






目录
3.4 线性判别分析
一般使用流程
线性判别分析的一般使用流程如下:首先在训练集上学得模型,由向量内积的几何意义可知,y 可以看作是x在w上的投影,因此在训练集上学得的模型能够保证训练集中的同类样本在w上的投影y很相近,而异类样本在w上的投影y很疏远。然后对于新的测试样本
,将其代入模型得到它在w上的投影
,然后判别这个投影
注意:线性判别分析是一种监督降维方法,即降维过程中需要用到样本类别标记信息。
算法原理
线性判别分析(Linear Discriminant Analysis,简称LDA)是一种经典的线性学习方法,也叫“Fisher判别分析”。
LDA的思想:给定训练样例集,设法将样例投影到一条直线上,使得同类样例的投影点尽可能接近
、异类样例的投影点尽可能远离;在对新样本进行分类时,将其投影到同样的这条直线上,再根据投影点的位置来确定新样本的类别。
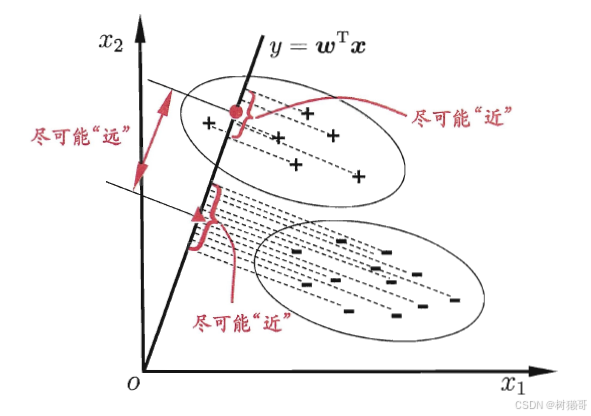
LDA的二维示意图。“+”、“-”分别代表正例和反例,椭圆表示数据簇的外轮廓,虚线表示投影,红色实心圆和实心三角形分别表示两类样本投影后的中心点 。
针对同类样例的投影点尽可能接近,可以让同类样例的协方差尽可能小,即尽可能小;
针对异类样例的投影点尽可能远,可以让类中心之间的距离尽可能大,即尽可能大。
右下角的“2”表示求“2 范数”,向量的2 范数即为模,右上角的“2”
表示求平方数。
同时考虑以上二者,则得欲最大化目标

推导过程:

定义:类内散度矩阵
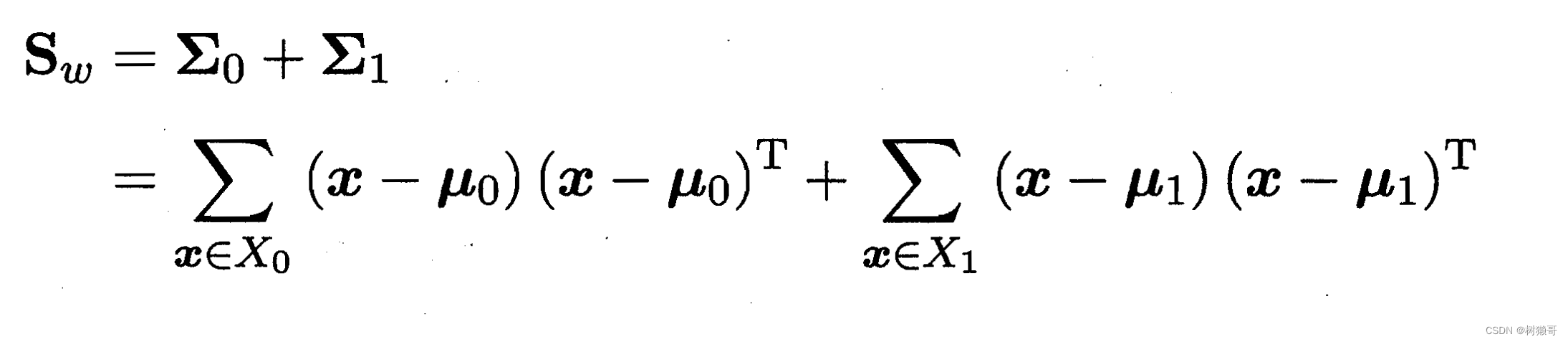
定义:类间散度矩阵
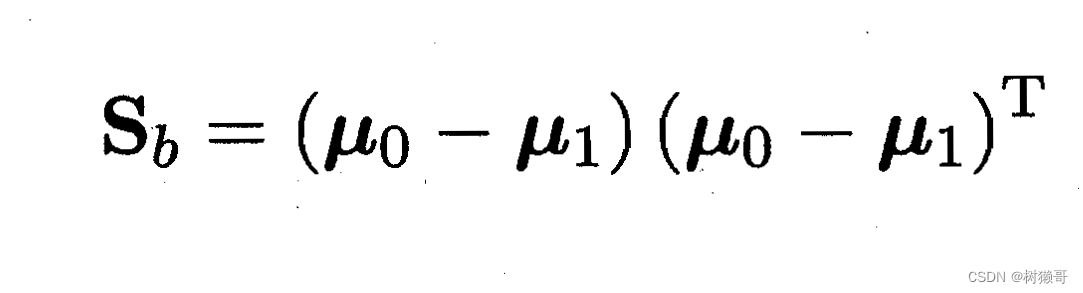
结合以上类内散度矩阵和类间散度矩阵,得
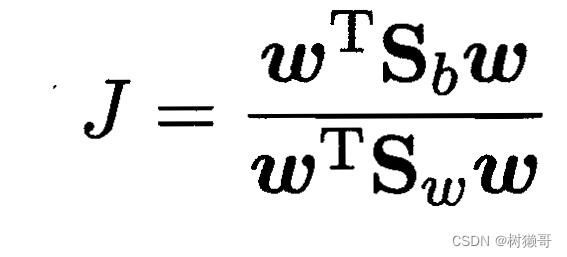
LDA的最大化目标,
和
的广义瑞利商。
求解w
令,则J等价于
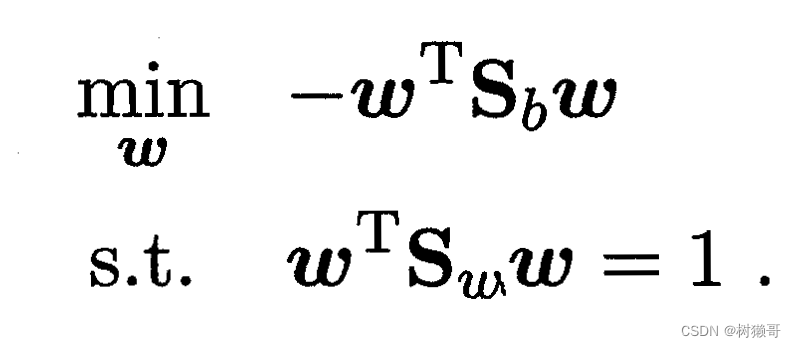
由此可定义拉格朗日函数,

由于最终要求解的w不关心其大小,只关心其方向,所以其大小可以任意取值。又因为 和
的大小是固定的,所以γ的大小只受w的大小影响,因此可以通过调整w的大小使得γ = λ,因此,此时γ/λ = 1,求解出w
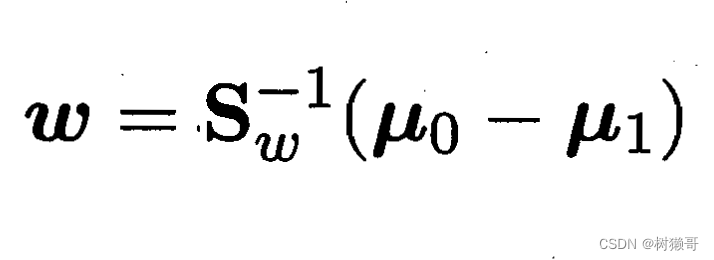
参考资料与文献
1、周志华. 机器学习[M]. 北京:清华大学出版社,2016.
2、谢文睿 秦州 贾彬彬 . 机器学习公式详解 第 2 版[M]. 人民邮电出版社,2023
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









