









写在前面的话: 总结一下学到的内容,还有在做项目中遇到的问题及其解决方式。都是为了学习巩固,有什么不对的地方还希望各位大佬指正出来,不胜感激。
1. 将编码制内容转换成可读内容
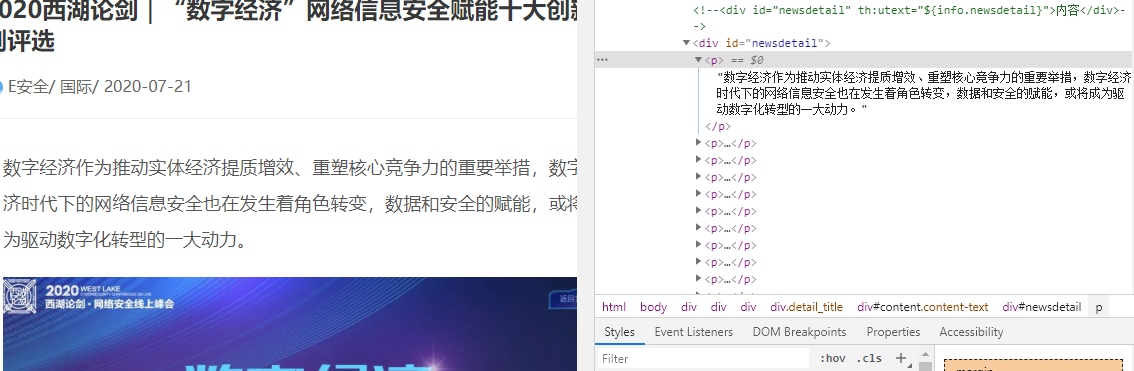

我们可以看到源码和网页审查元素不一样,正文实际上是在 js 代码中,那么可以通过正则获取再去进行解析。
from lxml import etree
import re
***
text = re.findall("<script>.*?var.*?content='(<p>.*?/p>)'.*?</script>", htmlstring, re.S|re.M)[0]
sub_html = etree.HTML(text)
contents = sub_html.xpath('//p//text()')
content = ' '.join(i.replace('\n', ' ').strip() for i in contents)
这样得到的内容仍然是编码制的,我们将其进行转换,其实这是unicode码,我们将其编码再解码即可。
content = content.encode('utf-8').decode("unicode-escape")
print(content)
2. json 追加模式去写入
要求是爬取的所有内容返回一个json,也就是所有网站存储到一个连接里,但是同时跑完存到一个列表里会有处理失败而中断的风险,所以追加是最好的方式,倒腾了几个小时才真正理解其用法,记录一下。
重点在于 json 要追加之前必须先 load 出来,才能 dump
- 里面有段代码是用来锁文件的,是因为在多线程以及多进程的处理下,单个文件存储必会发生安全问题,因此加入了文件锁,具体可查看相关内容 Python多进程操作同一个文件,文件锁问题,不过进程锁有没有用我还没尝试,而且
fcntl这个库只能在linux下使用。如果是对线程安全问题进行解决的话,可以直接用threading.Lock()去解决
def writeJson(urlpage, title, author):
"""每次返回的是经过处理的一个网站的url,作者,标题等等(删除了一些字段)"""
# 通过列表去存储数据,再存储为json格式
datas = []
data = {}
data['URLPAGE'] = urlpage
data['TITLE'] = title
data['AUTHOR'] = author
datas.append(data)
filename = 'datas.json' # 这个一般是通过程序获取,我随便定义了一个名字
# 判断是否为第一个存储的值,因为得保证每次打开文件获取到的内容是一个列表,而不是一个字典,如果没有理解这句话可以单步调试一下查看r变量
if os.path.isfile(filename) and os.path.getsize(filename) > 0:
f = open(filename, 'r', encoding='utf-8')
# fcntl.flock(f.fileno(), fcntl.LOCK_EX)
r = json.load(f)
f.close()
f = open(filename, 'w', encoding='utf-8')
# 添加内容
r.append(data)
json.dump(r, f)
f.close()
else:
f = open(filename, 'w', encoding='utf-8')
# fcntl.flock(f.fileno(), fcntl.LOCK_EX)
json.dump(datas, f)
f.close()
3. 繁体转简体
最好用的一个了,效果还佳
# 安装
# pip install opencc-python-reimplemented
# t2s - 繁体转简体(Traditional Chinese to Simplified Chinese)
# s2t - 简体转繁体(Simplified Chinese to Traditional Chinese)
# mix2t - 混合转繁体(Mixed to Traditional Chinese)
# mix2s - 混合转简体(Mixed to Simplified Chinese)
import opencc
cc = opencc.OpenCC('t2s')
s = cc.convert('*****') # 自己随便找一段
print(s)















 1563
1563

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









