







文章目录
一,案例分析
(一)TopN分析法介绍
TopN分析法是指从研究对象中按照某一个指标进行倒序或正序排列,取其中所需的N个数据,并对这N个数据进行重点分析的方法。
(二)案例需求
现假设有数据文件num.txt,现要求使用MapReduce技术提取上述文本中最大的5个数据,并最终将结果汇总到一个文件中。
先设置MapReduce分区为1,即ReduceTask个数一定只有一个。我们需要提取TopN,即全局的前N条数据,不管中间有几个Map、Reduce,最终只能有一个用来汇总数据。
在Map阶段,使用TreeMap数据结构保存TopN的数据,TreeMap默认会根据其键的自然顺序进行排序,也可根据创建映射时提供的 Comparator进行排序,其firstKey()方法用于返回当前集合最小值的键。
在Reduce阶段,将Map阶段输出数据进行汇总,选出其中的TopN数据,即可满足需求。这里需要注意的是,TreeMap默认采取正序排列,需求是提取5个最大的数据,因此要重写Comparator类的排序方法进行倒序排序。
二,案例实施
(一)准备数据文件
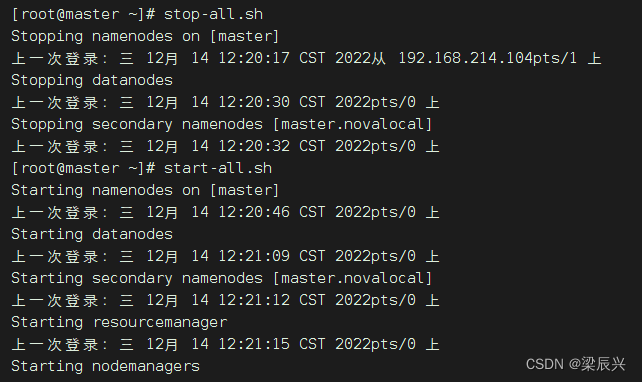
(1)启动hadoop服务
输入命令:start-all.sh
(2)在虚拟机上创建文本文件
1.expor目录下创建topn目录,输入命令:mkdir /export/topn

2.在topn目录下创建num.txt文件,输入命令:touch /export/topn/num.txt

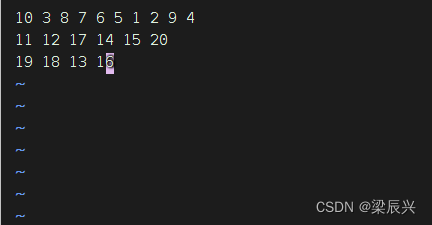
3.向num.txt文件添加如下内容:
10 3 8 7 6 5 1 2 9 4
11 12 17 14 15 20
19 18 13 16
输入命令:vim /export/topn/num.txt

(3)上传文件到HDFS指定目录
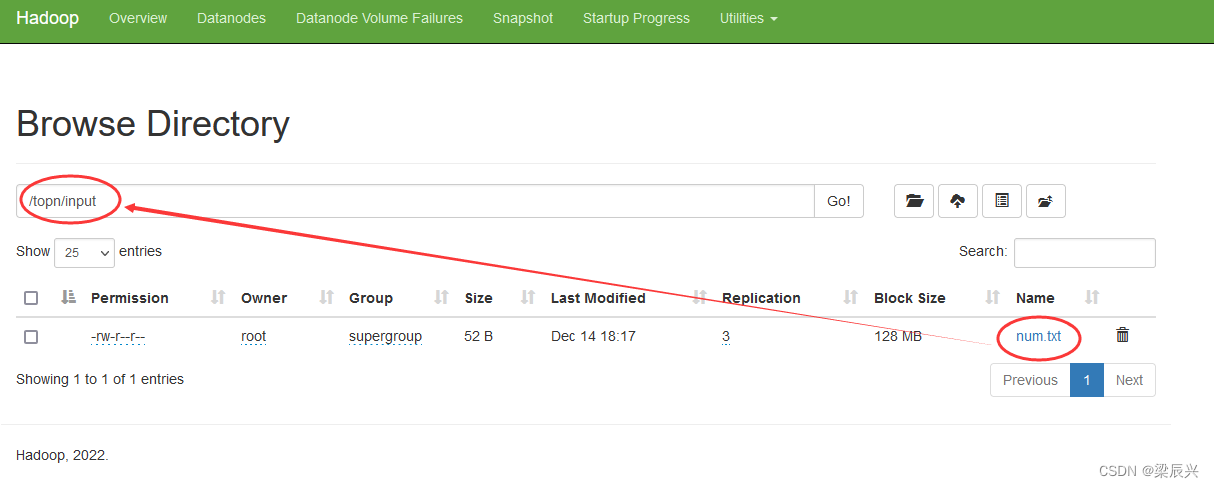
1.创建/topn/input目录,输入命令:hdfs dfs -mkdir -p /topn/input

2.将文本文件num.txt,上传到HDFS的/topn/input目录,输入命令:hdfs dfs -put /export/topn/num.txt /topn/input

3.在hadoop webui查看文件是否上传成功
(二)Map阶段实现
使用IntelliJ开发工具创建Maven项目TopN,并且新建net.hw.mr包,在该路径下编写自定义Mapper类TopNMapper,主要用于将文件中的每行数据进行切割提取,并把数据保存到TreeMap中,判断TreeMap是否大于5,如果大于5就需要移除最小的数据。TreeMap保存了当前文件最大5条数据后,再输出到Reduce阶段。
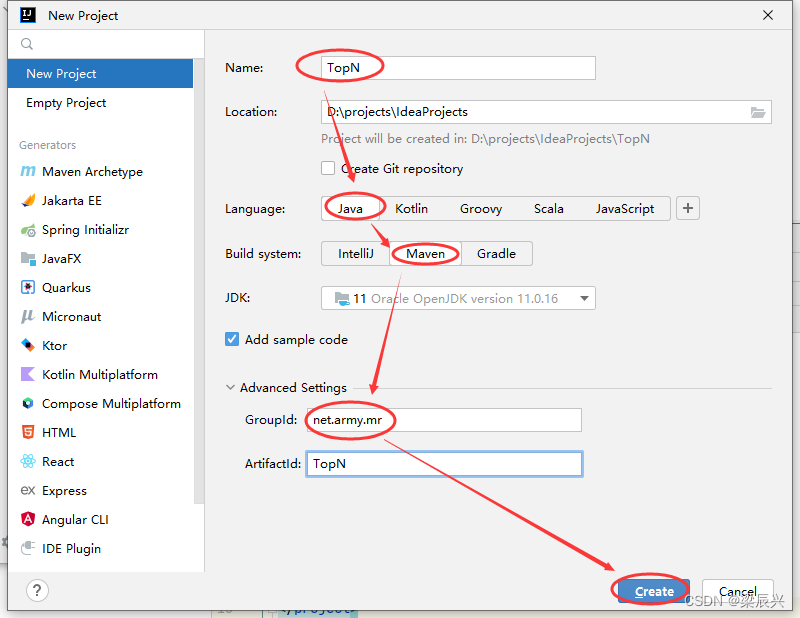
(1)创建Maven项目:TopN
1.配置好如下图,单击【Create】按钮
 2.创建成功
2.创建成功
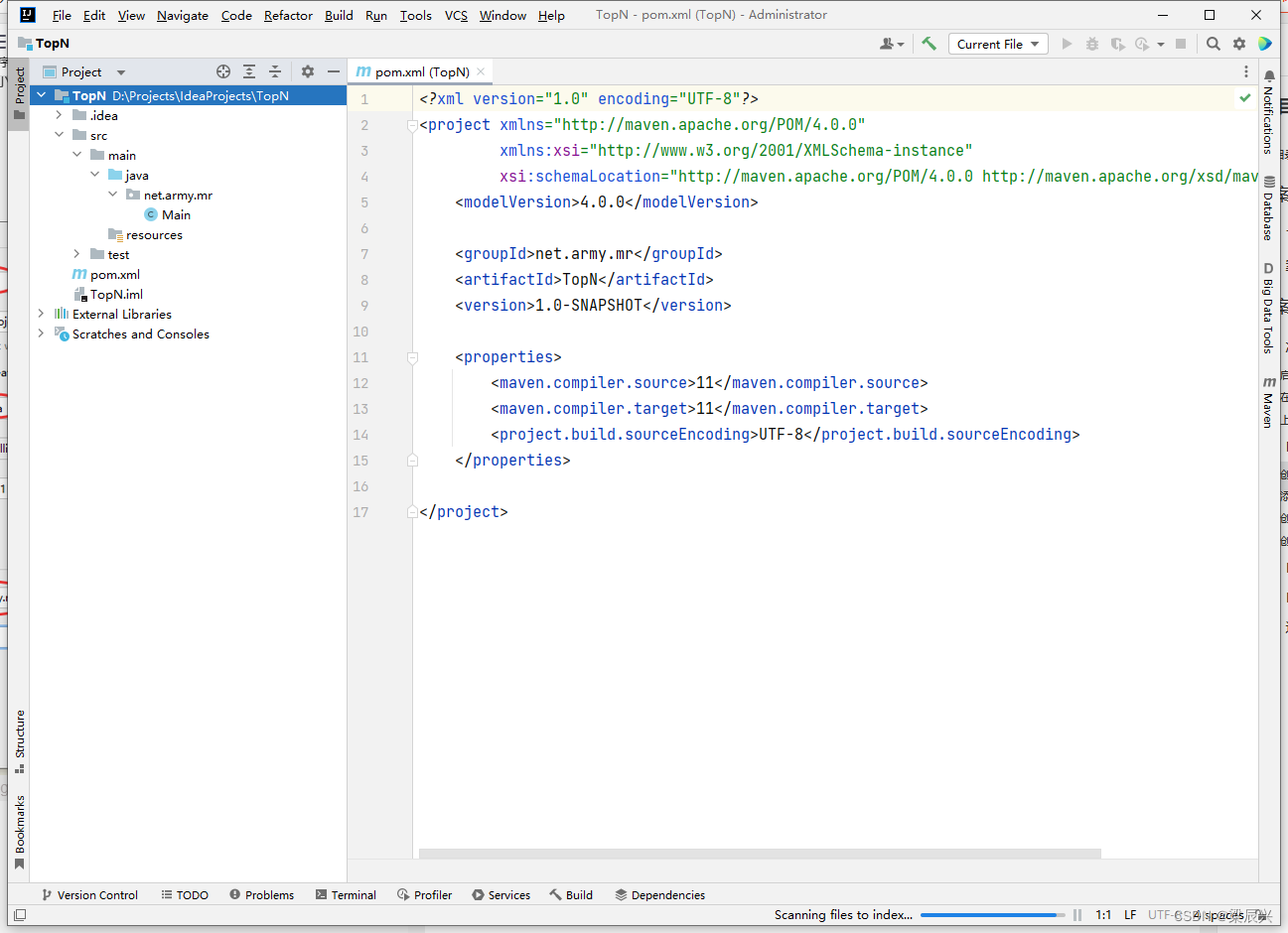 3.删除【Main】主类:右击【Main】类,单击【Delete】
3.删除【Main】主类:右击【Main】类,单击【Delete】
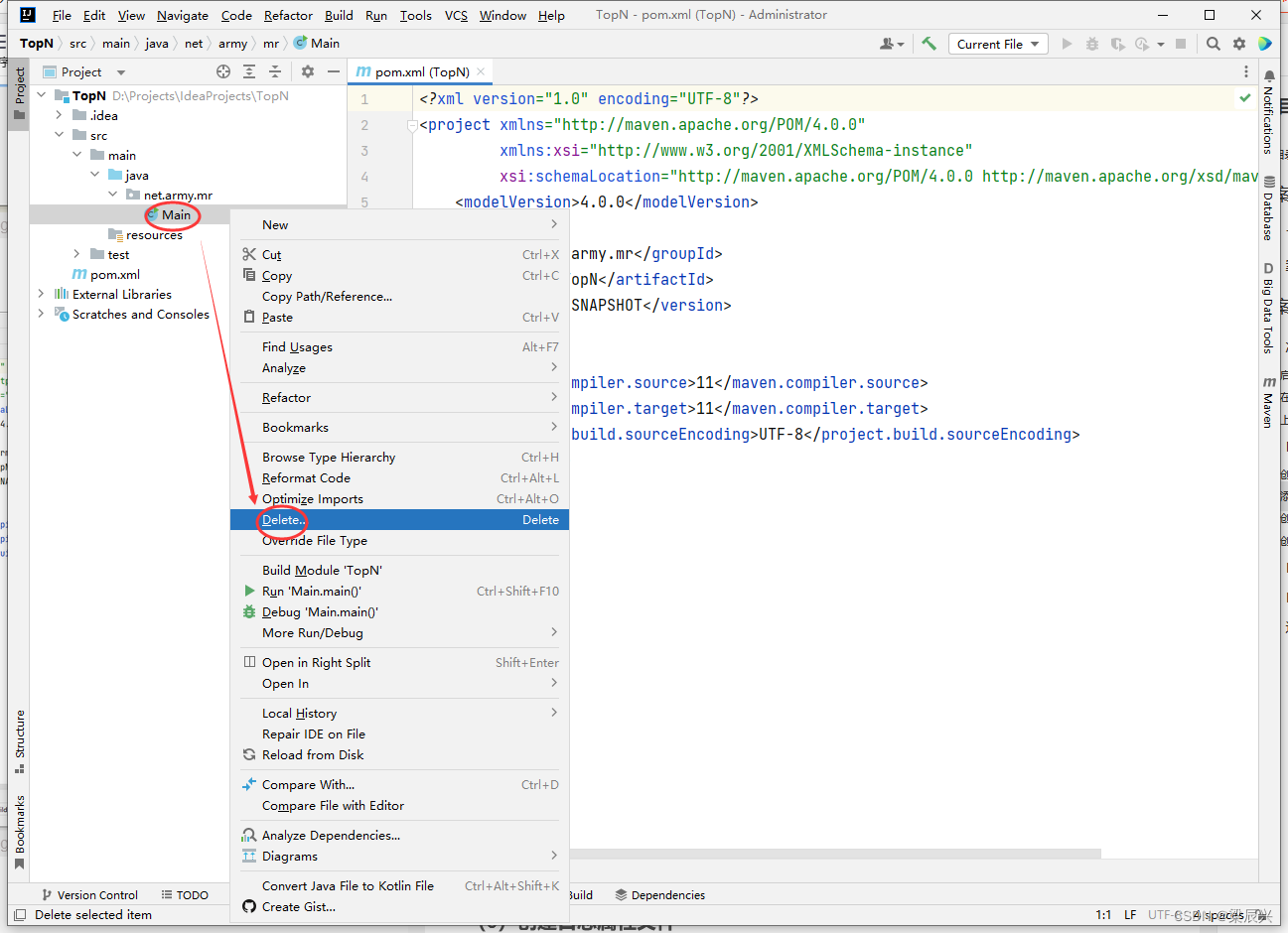
(2)添加相关依赖
1.在pom.xml文件里添加hadoop和junit依赖,添加内容如下:
<dependencies>
<!--hadoop客户端-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.4</version>
</dependency>
<!--单元测试框架-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.2</version>
</dependency>
</dependencies>
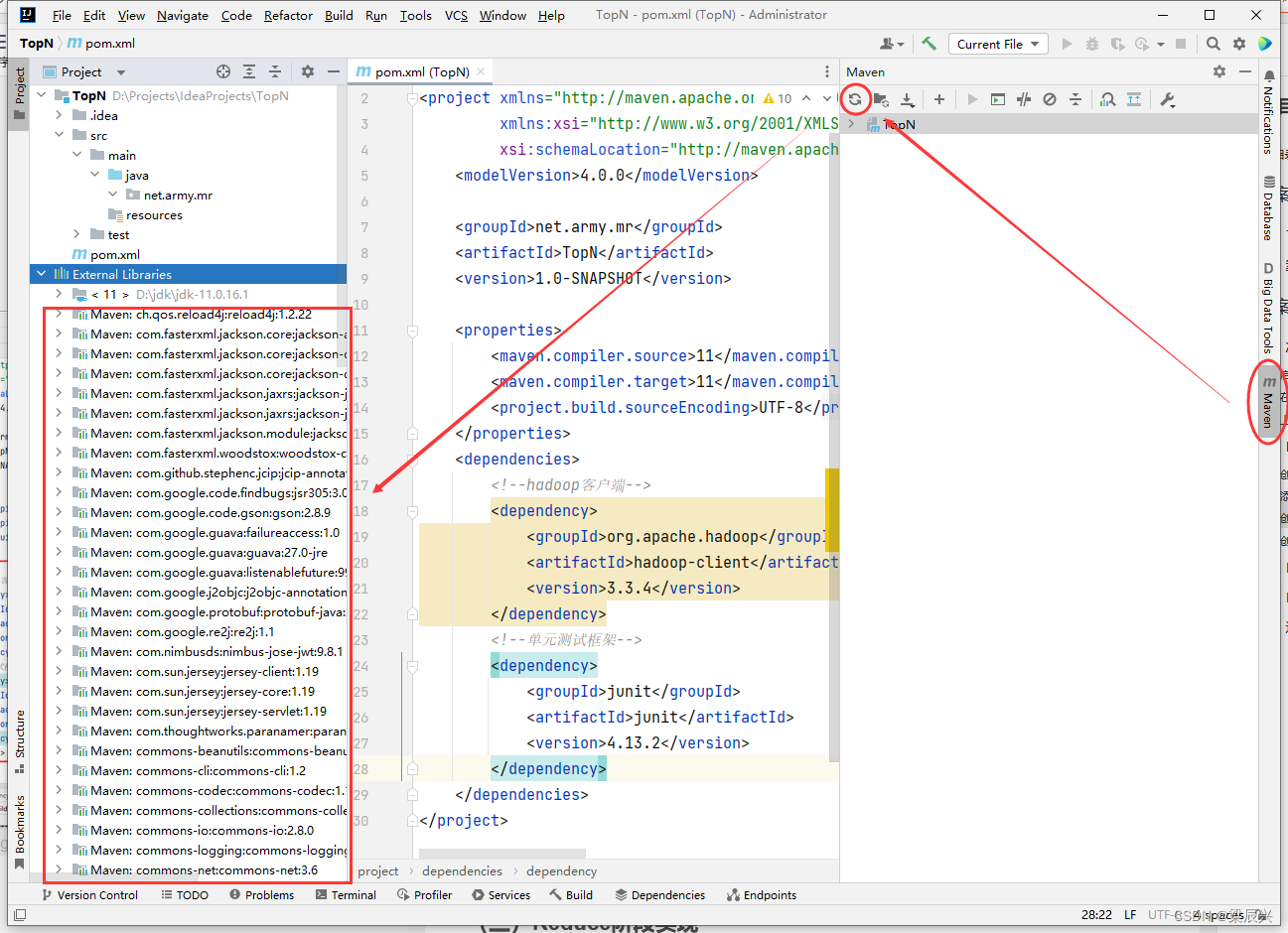
2.刷新本地的maven仓库,如果没有下载,会自动下载依赖到本地:单击【Maven】,单击【刷新】按钮
(3)创建日志属性文件
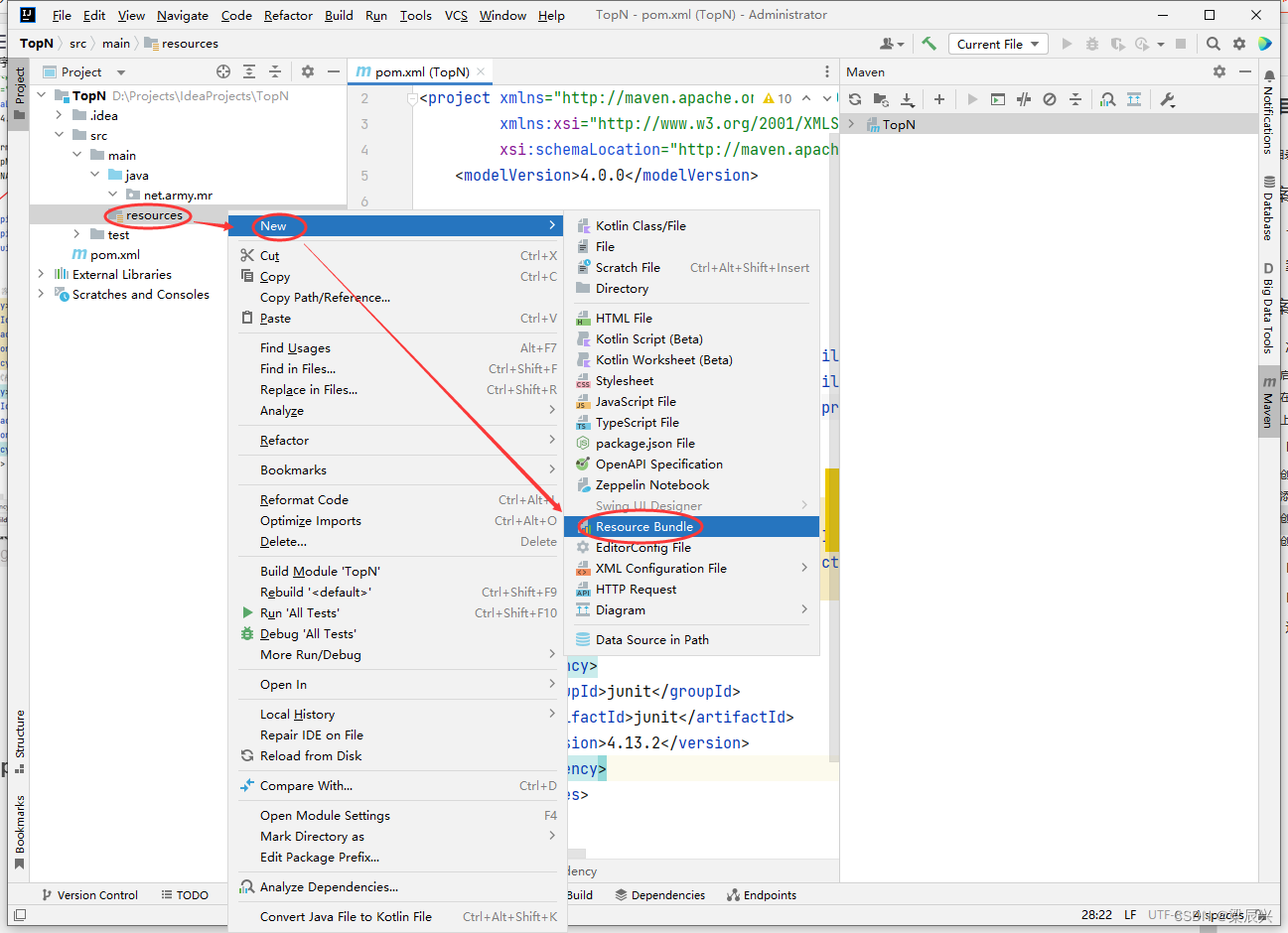
1.在resources目录里创建log4j.properties文件,右击【resources】,选择【New】,单击【Resource Bundle】
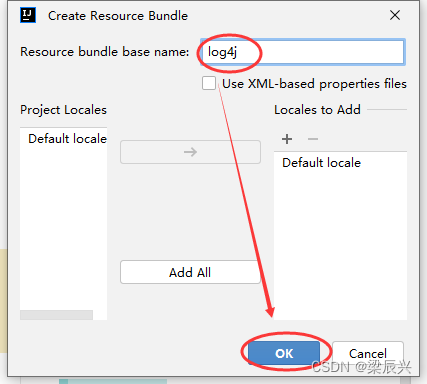
2.在弹出的对话框中输入:log4j,按【OK】按钮,成功创建
3.向log4j.properties文件添加如下内容:
log4j.rootLogger=INFO, stdout, logfile
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 237
237











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









