






目录
flink1.18以上需要 jdk11, 因此下载稍低的版本flink1.16.3 Downloads | Apache Flink
Flink有三种安装模式,本地模式, Standalone Cluster集群部署, Flink On Yarn。生产环境用on Yarn比较多,简单学习用本地模式即可。
解压安装
将文件放到/home/peng/software
tar -xvf flink-1.16.3-bin-scala_2.12.tgz 创建软链接
ln -s flink-1.16.3 flink启动本地集群
进入flink安装目录并启动本地集群
cd flink
./bin/start-cluster.sh
运行自带示例
使用自带的实例,快速部署作业到运行的集群上
./bin/flink run examples/streaming 查看运行结果
查看运行结果
(注意名字peng等 )
tail log/flink-*-taskexecutor-*.out我电脑是:
tail log/flink-peng-taskexecutor-0-ubuntu.out 
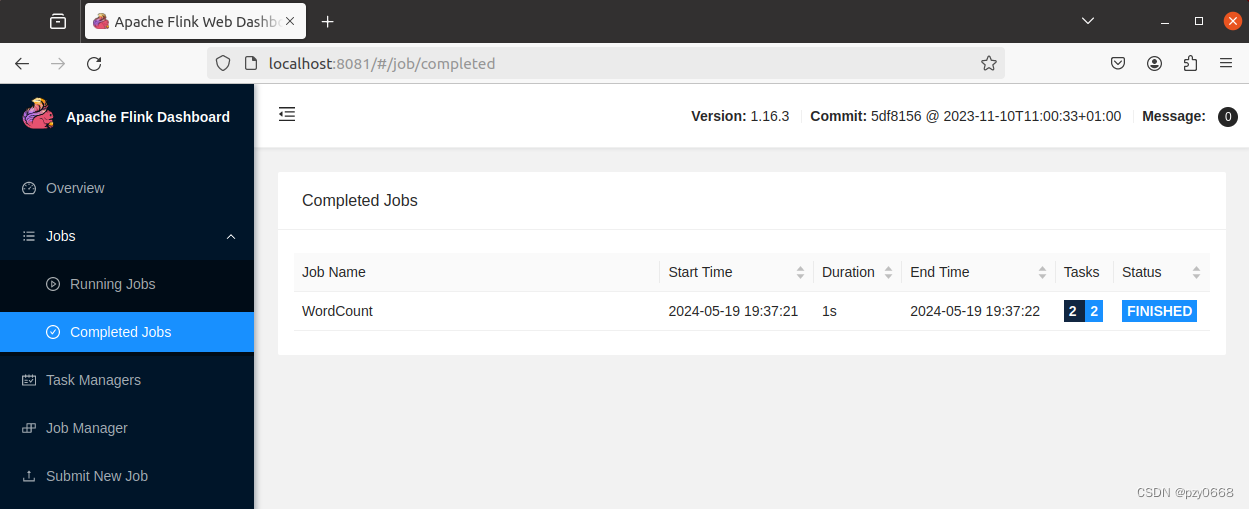
网页端查看作业状态
通过 Flink 的 Web UI 来监视集群的状态和正在运行的作业,localhost:8081查看
关闭集群
./bin/stop-cluster.sh注意参考自:本地模式安装 | Apache Flink















 861
861

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









