






ChatDev——大语言模型驱动的多智能体协作与演化
视频号
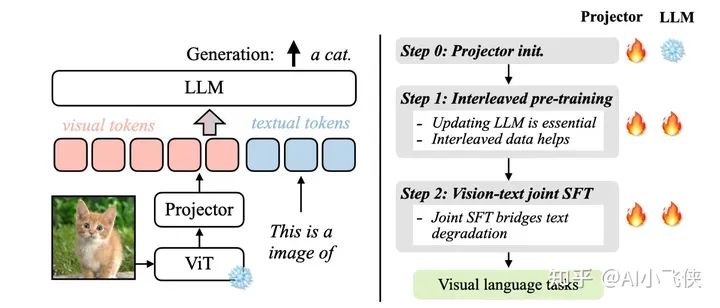
目前主流的多模态大模型的训练基本都是分为预训练和微调两阶段来进行的。
预训练阶段是为了让大语言模型(LLM)具有理解视觉信息的能力,也可以认为是将视觉特征空间对齐到文本空间。
微调阶段就是使用特定领域的数据,通过全量参数或者 LoRA这种参数高效的方法微调,让模型熟悉特定领域的知识。
VILA 这篇文章的研究重点就是从模型架构,数据构造,训练策略三个角度出发,找到一个最优的预训练方法。

主要结论
- • 在预训练阶段冻结 LLM,在 zero-shot上的性能可以达到最优。但如果需要上下文学习的能力,需要在预训练阶段放开 LLM 的参数;
- • 图片文本相互交叉的预训练数据比较有利于训练,单纯的图片文本对并不是最优的;
- • 在指令微调阶段,将纯文本指令数据混杂到图片-文本数据中,不仅能缓解纯文本任务性能的下降,而且能提高视觉、语言模型(VLM)任务的准确率。

相比较于 LLaVA1.5而言,VILA 几乎实现了全面的超越。
预训练VLM
更新LLM 是至关重要的

- • 预训练阶段是否放开 LLM,在 zero-shot上的性能完全一样。但是在 4-shot测试中,预训练阶段放开 LLM 能提高 11%,说明预训练放开 LLM 能极大提高模型的上下文学习能力;
- • Projector结构为 Linear 明显优于 Transformer层的堆叠,作者猜测是因为简单的 Linear 能促使 LLM 学习更多处理视觉信息的能力,从而导致更好的泛化性能。
深层 embedding 对齐假设
作者猜测,之所以微调 LLM 很关键,是因为在深层的隐空间中对齐图像和文本信息是非常重要的。
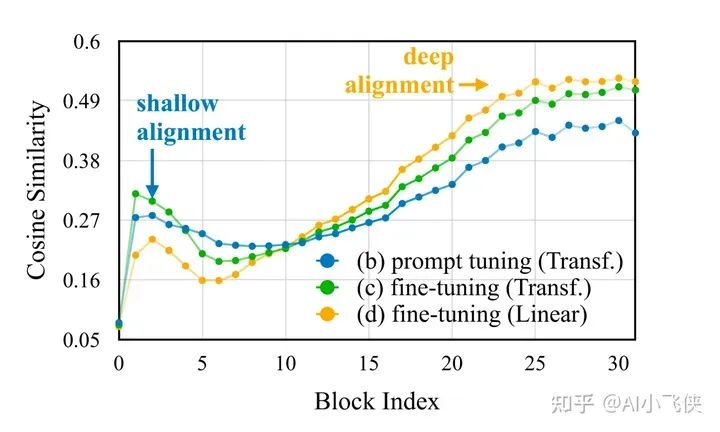
相互交叉的视觉语言语料库能帮助预训练
选择预训练数据

- • MMC4 是图片文本相互交叉的数据集,平均每个样本对应 4 张图片,每张图片对应 122.5 个 tokens;
- • COYO 是图文对数据集,文本部分都比较短,每张图片对应 22.7 个 tokens;
- • 训练的时候每个数据集根据 CLIP特征的相似度选择 25M 张图片;
交叉数据是至关重要的
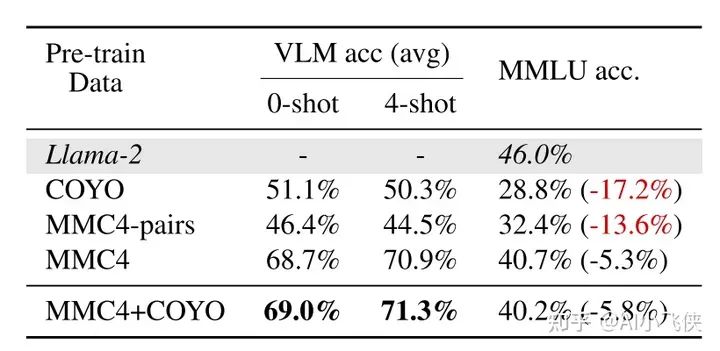
- • 使用图文对数据集 COYO 训练之后,LLama2的文本能力遭到灾难性遗忘,纯文本准确率(MMLU)下降 17.2%;
- • 使用图文交叉数据集 MMC4 训练之后,纯文本能力相较于原始的 Llama2仅仅下降 5.3%,多模态能力相较于 COYO 训练的模型得到极大提升,在 0-shot测试中提升 17%;
相互交叉的数据构成很重要,而不是因为文本分布
MMC4 数据集中文本长度较长,文本数据比较接近于纯文本数据的分布,可能是这个原因导致在纯文本任务中表现较好。
为了排除是因为 MMC4 文本较长导致的在MMLU 上结果较好,作者将 MMCU 改成图文对数据MMC4-pair。
MMC4:<txt1><im1><txt2><txt3><im2><txt4>
MMC4-pair: <im1><txt2>, <im2><txt4>
- • MMC4-pairs在纯文本任务MMLU上稍微减小了 COYO 的性能下降,这可能是因为较长的文本;
- • MMC4-pairs相较于 COYO 在多模态任务上结果变得更差,这可能是因为MMC4-pairs数据中图片和文本没有很强的匹配关系;

- • MMC4相较于 MMC4-pair在训练过程中损失更低,这表明完整的文本分割提高了更多的信息;
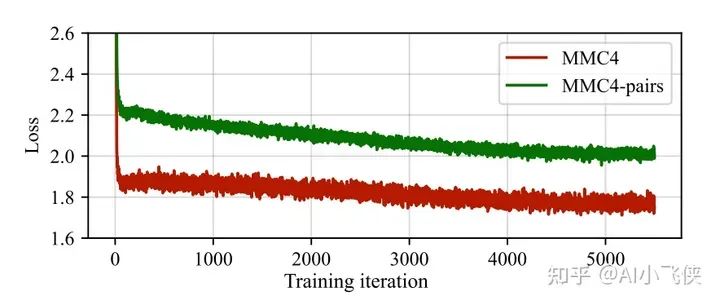
- • 综合上面的分析可以得出结论:相互交叉的数据允许模型去选择图片相关的信息,不会更多强迫模型去学习不相关的文本建模。
数据混合提高预训练
- • 在混合了 MMC4 和 COYO 后,在多模型任务中模型进一步获得了提高。
结合有监督微调(SFT)后恢复了LLM的下降
即使在预训练的数据中混合了图片文本相互交杂的数据,但纯文本任务还是有 5% 的下降。
这个问题可以在预训练的时候添加文本数据来解决,但是纯文本数据的比例又很难去确定。
作者发现,纯文本能力并没有遗忘,只是暂时隐藏了。只要在微调的时候添加了一点纯文本数据,就能完全恢复 LLM 在纯文本任务上的能力。
联合有监督微调
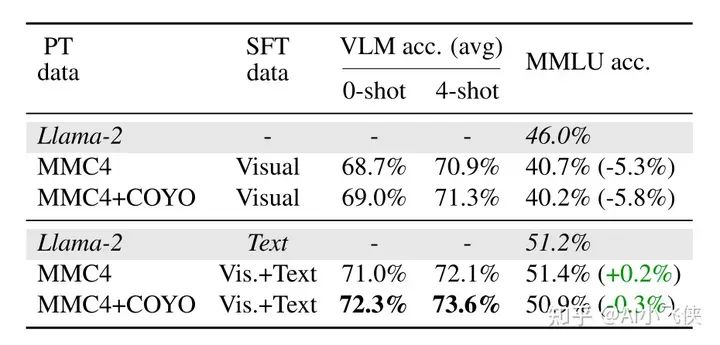
- • 一般的多模态大模型在微调阶段只使用视觉语言数据,这会导致纯文本任务性能的下降;
- • 作者在 FLAN 中采样 1M纯文本指令数据,混杂在多模态数据集中微调模型;
- • 结果表明,这种方法不仅完全恢复了 LLM 的纯文本能力,而且也进一步提高了模型在多模态任务中的能力;
- • 这可能是因为纯文本数据提高了模型的指令跟随能力,这个能力对于多模态任务也很重要。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。















 171
171

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









