






实践内容:
- 生成和下载的网络相同平均度和网络规模的随机网络
- 对比分析随机网络和下载的网络相关的特征和指标
- 采用度保持的网络随机化算法生成和下载的网络度序列相同的网络
- 利用BA模型生成与下载的网络模型相同的网络,其初始和每个时间t新加入节点的连边自己定义
- 对比分析生成的网络和下载的网络相关的特征和指标
一 网络数据分析
1.1 指标说明
网络数据来自于sociopatterns,数据集对应于2013年2月法国马赛一所高中学生之间的联系和友谊关系,通过各种技术测量得到。该数据集包含五个指标,每行的形式为"t i j Ci Cj",每一行的内容意义为:在[t-20, t]时刻,编号为i和编号为j的同学在一起活动,同时i同学和j同学分别来自Ci和Cj,Ci和Cj代表班级的编号。
1.2 网络平均度计算
在原始的网络数据集中,可以发现每一行包括同学i与同学j在一起活动的信息,因此,当设定节点为每一名高中生编号时,二者之间是否有联系,将取决于数据集中二者是否在同一段时间内一起活动过,即出现在同一行中。由此,我们通过获取学生编号、定义映射索引并构建邻接矩阵,即可计算每个节点的度数,取平均值,即得到网络的平均度。
# 读取数据
df = pd.read_csv('E:\\High-School_data_2013.csv', header=None,
sep='\s+', names=['t', 'i', 'j', 'C_i', 'C_j'])
row, col = df.shape
# 获取学生编号的集合
students = set(df['i']).union(set(df['j']))
# 定义学生编号映射的字典和索引
student_mapping = {}
index = 0
for student_id in students:
if student_id not in student_mapping:
student_mapping[student_id] = index
index += 1
# 构建邻接矩阵
num_students = len(students)
adjacency_matrix = np.zeros((num_students, num_students))
for index, row in df.iterrows():
student_i = student_mapping[row['i']]
student_j = student_mapping[row['j']]
adjacency_matrix[student_i, student_j] = 1
adjacency_matrix[student_j, student_i] = 1
# 计算每个节点的度
degrees = np.sum(adjacency_matrix, axis=1)
# 计算平均度
average_degree = np.mean(degrees)
print("N = ",num_students)
print("Average degree:", average_degree)
N = 327
Average degree: 35.584097859327215
1.3 绘制子图
由于原始数据集包含的节点数过多,考虑将数据集按照时间做划分,同一时间段活动的同学绘制一个子图,其中在同一时间段一起活动的同学之间表示有联系。
# 将数据按时间分组
grouped = df.groupby('t')
# 绘制无向图
for time, group in grouped:
# 创建一个子图
plt.figure()
# 添加子图标题
plt.title(f"Graph at Time {time}")
# 获取子图数据
subgraph_df = grouped.get_group(time)
# 创建子图
subgraph = nx.from_pandas_edgelist(subgraph_df, 'i', 'j')
# 绘制子图,并设置节点大小、标签大小、邻居节点连接距离
pos = nx.spring_layout(subgraph, k=2, iterations=100)
nx.draw(subgraph, pos, with_labels=True, node_size=300,
font_size=8, node_color='cyan', edge_color='black',
width=1)
# 显示图形
plt.show()
部分子图展示:

以上图片分别展示了在时间1385982020、1385982040和1385982060及其前20s时间段内活动的同学,节点之间的连线代表这两位同学在一起活动。
1.4 整体图像
不按照时间进行划分,将全部数据绘制成一张网络图,用于与后续生成的随机网络图作对比。
# 绘制整体图像
plt.figure()
plt.title('Total Graph')
graph_df = nx.from_pandas_edgelist(df, source='i', target='j')
# 绘制图,并设置节点大小、标签大小、邻居节点连接距离
pos = nx.spring_layout(graph_df, k=2, iterations=100)
# 计算节点的度
degrees = dict(graph_df.degree())
# 根据节点的度定义节点的颜色,度越大,颜色越深
node_color = [degree for node, degree in degrees.items()]
nx.draw(graph_df, pos, with_labels=False, node_size=200,
font_size=8, node_color=node_color, edge_color='black',
width=1)
plt.show()
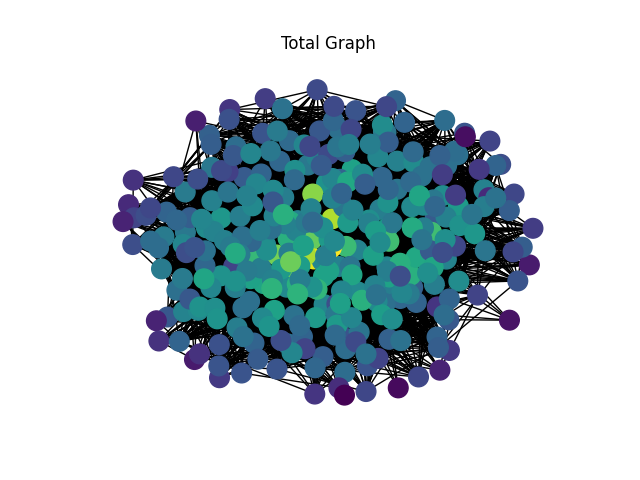
二 随机网络
2.1 随机网络生成
按照要求,需要生成与该网络数据规模相同且平均度相同的随机网络,网络规模考虑节点的个数、平均度相同则要考虑概率的设置。
根据随机网络平均度的公式:
<
k
>
=
p
∗
(
n
−
1
)
<k> = p*(n-1)
<k>=p∗(n−1),我们将概率设置为该网络数据的平均度与(网络规模-1)的比值。
# 定义节点数量和边的概率
n = num_students # 节点数量
p = average_degree / (n - 1) # 边的概率
# 生成随机网络
random_graph = nx.erdos_renyi_graph(n, p)
# 计算节点的度
degrees = dict(random_graph.degree())
# 根据节点的度定义节点的颜色,度越大,颜色越深
node_color = [degree for node, degree in degrees.items()]
plt.figure()
plt.title('Random Graph')
# 绘制随机网络
nx.draw(random_graph, with_labels=False, node_color=node_color,
node_size=200, width=0.5)
plt.show()

2.2 对比相关特征和指标
2.2.1 度分布
在随机网络中,有些节点有许多连接,有些节点只有较少的连接,甚至没有连接,度分布 p k p_{k} pk,表示一个随机选择的节点度为 k k k的概率。以下是随机网络的度分布直方图,反映了不同节点度的数量分布。
# 定义节点数量和边的概率
n = num_students # 节点数量
p = average_degree / (n - 1) # 边的概率
# 生成随机网络
random_graph = nx.erdos_renyi_graph(n, p)
# 计算节点的度
degrees =[degree for node, degree in random_graph.degree()]
# 绘制度分布直方图
plt.figure()
plt.hist(degrees, bins=range(max(degrees)+1), color='skyblue',
edgecolor='black', alpha=0.7)
plt.title('Degree Distribution')
plt.xlabel('Degree')
plt.ylabel('Frequency')
plt.grid(True)
plt.show()
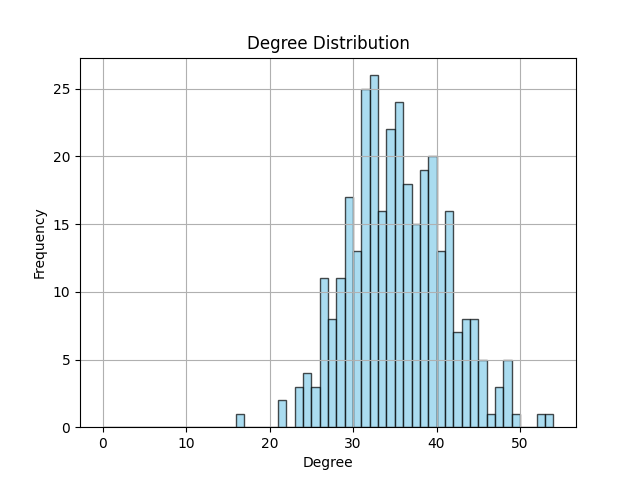
可以发现,节点度数目主要集中30到40之间,与所获取的网络数据平均度35.58所反映的集中趋势吻合。
泊松分布曲线:

对比分布曲线和度分布直方图,可以认定该随机数据符合泊松分布。
注:随机网络度分布的精确形式是二项分布。只有在(平均度)远小于N(节点数目)的极限情况下才可以近似为泊松分布。但由于大多数真实网络是稀疏的,上述近似需要的条件通常会被满足。
# 计算节点的度
degrees =[degree for node, degree in graph_df.degree()]
# 绘制度分布直方图
plt.figure()
plt.hist(degrees, bins=range(max(degrees)+1), color='pink',
edgecolor='black', alpha=0.7)
plt.title('Degree Distribution')
plt.xlabel('Degree')
plt.ylabel('Probability')
plt.grid(True)
plt.show()
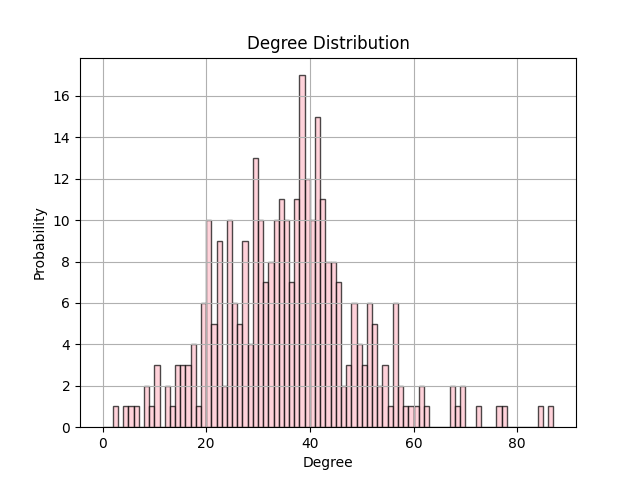
对比随机网络的度分布图和实际网络的度分布图,发现随机网络的度分布图更为集中,而实际网络的度分布图会出现一些极端值,如存在2个度大于80的节点以及部分度小于10的节点,这些情况在随机网络中均不存在。从该案例数据进行解释,该度分布图反映了高中生群体中存在少数“社牛”与“社恐”,“社牛”在社交圈子中拥有大量的朋友联系,相反,“社恐”在圈子中拥有的朋友数很少。
2.2.2 拓扑结构
对比获取的网络数据和随机网络的拓扑结构,初步认定网络数据为全连通状态。
全连通状态:
- 仅有一个巨连通分支
- 没有孤立节点和小连通分支
- 巨连通分支的大小为N
- 巨连通分支中有环
在随机网络的演化过程中,随着网络的平均度的改变,随机网络的拓扑结构也会发生变化,其中包括:亚临界状态、临界点、超临界状态以及全连通状态。当平均度 < k > <k> <k>大于 l n N ln{N} lnN时,可以认为该网络为全连通状态。从网络数据分析中所得信息可知,平均度为35.58,N为327,显然满足全连通状态的平均度要求。
2.2.3 网络直径
网络直径指的是一个网络中任意两个节点之间的最短路径的最大长度,计算网络直径的算法通常使用图论中的最短路径算法,如广度优先搜索等。基于Python,可以直接调用库函数计算图中的最短路径。
G = nx.Graph()
G.add_edges_from(random_graph.edges())
# 计算随机网络直径
diameter = nx.diameter(G)
print("随机网络直径为:", diameter)
G1 = nx.Graph()
G1.add_edges_from(graph_df.edges())
# 计算下载网络直径
diameter1 = nx.diameter(G1)
print("下载网络直径为:", diameter1)
随机网络直径为: 3
下载网络直径为: 4
从网络直径这一特征指标来看,下载的网络数据网络直径为4,而随机网络直径为3,存在一定差异。在实际情况下,真实的网络数据往往会存在极端路径,随机网络按照一定规则生成随机具有联系的节点,出现极端路径的概率较低。
2.2.4 平均距离
平均距离的计算公式:
<
d
>
=
l
n
N
l
n
<
k
>
<d> =\frac{lnN}{ln<k>}
<d>=ln<k>lnN
d_average = math.log(num_students) / math.log(average_degree)
print("公式计算的平均距离为: ", d_average)
公式计算的平均距离为: 1.620975401634233
由于随机网络的网络规模和平均度均与下载的网络相同,因此二者的网络平均距离显然相同。
2.2.5 集聚系数
集聚系数的计算公式:
C
i
=
2
<
L
i
>
k
i
(
k
i
−
1
)
C_{i}=\frac{2<L_{i}>}{k_{i}(k_{i}-1)}
Ci=ki(ki−1)2<Li>
w
h
i
l
e
<
L
i
>
=
p
k
i
(
k
i
−
1
)
2
,
p
while\;<L_{i}>=p\frac{k_i(k_i-1)}{2},p
while<Li>=p2ki(ki−1),p为节点
i
i
i任意两个邻居节点之间的连接概率。
假设节点 i i i具有 k i k_{i} ki个邻居节点,那么对于这些邻居节点,它们之间最多有 k i ( k i − 1 ) 2 \frac{k_i(k_i-1)}{2} 2ki(ki−1)条连接,因此邻居节点之间的连接数目的期望值 < L i > = p k i ( k i − 1 ) 2 <L_{i}>=p\frac{k_i(k_i-1)}{2} <Li>=p2ki(ki−1)。
clustering_coefficients = nx.clustering(random_graph)
# 提取节点和对应的聚集系数
nodes = list(clustering_coefficients.keys())
coefficients = list(clustering_coefficients.values())
# 绘制聚集系数的分布图
plt.figure()
plt.hist(coefficients, bins=20, alpha=0.75)
plt.xlabel('Clustering Coefficient')
plt.ylabel('Frequency')
plt.title('Clustering Coefficient Distribution')
plt.show()

从随机网络的集聚系数分布图来看,大多数节点的集聚系数位于0.1到0.12之间,整体分布呈现正态分布。
# 计算每个节点的聚集系数
clustering_coefficients = nx.clustering(graph_df)
# 提取节点和对应的聚集系数
nodes = list(clustering_coefficients.keys())
coefficients = list(clustering_coefficients.values())
# 绘制聚集系数的分布图
plt.figure()
plt.hist(coefficients, bins=20, alpha=0.75, color='pink')
plt.xlabel('Clustering Coefficient')
plt.ylabel('Frequency')
plt.title('Clustering Coefficient Distribution')
plt.show()
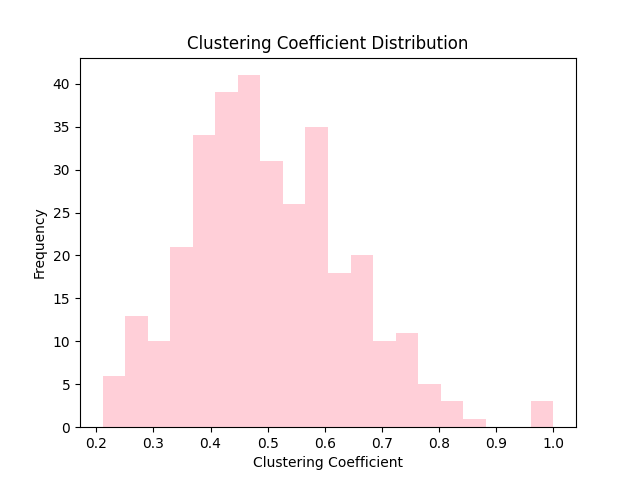
在集聚系数分布上,实际下载的网络与随机网络存在较大差异,实际网络的集聚系数明显大于随机网络所得到的集聚系数。在该数据案例中,说明自己的朋友们也很大概率成为朋友,反映了高中生群体的社交圈子较为集中。
三 度保持的网络随机化
3.1 网络生成
采用度保持的网络随机化算法可以生成与原始网络具有相同节点度分布的新网络。这种算法的目标是在保持网络的全局结构不变的前提下,随机化节点之间的连接,以此来生成具有相似度分布但是拥有不同连接模式的网络。
# 生成一个具有相同节点度分布的度保持的随机化网络
randomized_G = nx.configuration_model(
list(dict(graph_df.degree()).values()), seed=42)
plt.figure()
plt.title('Degree-Preserved Randomized Graph')
# 绘制图,并设置节点大小、标签大小、邻居节点连接距离
pos = nx.spring_layout(randomized_G, k=2, iterations=100)
# 计算节点的度
degrees = dict(randomized_G.degree())
# 根据节点的度定义节点的颜色,度越大,颜色越深
node_color = [degree for node, degree in degrees.items()]
nx.draw(randomized_G, pos, with_labels=False, node_size=200,
font_size=8, node_color=node_color, edge_color='black',
width=1)
plt.show()

从度保持随机化网络的图像中发现,整体的拓扑结构与原来的网络无明显差别,但是会出现部分成环的情况。
3.2 对比相关特征和指标
3.2.1 度分布

对比实际网络的度分布图(图8),发现根据度保持算法得到的随机网络的度分布与实际网络度分布基本一致,但仍然存在一定区别,这说明度保持算法可以在很大程度上保持原有网络节点的度分布。
3.2.2 网络直径
# 生成一个具有相同节点度分布的度保持的随机化网络
randomized_G = nx.configuration_model(
list(dict(graph_df.degree()).values()), seed=42)
G = nx.Graph()
G.add_edges_from(randomized_G.edges())
# 计算随机网络直径
diameter = nx.diameter(G)
print("度保持随机网络直径为:", diameter)
度保持随机网络直径为: 4
对比实际网络的网络直径,发现二者相同,而完全随机化的网络的网络直径与实际网络直径却有所差距,由此发现,采用度保持的随机化网络保留了实际网络更多的网络特征。
3.2.3 集聚系数
# 生成一个具有相同节点度分布的度保持的随机化网络
randomized_G = nx.configuration_model(
list(dict(graph_df.degree()).values()), seed=42)
randomized_G = nx.Graph(randomized_G)
# 计算每个节点的聚集系数
clustering_coefficients = nx.clustering(randomized_G)
# 提取节点和对应的聚集系数
nodes = list(clustering_coefficients.keys())
coefficients = list(clustering_coefficients.values())
# 绘制聚集系数的分布图
plt.figure()
plt.hist(coefficients, bins=20, alpha=0.75, color='cyan')
plt.xlabel('Clustering Coefficient')
plt.ylabel('Frequency')
plt.title('Clustering Coefficient Distribution')
plt.show()
注意:由于根据度保持的网络随机化算法得到的NetworkX图可能为多重图(指允许两个节点之间存在多条边。因此,需要将randomized_G转换为简单图对象再计算每个节点的集聚系数。

从得到的图像发现,通过度保持随机化算法得到的网络集聚系数整体明显小于实际网络各节点的集聚系数,绝大多数节点的集聚系数集中在0.10到0.15之间,相较于简单随机得到的随机网络,度保持随机化网络中少数节点出现较极端的集聚系数。
四 BA模型
4.1 BA网络模型生成
BA模型是一种用于生成无标度网络的模型,网络中的节点度数分布遵循幂律分布。BA 模型的主要思想是网络的增长和优先连接。
- 增长特性:网络通过添加新的节点而不断生长,即网络的规模是不断扩大的。
- 优先连接特性:即新的节点更倾向于与那些具有较高连接度的节点相连接,这种效应也被称为“富者更富”或“马太效应”。
BA = nx.random_graphs.barabasi_albert_graph(327, 35)
plt.figure()
plt.title('BA Model Graph')
pos = nx.spring_layout(BA, k=2, iterations=100)
# 计算节点的度
degrees = dict(BA.degree())
# 根据节点的度定义节点的颜色,度越大,颜色越深
node_color = [degree for node, degree in degrees.items()]
nx.draw(BA, pos, with_labels=False, node_size=200,
font_size=8, node_color=node_color, edge_color='black',
width=1)
plt.show()
下载的网络数据的网络规模为327,平均度为35.58,因此设置模型参数n、m分别为327、35(两者均要求为int型变量),为更好地与原有数据图像对比,同样按照度越大颜色越深的方法实现可视化图像。

从BA模型生成的图像来看,颜色更深的节点数目明显多于原有数据整体图像(图4),这很好地反映了BA模型的优先连接特性,它对度数越高的节点赋予更高的连接可能性,因此出现“富者越富”现象。
4.2 对比相关特征和指标
4.2.1 度分布
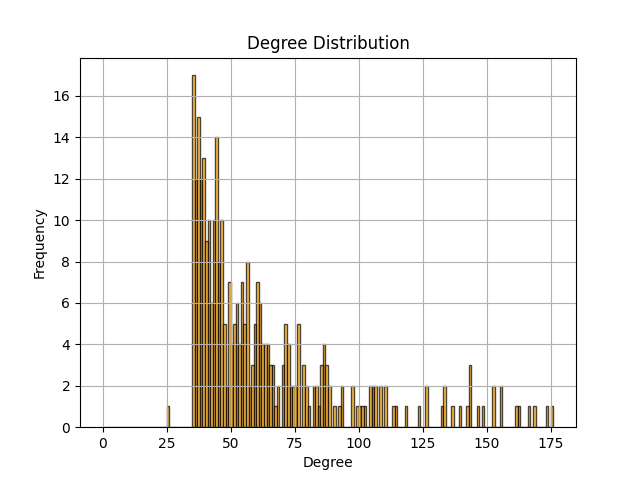
从得到的BA模型度分布图像来看,BA网络节点的度分布呈现反比例函数曲线趋势,存在少数度较大的节点,绝大多数节点的度在30到50之间,但是却不存在度小于25的节点。这相较于实际网络存在差异,实际网络中存在具有更小度的节点,但尚未出现度大于100的节点。BA网络模型的度分布呈现这种现象也恰好反映了它增长、优先连接的特性,这种特性使得具有更大度的节点出现的可能性增大。
4.2.2 网络直径
BA模型网络直径为: 3
BA网络模型的网络直径为3,与实际网络模型的网络直径存在差异,与简单随机化网络的网络直径相同。
4.2.3 集聚系数
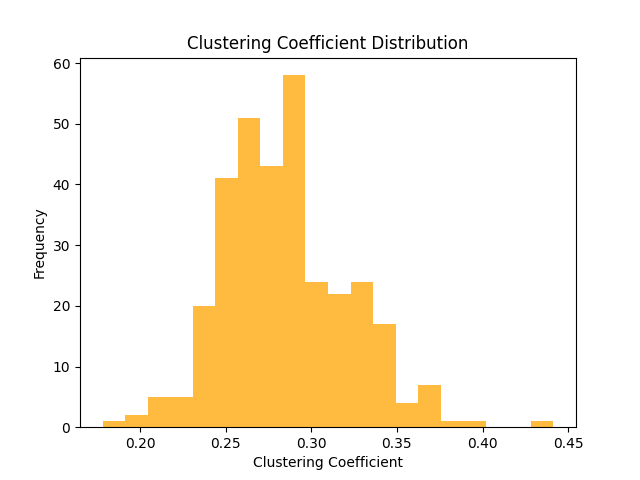
对比实际网络模型集聚系数分布图(图10),BA网络模型的集聚系数分布较为集中,绝大多数集中在0.25到0.35之间,同时,BA网络模型各节点整体的集聚系数也小于实际网络模型节点的集聚系数。但是相较于简单随机化网络与度保持的随机化网络,BA网络模型中的节点拥有较大的集聚系数。















 2703
2703

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









