







扁鹊(BianQue)
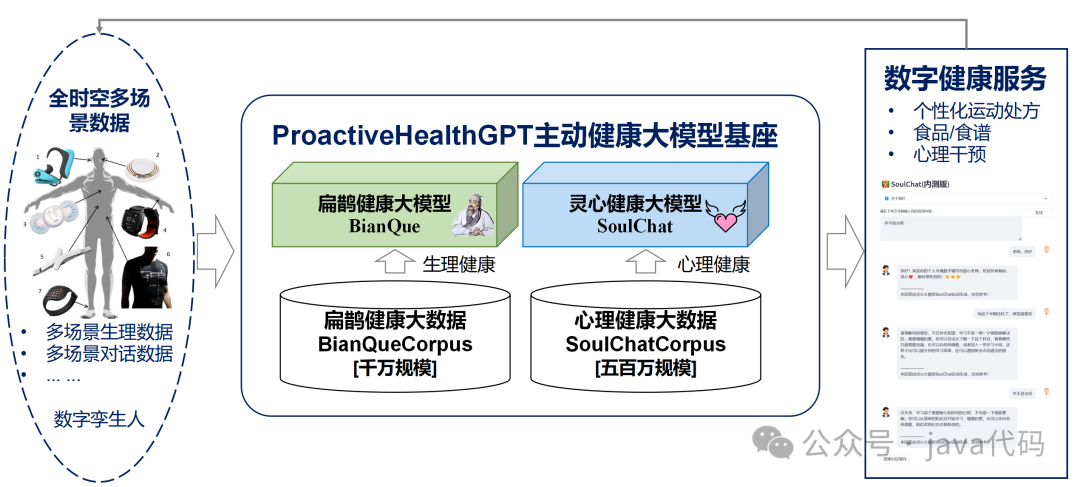
基于主动健康的主动性、预防性、精确性、个性化、共建共享、自律性六大特征,华南理工大学未来技术学院-广东省数字孪生人重点实验室开源了中文领域生活空间主动健康大模型基座ProactiveHealthGPT。
我们期望,生活空间主动健康大模型基座ProactiveHealthGPT 可以帮助学术界加速大模型在慢性病、心理咨询等主动健康领域的研究与应用。本项目为 生活空间健康大模型扁鹊(BianQue) 。
扁鹊健康大数据BianQueCorpus
我们经过调研发现,在健康领域,用户通常不会在一轮交互当中清晰地描述自己的问题,而当前常见的开源医疗问答模型(例如:ChatDoctor、本草(HuaTuo,原名华驼 )、DoctorGLM、MedicalGPT-zh)侧重于解决单轮用户描述的问题,而忽略了“用户描述可能存在不足”的情况。哪怕是当前大火的ChatGPT也会存在类似的问题:如果用户不强制通过文本描述让ChatGPT采用一问一答的形式,ChatGPT也偏向于针对用户的描述,迅速给出它认为合适的建议和方案。然而,实际的医生与用户交谈往往会存在“医生根据用户当前的描述进行持续多轮的询问”。并且医生在最后根据用户提供的信息综合给出建议,如下图所示。我们把医生不断问询的过程定义为 询问链(CoQ, Chain of Questioning) ,当模型处于询问链阶段,其下一个问题通常由对话上下文历史决定。

我们结合当前开源的中文医疗问答数据集(MedDialog-CN、IMCS-V2、CHIP-MDCFNPC、MedDG、cMedQA2、Chinese-medical-dialogue-data),分析其中的单轮/多轮特性以及医生问询特性,结合实验室长期自建的生活空间健康对话大数据,构建了千万级别规模的扁鹊健康大数据BianQueCorpus。对话数据通过“病人:xxx\n医生:xxx\n病人:xxx\n医生:”的形式统一为一种指令格式,如下图所示。

input: "病人:六岁宝宝拉大便都是一个礼拜或者10天才一次正常吗,要去医院检查什么项目\n医生:您好\n病人:六岁宝宝拉大便都是一个礼拜或者10天才一次正常吗,要去医院检查什么项目\n医生:宝宝之前大便什么样呢?多久一次呢\n病人:一般都是一个礼拜,最近这几个月都是10多天\n医生:大便干吗?\n病人:每次10多天拉的很多\n医生:"target: "成形还是不成形呢?孩子吃饭怎么样呢?"
训练数据当中混合了大量target文本为医生问询的内容而非直接的建议,这将有助于提升AI模型的问询能力。
使用方法
- 克隆本项目
cd ~
git clone https://github.com/scutcyr/BianQue.git
- 安装依赖 需要注意的是torch的版本需要根据你的服务器实际的cuda版本选择,详情参考pytorch安装指南
cd BianQue
conda env create -n proactivehealthgpt_py38 --file proactivehealthgpt_py38.yml
conda activate proactivehealthgpt_py38
pip install cpm_kernels
pip install torch==1.13.1+cu116 torchvision==0.14.1+cu116 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu116
- 【补充】Windows下的用户推荐参考如下流程配置环境
cd BianQue
conda create -n proactivehealthgpt_py38 python=3.8
conda activate proactivehealthgpt_py38
pip install torch==1.13.1+cu116 torchvision==0.14.1+cu116 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu116
pip install -r requirements.txt
pip install rouge_chinese nltk jieba datasets
# 以下安装为了运行demo
pip install streamlit
pip install streamlit_chat
- 【补充】Windows下配置CUDA-11.6:下载并且安装CUDA-11.6、下载cudnn-8.4.0,解压并且复制其中的文件到CUDA-11.6对应的路径&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 774
774

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









