







 超级会员免费看
超级会员免费看
代码讲解:基于python居民消费水平的的kemans聚类分析可视化实战完整 代码数据_哔哩哔哩_bilibili
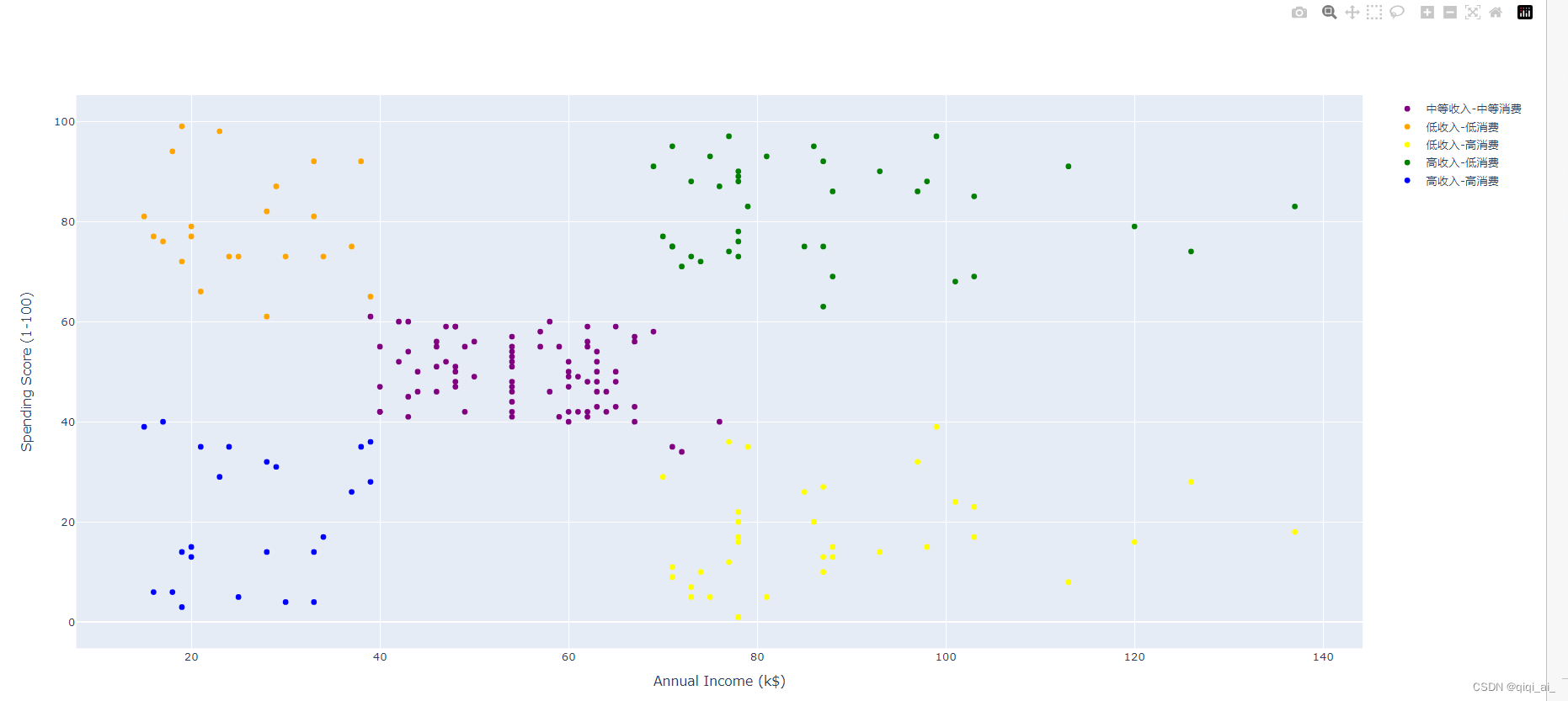
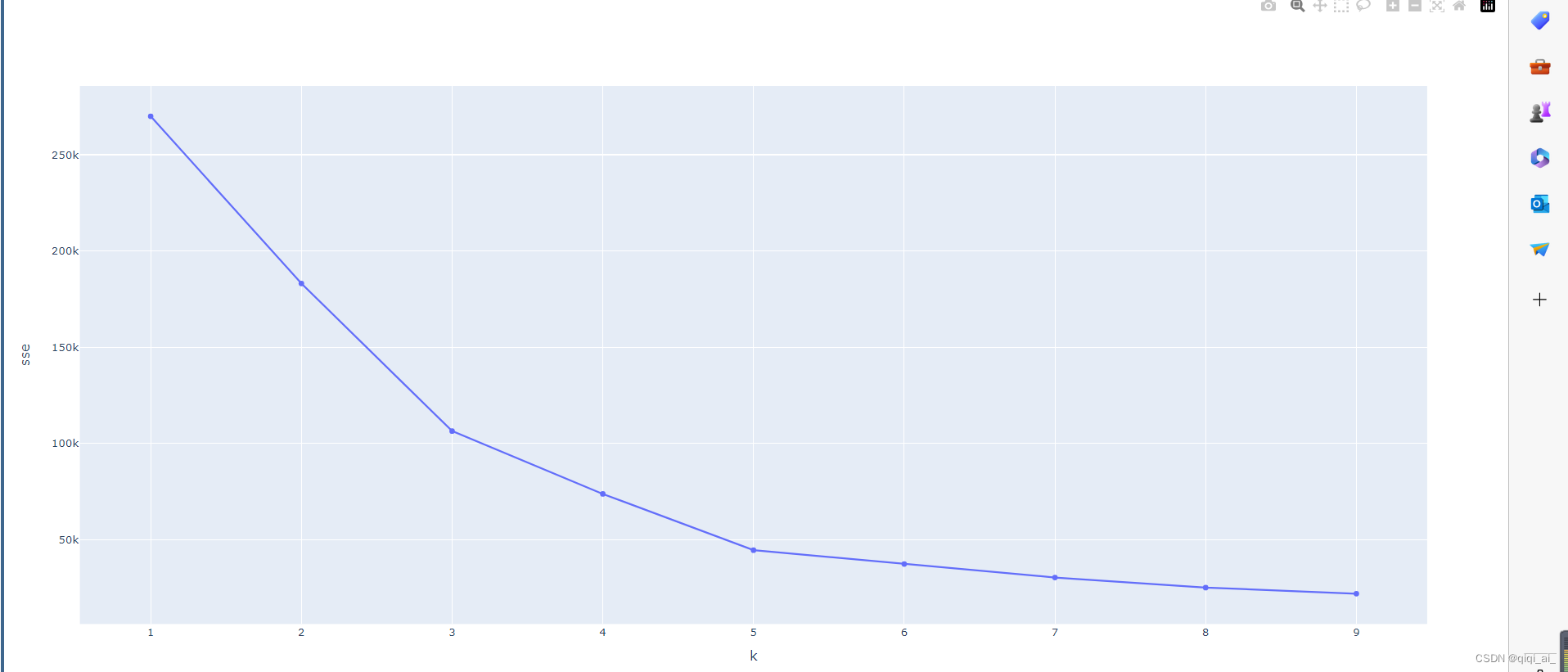
完整代码:
#引入依赖
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import plotly.offline as py
import plotly.graph_objects as go
from sklearn import preprocessing
from sklearn.cluster import KMeans
df = pd.read_csv(r'data.csv')
print(df.head(5))
print(df.info())
trace = go.Scatter(x=df['Annual Income (k$)'], y=df['Spending Score (1-100)'], mode='markers')
layout = go.Layout(xaxis=dict(title='Annual Income (k
 订阅专栏 解锁全文
订阅专栏 解锁全文

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











