










粗糙的刑事量刑模型-随机森林算法
一、效果
(一)特征重要性
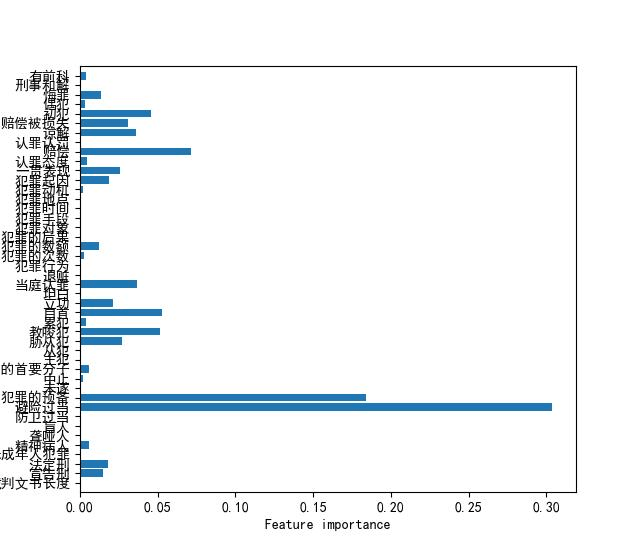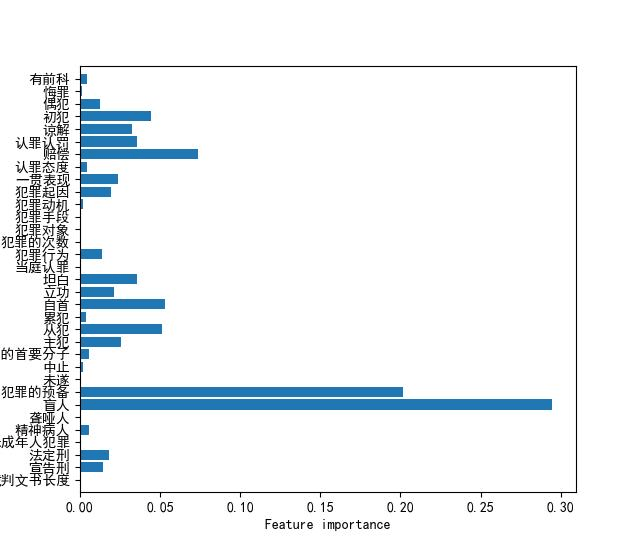
(二)预测精度

(三)结果
监督学习的几个算法都试过,只有随机森林的测试集效果较好可以达到30%,其余大多只有20%多,当然如果继续调参可能会更好,但是整体而言,大致也仅在30%左右;训练集最好的时候可以到80%以上,但是测试集最高只能30%左右
结论:模型泛化能力不足,拟合能力也不是非常好
可能原因:特征使用的量刑情节使用的是0、1判断,可能过于稀疏而且提取时也可能存在一定问题,可能没有和特定的人匹配完全。需要重新调整参照标签
二、大致思路
(一)数据爬取
数据爬取使用的是selenium+xpath,尝试过使用requests,也进行了js反反爬
部分js反反爬
def __RequestVerificationToken():
"""cipher参数解密"""
start_logger()
with open('J:\\PyCharm项目\\项目\\中国裁判文书网\\requests路线\\cipher.js', encoding='utf-8') as f:
jsdata_1 = f.read()
js_1 = execjs.compile(jsdata_1, cwd=r"C:\\Users\\Administrator\\node_modules")
__RequestVerificationToken = js_1.call('random',24)
return __RequestVerificationToken
logging.debug(__RequestVerificationToken())

有关js反反爬需要感谢大佬"越学越害怕"的帮助,虽然最后由于瑞数没有成功。
request没有成功采用的是selenium,链接: 中国裁判文书下载:selenium路线.
最后成功获取28万份裁判文书!!!!!!
但是原本准备获取58万份裁判文书的,失败的原因部分在于网络,有时因为网络延迟导致翻页失败;但是还有一些不知道为什么拿不到,可能是由于通过全国区县的限定词进行全文检索限定的不够精确将部分文书忽略掉了
(二)数据处理
1、解压缩
解压:
def unzip_file(zip_file_name, destination_path):
try:
archive = zipfile.ZipFile(zip_file_name, mode='r')
for file in archive.namelist():
try:
archive.extract(file, destination_path)
except Exception as e:
print(e)
continue
except:
pass
def zipfile_name(file_dir):
# 读取文件夹下面的文件名.zip
L = []
index = 1
for root, dirs, files in os.walk(file_dir):
#rint(files)
for file in files:
if os.path.splitext(file)[1] == '.zip': # 读取带zip 文件
L.append(os.path.join(root, file))
print("正在解压缩-----------------第%d个压缩包-------------------------------------" % index)
index += 1
return L
# 入口函数
def main():
fn = zipfile_name(input_files.strip('\u202a'))
for file in fn:
unzip_file(file, output_files.strip('\u202a'))
if __name__ == "__main__":
main()
这是是从csdn上复制下来的,自己用的也是这个,应该是来自博主:DesolatePoison的《https://blog.csdn.net/qq_40695642/article/details/100170316?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522159357139119725211911252%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=159357139119725211911252&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allfirst_rank_ecpm_v1~rank_ctr_v4-3-100170316.ecpm_v1_rank_ctr_v4&utm_term=%E6%96%87%E4%BB%B6%E6%89%B9%E9%87%8F%E8%A7%A3%E5%8E%8B%E7%BC%A9python》
整体解压时间似乎也较长大体上应该花了5-6个小时
2、去重
由于爬取时使用全文检索,不可避免的会存在下载的裁判文书重复,因而写了去重的程序
def repeat_file_find():
repeat_files = {}
for file_name in file_names:
if file_name in repeat_files:
repeat_files[str(file_name)] += 1
else:
repeat_files[str(file_name)] = 1
'''排序'''
repeat_files_ = sorted(repeat_files.items(), key=lambda x: x[1], reverse=True)
pprint.pprint(repeat_files_[:100])
with open("重复文件有哪些.json", "w+")as f:
json.dump(repeat_files_,f)
#文件dump,数据dumps
#repeat_file_find()
data = open("重复文件有哪些.json", "r", encoding='utf-8', errors='Egnore').read()
datas = json.loads(data)
for i in datas:
print(i)
但是奇怪的是:似乎没有重复的文件??????、

该内容已经经过排序了,最多的排在前面,但是这里没有重复的文件
疑惑:似乎解压后不用去除,可以自动去重?
好像确实是这样,在后面移动也是如此
3、格式转换
裁判文书下载下来的是压缩包,压缩包内文件格式为doc

python不识别doc,python-docx只能使用docx格式的,但是下载的文书格式均为doc格式的,因为需要转为docx格式的
比较坑的是:
csdn上转换的docx,都是使用word实现的,但是我用到是wps,用word也能转换为docx,不报错。
但是读取时就会无法读取,csdn上说加空格,这是没有什么用的,原因就在于缺失了word,应该是这个原因,因而转为能够读取的docx需要使用先用的wps程序
代码:
def doc_to_docx(path):
"""
DOC转为docx,wps格式
"""
index_ = 1
"""打开wps"""
#word = wc.gencache.EnsureDispatch('kwps.application')#有缓存之类的
#重复跳过一:
with open("J:\PyCharm项目\项目\中国裁判文书网\selenium路线\数据清洗模块\文书由doc转为docx\docx已经有的.txt","r",encoding="utf-8")as f:
list_ = f.readlines()
# 重复跳过二:
with open("J:\PyCharm项目\项目\中国裁判文书网\selenium路线\数据清洗模块\docx移动至新文件夹中\已经存在的docx.txt","r",encoding="utf-8")as f:
list_2 = f.readlines()
"""遍历doc文档"""
for index,path_ in enumerate(glob.glob(os.path.join(path, "*"))):
path1 = path_ + "\n"
if path1 in list_ or path1 in list_2:#
print("重复跳过中-----------------------------------")
pass
else:
try:
word = wc.Dispatch('kwps.application')
doc = word.Documents.Open(path_)
# 错在没有加入文件名,位置加名字加格式
"""保存在同一文件夹下命名为docx,注意此处必须为docx否则转换不成功,必须为12否则无法读取"""
doc.SaveAs2(path_.split('.')[0] + ".docx", 12)
# print(path_.split('.')[0] + ".docx")
# 保存在其他地方的 文件夹
# doc.SaveAs(output + path_.split("/")[-1].split(".")[0] + ".docx", 16)
print('正在进行格式转换--------------------------%d---------------------------------' % index)
print("页面关闭第%d次---------------------------------------"%index_)
index_ += 1
doc.Close()
if index_ < 10000:
pass
else:
word.Quit()
print("wps程序退出中--------------------%d---------"%index_)
index_ = 1
except Exception as e:
print(e)
关键:
word = wc.Dispatch('kwps.application')#是kwps而不是word
doc.SaveAs2(path_.split('.')[0] + ".docx", 12)#参数为12
这样转换比较忙,用了二天多,而这过程中无法使用wps,否者会乱
如果有更好的方法请一定私信我!!!!!!!!
4、文件移动
当然这个可以在第3步的时候直接docx保存到指定的文件夹中
文件移动过程中发现,确实可以去重,因为重复文件不会移动到指定的文件夹中去
5、法条分割为匹配的数据集
当然这有个前提就是先要读取docx文档内容
我用python-docx有时能读有时不能,就换成了docx2txt
主要代码:
text = docx2txt.process(path)
print(text)
通过逗号、句号进行分割形成匹配数据集
def split_docx_judments(path):
“”“刑事诉讼法、民事诉讼法、行政诉讼法基本可以共用一套函数”""
writer = []
index = 1
list_ = []
text = read(path).replace("\n", “”).replace("\u3000", “”).replace(" ", “”).strip()
pattern = re.compile("判决如下:被告人(.*?)犯(.*?),判处有期徒刑(.*?),")
match = re.findall(pattern,text)
if len(match) > 0:
#print("文书内容:",match)
for content_ in match:
if "强奸罪" in content_:
#print("命中文书内容:", i)
content = text.split(",")
"""一个一个切分"""
for i in content:
for i_ in i.split("。"):
for i_1 in i_.split(";"):
for i_2 in i_1.split(":"):
for i_3 in i_2.split("、"):
writer.append(i_2.strip())
return writer,content_
else: # 补上这一句是为了防止匹配失败时的处理也是非len(match) > 0
content = "非正常裁判文书"
return content
分割完成后为:

当然也可以通过jieba进行切词,但是切词的用来作为匹配时的错误可能性就会比较高,因而我选用的是这种方法
6、选择罪名和法定刑
不能进行全罪名,这样有些量刑情节会出现问题
用正则提取,主要内容
pattern = re.compile("【(.*?)】.*?的,处(.*?)。")
content_need = re.findall(pattern, writer)
pattern_ = re.compile("【(.*?)】.*?的,对(.*?)。")
提取后放入csv

7、选择量刑情节
通过《量刑指导意见》进行提取,核心的正则匹配
pattern = re.compile("量刑要素的细化(.*?)第二十七条")
结果为:

此处部分内容进行了人工填补
8、加重构成要件的去除
选择的罪名为:强奸罪,原因相对重要的罪名,且其基础法定刑为3-10年,可能较好处理
去除加重构成要件核心在于模糊匹配
def clear_high_simple(path):
"""简单判断是否超过十年"""
try:
if sp(path) == "非正常裁判文书":
message = "非正常裁判文书"
return message
else:
text, match = sp(path)
Arabic_numerals = cm(str(match))
if Arabic_numerals >= 10:
with open("J:\PyCharm项目\项目\中国裁判文书网\selenium路线\法条内容提取\加重构成要件排除\强奸罪加重.txt", "r")as f:
for i in f.readlines():
for i1 in text:
# print(fuzz.partial_ratio(i.strip("\n"), i1))
fraction = fuzz.partial_ratio(i.strip("\n"), i1)
if fraction > 80 and len(i1) > 2:
number = 1
return number
else:
number = 0
return number
except Exception as e:
print(e)
9、模糊匹配相应数据并写入excel中
模糊匹配前需要先对文书内容进行特点罪名的读取,只选择选定大多罪名
选择选定的罪名进行相应文书的选择
def split_docx_judments(path):
"""刑事诉讼法、民事诉讼法、行政诉讼法基本可以共用一套函数"""
writer = []
index = 1
list_ = []
text = read(path).replace("\n", "").replace("\u3000", "").replace(" ", "").strip()
pattern = re.compile("判决如下:被告人(.*?)犯(.*?),判处有期徒刑(.*?),")
match = re.findall(pattern,text)
if len(match) > 0:
#print("文书内容:",match)
for content_ in match:
if "强奸罪" in content_:
#print("命中文书内容:", i)
content = text.split(",")
"""一个一个切分"""
for i in content:
for i_ in i.split("。"):
for i_1 in i_.split(";"):
for i_2 in i_1.split(":"):
for i_3 in i_2.split("、"):
writer.append(i_2.strip())
return writer,content_
else: # 补上这一句是为了防止匹配失败时的处理也是非len(match) > 0
content = "非正常裁判文书"
return content
这种选择相对比较成功,因为裁判文书的判决基本格式为:

即其格式化相对模型,正则提取后的人与罪能够在一起
然后是整篇文书相应内容的写入
for i in text:
# print(i)
"""一直出现问题在于txt路径是相对路径"""
with open("J:\PyCharm项目\项目\中国裁判文书网\selenium路线\法条内容提取\量刑情节.txt", "r", encoding="utf-8")as f:
condition = f.readlines()
for i_ in condition:
if fuzz.partial_ratio(i_.strip("\n"), i) > 90:
element_lists[title] = 1
dataframes[i_.strip("\n")] = element_lists
"""注意此处的缩进程度需到此处即for处,继续缩进存在无法更新过快"""
for i_ in condition:
element_list[title] = 0
dataframe[i_.strip("\n")] = element_list
这里有个问题就是字典的更新,直接if.else会对内容进行覆盖,此处原因不知道是字典本身的原因还是由于我使用了多线程导致的
进行字典更新,比较复杂的写法
"""字典更新"""
dataframe_ = dict(dataframe, **dataframes)
"""法定刑更新"""
dataframe_1 = {"法定刑": {title: 6}}
dataframe_2 = dict(dataframe_, **dataframe_1)
"""文书长度更新"""
dataframe_3 = {"裁判文书长度": {title: len(''.join(text))}}
dataframe_4 = dict(dataframe_2, **dataframe_3)
"""宣告刑更新"""
dataframe_5 = {"宣告刑": {title: match[2]}}
dataframe_6 = dict(dataframe_4, **dataframe_5)
pprint.pprint("更新后的字典 :")
pprint.pprint(dataframe_6["宣告刑"][title])
pprint.pprint(dataframe_6)
之后就是excel的写入
10、数据调整
合并excel,核心代码:
pd.concat(data_frames, axis=0, ignore_index=True)
数据内容处理,主要是分组,将机器学习的参数标签与预测值进行分开,如果写入做的比较好就不需要进行这样的数据处理
def data_site_change():
content = pd.read_excel(r"F:\360下载\提取后的excel文件(测试集)\合并的excel\合并的量刑模型数据(原始).xls".strip('\u202a'))
# 位置调换
dataframe_2 = content.宣告刑
# df已经变更为content
df = content.drop('宣告刑', axis=1)
#print("修改时: ")
#print(df)
df.insert(1, '宣告刑', dataframe_2)
#print("修改后: ")
x = df.iloc[:, 2:]
#print(x)
y = df.iloc[:, 1:2]
df["宣告刑"] = df["宣告刑"].map(lambda x:cm(x))
df["法定刑"] = df["法定刑"].map(lambda x:p(x))
print(df)
writer = pd.ExcelWriter(r"F:\360下载\提取后的excel文件(测试集)\合并的excel\合并的量刑模型数据_2.xls".strip('\u202a'))
df.to_excel(writer, sheet_name='强奸罪量刑模型修改', index=False)
writer.save()
data_site_change()
这里的关键在于中文数字转为阿拉伯数字数字
转换代码:将csdn上的一个博主的中文转数字进行了加工
def chinese_math(need_change):
"""注意单位:此时是月"""
time_year = 0
time_month=0
for i, key in enumerate(list(need_change)):
if key == "年":
number = list(need_change)[i - 1]
# print(list(need_change)[i-1])
if number in word.keys():
time_year = change(number) *12
elif key == "月":
number_1 = list(need_change)[i - 2]
if number_1 in word.keys():
time_month = change(number_1)
time = time_year + time_month
#print(str(time) + "年")
return time
need_change = “三年七个月。(刑期从判决执行之日起计算。判决执行以前先行羁押的”
print(chinese_math(need_change))

全部转换为月份,因为全部转为年份,在训练时汇报数据类型错误(实测比较麻烦,所以转为月份),使用int()强制转换会造成宣告刑的不准确,因而转为月份较好。
修改前:

修改后:

当然此处的法定刑并不是进行了转换,而是修改,因为之前使用中线理论设置为6年,但是拟合能力不足,于是通过随机数增加权重的方法进行了随机化以模拟幅度理论(其实影响不大,几乎没有什么影响)
11、机器学习
基本都是使用监督学习算法
首先进行数据类型转换
df = pd.read_excel(file)
X_ = df.iloc[:,2:]
y_ = df.iloc[:,1:2]
"""变成列表"""
X = X_.values.tolist()
y_1 = y_.values.tolist()
"""两层列表变成一层"""
y = sum(y_1,[])
"""数组化"""
X= np.array(X)
y = np.array(y)
最终结果需要变为数组,即
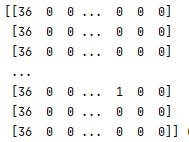
sklearn的数据集类型也是这样
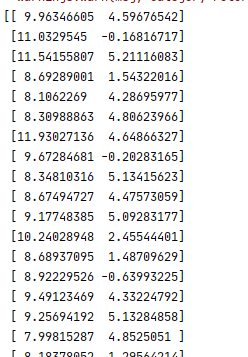
<class 'numpy.ndarray'>
否者报错:
ValueError: Number of features of the model must match the input. Model n_features is 44 and input n_features is 2

第一个是k近邻算法的拟合得分,第二个是随机森林的得分
拟合效果以及测试集的拟合效果均不是很好,特别是测试集的拟合
最后一个list格式的是预测值,k近邻算法反而比拟合效果好的随机森林要准确,正确的值为40个月
github仓库中的一个量刑辅助的测试集得分只有0.16

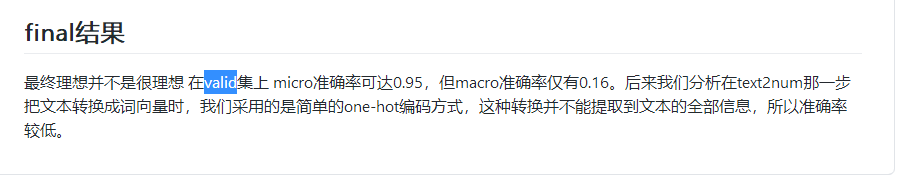
可见可能是相关标签的抽取的多少以及准确度问题
三、总结
机器学习效果不太好的原因可能是量刑情节设置的不太合理,但是也有本身不完善的原因,
等待下一步调整















 1841
1841











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









