







这两天获取了两份关于长沙的数据:长沙景点和长沙美食,之后进行了分析,如果有朋友想去长沙或者周边城市玩,要仔细看看喔。

导入库
长沙景点
数据获取
长沙景点的数据获取方法和之前那篇关于厦门的文章是一样的,只是重新跑了一遍代码,具体过程不再阐述,感兴趣的朋友可以看之前的文章,爬取的字段:
中文名
英文名
攻略数
评价数
位置
排名
驴友占比
简介
具体的源代码如下:
最终数据有1152条,数据中绝大部分是长沙的景点数据,也有少量少量周边城市,比如:宁乡、浏阳等的数据,整体的数据前5行如下:
下面重点介绍数据分析的过程
整体情况
首先看看整体的数据情况:
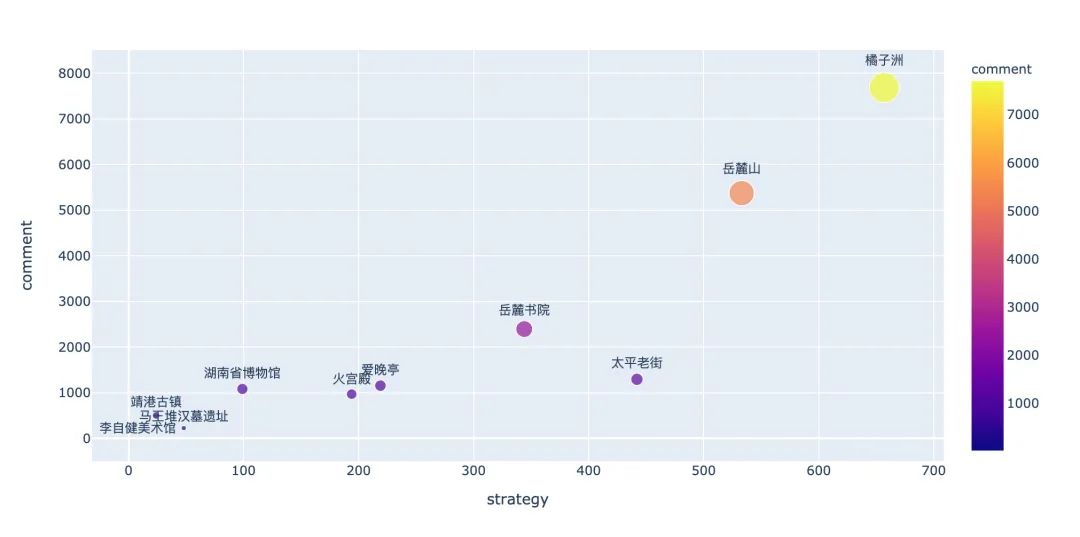
很显然:橘子洲、岳麓山、岳麓书院、太平老街排名靠前
排名靠前景点
看看排名靠前的景点是哪些?
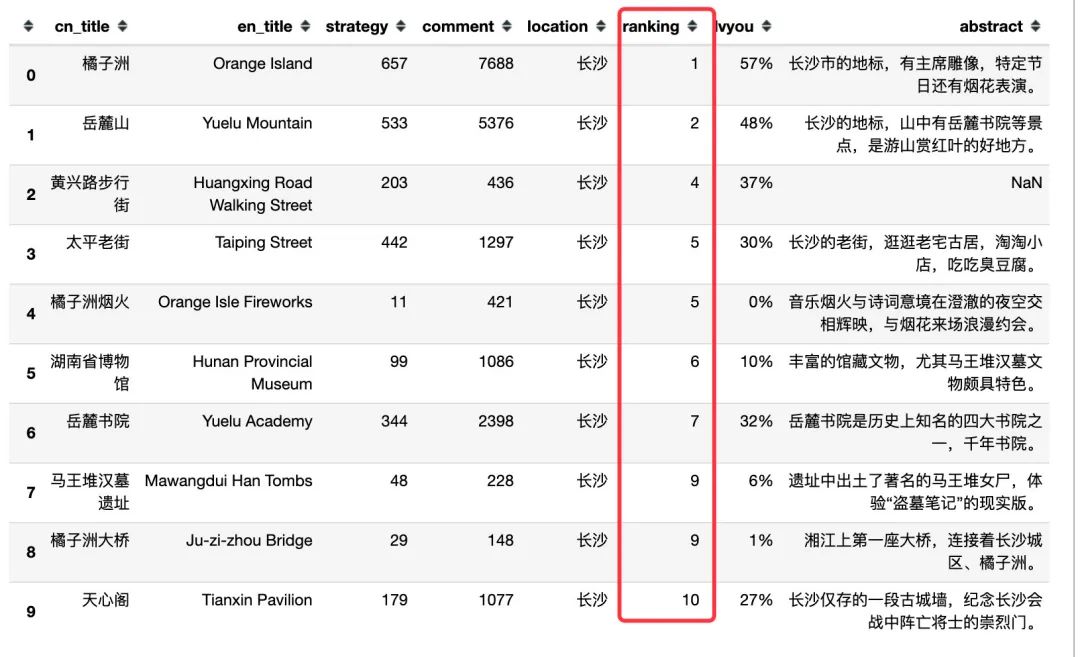
通过排名我们发现:橘子洲(烟火、大桥、天心阁)、岳麓山(书院)、黄兴路步行街、马王堆汉墓遗址、湖南省博物馆,整体排名很靠前,深受游客们欢迎,具体看看排名前20的景点:
[图片上传失败…(image-809a5a-1633093980387)]
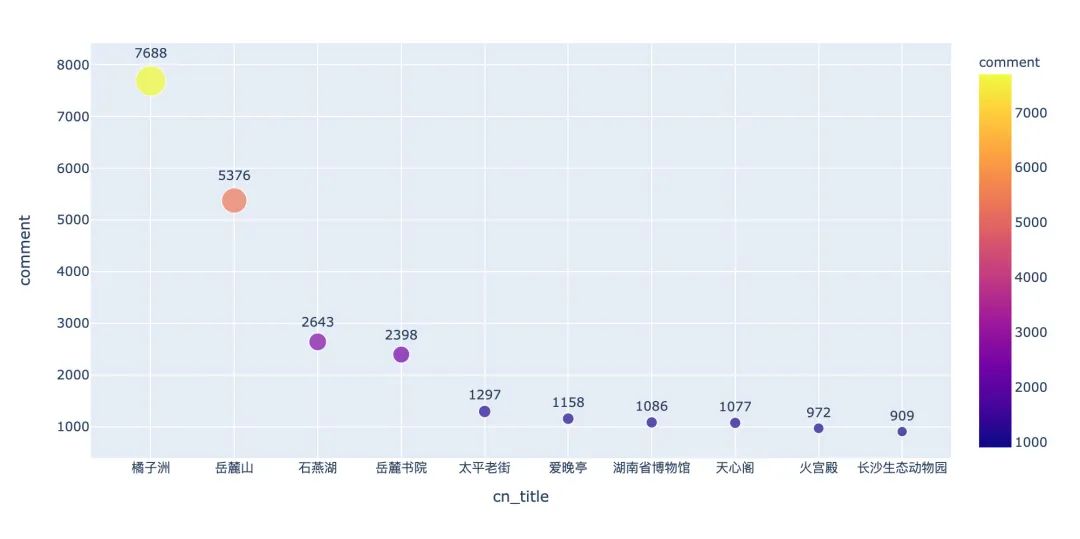
评论火爆景点
很多游客到了一个景点喜欢写评论,看下哪些景点获得大量的评论:
攻略在手,旅游不愁
出门旅游之前最好还是做一份旅游攻略,看看提供攻略最多的前10景点是哪些:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1049
1049











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









