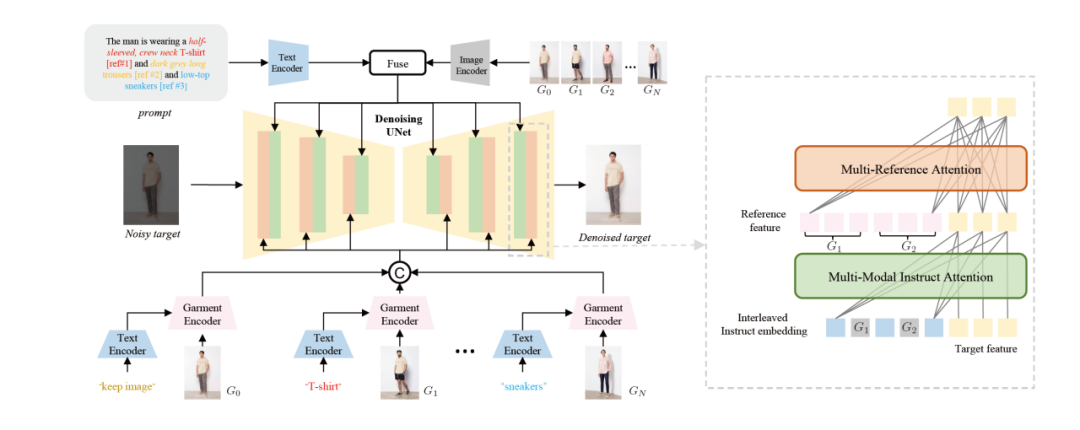
接下来是更具体的方法。
首先研究团队预训练了一个服装编码器,在这一stage中MMTryon利用文本作为query,将得到的特征与grouding dino+SAM所得到的mask计算一个query损失。
目标是经过text query 后仅激活文本对应区域的特征,这样可以摆脱对于服装分割的依赖。同时,利用大量的pair对更好的编码服装特征。
之后,为了更稳定的训练组合换装,需要多件服装组合式换装的pair图,但是这样的pair图采集成本很高。
为此,研究团队提出了一个基于大模型的数据扩增模式,利用视觉语言模型以及grouding dino+SAM去得到了不同区域的mask,来保护对应的上衣或者下衣区域,利用stable diffusion XL去重绘保护区域外剩下的内容,构建了100w的增强数据集,训练中将增强数据集与90w原始数据一起加入训练。
基于增强的数据集以及服装编码器,MMTryon设计了多参考图像注意力模块和多模态图文注意力模块,其中多参考图图像注意力模块用于将多件衣服的特征注入到目标图像来控制多件衣服的试穿,多模态图文注意力模块利用详细的文本与图像的clip编码来控制多样的试穿风格。
可以看到,MMtryon 由于服饰编码器丰富的表征能力,对于各种类型的换装都可以有真实的虚拟试穿效果:

无论是真人图像还是挂台服饰,只需要多张服装参考图像及文本,就可以组合式换装并控制换装风格。
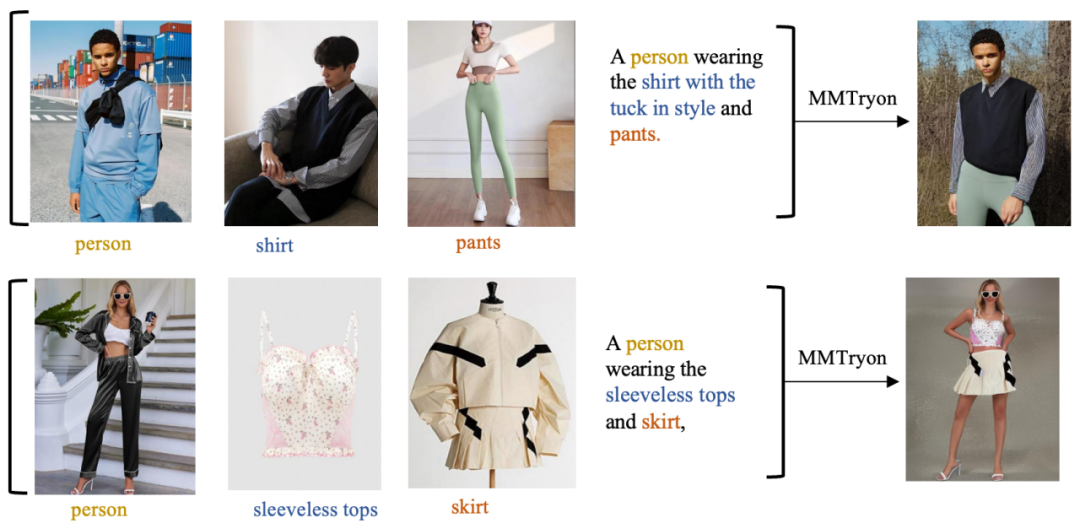
甚至还能作为一个fashion换装辅助设计来帮你买衣服:

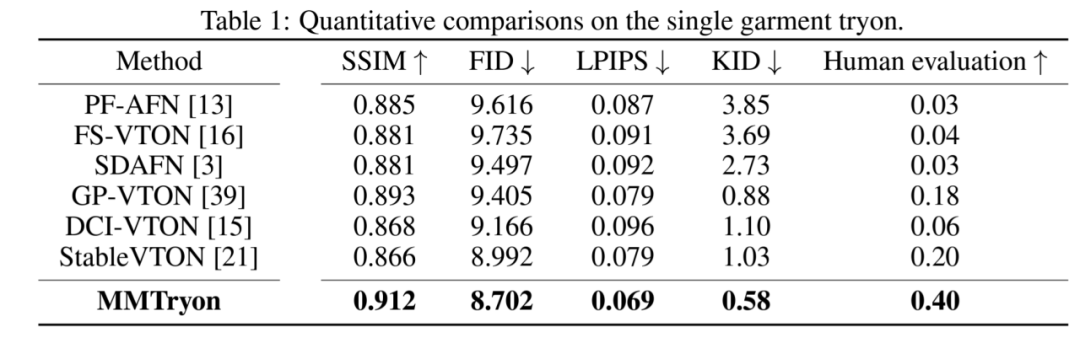
在量化指标上,MMTryon优于其他baseline的的效果,在开源数据集测试集合的Human evaluation中,MMTryon也超过其它baseline模型
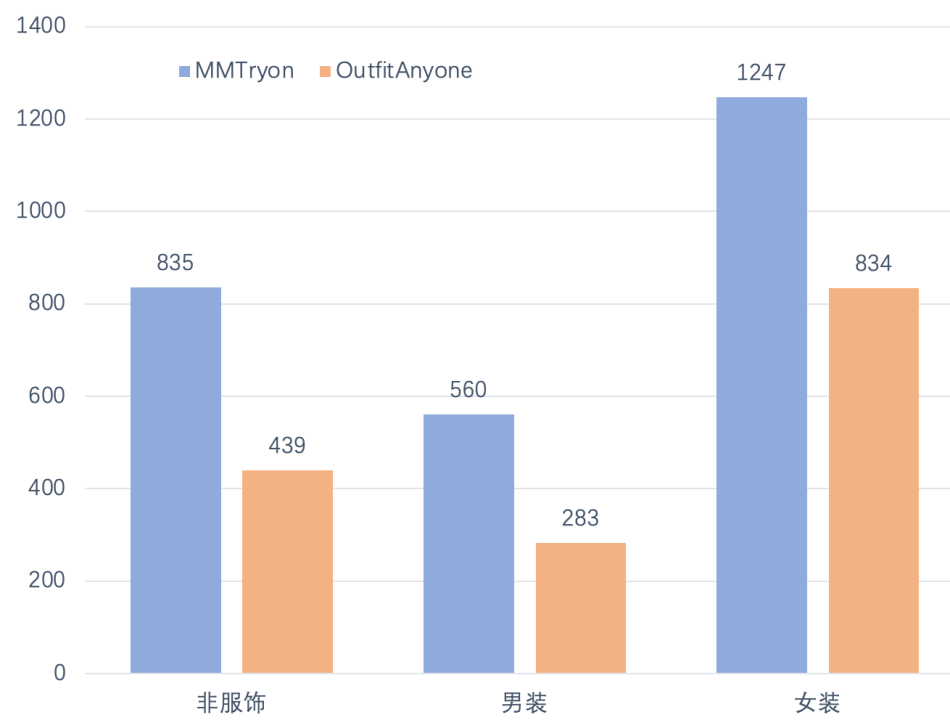
在复杂场景的Human evaluation中,MMTryon也超越了目前的社区模型outfit anyone。
研究人员收集了复杂场景女装图片142张,男装图片57张,非服装图片87张,共邀请15位参与者参与评测,选择更喜欢的方案结果。从图表中可以看出,MMTryon的效果更受测试者的喜欢。
更多细节,感兴趣的家人们可以查看论文~
论文链接:https://arxiv.org/abs/2405.00448
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









