






在消费级硬件上部署大型语言模型(LLM)可能会面临一些难题。如果LLM的模型参数规模超出了GPU的内存容量,通常会采用量化技术来降低其体积。然而,量化后,模型的体积可能依然过大,无法被GPU容纳。一个替代方案是在CPU的RAM上运行那些为CPU推理而优化的框架,例如llama.cpp。
Intel也在努力提升CPU上的推理速度。他们开发了一个基于Hugging Face Transformers的框架,名为Intel的Transformer扩展,使用起来非常方便,能够充分利用CPU的性能。
Neural Speed,一个依赖于Intel Transformer扩展的框架,进一步加速了在CPU上运行4位LLM的推理过程。Intel声称,使用这个框架可以使推理速度比llama.cpp快40倍???
在这篇文章中,我们将回顾Neural Speed带来的主要优化,并展示如何使用它进行推理吞吐量的基准测试。同时,我也会将其性能与llama.cpp进行对比。
Neural Speed 针对 4 位 LLM 的推理优化
在 NeurIPS 2023 上,英特尔展示了 CPU 推理的主要优化:CPU 上的高效 LLM 推理。在下图中,绿色的组件是 Neural Speed 为高效推理带来的主要新增内容:
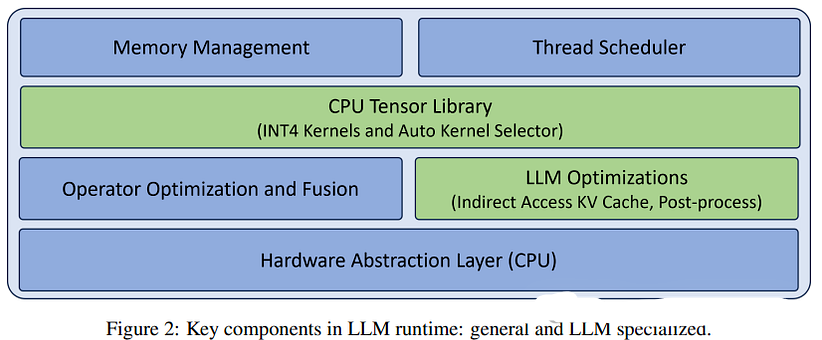
CPU张量库包含了多个针对4位模型推理进行优化的内核,这些内核不仅适用于Intel的x86 CPU,还支持AMD的CPU。这些内核特别针对使用INT4数据类型进行量化的模型进行了优化处理。Neural Speed框架支持并加速了GPTQ、AWQ和GGUF等模型。此外,如果模型尚未量化,Intel还提供了自己的量化工具库——Neural Compressor,以便于进行量化处理。
关于上图中提到的“LLM优化”,Intel在其NeurIPS论文中并没有详细阐述。他们仅仅提到了KV缓存的内存预分配,暗示当前的框架可能没有进行这种预分配。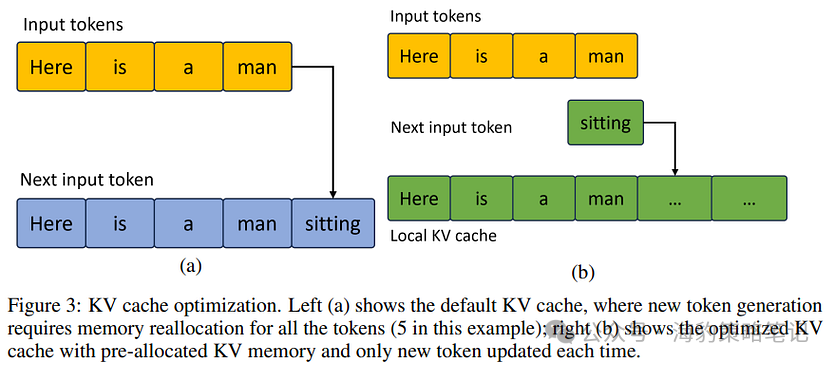
论文展示了一个与推理效率相关的基准。他们测量了下一个词的预测延迟,并将其与基于 ggml 的模型(即以 GGUF 格式由 llama.cpp 量化的模型)的延迟进行了比较。
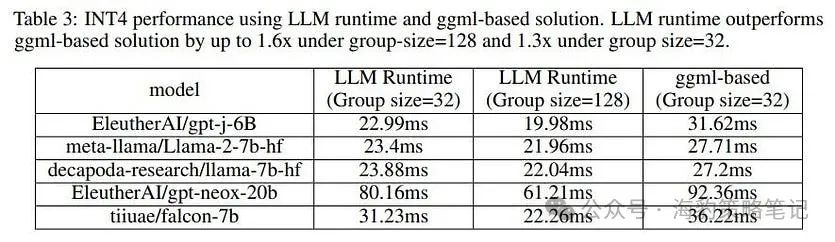
它们没有提及用于获取这些结果的硬件配置。根据这些实验,Neural Speed 预测下一个标记的延迟比 llama.cpp 低 1.6 倍。
GPU加速推理
我们可以用 pip 以及我们需要的所有其他库来安装它:
pip install neural-speed intel-extension-for-transformersacceleratedatasets
Neural Speed 由 Intel 的 transformer 扩展直接调用。我们不需要导入它,但需要导入 transformers 的扩展。注意:我们不是从 “transformers” 导入的,而是从 “intel_extension_for_transformers.transformers” 导入:
from intel_extension_for_transformers.transformers import AutoModelForCausalLM
然后,以 4 位加载模型:
model = AutoModelForCausalLM.from_pretrained(
model_name, load_in_4bit=True)
Intel 的 transformer 将以 4 位量化和序列化模型。这可能需要时间。使用 Google Colab 的 L4 实例的 16 个 CPU,7B 模型大约需要 12 分钟。
我对这个模型的推理吞吐量进行了基准测试,仍然使用 Google Colab 的 L4 实例。使用 Neural Speed 和英特尔的量化,它平均可以产生:
每秒 32.5 个tokens
确实很快。但它比 llama.cpp 快吗?我用 llama.cpp 到 4 位(类型 0)量化了模型。然后,我将这个模型与 llama.cpp 一起运行推理。它产生:
每秒 9.8 个*tokens*
它比 Neural Speed 慢得多,但我们与 Neural Speed 的 GitHub 页面上提到的“比 llama.cpp 快 40 倍”相去甚远。请注意,对于这两个框架,我没有尝试不同的超参数或硬件。
作者认为,加速取决于 CPU 内核的数量。llama.cpp 和 Neural Speed 之间的速度差距应该会随着内核的增加而更大,Neural Speed 会越来越快。Neural speed 还支持 GGUF 格式。我使用加载的蛋黄酱的 gguf 版本再次运行基准测试,如下所示:
model_name = "kaitchup/Mayonnaise-4in1-02"
model = AutoModelForCausalLM.from_pretrained(
model_name, model_file = "Q4_0.gguf"
)
发现它比使用 Neural Speed 创建的量化模型快 25%:
每秒 44.2 个t0kens
比 llama.cpp 快 4.5 倍。
结论
Intel Neural Speed确实表现出色,虽然无法验证其速度是否真的比llama.cpp快40倍,但即使只有4.5倍的加速,也已经相当牛逼了。
在选择CPU还是GPU进行推理时,需要考虑几个因素。随着CPU推理性能的提升,尤其是在处理单个实例(批量大小为1)时,CPU和GPU之间的速度差异已经变得不那么明显。然而,当处理两个或更多大小的批处理时,如果有足够的可用内存,GPU通常会提供更快的性能。这主要是因为GPU拥有卓越的并行处理能力,能够同时处理大量数据。
总的来说,如果内存资源充足,且需要处理较大批量的数据,GPU可能是更好的选择。但如果内存有限,或者主要处理单个实例,CPU上的推理性能已经足够强大,可以考虑使用CPU进行推理。随着技术的进步,CPU和GPU之间的性能差距可能会继续缩小。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









