









 本文介绍了10个用于自动执行探索性数据分析的Python库,如D-Tale、Pandas-Profiling、Sweetviz等,它们能快速生成数据概述和可视化,减少手动工作,提高数据处理效率。
本文介绍了10个用于自动执行探索性数据分析的Python库,如D-Tale、Pandas-Profiling、Sweetviz等,它们能快速生成数据概述和可视化,减少手动工作,提高数据处理效率。
探索性数据分析是数据科学模型开发和数据集研究的重要组成部分之一。在拿到一个新数据集时首先就需要花费大量时间进行EDA来研究数据集中内在的信息。自动化的EDA Python包可以用几行Python代码执行EDA。在本文中整理了10个可以自动执行EDA并生成有关数据的见解的Python包,看看他们都有什么功能,能在多大程度上帮我们自动化解决EDA的需求。
- DTale
- Pandas-profiling
- sweetviz
- autoviz
- dataprep
- KLib
- dabl
- speedML
- datatile
- edaviz
1、D-Tale
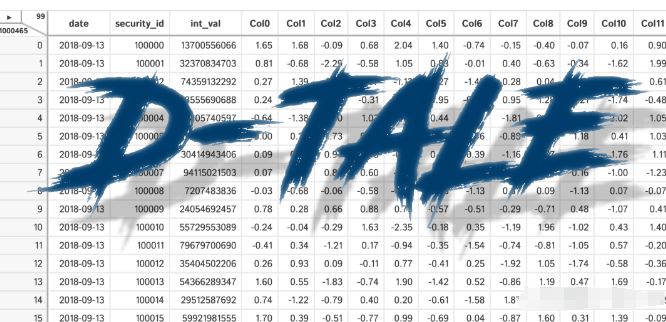
D-Tale使用Flask作为后端、React前端并且可以与ipython notebook和终端无缝集成。D-Tale可以支持Pandas的DataFrame, Series, MultiIndex, DatetimeIndex和RangeIndex。
import dtale
import pandas as pd
dtale.show(pd.read_csv("titanic.csv"))
1713834663926)
D-Tale库用一行代码就可以生成一个报告,其中包含数据集、相关性、图表和热图的总体总结,并突出显示缺失的值等。D-Tale还可以为报告中的每个图表进行分析,上面截图中我们可以看到图表是可以进行交互操作的。

2、Pandas-Profiling

Pandas-Profiling可以生成Pandas DataFrame的概要报告。panda-profiling扩展了pandas DataFrame df.profile_report(),并且在大型数据集上工作得非常好,它可以在几秒钟内创建报告。
#Install the below libaries before importing
import pandas as pd
from pandas_profiling import ProfileReport
#EDA using pandas-profiling
profile = ProfileReport(pd.read_csv('titanic.csv'), explorative=True)
#Saving results to a HTML file
profile.to_file("output.html")

3、Sweetviz
Sweetviz是一个开源的Python库,只需要两行Python代码就可以生成漂亮的可视化图,将EDA(探索性数据分析)作为一个HTML应用程序启动。Sweetviz包是围绕快速可视化目标值和比较数据集构建的。
import pandas as pd
import sweetviz as sv
#EDA using Autoviz
sweet_report = sv.analyze(pd.read_csv("titanic.csv"))
#Saving results to HTML file
sweet_report.show_html('sweet_report.html')
Sweetviz库生成的报告包含数据集、相关性、分类和数字特征关联等的总体总结。

4、AutoViz
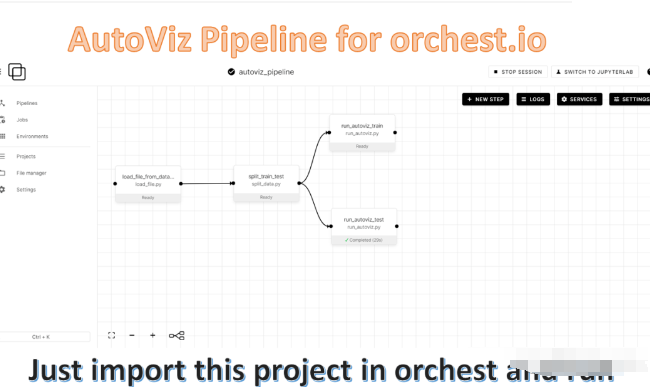
Autoviz包可以用一行代码自动可视化任何大小的数据集,并自动生成HTML、bokeh等报告。用户可以与AutoViz包生成的HTML报告进行交互。
import pandas as pd
from autoviz.AutoViz_Class import AutoViz_Class
#EDA using Autoviz
autoviz = AutoViz_Class().AutoViz('train.csv')

5、Dataprep
Dataprep是一个用于分析、准备和处理数据的开源Python包。DataPrep构建在Pandas和Dask DataFrame之上,可以很容易地与其他Python库集成。
DataPrep的运行速度这10个包中最快的,他在几秒钟内就可以为Pandas/Dask DataFrame生成报告。
from dataprep.datasets import load_dataset
from dataprep.eda import create_report
df = load_dataset("titanic.csv")
create_report(df).show_browser()
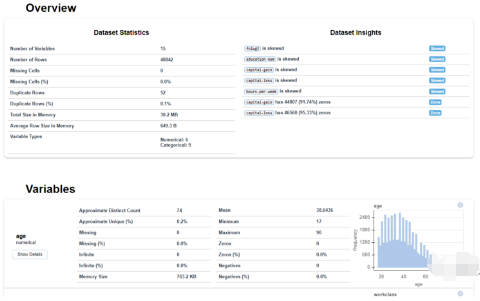
6、Klib

klib是一个用于导入、清理、分析和预处理数据的Python库。
import klib
import pandas as pd
df = pd.read_csv('DATASET.csv')
klib.missingval_plot(df)
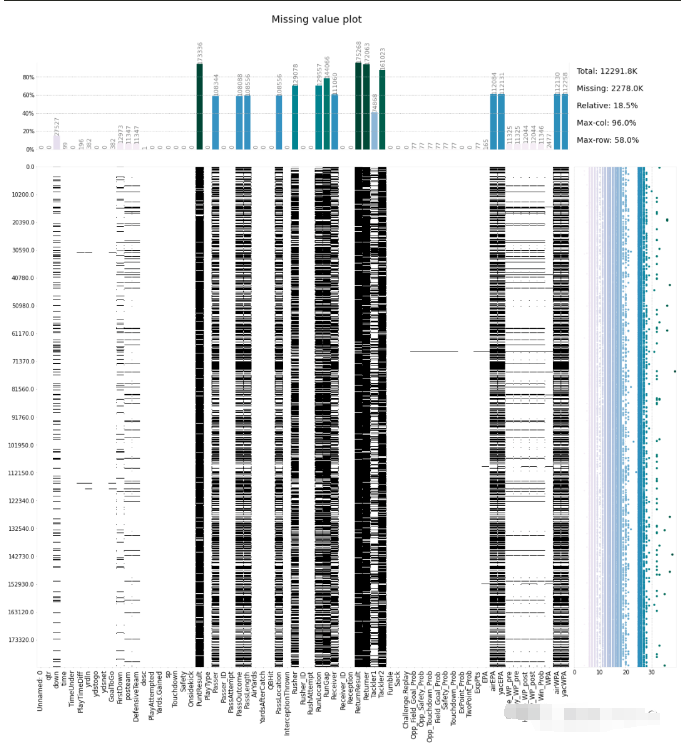
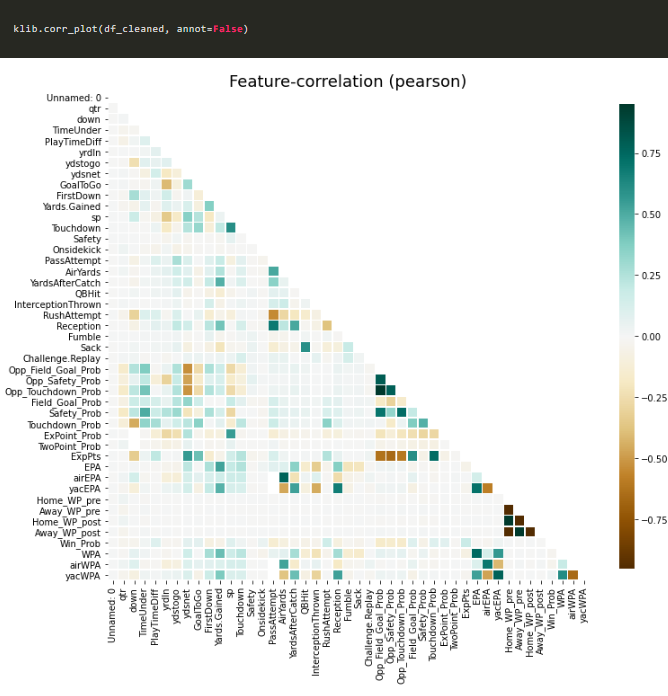
klib.corr_plot(df_cleaned, annot=False)
’ fill=‘%23FFFFFF’%3E%3Crect x=‘249’ y=‘126’ width=‘1’ height=‘1’%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
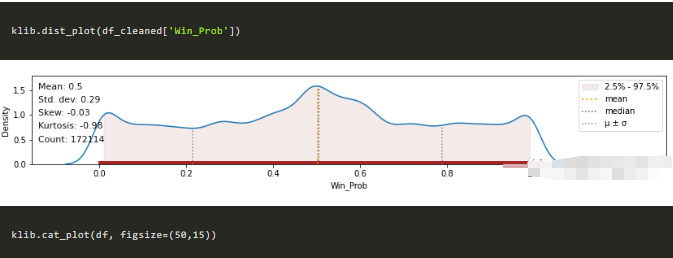
klib.dist_plot(df_cleaned['Win_Prob'])
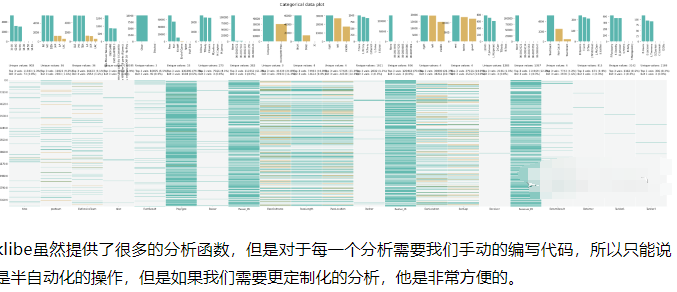
klib.cat_plot(df, figsize=(50,15))
klibe虽然提供了很多的分析函数,但是对于每一个分析需要我们手动的编写代码,所以只能说是半自动化的操作,但是如果我们需要更定制化的分析,他是非常方便的。
7、Dabl
Dabl不太关注单个列的统计度量,而是更多地关注通过可视化提供快速概述,以及方便的机器学习预处理和模型搜索。
dabl中的Plot()函数可以通过绘制各种图来实现可视化,包括:
- 目标分布图
- 散点图
- 线性判别分析
import pandas as pd
import dabl
df = pd.read_csv("titanic.csv")
dabl.plot(df, target_col="Survived")

8、Speedml
SpeedML是用于快速启动机器学习管道的Python包。SpeedML整合了一些常用的ML包,包括 Pandas,Numpy,Sklearn,Xgboost 和 Matplotlib,所以说其实SpeedML不仅仅包含自动化EDA的功能。
SpeedML官方说,使用它可以基于迭代进行开发,将编码时间缩短了70%。
from speedml import Speedml
sml = Speedml('../input/train.csv', '../input/test.csv',
target = 'Survived', uid = 'PassengerId')
sml.train.head()
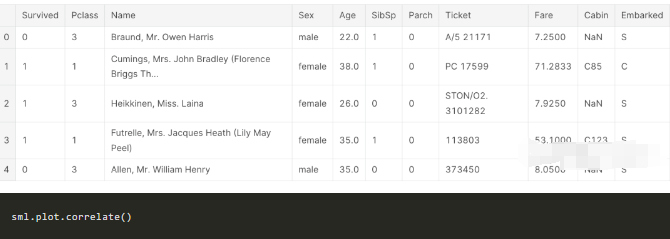
sml.plot.correlate()
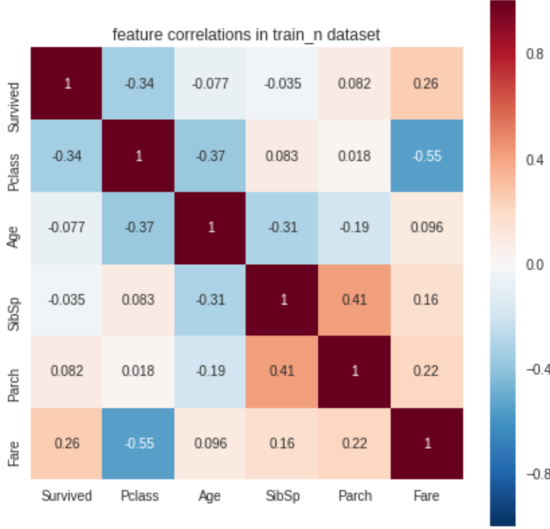
sml.plot.distribute()
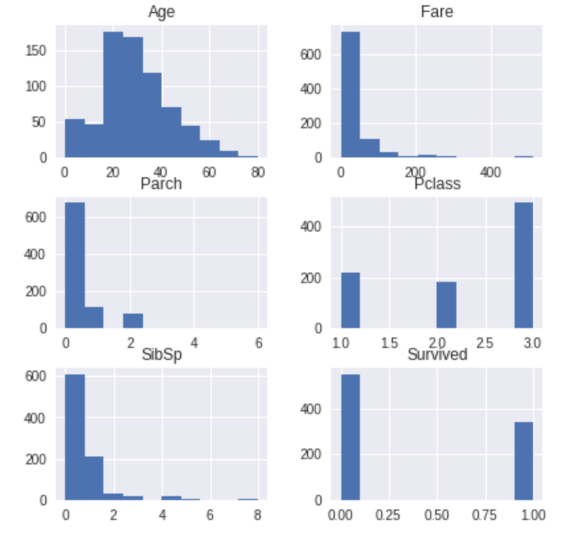
sml.plot.ordinal('Parch')
sml.plot.ordinal('SibSp')
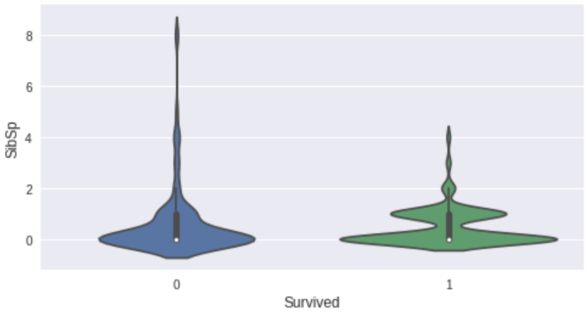
sml.plot.continuous('Age')
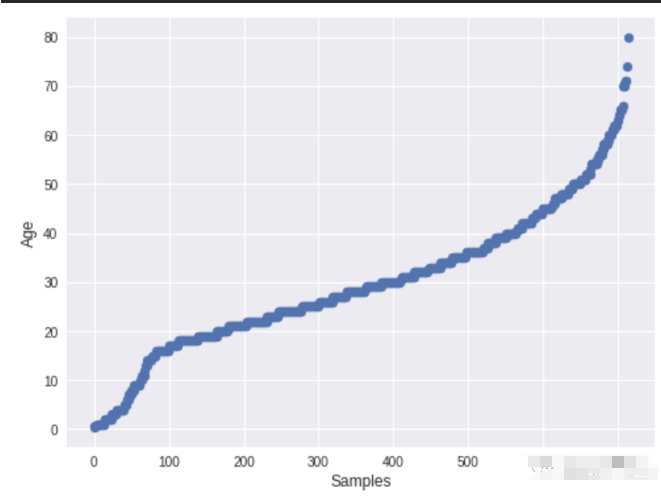
9、DataTile
DataTile(以前称为Pandas-Summary)是一个开源的Python软件包,负责管理,汇总和可视化数据。DataTile基本上是PANDAS DataFrame describe()函数的扩展。
import pandas as pd
from datatile.summary.df import DataFrameSummary
df = pd.read_csv('titanic.csv')
dfs = DataFrameSummary(df)
dfs.summary()
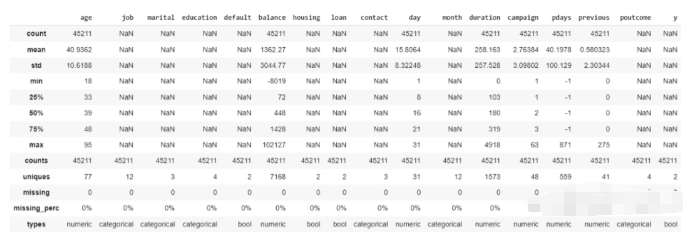
10、edaviz
edaviz是一个可以在Jupyter Notebook和Jupyter Lab中进行数据探索和可视化的python库,他本来是非常好用的,但是后来被砖厂(Databricks)收购并且整合到bamboolib 中,所以这里就简单的给个演示。

总结
在本文中,我们介绍了10个自动探索性数据分析Python软件包,这些软件包可以在几行Python代码中生成数据摘要并进行可视化。通过自动化的工作可以节省我们的很多时间。
Dataprep是我最常用的EDA包,AutoViz和D-table也是不错的选择,如果你需要定制化分析可以使用Klib,SpeedML整合的东西比较多,单独使用它啊进行EDA分析不是特别的适用,其他的包可以根据个人喜好选择,其实都还是很好用的,最后edaviz就不要考虑了,因为已经不开源了。
关于Python学习指南
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后给大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、自动化办公等学习教程。带你从零基础系统性的学好Python!
👉Python所有方向的学习路线👈
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。(全套教程文末领取)

👉Python学习视频600合集👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉Python70个实战练手案例&源码👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉Python大厂面试资料👈
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


👉Python副业兼职路线&方法👈
学好 Python 不论是就业还是做副业赚钱都不错,但要学会兼职接单还是要有一个学习规划。

👉 这份完整版的Python全套学习资料已经上传,朋友们如果需要可以扫描下方CSDN官方认证二维码或者点击链接免费领取【保证100%免费】
















 942
942











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









