







前言
嗨喽~大家好呀,这里是魔王呐 ❤ ~!

再我们缺少素材的时候,我们第一反应
我们肯定会去网上寻找,但是!!
有的素材需要VIP!这可咋整呢?

看我利用python大展神通,采集某图网图片数据

完整源码、python资料: 点击此处跳转文末名片获取
本次目标
利用知识点:
-
动态页面分析
-
动态数据抓包
-
requests

开发环境:
-
版 本: python 3.8
-
编辑器: pycharm 2022.3.2
-
requests >>> pip install requests
如何安装python第三方模块:
-
win + R 输入 cmd 点击确定, 输入安装命令 pip install 模块名 (pip install requests) 回车
-
在pycharm中点击Terminal(终端) 输入安装命令

代码展示
图片的构建规律
https://photo.***.com/{作者id}/f/{当前图片id}.jpg
导入模块
import requests
import parsel
网址放出来就过不了审啦,大家自行添加吧
headers = {
'cookie': 'PHPSESSID=a6phn4ue7180gv3lu9ptdefu15; webp_enabled=1; lang=zh; log_web_id=6142749383; ttcid=33eb5efe64ce4d7ab777615d594b674c35; tt_scid=iiNP.JKSffhMzg6Ij8Wvc1QUUUp34mxhxh8tTbKXVDKz.iGDujlYmC9Y8vT-OaVDdb39',
'referer': 'https://****.com/tags/Cosplay/',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36',
}
main_url = 'https://*****.com/explore/'
html_data = requests.get(main_url).text
select = parsel.Selector(html_data)
two_url_list = select.css('.tags-all-link::attr(href)').getall()
for two_url in two_url_list:
# 'https://****.com/categories/subject/'
three_url = 'https://****g.com/rest/tag-categories/' + two_url.split('/')[-2]
print(three_url)
pages = requests.get(three_url).json()['data']['pages']
for page in range(1, pages+1):
three_url = 'https://****.com/rest/tag-categories/' + two_url.split('/')[-2] + f'?page={page}&count=20'
tag_list = requests.get(three_url).json()['data']['tag_list']
for tag in tag_list:
tag_url = tag['url']
tag_name = tag_url.split('/')[-2]
for page in range(1, 101):
# 请求与响应
url = f'https://***.com/rest/tags/{tag_name}/posts?page={page}&count=20&order=weekly'
json_data = requests.get(url=url, headers=headers).json()
postList = json_data['postList']
for post in postList:
author_id = post['author_id']
for img in post['images']:
img_id_str = img['img_id_str']
img_url = f'https:/***.com/{author_id}/f/{img_id_str}.jpg'
print(img_url)
效果展示




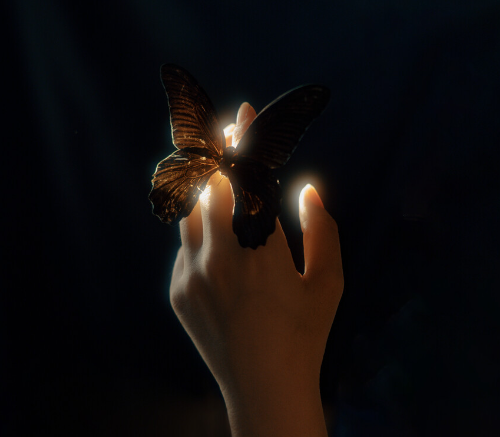






 、
、



尾语 💝
要成功,先发疯,下定决心往前冲!
学习是需要长期坚持的,一步一个脚印地走向未来!
未来的你一定会感谢今天学习的你。
—— 心灵鸡汤
本文章到这里就结束啦~感兴趣的小伙伴可以复制代码去试试哦 😝



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









