






“ 在你的电脑上运行一个强大的AI助手,它不仅能力超群,还把所有秘密都藏在你的硬盘里。好奇这是如何实现的吗?动动手,三分钟就可以完成LLaMA-3的本地部署!”

01
—
LLaMA-3
最近在试验检索增强生成(RAG)的项目,想试试换一个强点的模型试试看效果是否有改观,动手试了一下本地搭建一个私有大模型作为基模型,这次试试LLama3,下次搭阿里通义千问的Qwen2模型。
早在4月份,Meta开源了 LLaMA-3(Large Language Model Meta AI 3), 在多个关键的基准测试中性能优于业界先进同类模型,其在代码生成等任务上实现了全面领先,能够进行复杂的推理,可以更遵循指令,能够可视化想法并解决很多微妙的问题。
主要亮点:
- 基于超过 15T token 训练,相当于 Llama 2 数据集的 7 倍还多;
- 支持 8K 长文本,改进的 tokenizer 具有 128K token 的词汇量,可实现更好的性能;
- 在大量重要基准中均具有最先进性能;
- 新能力范畴,包括增强的推理和代码能力;
- 带有 Llama Guard 2、Code Shield 和 CyberSec Eval 2 的新版信任和安全工具。
02
—
安装Ollama
Ollama 是一款在本地环境中运行和管理大型语言模型(LLMs)的开源工具。它为开发者、研究人员和爱好者提供了一个高效、易用的平台,能够快速实验、管理和部署最新的大语言模型。
技术特点与优势:
-
本地部署:Ollama 允许用户在本地启动并运行各种大型语言模型,如 Llama 2、CodeLLaMA、Falcon 和 Mistral 等。这不仅降低了使用大语言模型的门槛,还提高了数据隐私和安全性。
-
丰富的模型库:Ollama 提供了一个预构建的模型库,支持多种流行的大语言模型,包括 Qwen2、Llama3、Phi3 和 Gemma2 等。这些模型可以轻松集成到各种应用程序中,满足不同场景的需求。
-
易于使用的接口:Ollama 提供了类似于 OpenAI 的 API 接口和聊天界面,方便用户进行模型的部署和使用。此外,它还支持基于命令行的方式运行多种大语言模型,并提供了相应的 Python 和 JS SDK,方便实现 Chatbot UI。
-
可定制性:Ollama 具有高度的可定制性,允许用户创建和运行自定义的语言模型。
-
跨平台支持:Ollama 支持 macOS、Linux 和 Windows(预览版),并且可以在使用 Docker 快速部署。这大大增强了其适用性和灵活性。
安装环境:普通的联想台式机,无GPU。安装过程不需要科学上网。
Ollama 官方下载地址:https://ollama.com/download。根据自己的操作系统选择不同的版本。
Github 上也有Docker版本:https://github.com/ollama/ollama。

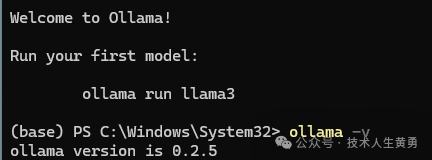
安装完成,查看版本,验证是否安装成功。
ollama -v
03
—
下载模型
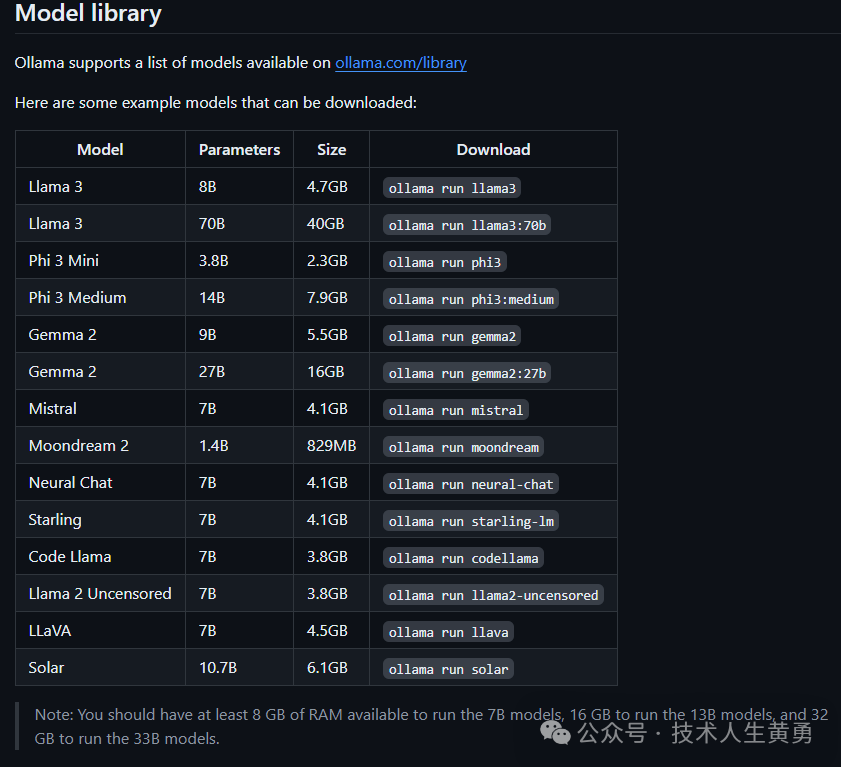
安装完成后可以直接下载内置的诸多开源模型,下面为内置的部分模型名称。
内存要求:至少8GB可用内存运行7B模型,16GB运行13B模型,32GB运行33B模型。
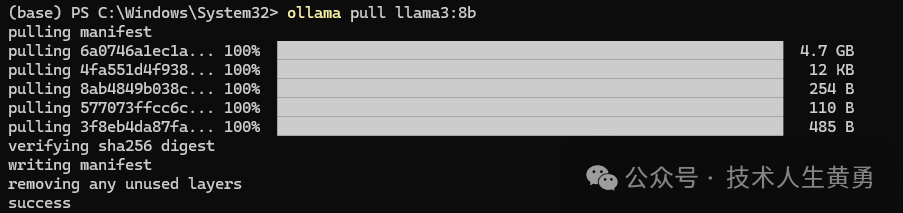
下载llama3:8b,冒号前面为模型名称,冒号后面型号,也是模型参数大小。
ollama pull llama3:8b
运行模型:
ollama run llam3
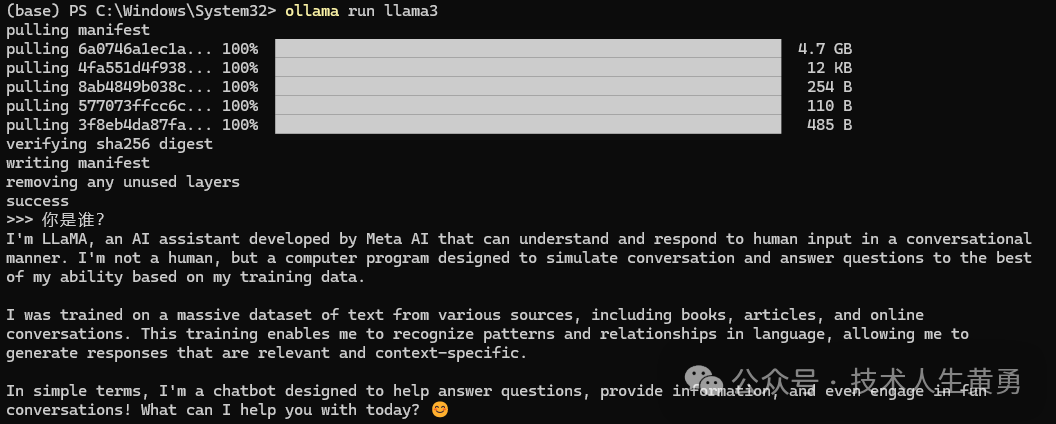
因为国外模型,默认回答英文,指定模型中文回复即可。
使用命令行显然很不方便,咱们使用 Docker 给大模型一个对话的 Web界面,使用下面命令启动 Open WebUI,注意修改 open-webui-data后面本地路径。前提:本地先安装好 Docker 服务。
docker run -p 8080:8080 -e OLLAMA_BASE_URL=http://host.docker.internal:11434 --name open-webui --restart always -v open-webui-data:/DATA/ ghcr.io/open-webui/open-webui:main
经过漫长的拉取镜像过程后,显示了启动界面。
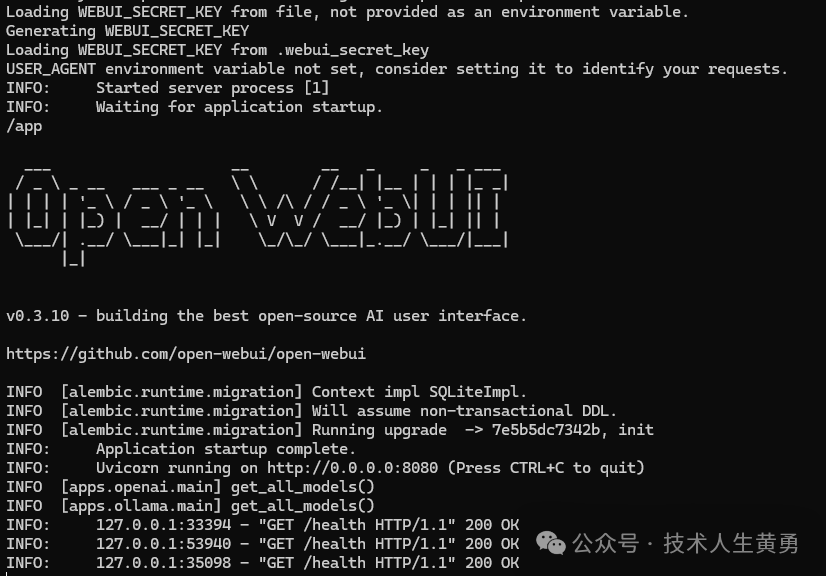
在浏览器地址栏输入 http://127.0.0.1:8080,第一次访问时需要注册用户登录后就可以看到类似Chat-GPT的聊天对话界面,对话之前,在左上角选择咱们刚下载好的llama3:latest。
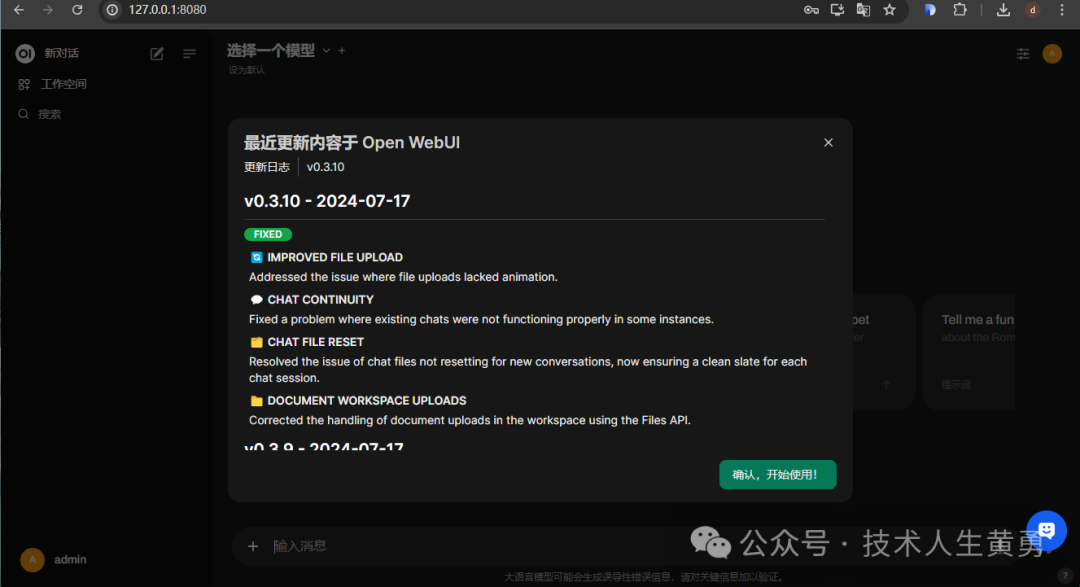
通过web界面用中文询问同样的问题,就不需要向命令行交互那样,指定大模型使用中文回答。

提供对话生成的 API 服务
搭建本地模型目的是为了项目所用,所以我们还需要与 OpenAI 类似的对话生成的 API,使用前先点击设置 - Account,生成一个API Key,就可以用这个 Key 来调用 API了。
命令行的 curl 测试命令:
$ curl -X POST -H “Authorization: Bearer api key” -H “Content-Type: application/json” http://localhost:8080/ollama/api/generate -d ‘{“model”:“llama3-cn:latest”,“stream”:false,“prompt”:“你是谁?你能做什么”}’
对话生成速度略显慢一点,实测时能看到一个字一个字往外蹦,开始回答上面的问题大约需要1~2秒,回答完估计在10秒左右。
到这里,我们有了一个无需GPU硬件资源,对话内容、文档数据等等都存储在本地,属于我们私有的大模型。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。















 1781
1781

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









