







Spark on Yarn 参数调优-计算方式
1. 整理机器信息
机器数: 3台
# 查看物理CPU个数
cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l
或grep 'physical id' /proc/cpuinfo | sort -u | wc -l
每台机器核数:8核
# 查看每个物理CPU中core的个数(即核数)
cat /proc/cpuinfo| grep "cpu cores"| uniq
或者grep 'core id' /proc/cpuinfo | sort -u | wc -l
每台机器都是单核处理器
# 查看逻辑CPU的个数
cat /proc/cpuinfo| grep "processor"| wc -l
或者grep 'processor' /proc/cpuinfo | sort -u | wc -l
每台机器核数:8核
# 查看CPU信息(型号)
cat /proc/cpuinfo | grep name | cut -f2 -d: | uniq -c
查看结果:8 Intel(R) Xeon(R) CPU E5-2630 v4 @ 2.20GHz
# 内存自由状态信息
master : 22 当做20
worker1: 26 当做25
worker2: 26 当做25
Top命令 查看内存信息

Free -h命令 查看内存信息(人性化显示)
cdh-master

cdh-worker1

cdh-worker2

计算参考因素
2.1 Yarn ApplicationMaster(AM):
AM负责从ResourceManager申请资源,与NodeManager进行通信启动/停
止任务,监控资源的使用。在Yarn上执行Spark也要考虑AM所需资源(1G
和 1个Executor)。
2.2 HDFS Throughput:
HDFS Client有多个并发线程写的问题,HDFS每个Executor的使用5个任
务就可获取完全并发写。因此最好每个Executor的cores不高于5.
2.3 MemoryOverhead:spark.yarm.executor.memoryOverhead
下面图片展示 spark-yarn-memory-usage
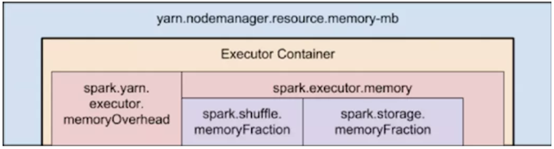
每个executor需要内存=
spark-executor-memory+spark.yarm.executor.memoryOverhead
spark.yarm.executor.memoryOverhead=Max(384m,7%*spark.executor.memory)
即大 于等于384M
如果我们为每个executor申请20GB资源,实际上AM获取的资源20GB+7%*20GB=~
23GB。
总结:该集群现有内存 核数 使用状态
核数:单台机器 8核 * 3 = 24 核数 core
内存:三台机器总可用内存 70g
计算:
4.1 最优化计算
每个executors设 5 cores,即 —executor-cores = 5(以达到 HFDS throughput有更好
的并发效果)
每个节点为Yarn daemons保留一个core,即每个节点可用cores为8-1=7个。
所以,集群当中可用的cores总数为 7*3=21核 当做20 core处理
Executors = 20/5 = 4
预留一个executor给AM, 则剩下3个executor —num-executors=3
每个节点的executor数= 3 / 3 = 1
每个节点的每个executor分配的内存= 20 / 1= 20GB
去除heap overhead=7%*20GB=2GB 所以,—executor-memory=20-2=18G 给16g
4.2 综合调整Yarn配置支持spark配置















 636
636











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









