







0 概要
github链接: link
pycorrector: 中文文本纠错工具。支持中文音似、形似、语法错误纠正,python3开发。
常见错误类型:

1 名词
TODO
2 实现方法
可以归纳为两类方法:
2.1 语言模型(规则)
依据语言模型检测错别字位置,通过拼音音似特征、笔画五笔编辑距离特征及语言模型困惑度特征纠正错别字。
- 中文纠错分为两步走,第一步是错误检测,第二步是错误纠正;
- 错误检测部分先通过结巴中文分词器切词,由于句子中含有错别字,所以切词结果往往会有切分错误的情况,这样从字粒度和词粒度两方面检测错误, 整合这两种粒度的疑似错误结果,形成疑似错误位置候选集;
- 错误纠正部分,是遍历所有的疑似错误位置,并使用音似、形似词典替换错误位置的词,然后通过语言模型计算句子困惑度,对所有候选集结果比较并排序,得到最优纠正词。
2.2 深度学习模型
pycorrector实现了ConvSeq2Seq、BERT、MacBERT、ELECTRA、ERNIE、Transformer等多种模型的文本纠错,并在SigHAN数据集评估各模型的效果。
3 项目文件结构介绍
版本号:0.5.0
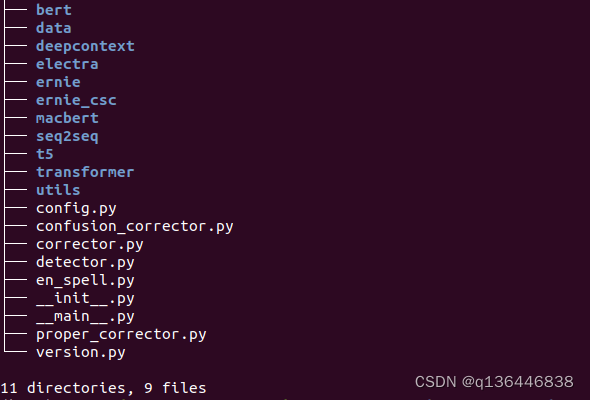
| 目录/文件名 | 内容 |
|---|---|
| bert | 存放bert模型相关代码 |
| data | 存放中英文分词用数据,和sighan2015 |
| deepcontext | |
| electra | 存放electra模型相关代码 |
| ernie | 存放ernie模型相关代码 |
| ernie_csc | 存放ernie_csc模型相关代码 |
| macbert | 存放macbert模型相关代码 |
| seq2seq | 存放Convseq2seq模型相关代码 |
| t5 | 存放t5模型相关代码 |
| transformer | 存放transformer模型相关代码 |
| utils | 文件夹工具方法存放 |
| config.py | 配置信息 |
| confusion_corrector.py | 混淆词纠正类 |
| corrector.py | 中文拼写检查子类(主要使用类) |
| detector.py | 中文拼写检查基类 |
| en_spell.py | 英文拼写检查 |
| __init__.py | 默认模型方法初始化接口 |
| __main__.py | 文本纠错命令行接口 |
| proper_corrector.py | 专用名词就错代码 |
| version.py | 版本号 |
4 备注
另有jcorrector( link)是其他人仿写pycorrector的java包。其中实现了规则方法和macbert。不过其中细节有修改。















 1806
1806











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









