






一、长文本的核心问题与解决方向
1.1 文本长度与显存及计算量之关系
要研究清楚长文本的问题,首先应该搞清楚文本长度在模型中的地位与影响。那么我们便以 Decoder-base 的模型为例来进行分析
1.1.1 模型参数量
Decoder-base 的模型主要包括 3 个部分:embedding, decoder-layer, head。
其中最主要部分是decoder-layer,其由 � 个层组成,每个层又分为两部分:self-attention 和 MLP。









二、长文本与位置编码
在 Transformer 结构的模型中,Attention模块的值与顺序无关,因此需要加入位置编码以确定不同位置的 token。典型的位置编码方式有两类:
- 绝对位置编码:即将位置信息融入到输入中
- 相对位置编码:微调Attention结构,使其能够分辨不同位置的Token
随着文本长度的增加,位置编码也会发生相应的变化,因此处理好位置编码问题是解决长文本问题的重要环节。

由于绝对位置编码由两部分组成,且两部分相互独立,因此无法计算相对距离。下面介绍几种典型的绝对位置编码:


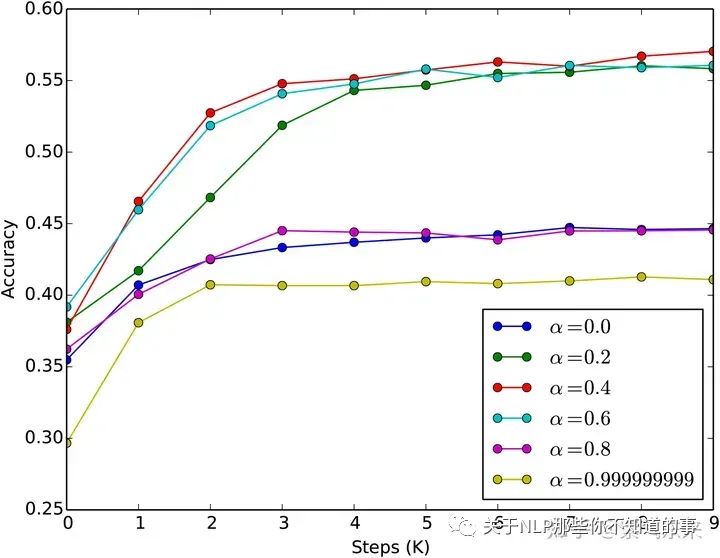
不同alpha下BERT MLM的训练准确率
需要说明的是,这种矩阵式的位置编码方式在当前的大模型中已经比较少采用了,仅有 GPT2 等早期模型中采用了这种方式。
2.1.2 Sinusoidal 位置编码


整体位置编码如下图所示:
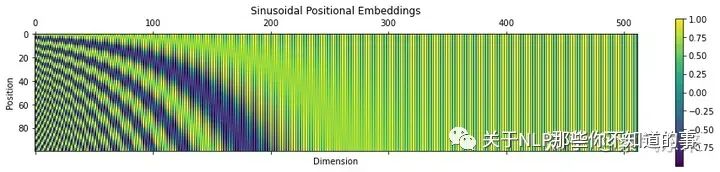
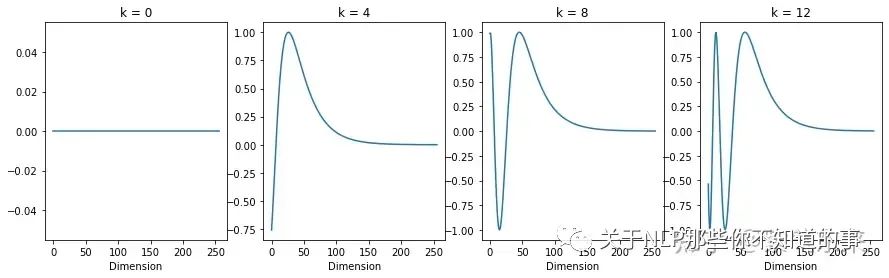
首先研究 Sinusoidal 位置编码与位置之间的关系,绘制不同位置下,函数值与 sin 维度的关系

其曲线如下图所示, 可以从图中得到几点结论:
- 位置越远,频率越大
- 随着维度增大,函数逐渐收敛到 0 (cos 函数收敛到 1 )
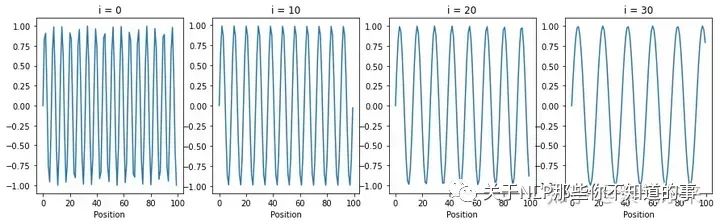
研究 Sinusoidal 位置编码与维度分量之间的关系,绘制不同维度分量 i 下,函数值与位置的的关系

Sinusoidal位置编码与维度分量的关系如下图所示,可以发现结论如下:
- 每个分量都具有周期性,是正弦或余弦函数
- 越靠后的分量(i 越大),波长越长,频率越低
了解了这些基本的特性后,接下来就需要讨论更加深层次的问题:
问题一:为什么用包含各频率的正弦和余弦对?
位置编码存储的是一个包含各频率的正弦和余弦对,这样做有两个好处:
- 可以使得不同位置的编码向量之间有一定的规律性,比如相邻位置之间的差异较小,而距离较远的位置之间的差异较大。这是由正弦和余弦函数的连续性和单调性保证的,即对于任意两个相邻的位置,它们对应的编码向量在每一个维度上都只有微小的变化,而对于任意两个距离较远的位置,它们对应的编码向量在每一个维度上都有较大的差异。
- 可以使得编码向量在任意维度上都能保持唯一性,即不同位置在同一个维度上不会有相同的值。这是由正弦和余弦函数的周期性和相位差保证的,即对于任意两个不同的位置,它们对应的编码向量在每一个维度上都不相等。
问题二:底数对结果的影响是什么?
底数越大,位置向量能表示的序列就越长,这是大底数的好处。但是,底数大,意味着在-1到+1的范围内向量的取值越密集,造成两个位置的向量距离越近,这对后续的Self-Attention模块来说是不利的,因为它需要经历更多的训练次数才能准确地找到每个位置的信息,或者说,才能准确地区分不同的位置。长序列需要长编码。但这样又会增加计算量,特别是长编码会影响模型的训练时间。所以,那个底数并非是越大越好。
问题三:Sinusoidal 位置编码如何外推
三角函数式位置编码的特点是有显式的生成规律,因此可以期望于它有一定的外推性。另外一个使用它的理由是:由于

2.1.3 其他的绝对位置编码
如递归式(如 FLOATER)和相乘式(如PENG Bo:中文语言模型研究:(1) 乘性位置编码),因使用较少,在此不予赘述。
2.2 相对位置编码及其外推
相对位置并没有完整建模每个输入的位置信息,而是在算Attention的时候考虑当前位置与被Attention的位置的相对距离,由于自然语言一般更依赖于相对位置,所以相对位置编码通常也有着更好的表现,灵活性也更大。
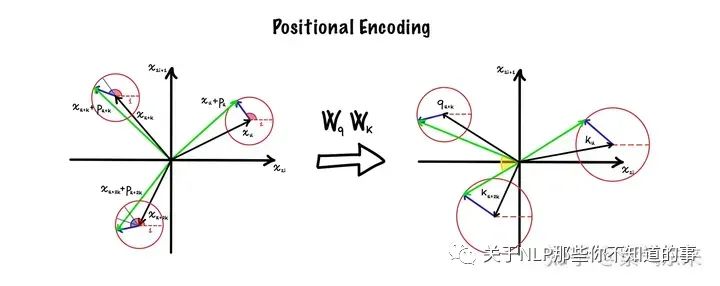
2.2.1 旋转位置编码 RoPE
实际上 RoPE 的诸多思想来源于 Sinusoidal 位置编码,区别在于 Sinusoidal 位置编码采用和 word embedding 相加的形式,RoPE 则采用了矩阵相乘的形式。
在正式介绍之前,我们需要回顾一下经典的欧拉公式

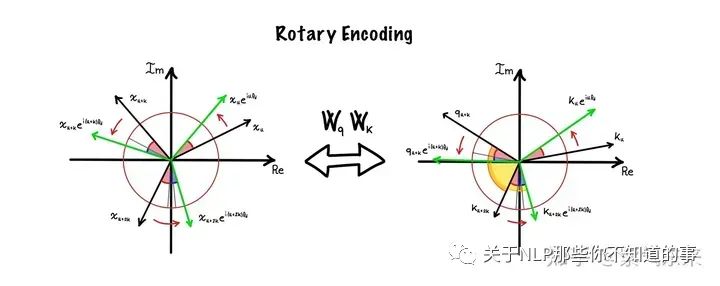



旋转角度随维度的变化
2.2.2 远程衰减问题


下图展示了不同距离尺度上不同 base 值的积分结果,可以得到以下结论:
- 除了 base=1 外,均有明显的远程衰减特性
- base 越小,衰减得越快且幅度也更大
- base 越大,衰减得越慢且幅度也越小
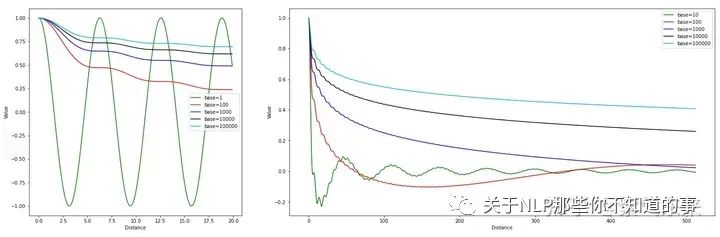
不同距离尺度上的积分结果
2.2.3 RoPE 长度的内插与外推
长度外推性是一个训练和预测的长度不一致的问题。提现有两点:
- 预测的时候用到了没训练过的位置编码(不管绝对还是相对);
- 预测的时候注意力机制所处理的token数量远超训练时的数量。
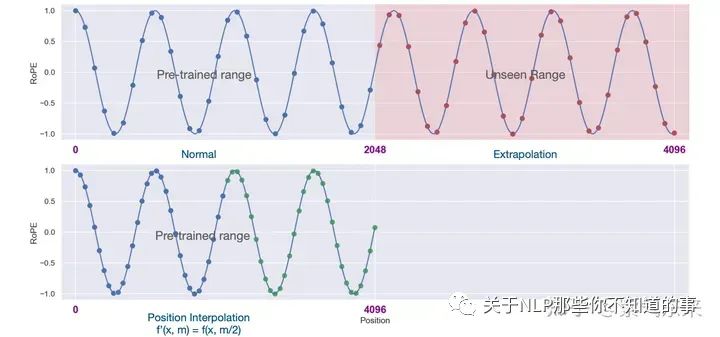
一旦我们在模型中有效地整合了相对位置信息,增加 LLM 上下文窗口的最直接方法就是通过位置插值 (position interpolation,PI) 进行微调。
这种方法实现很简单,如果希望将预训练阶段的位置向量范围[0,2048] 外推到[0,4096],只需要将对应位置缩放到原先支持的区间([0,2048])内:计算公式如下,L为原先支持的长度(如2048), L’为需要扩展的长度(如4096):
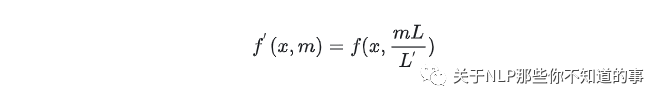
其过程如下图所示:




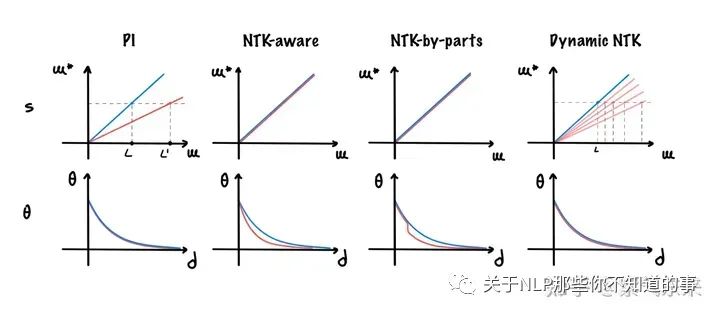
需要说明的是,论文 Scaling Laws of RoPE-based Extrapolation 中深入研究了 RoPE 位置编码的特性,其结论就是:RoPE 中 base 的放大和缩小都能获得很好的外推效果(base=10K 效果最差)。原因在于:
- 当 base 较小时(如 500),RoPE 的三角函数周期变短,训练时就可以见过完整的 cos/sin 值域;
- 当 base 较大时(如 1000000),RoPE 的三角函数周期变长,训练时虽然不能见过完整的 cos/sin 值域,但是外推时仍处于单调区间。
2.2.4 其他形式的编码方式及其外推
在苏神的文章Transformer升级之路:12、无限外推的ReRoPE?中指出:RoPE 形式上是一种绝对位置编码,但实际上给 Attention 带来的是相对位置信息,即如下的Toeplitz矩阵:

这么这种形式的 bias 似乎有种似曾相识的感觉,没错,就是 ALiBi 编码。严格来说,ALiBi 并不算位置编码,因为它并没有作用在 embedding 上,而是直接作用在了 Attention 上,通过这种构造方式既实现了远程衰减,又实现了位置的相对关系。
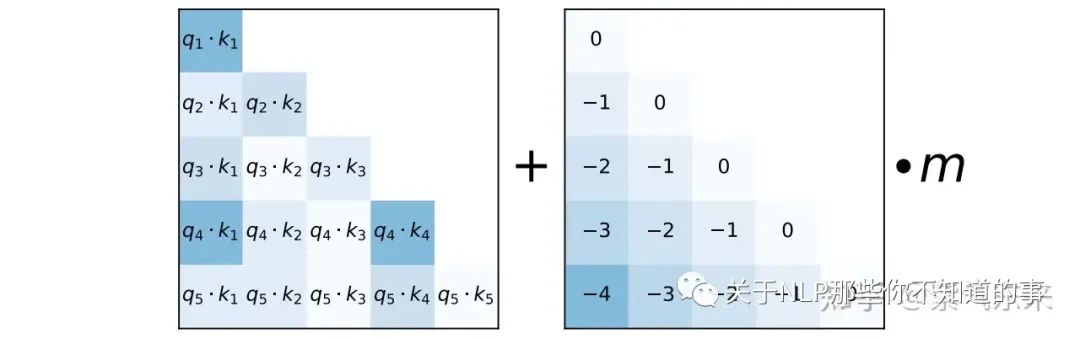
ALiBi 的作用原理
对于外推特性,ALiBi 与前文所述的方法也是不同的,体现在:
- 事后修改,比如NTK-RoPE、YaRN、ReRoPE等,这类方法的特点是直接修改推理模型,无需微调就能达到一定的长度外推效果,但缺点是它们都无法保持模型在训练长度内的恒等性
- 事前修改,如ALIBI、KERPLE、XPOS以及HWFA等,它们可以不加改动地实现一定的长度外推,但相应的改动需要在训练之前就引入,因此无法不微调地用于现成模型
三、长文本与 Attention 机制
Attention 机制也是制约长文本实现的重要因素,以下是几种典型的 Attention 的 方式:
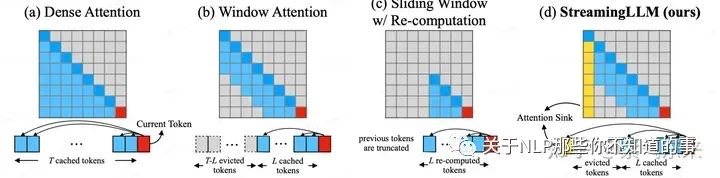
关于 Attention 机制改进的更多类型和细节,笔者在之前的文章中已经有所讨论,可参考:
NLP(二十):漫谈 KV Cache 优化方法,深度理解 StreamingLLM
https://zhuanlan.zhihu.com/p/659770503
在此主要想介绍一个方案 —— LongLora 。
回顾第一节中研究的结论,长文本影响最大的就是 self-attention 中的,随长度二次变化的显存占用和计算复杂度。为解决这个问题,LongLora 的原则是,虽然在推理过程中需要密集的全局注意力,但通过稀疏的局部注意力可以有效且高效地微调模型。
LongLora 在微调期间延长上下文长度,同时使用 Lora 方法保持高性能和低复杂性。其中最关键的是提出了转移短注意力(S2-Attn)方案。下面简要介绍这一方案:
S2-Attn 在微调阶段使用局部注意力而不是全局注意力。即将输入文档分解为几个不同的组,并在每个组中分别应用注意力机制(Pattern 1)。尽管这种方式能够在资源占用不多的情况下拓展长度,由于不同组之间缺乏信息交换,随着上下文长度的增加,会导致混乱增加。
为了解决上述问题,S2-Attn 引入了组大小一半的移位操作,确保相邻组之间顺利的信息交换(Pattern 2)。这种做法有助于模型在文本开头和结尾之间顺利交换信息,从而提高模型稳定性。
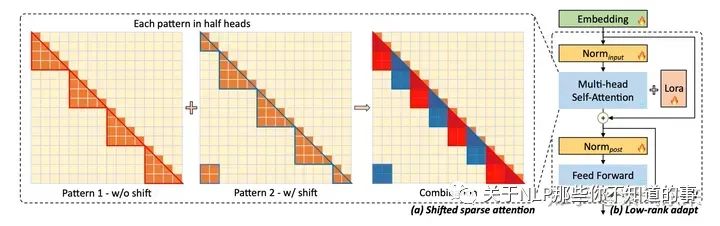
LongLora 整体框架
而本文提出的 shift short attention 有一半的 head 会被做 shift,如下图所示,然后每个 group 内作 self-attention,从而使信息可以在不同 group 间传递。这种做法实际上将 Pattern 1 和 Pattern 2 结合起来,而没有引入额外的计算开销,使其非常适合高效处理长序列文本。
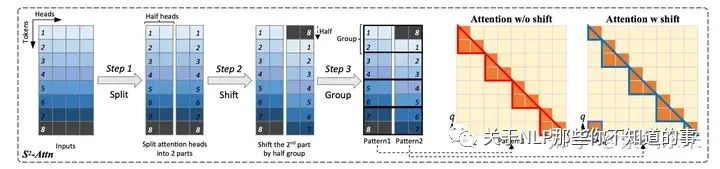
shift short attention 原理
此外,LongLoRA相比于Lora还可以微调embedding层和normalization层。尽管这两项内容占的参数量很小(以Llama 2-7B为例,embedding层只占1.94%,normalization层更是不到十万分之四),对结果也起到了重要作用。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。















 919
919

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









