







一、线性表示的任务内容
目标:探究一个人的外貌,性格,财富,内涵对一个恋爱次数的影响程度。也就是根据样本的恋爱次数和样本中每个人的外貌,性格,财富,内涵的得分来通过深度学习预测出这四个领域对恋爱次数的权重。
重中之重:
已知数据:样本人数500人,这500个人的恋爱次数Y(y看成一个向量,实际上是一个“张量”),以及这500个人在外貌,性格,财富,内涵四个领域上的得分情况X(x可以看成是一个500行4列的矩阵,每行代表一个人在四个领域上的得分,x其实也是一个“张量”)
要我们自己预测的:①恋爱次数与四个领域得分的公式。②预测四个领域对恋爱次数的第一组权重w0,以及损失值b0。③设置梯度下降的学习率𝜂
学习率(又叫“超参数”)用于通过w0,b0来求w1,b1在以此类推求wn,bn。L代表损失函数,L对w和b的求导和回传直接通过torch.backward()函数执行,之后保存在张量网上通过w.grad和b.grad即可得到该值。
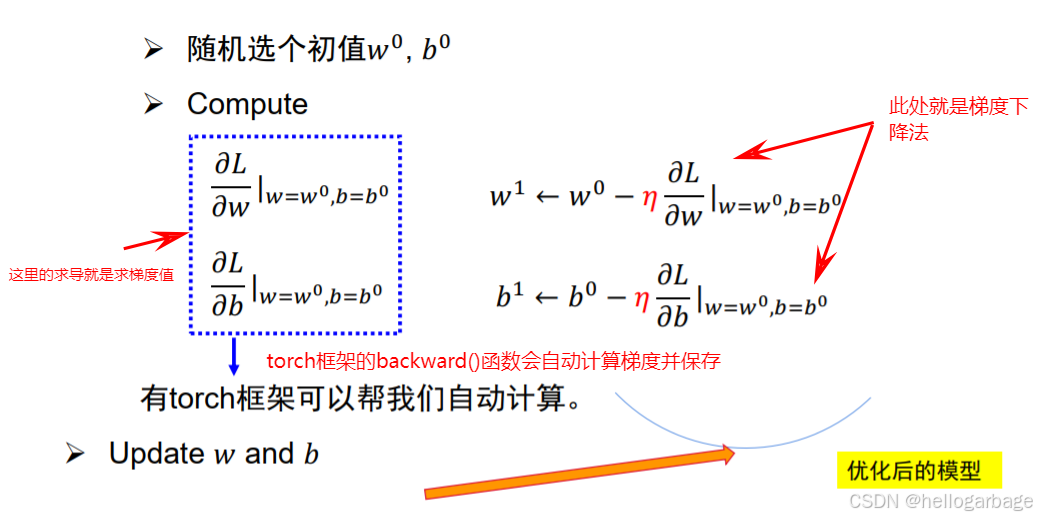
要通过深度模型得到的:①相对准确的四个领域对恋爱次数的权重w,以及相对准确的损失值b
任务过程:
①预测一个公式:Y = X * w + b(y就是恋爱次数,x就是样本每个人在各领域的得分,w是我们预测的各个领域的权重(即①中的w0是最开始预测的权重,后续通过深度模型不断修改为w1,w2...,所以我们就记为w),b是计算的偏差,也叫“损失值”,b在深度学习的过程中也会不断地变化)
②我们预测一下外貌,性格,财富,内涵的权重,即w0 = (外貌,性格,财富,内涵)= (某个值,某个值,某个值,某个值)(一般来说都是凭感觉设置,本次学习中采用随机生成),以及预测一下损失值b0
③通过backward()函数得到损失函数L对w的导数值,和L对b的导数值(也叫梯度值,如下图),然后通过梯度下降公式不断更新w和b。
二、获取一组数据
import torch
import matplotlib.pyplot as plt
import random
# 这个地方是我们自己创造出来的数据,用于后续跟神经网络推测出来的数据进行对比
def create_data(w, b, data_num):
x = torch.normal(0, 1, (data_num, len(w)))
y = torch.matmul(x, w)
noise = torch.normal(1, 0.01, y.shape)
y += noise # 为了与后续深度学习预测的结果有些误差,给我们实际数据加上点噪声(偏差)
return x, y
num = 500
true_w = torch.tensor([8.1, 2, 2, 4]) # (外貌,性格,财富,内涵)的权重就是[8.1, 2, 2, 4]
true_b = torch.tensor(1.1) # 损失值b的值就是1.1
X, Y = create_data(true_w, true_b, num) # 最终得到X是样本每个人的在四个领域的分值,Y是每个人的恋爱次数
num:样本人数
X:样本每个人在四个领域的得分情况
Y:每个人的恋爱次数
以上我们所需的数据已经取得,它们的取得的过程可以忽略了,因为在实际生活中,我们也只是得到结果,接下来的重头戏就是通过结果来用深度学习反推四个领域的权重。
三、深度学习流程
1、预测公式
# torch.matmul(x, w)代表x 和 w两个张量相乘,
# 在本次项目中可看成是500x4的矩阵乘4x1的列向量
def fun(x, w, b):
# 这一个pred_y = torch.matmul(x, w) + b 是我们预测的关系式
# 虽然跟获取数据用到的公式是一样的,但是此处就假装我们不知道,
# 并且假装是因为我们预测的很准确就行!
pred_y = torch.matmul(x, w) + b
return pred_y2、设置损失函数
def meaLoss(pre_y, y): # 此处我们采用平均绝对误差法
return torch.sum(abs(pre_y - y)) / len(y)计算损失函数的常用方法:
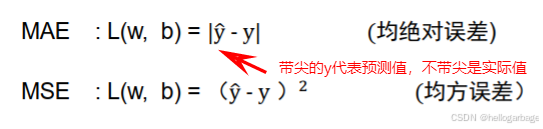
3、梯度下降方法
def sgd(paras, lr): # 随机梯度下降,传入的paras就是[权重,损失值],lr是学习率
with torch.no_grad(): # 属于这句代码的部分,不计算梯度
for para in paras:
para -= para.grad * lr # 不能写成 para = para - para.grad * lr
para.grad.zero_() # 使用过的梯度,归0,不归0的话之后执行backward()会一直累加梯度值4、设置我们自己的预测值
lr = 0.01 # 学习率
# requires_grad = True 代表要系统跟踪w_0,
# 后续使用backward()函数才会对变量进行求导,才会得到w_0.grad
w_0 = torch.normal(0, 0.1, true_w.shape, requires_grad=True) # 随机生成一组预测的权重
b_0 = torch.tensor(0.01, requires_grad=True) # 预测损失值为0.01
print(w_0, b_0)输出结果:
tensor([-0.0749, -0.0443, -0.0580, 0.0737], requires_grad=True) tensor(0.0100, requires_grad=True)
5、开始进行深度学习并得出预测值
def data_provider(data, label, batchsize): # 用来从已知数据中随机获取batchsize大小的数据
length = len(label)
indices = list(range(length))
random.shuffle(indices)
for each in range(0, length, batchsize):
get_indices = indices[each: each + batchsize]
get_data = data[get_indices]
get_label = label[get_indices]
yield get_data, get_label # 有存档点的return
batchsize = 16
epochs = 50
for epoch in range(epochs):
data_loss = 0
for batch_x, batch_y in data_provider(X, Y, batchsize):
pred_y = fun(batch_x, w_0, b_0)
loss = meaLoss(pred_y, batch_y)
# loss通过meaLoss(pred_y, batch_y)得到,
# 而pred_y通过fun(batch_x, w_0, b_0)得到,
# 所以loss.backward()进行梯度回传时,系统知道是要对w_0和b_0进行求导的
loss.backward() # 执行backward()后对应的梯度值可通过w_0.grad,b_0.grad调用
sgd([w_0, b_0], lr) # 用梯度下降法重新计算权重值和损失值
data_loss += loss
print("epoch %03d: loss: %.6f" % (epoch, data_loss))输出结果:
epoch 000: loss: 232.307953
epoch 001: loss: 226.154343
epoch 002: loss: 226.238464
epoch 003: loss: 214.773056
epoch 004: loss: 209.055344
epoch 005: loss: 202.886490
epoch 006: loss: 200.612411
epoch 007: loss: 190.136520
epoch 008: loss: 184.927856
epoch 009: loss: 180.094757
epoch 010: loss: 174.107803
epoch 011: loss: 166.718491
epoch 012: loss: 158.971954
epoch 013: loss: 158.108032
epoch 014: loss: 146.800247
epoch 015: loss: 141.942947
epoch 016: loss: 137.445343
epoch 017: loss: 130.635696
epoch 018: loss: 123.757523
epoch 019: loss: 116.835831
epoch 020: loss: 110.367287
epoch 021: loss: 105.565384
epoch 022: loss: 97.597321
epoch 023: loss: 93.112129
epoch 024: loss: 87.008301
epoch 025: loss: 82.151489
epoch 026: loss: 73.495461
epoch 027: loss: 67.522324
epoch 028: loss: 61.902100
epoch 029: loss: 55.634281
epoch 030: loss: 51.143543
epoch 031: loss: 43.941742
epoch 032: loss: 38.302723
epoch 033: loss: 31.454702
epoch 034: loss: 25.196283
epoch 035: loss: 19.039461
epoch 036: loss: 13.176503
epoch 037: loss: 7.065070
epoch 038: loss: 1.512665
epoch 039: loss: 0.311409
epoch 040: loss: 0.294657
epoch 041: loss: 0.302569
epoch 042: loss: 0.288828
epoch 043: loss: 0.310363
epoch 044: loss: 0.311040
epoch 045: loss: 0.293796
epoch 046: loss: 0.288349
epoch 047: loss: 0.293212
epoch 048: loss: 0.292690
epoch 049: loss: 0.309450
真实的函数值 tensor([8.1000, 2.0000, 2.0000, 4.0000]) tensor(1.1000)
深度训练得到的参数值 tensor([8.0994, 2.0012, 2.0073, 4.0042], requires_grad=True) tensor(1.0013, requires_grad=True)
有以上结果我们可以看到,深度训练得到的一组权重值相当的接近真实的权重值


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









