







这个爬虫的初衷是源于公司的一个项目,公司在建设舆情分析系统,所以需要大量的数据,当然微博这个较大的交际圈有大量的信息,所以老大让我爬微博,但是又给我给了个需求,要自定义爬虫,用户输入一个关键字,爬取和这个关键字有关的全部内容,像这个样子:
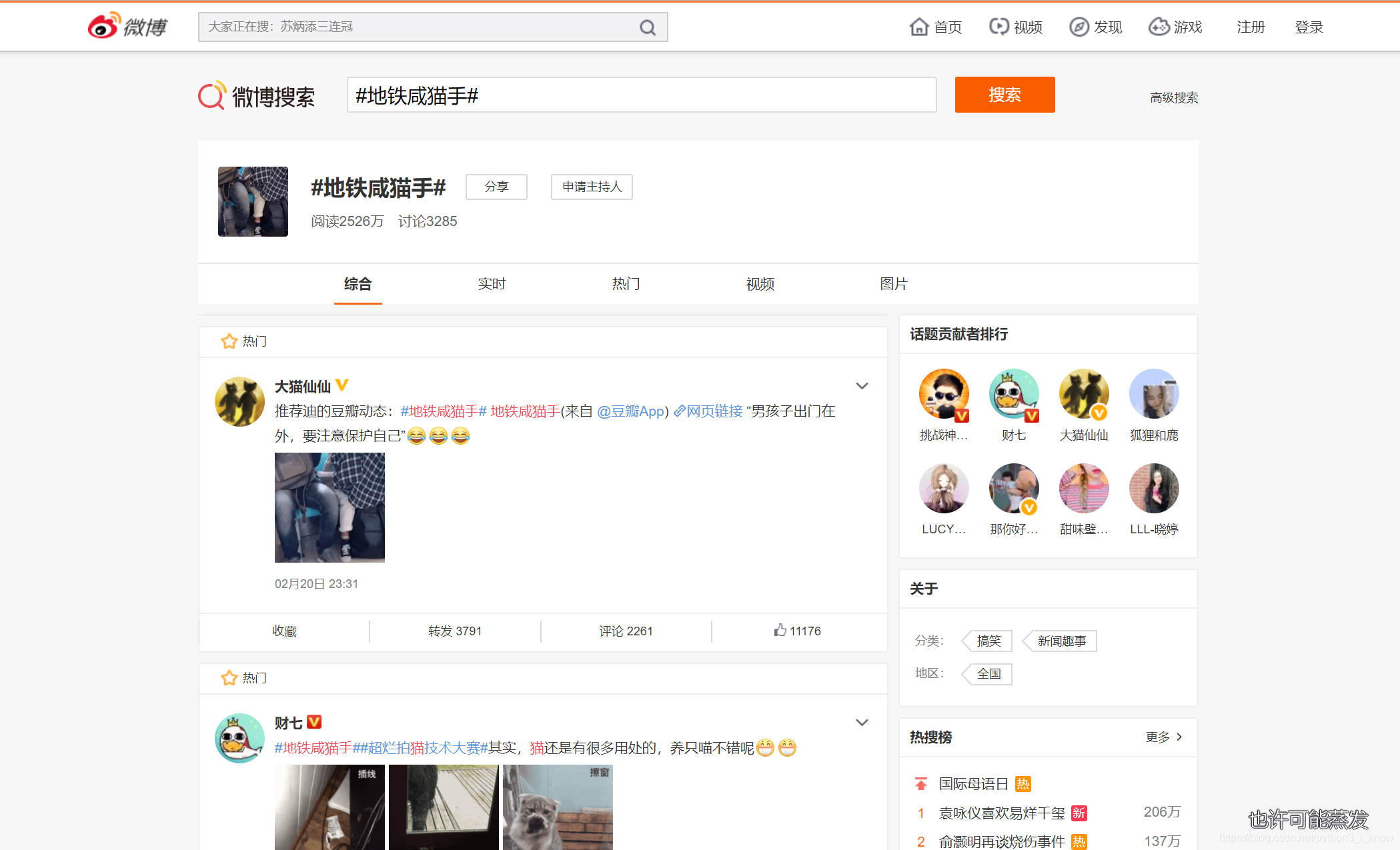
在搜索框内输入咸猫手,把所有的咸猫手全部揪出来,嘻嘻,我纳闷了半天,就想到用selenium爬取,结果还是很好的啦~,看代码:
#注:此为部分代码(重点,嘻嘻)
import time
import re
import pymysql
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from lxml import etree
def weibo_spider(key,time_=None):
'''
:param key: 关键字,
:param time_: 时间,eg:2019-02-09-15:2019-02-10-15
:return:
'''
#加载页面
#无头请求
chrome_options = Options()
chrome_options.add_argument('--headless')
browser = webdriver.Chrome(chrome_options=chrome_options)
#
# browser = webdriver.Chrome()
wait = WebDriverWait(browser, 10)
browser.get('https://s.weibo.com')
input = wait.until(EC.presence_of_element_located((By.XPATH,"//div[@class='search-input']/input")))
button = wait.until(EC.element_to_be_clickable((By.CLASS_NAME,'s-btn-b')))
input.clear()
input.send_keys(key)
button.click()
#爬虫函数
def spider_func(html):
for item in html.xpath("//div[@class='m-con-l']//div[@class='card']"):
author = item.xpath(".//a[@class='name']/text()")[0]
author_url = 'https:' + item.xpath(".//a[@class='name']/@href")[0]
text_list = item.xpath(".//div[@class='content']/p[@class='txt']/text()")
text = ''.join(text_list).strip().replace('\n','').replace(' ','')
time_list = item.xpath(".//div[@class='content']/p[@class='from']/a[@target='_blank']/text()")[0].strip()
forword_list = item.xpath(".//div[@class='card-act']//li[2]/a/text()")[0]
comment_list = item.xpath(".//div[@class='card-act']//li[3]/a/text()")[0]
praise_list = item.xpath(".//div[@class='card-act']//li[4]/a/em/text()")
用selenium有个最头疼的问题就是每次运行就会出现一个页面,我这个要部署到服务器上,当然不能出现那个页面,所以,无头请求就解决了,嘻嘻,其实这个想法出来后,剩余的内容就不怎么难了

















 417
417

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









