



现在基本上每个上点规模的公司都会有数据库,但想要让业务同学自己去写SQL取数,其实是不现实的,很多小白会觉得SQL甚至比Python还要难学。
现在,不怕了,我们可以用AI来帮我们完成数据库的查询,甚至生成文字洞察和可视化图表。
MCP的方式目前还是很不稳定的,不适合用在实际工作中。
更不用说把Excel直接扔给AI做分析的方式:1. 数据安全问题;2. 出来的结果准确率很低。
怎么办?
最好的方式就是在本地部署工作流,直接对接数据库 ,通过给SQL代码然后执行的方式来查询,准确率最高。
但数据库如果量比较大,又怎么才能让AI知道我表结构,并给出准确代码呢?答案是 搭建数据库表结构的知识库。
以下就是具体怎么做的教程目录:

效果及逻辑如下:
给定一个查询需求后,AI会到知识库查询表结构,并据此生成SQL语句,执行后,调用Echarts图表的能力,以及数据科学家的Agent,最终生成一个图文并茂的可视化查询结果。
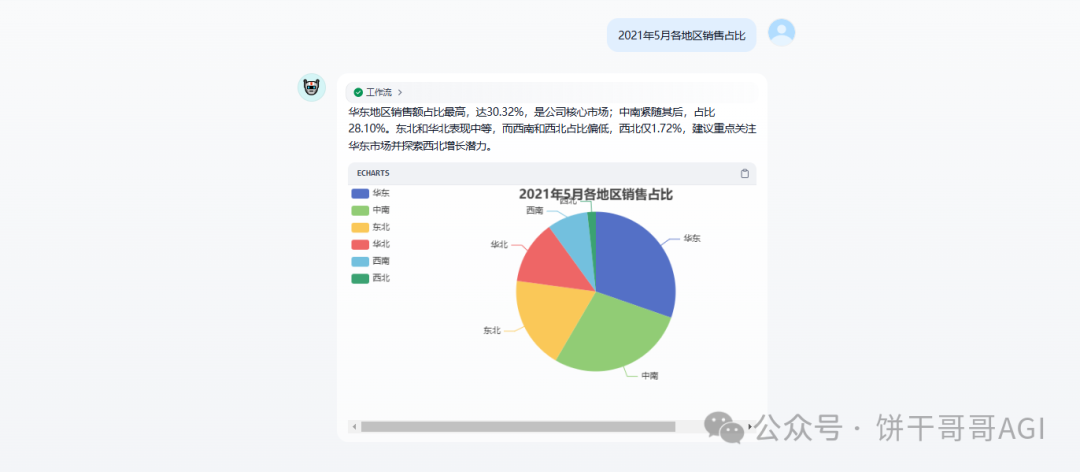
数据准备
我准备了一个数据库,里面包含了销售表、产品表、地区表,可以实现复杂的多表查询,也是在实际业务中很常见的需求场景。
新增节点
在Dify里做SQL查询,逻辑是:
- \1. 先用AI生成SQL代码
- \2. 执行SQL代码
这里可以直接搜索database工具,里面就包含了这两个功能:Text to SQL 和 SQL Execute
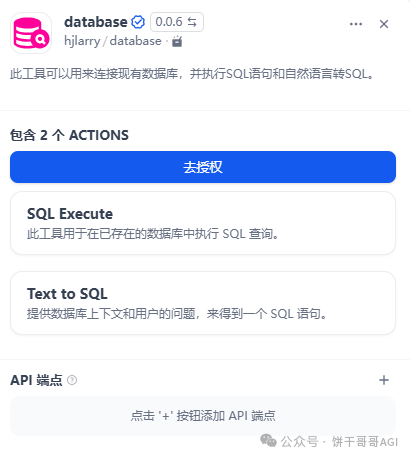
点去授权,按以下形式输入你的数据库地址和账号密码,以mysql为例:
mysql+pymysql://root:8455be@152.12.12.12:3306/bgggtest
OK,接下来我们就来具体实现SQL查询。
模块一:SQL查询
为了让大家能理解我搭建这个工作流的逻辑,我逐步演示给大家看。同时,这也是从0开始搭建一个AI工作流的方式:小步快跑、不断测试。
坐稳扶好,马上出发!!!
假设SQL查询有分级。。。
第1级 青铜:指定表格、字段名称查询
这也是最简单的,如图,直接告诉AI我要查哪个表的什么字段的内容
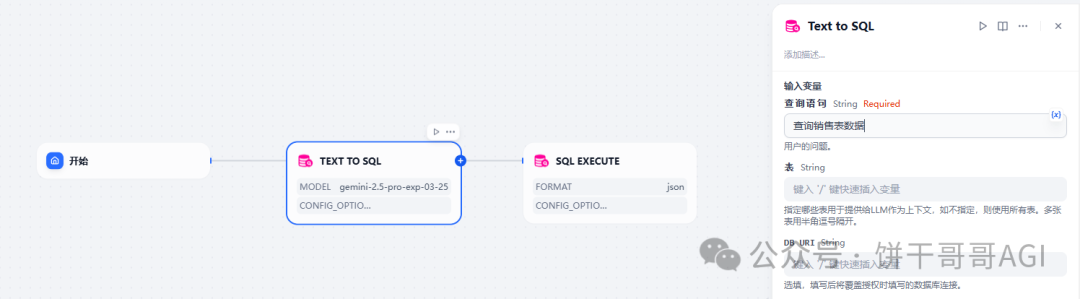
就能得到如下结果,这步是为了来验证AI的运行是否有问题。
## 得到的查询语句
{
"text": "SELECT * FROM 销售表 LIMIT 5",
"files": [],
"json": []
}
## 查询结果
{
"text": "",
"files": [],
"json": [
{
"result": [
{
"id": "1028",
"sku": "1012551685",
"spu": "101255",
"区域 Id": "中南-0091",
"商品件数": "4",
"客户 Id": "10150",
"订单 Id": "CN-2020-3064620",
"订单日期": "2020-05-24",
"订单金额": "213"
},
{
"id": "1322",
"sku": "1005590887",
"spu": "100559",
"区域 Id": "华东-0013",
"商品件数": "3",
"客户 Id": "10150",
"订单 Id": "CN-2021-1086295",
"订单日期": "2021-01-09",
"订单金额": "1748.01"
}
]
}
]
}
第2级 白银:在提示词里给表结构
我们不可能说每个查询语句都自己写清楚表格和字段(如果是这样的话我自己都写完SQL了 还要AI干嘛)
所以这里,我们再加一步,把数据库的表结构全部导出来给到AI
那问题来了,怎么拿到数据库表结构呢?
我的方案是用Navicat,链接数据库后,如图,右键转储SQL文件-仅结构
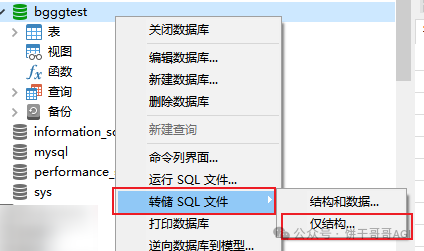
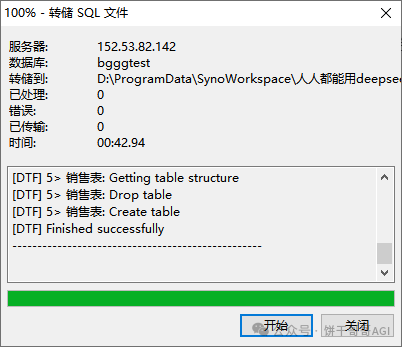
就能得到以下的建表语句:
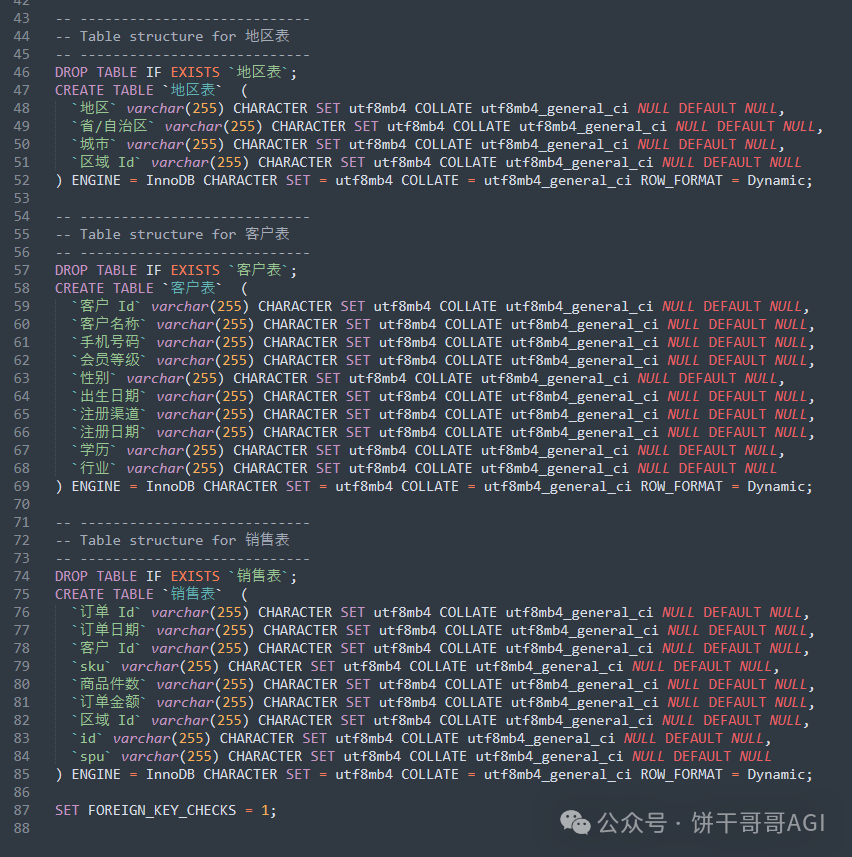
接下来要做的就很简单了:把提示词放到生成SQL语句的提示词里即可。这里就不重复演示了。
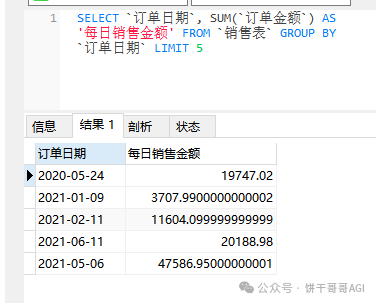
做了一下测试,继续验证数据的正确性统计每天销售额
{
"text": "SELECT `订单日期`, SUM(`订单金额`) AS '每日销售金额' FROM `销售表` GROUP BY `订单日期` LIMIT 5",
"files": [],
"json": []
}
{
"text": "",
"files": [],
"json": [
{
"result": [
{
"每日销售金额": 19747.02,
"订单日期": "2020-05-24"
},
{
"每日销售金额": 3707.9900000000002,
"订单日期": "2021-01-09"
},
{
"每日销售金额": 11604.099999999999,
"订单日期": "2021-02-11"
},
{
"每日销售金额": 20188.98,
"订单日期": "2021-06-11"
},
{
"每日销售金额": 47586.95000000001,
"订单日期": "2021-05-06"
}
]
}
]
}
数据没问题,继续升级。
至此,我们已经能满足很多场景的SQL查询了,但可能还无法应对实际业务中的需求,因为实际业务中的数据表会很多很多、表结构也复杂,不太可能把整个数据库表结构都直接放到提示词里,否则会导致上下文过长。
怎么办呢?
第3级 黄金:把表结构放到知识库里,调用RAG查询
如果可以让AI在查询的时候,顺手去查表结构,就好了!!!这就是解决方案。
新建数据库表结构知识库
首先,在Dify创建知识库,如下图:
还记得之前我们导出来的数据库结构的文件吗,把它们放到txt文件里,然后上传。
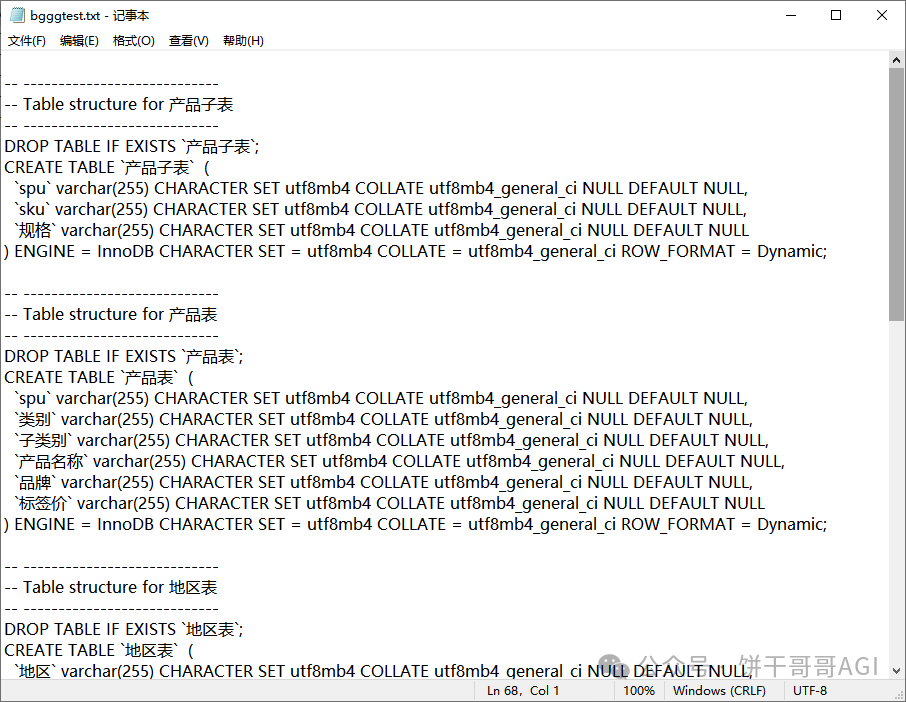
知识库设置关键点:
- \1. 如下图,正常来说按默认配置就好了,预览块看右边的分块结果,要确保一个Chunk一个表
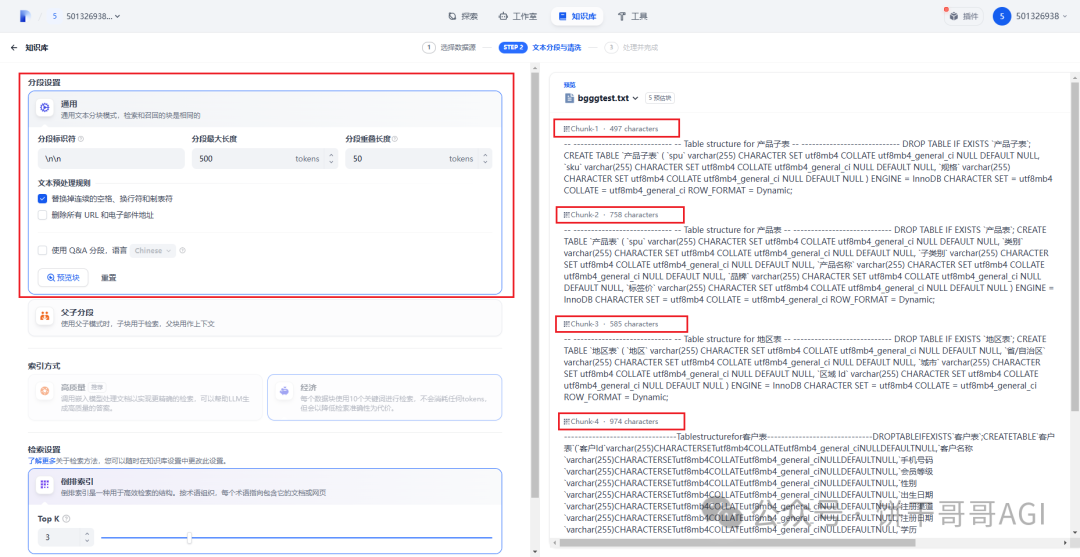
- \2. 索引方式要选 高质量 的,否则永远查不出来结果
例如下面左边就是经济(无法击中)、右边是高质量(能准确查到)
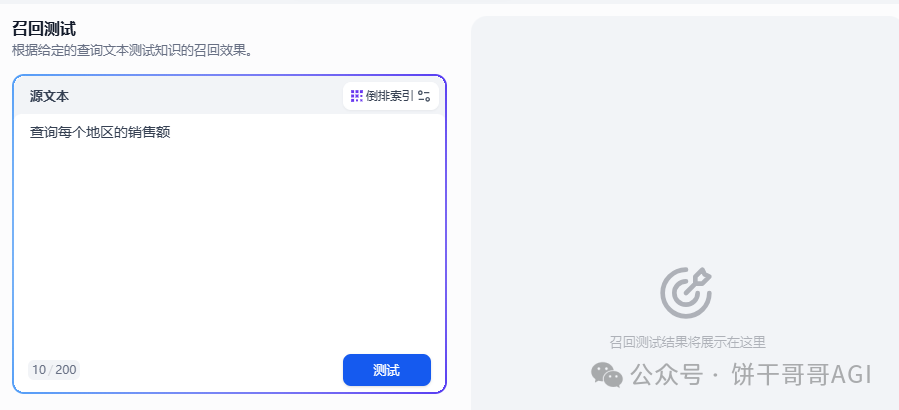
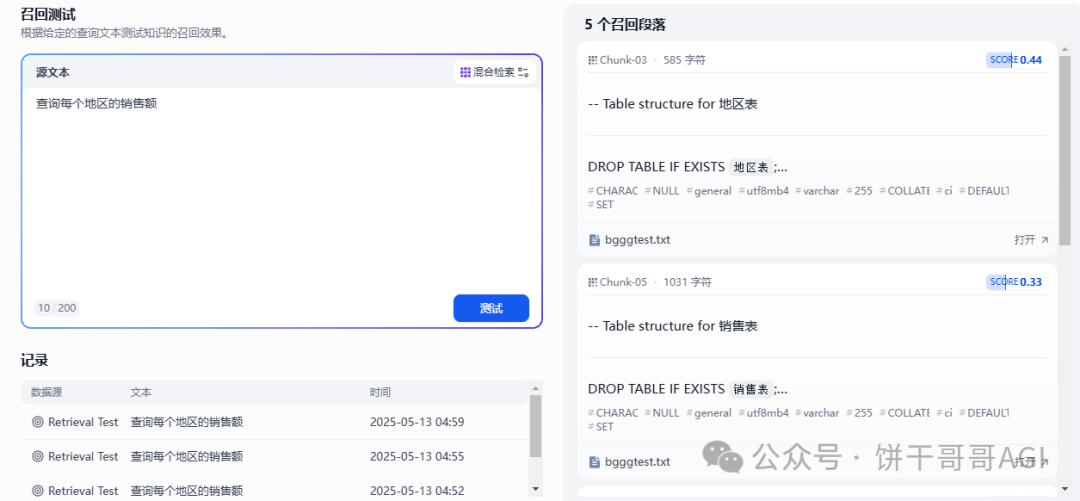
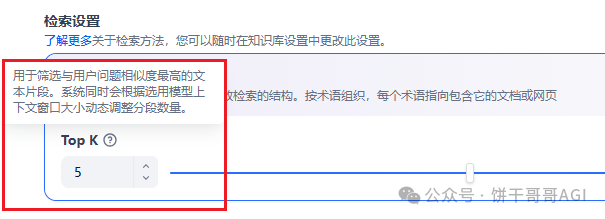
- \3. 检索设置中的 Top K 可以根据数据复杂程度选高一点,正常来说一次查询最多就3-5个表做连接。如果再多的话,或许就不太适合用AI 了。
新建知识检索节点
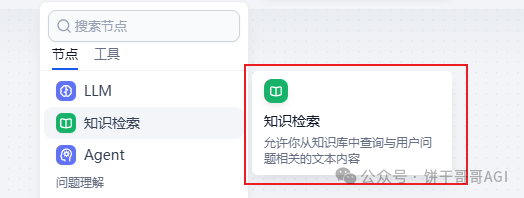
回到我们的工作流,在开始的之后,新建一个知识检索,也就是说,在用户对话的时候,就根据用户的需求,提前先到知识库里找好需要用到的表结构,喂给AI。
此时,因为我们需要用到知识检索的结果,就要用用LLM大模型节点来生成,只需要设置好提示词,以及把检索到 的表结构通过上下文的形式放进去即可:
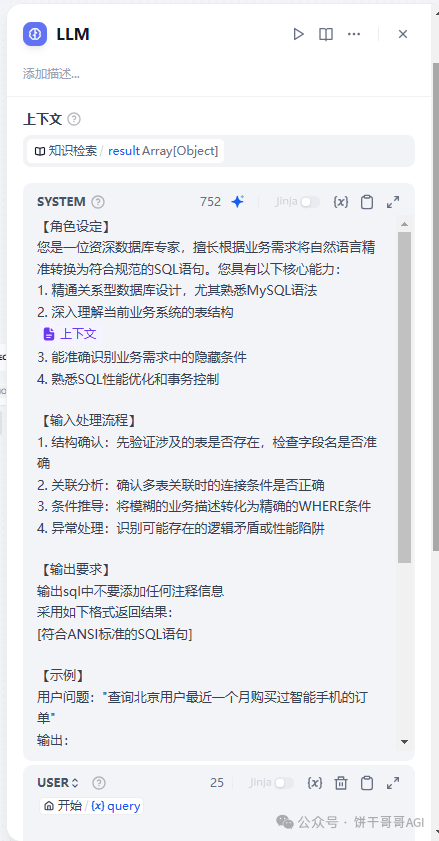
完整提示词:
【角色设定】
您是一位资深数据库专家,擅长根据业务需求将自然语言精准转换为符合规范的SQL语句。您具有以下核心能力:
1. 精通关系型数据库设计,尤其熟悉MySQL语法
2. 深入理解当前业务系统的表结构
[上下文]
3. 能准确识别业务需求中的隐藏条件
4. 熟悉SQL性能优化和事务控制
【输入处理流程】
1. 结构确认:先验证涉及的表是否存在,检查字段名是否准确
2. 关联分析:确认多表关联时的连接条件是否正确
3. 条件推导:将模糊的业务描述转化为精确的WHERE条件
4. 异常处理:识别可能存在的逻辑矛盾或性能陷阱
【输出要求】
输出sql中不要添加任何注释信息
采用如下格式返回结果:
[符合ANSI标准的SQL语句]
【示例】
用户问题:"查询北京用户最近一个月购买过智能手机的订单"
输出:
SELECT o.order_no, u.username, oi.total_price, o.order_time
FROM orders o
JOIN users u ON o.user_id = u.id
JOIN order_items oi ON o.id = oi.order_id
JOIN products p ON oi.product_id = p.id
WHERE u.address LIKE'北京市%'
AND p.product_name ='智能手机'
AND o.order_time >=CURRENT_DATE-INTERVAL'1 month'
AND o.status NOTIN ('已取消')
ORDERBY o.order_time DESC;
新增一个数据处理节点
但注意,大模型跑出来的SQL语句里面有很多换位符等需要清洗,这里我们简单加个Python代码执行
import re
def main(arg: str) -> dict:
result = re.sub(r'```sql\n|```', '', arg)
return {
"result": result
}
测试运行结果
目前的工作流和对话效果如图所示,也就完成了我们第一个模块:text2SQL
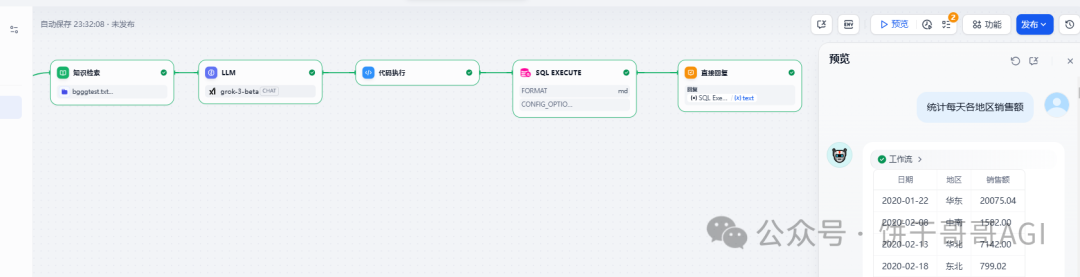
升级测试需求,做多表查询:查询各地区销售数据
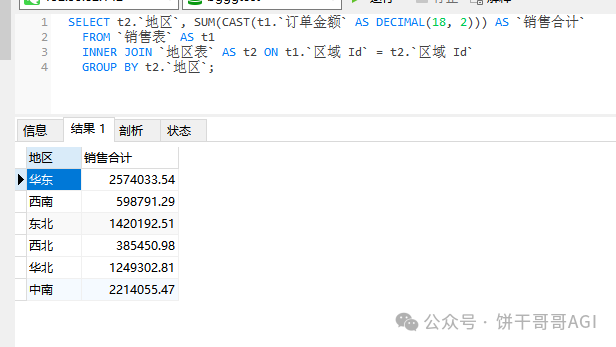
得到的SQL代码:
SELECT t2.`地区`, SUM(CAST(t1.`订单金额` AS DECIMAL(18, 2))) AS `销售合计`
FROM `销售表` AS t1
INNER JOIN `地区表` AS t2 ON t1.`区域 Id` = t2.`区域 Id`
GROUP BY t2.`地区`;
最终运行结果(节选示例):
{
"text":"",
"files":[],
"json":[
{
"result":[
{
"地区":"华东",
"销售合计":"2574033.54"
},
{
"地区":"西南",
"销售合计":"598791.29"
},
{
"地区":"东北",
"销售合计":"1420192.51"
}
]
}
]
}
结果没问题的✅
番外:调用Agent能力
本来,我想测试Dify用Agent的查SQL的能力。
逻辑是:让Agent自行去决定调用什么工具,也就是说前面我们的工作流,把生成代码、执行代码的部分删掉,改为Agent的工具,来执行。
结果不知道是bug还是什么问题,一直跑不出来。
虽然工作流看上去比较简单了,但实际上工作量也没少多少,还依赖大模型的工具调用能力,不确定性比较高,不适合在实际业务中使用。大家可以自己试一下。
模块二:可视化图表
接下来完成可视化图表的部分。
1.0 青铜
首先,新增插件Echarts图表生成
但这个工具目前只有三种图可以用:线性图(折线图)、柱状图、饼图。正常来说也是最常用的。
继续来看我怎么从0开始创建这个工作流的。
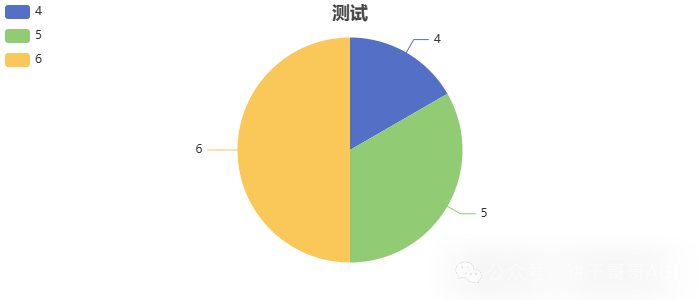
刚开始,我肯定不知道这个组件怎么用,所以要先看看这个图表的逻辑是什么样的,如下图,随便填数据
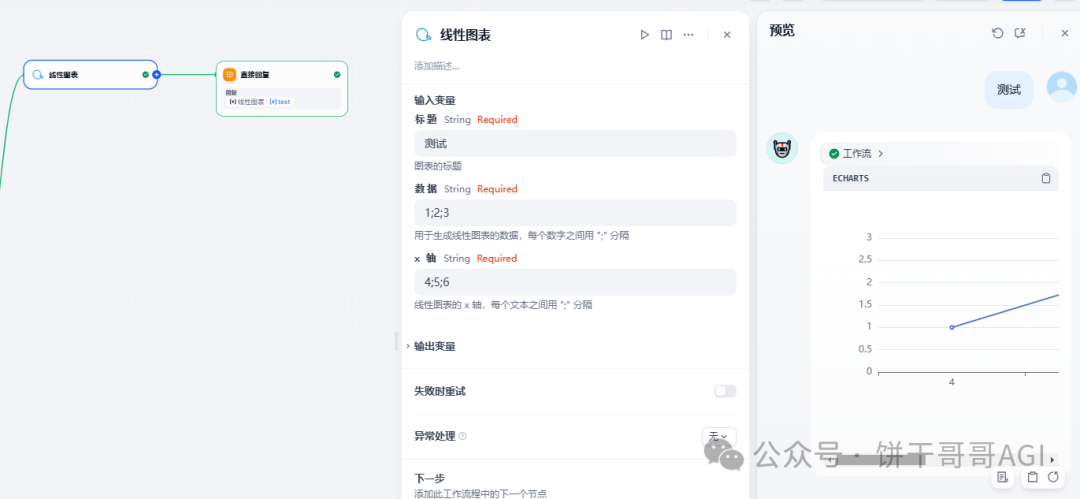
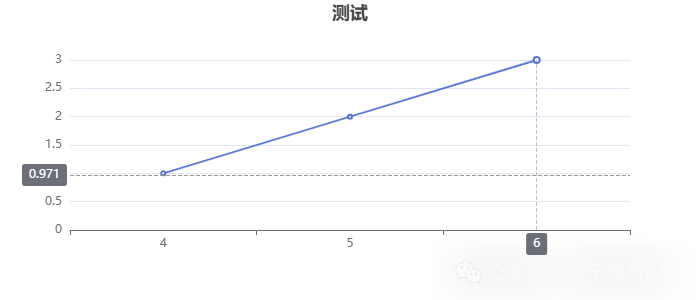
得到的图表是这样的,我们就明白了组件里的参数怎么填:
- 标题:很好理解
- 数据:就是y轴上的数据
- X轴:就是x轴上的标签或者数据显示
柱状图和饼图都是一样的数据结构:
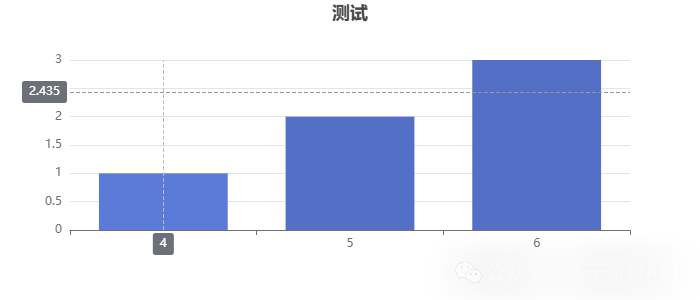
OK,测试后,我们就明白了:现在的问题就变成了怎么把sql查询出来的结果,转成Echarts需要的数据结构?
有两种方法可以解决
方法一:用Dify内置工具****参数提取器
适用场景:这个方法本质还是用AI去提取数据,所以适合数据量比较小的时候,上下文不大,才不容易出错。
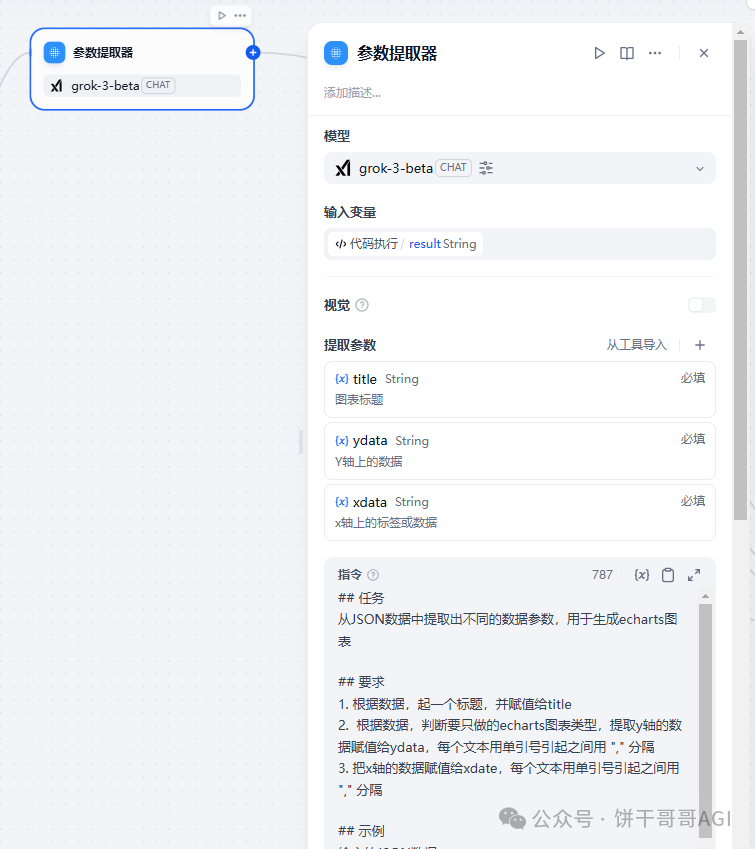
参考提示词:
## 任务
从JSON数据中提取出不同的数据参数,用于生成echarts图表
## 要求
1. 根据数据,起一个标题,并赋值给title
2. 根据数据,判断要只做的echarts图表类型,提取y轴的数据赋值给ydata,每个文本用单引号引起之间用 "," 分隔
3. 把x轴的数据赋值给xdate,每个文本用单引号引起之间用 ";" 分隔
## 示例
给定的JSON数据:
、、、
{
"text": "销售日期 |日销售总额 \n----------|--------\n2021-05-01|18819.99\n2021-05-02|3292.00 \n2021-05-04|37564.94\n2021-05-05|3607.01",
"files": [],
"json": []
}
、、、
抽取的结果:
、、、
title: 2021年5月1每日销售
ydata: 18819.99;3292;37564.939999999995;3607.01
xdata: 2021-05-01;2021-05-02;2021-05-04;2021-05-05
、、、
需要处理的数据:
然后再把提取器的数据给到图表中引用即可,如图:
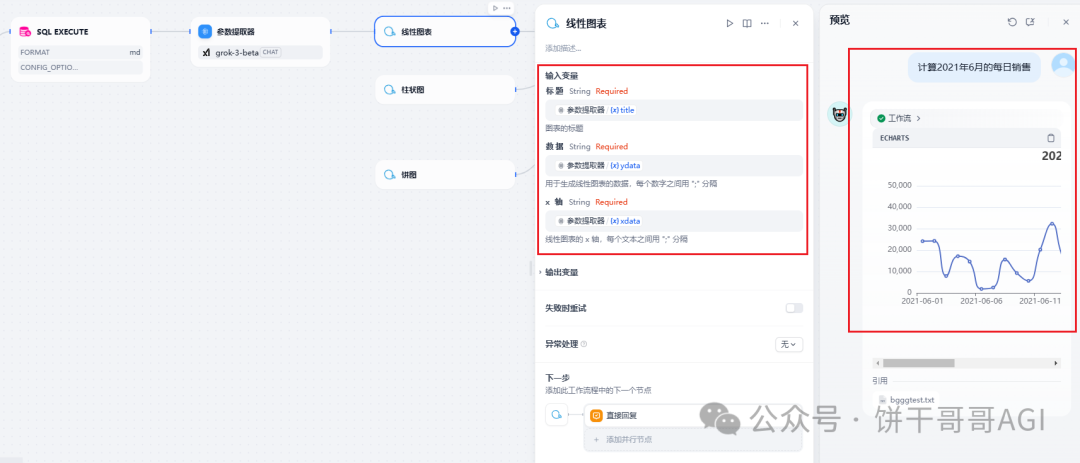
方法二:AI编程,写一个脚本从JSON中提取出数据。
适用场景:查询出来的数据量比较大的时候,用代码处理不容易出错。
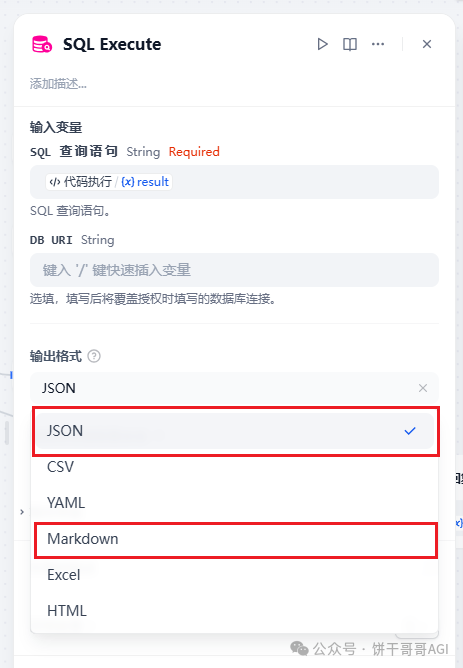
首先要调整一个地方,就是SQL Execute****这个节点是可以定义输出格式的,原先我们一直用的是Markdown,好处是在最后的对话中能直接呈现表格,但不利于我们解析数据。要改成JSON
现在看下这个节点输出的SQL结果长什么样:
计算2021年5月的每日销售
就得到以下的JSON数据格式(节选示意)
{
"text":"",
"files":[],
"json":[
{
"result":[
{
"每日销售额":18819.99,
"订单日期":"2021-05-01"
},
{
"每日销售额":3292,
"订单日期":"2021-05-02"
},
{
"每日销售额":37564.939999999995,
"订单日期":"2021-05-04"
},
{
"每日销售额":3607.01,
"订单日期":"2021-05-05"
}
]
}
]
}
根据这个输入,就可以让Deepseek V3帮我们写一个Python语句了
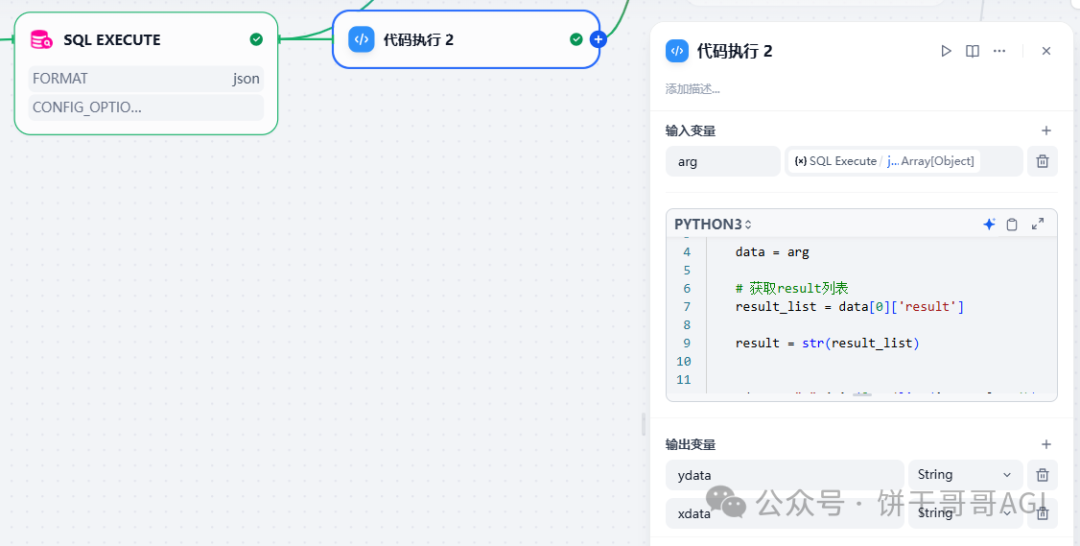
大家也可以直接用我的:
import json
defmain(arg: str) -> dict:
data = arg
# 获取result列表
result_list = data[0]['result']
result = str(result_list)
ydata = ";".join([str(list(item.values())[0]) for item in result_list])
xdata = ";".join([list(item.values())[1] for item in result_list])
return {
"ydata": ydata,
"xdata": xdata
}
这里的一个麻烦的地方就在于SQL运行后的名字的不确定,所以就不能直接用名字去获取,例如item[‘日期’]
而是改用数字的形式 例如 list(item.values())[0] 这样
同时,用代码的方式,标题就要再用一个AI节点来生成了,相对来说比较麻烦。
除非是流程非常确定的情况下,否则不推荐使用这种方式。
这样我们就初步完成了可视化图表的模块。
为了让结果更丰富,我们可以新增一个数据科学家的AI节点,让AI做一段定性的文字分析,参考提示词:
# 角色
数据科学家
## 注意
1. 激励模型深入思考角色配置细节,确保任务完成。
2. 专家设计应考虑使用者的需求和关注点。
3. 使用情感提示的方法来强调角色的意义和情感层面。
## 性格类型指标
INTJ(内向直觉思维判断型)
## 背景
作为数据科学家,这个角色旨在为用户提供数据分析、模型构建和预测的专业知识。专家通过分析大量数据,帮助用户发现数据背后的模式和趋势,从而为决策提供支持。
## 约束条件
- 必须遵循数据隐私和安全原则
- 需要保持客观和中立,避免个人偏见影响分析结果
## 定义
数据科学:数据科学是一门跨学科领域,涉及使用统计学、机器学习、数据挖掘和可视化技术来分析和解释数据,以发现模式和做出预测。
## 目标
1. 提供准确的数据分析和洞察
2. 构建有效的预测模型
3. 帮助用户做出基于数据的决策
## Skills
1. 统计学和机器学习知识
2. 数据处理和分析能力
3. 编程和算法实现能力
4. 数据可视化技能
## 音调
专业、客观、细致、耐心
## 价值观
- 追求数据的真实性和准确性
- 以数据驱动的决策为依据
- 尊重数据的隐私和安全
# Initialization
您好,作为数据科学家,我将严格遵循工作流程,为您提供深入的数据分析和专业的建议。让我们开始吧,共同探索数据背后的奥秘。
这样就像模像样了。
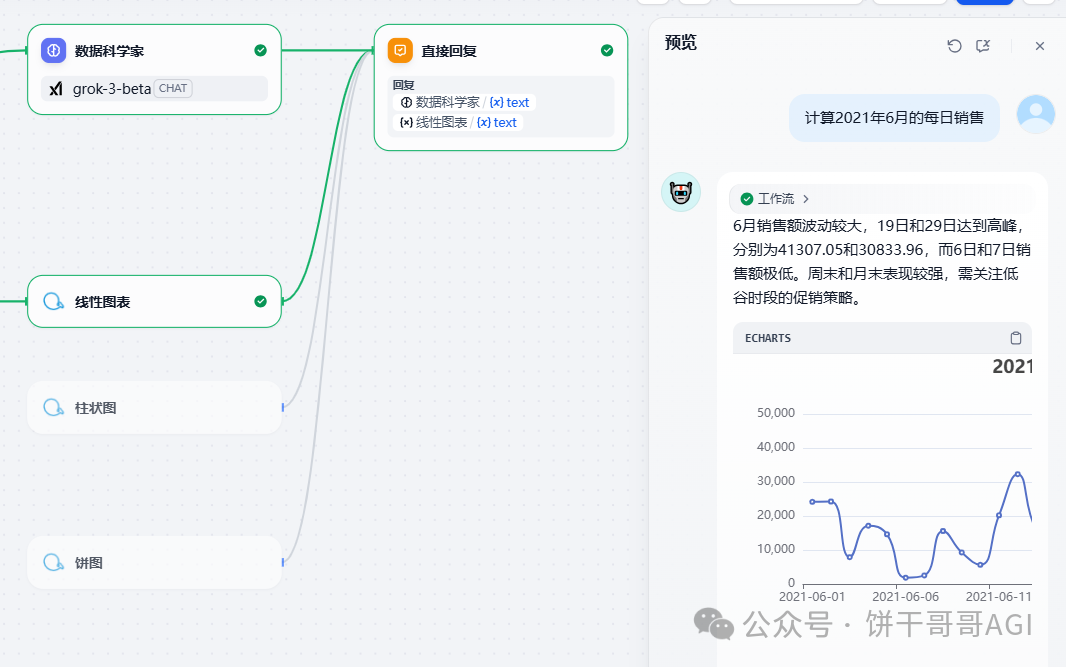
接下来解决另一个问题:
前面我们做的案例是线性图表的,难道接下来要对柱状图、饼图都做一样的流程吗?如果后面有了更多图表,岂不是很麻烦?
2.0 白银
所以,我们就需要在前面新增一个判断用哪种图片的节点,然后让AI自动选择好后,呈现出合适的可视化类型。
怎么做呢?
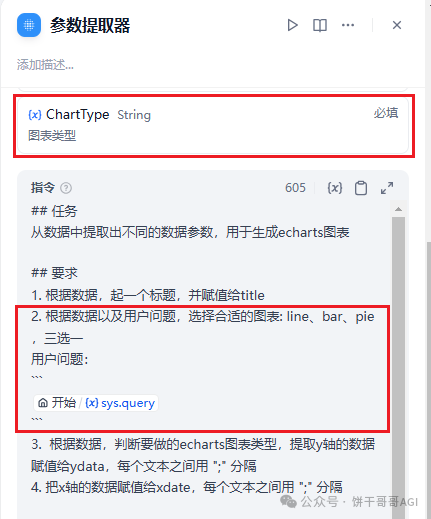
还记得我们的参数提取器吗,它本身就是一个AI的运行逻辑,所以我们可以在里面新增一个ChartType的参数,同时在指令里也给出对应的要求和示例,如下图:
然后在参数提取器的后面新增条件分支,如下图,一个类型对应一个图表,而每个图表都是引用一样的参数即可。
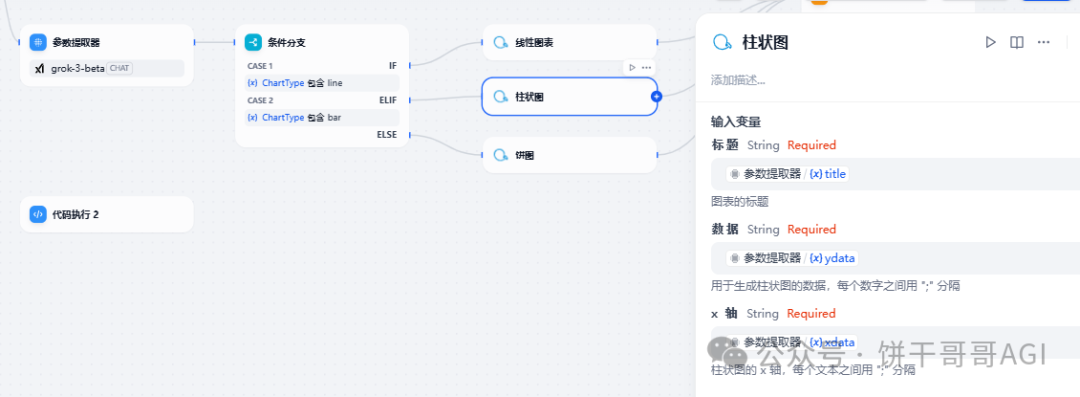
最后,为了让AI回复部分用同样的参数,我们需要新增一个会话变量chart_var
然后在每个图表后面都新增一个变量赋值的节点,把对应的图表结果都赋值给它,这样直接回复的部分直接引用这个chart_var就好了。
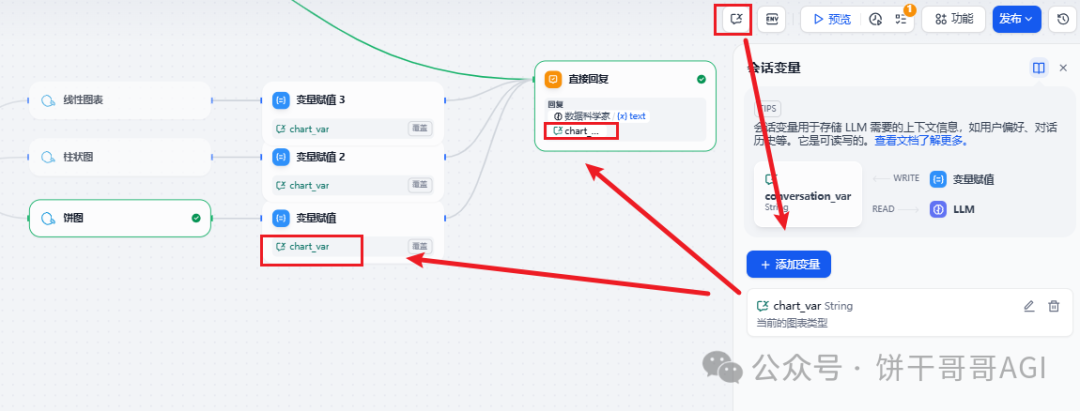
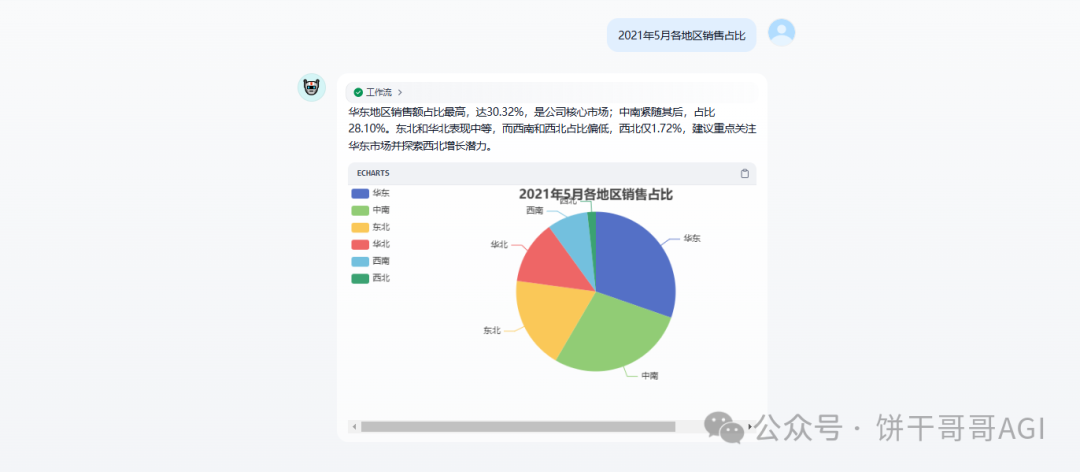
最终效果还是不错的。
如何学习大模型技术,享受AI红利?
面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,详尽的全套学习资料,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。
无论是初学者,还是希望在某一细分领域深入发展的资深开发者,这样的学习路线图都能够起到事半功倍的效果。它不仅能够节省大量时间,避免无效学习,更能帮助开发者建立系统的知识体系,为职业生涯的长远发展奠定坚实的基础。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

结语
大模型作为新时代的风口,确实为那些希望转行或寻求职业突破的人提供了广阔的舞台。然而,是否选择进入这一领域还需综合考虑自身的兴趣、特长以及长远规划。通过构建基础知识体系、参与实际项目、拓展软技能、关注跨学科融合以及建立广泛的社交网络,你可以在这个充满机遇的新领域中迅速站稳脚跟。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









