







表的定义
如果说有什么数据结构是人人都能想到的,则非表结构莫属。
那么作为一个数据结构的表结构具有什么特征呢?
显然,一个表的本质也是一种数据访问方式:一种可以对标的任意位置进行访问的方式,根据这个思路,可以对表结构给出如下的定义/
表结构是一个某类型数据项组成的有穷序列,它支持下述操作:
(1) 创建一个空表;
(2) 判断一个表是否为空;
(3) 计算一个表中元素的个数;
(4) 清除表中所有元素;
(5) 在特定位置上插入一个元素;
(6) 将特定位置上的元素删除;
(7) 取出特定位置上的元素的值;
(8) 将特定位置上的元素予以替换;
(9) 遍历表里所有元素。
如果将这个定义与栈和队列的定义进行比较,可以发现他们的去区别确实只在数据的访问方式上。由于表结构要支持对任意位置数据的访问,所谓的位置概念就成为了表结构的一个重要概念。即表里面的每个元素有一个位置,只要给出这个位置,就可以对这个元素进行访问。而位置就是一个整数值。
| A | B | C | D | E | F | G | H | I | J |
(a) 一个表结构
| A | B | C | D | E | G | H | I | J |
|
(b)删除表结构中的元素F;
表的实现
与栈和队列一样,表的实现也可以分为连续和链接两种。通常情况下,连续存放的表结构称为线性表;链接实现方式的表结构称为链表。而连续实现的机制当然也是数组。而且,由于数组可以通过下标来对特定元素进行直接访问,数组就成为表的再现。事实上,从某种意义上说,数组就是表,比不过平时所见的数组所支持的操作不如表结构多而已。
下面是线性表的定义。
const int maxlist = 100; //表的最大尺寸 const int success =0; const int overflow = 1; const int underflow = 2; const int invalid_range = 3;typedef int listEntry; class list { public: list(void); int size() const; bool full() const; bool empty() const; void clear(); void traverse(void(*visit)(listEntry&)); int retrieve(int pos, listEntry &x) const; int replace(int pos, const listEntry &x); int remove(int pos); int insert(int pos, const listEntry &x); ~list(void); protected: int count; listEntry data[maxlist]; //使用数组来存放数据元素 };
int list::size() const //返回表结构里的元素个数
{
return count;
}
bool list::full() const
{
return (count == maxlist);
}
bool list::empty() const
{
return (count == 0);
}
void list::clear()
{
for (int i = 0; i <= count - 1; i++)
data[i] = 0;
}
int list::insert(int position, const listEntry &x) //在表位置position上插入元素x
{
if (full())
return overflow;
if (position<0 || position>count)
return invalid_range;
for (int i = count - 1; i >= position; i--)
data[position] = x;
count++;
return success;
}
int list::retrieve(int position, listEntry &x) const//取出表位置position上的元素
{
if (empty())
return underflow;
if (position<0 || position>count)
return invalid_range;
x = data[position];
return success;
}
int list::remove(int position)//删除表位置position上的元素
{
if (empty())
return underflow;
if (position<0 || position>count)
return invalid_range;
for (int i = position; i <= count - 1; i++)
data[i] = data[i + 1];
count--;
return success;
}
int list::replace(int position, const listEntry&x)//用x替换表位置position上的元素
{
if (empty())
return underflow;
if (position<0 || position>count)
return invalid_range;
for (int i = position; i <= count - 1; i++)
data[position] = x;
return success;
}
void list::traverse(void(*visit)(listEntry &))//遍历表里所有元素
{
for (int i = 0; i < count; i++)
(*visit)(data[i]);
}
list::list(void)
{
count = 0;
}
list::~list(void)
{
}链表——链接实现的表结构
const int success = 0;
const int overflow = 1;
const int underflow = 2;
const int invalid_range = 3;
typedef int nodeEntry;
using namespace std;
struct node //链表的节点定义
{
//数据成员
nodeEntry entry;
node *next;
};
class list
{
public:
list(void);
int size() const;
bool full() const;
bool empty() const;
void clear();
void traverse(void(*visit)(node&));
int retrieve(int pos, node &x) const;
int replace(int pos, const node &x);
int remove(int pos);
int insert(int pos, const node &x);
//为表结构增加的操作符重载及构析函数
~list(void);
list(const list ©);
void operator = (const list ©);
protected:
int count;
node *head;
node *setPosition(int position) const; //辅助函数,用来设置表结构里面的位置
};
这里的数据成员与线性表里的数据成员有一个不同:删除了数据成员,增加了head,它是指向Node的一个指针,而Node的结构就是连接结构的一个节点。
|
|
|
|
|
| 链表 |
node *list::setPosition(int position)const //返回指向处于position位置上的节点的指针
{
node *q = head;
if (position > 1)
for (int i = 1; i < position; i++)
q = q->next;
return q;
}显然,如果0到count之间的任意整数被作为setPosition函数的参数position的概率相同,则setPosition函数的执行时间成本与表中数据项个数成正比,即O(n)。
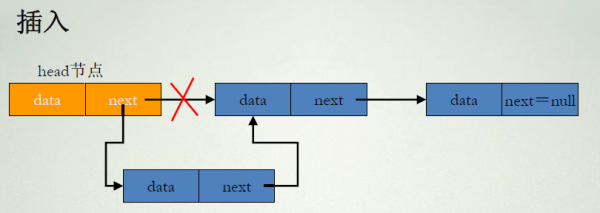
int list::insert(int position, node *x)//将元素插入位置position上
{
if (position < 1)
{
cout << "位置不在合法范围内。" << endl;
return invalid_range;
}
node *previous, *following;
if (position > 1)
{
previous = setPosition(position - 1);
following = previous->next;
}
else
following = head;
if (position == 1)
head = x;
else
{
previous->next = x;
x->next = following;
}
count++;
return success;
}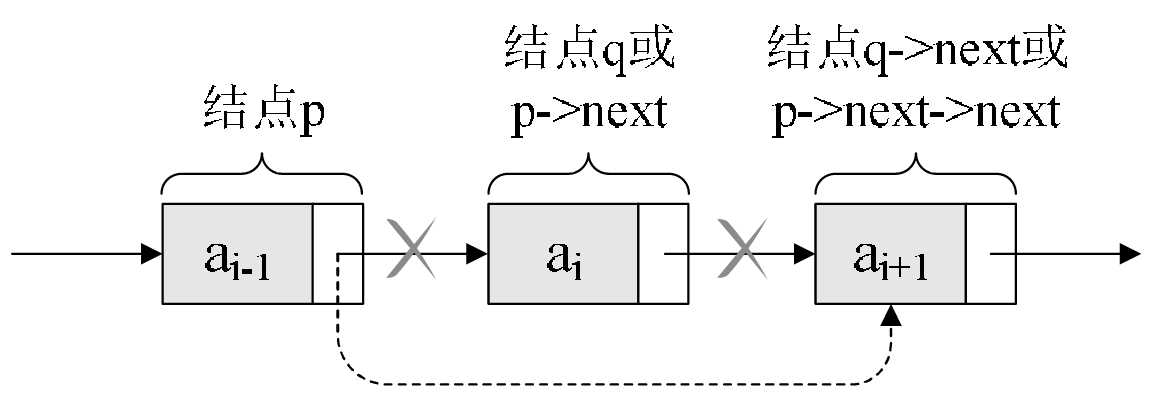
在链表中进行删除比插入还要简单,只需要将待删除节点的前驱结点指向带删除节点的后继节点即可,如上图。但是味蕾不产生内存泄露,需要将从链表中移除的节点释放。
删除函数的程序实现如下。
int list::remove(int position)//将位置position上的元素删除
{
if (position<1 || position>count)
{
cout << "位置不在合法范围内。" << endl;
return invalid_range;
}
node *previous, *following;
if (position > 1)
{
previous = setPosition(position - 1);
if (position < count - 1)
following = setPosition(position + 1);
else
following = NULL;
}
else
{
previous = head;
if (position < count - 1)
following = setPosition(position + 1);
else
following = NULL;
}
previous->next = following;
count--;
return success;
}
链表中的其他函数的实现也比较简单,如下所示。
int list::size() const //返回表结构中的元素的个数
{
return count;
}
bool list::empty() const
{
return (count == 0);
}
void list::clear()
{
node *old_node;
while (head != NULL)
{
old_node = head;
head = head->next;
delete old_node;
}
}
int list::retrieve(int position, node *x) const //取出表位置position上的元素
{
node *temp;
if (empty())
return underflow;
if (position<1 || position>count)
{
cout << "位置不在合法范围内。" << endl;
return invalid_range;
}
temp = setPosition(position);
x->entry = temp->entry;
return success;
}
int list::replace(int position, const node *x) //用x替代表位置position上的元素
{
if (empty())
return underflow;
if (position<1 || position>count)
{
cout << "位置不在合法范围内。" << endl;
return invalid_range;
}
node *to_replace;
to_replace = setPosition(position);
to_replace->entry = x->entry;
return success;
}
list::list(void)
{
count = 0;
head = NULL;
}
list::~list(void)
{
}从前面实现的插入和删除操作的程序可以很容易发现,操作的成本取决于setPosition函数,而其时间复杂度为O(n),所以我们还可以进一步的优化setPosition函数操作的效率。
也就是记住当前的位置,那么下次定位就不是从头开始,而是从上次开始了。要记住当前位置,只需要堆链表类进行席位修改即可。即增加一个数据成员current,用来记录本次操作所处的位置(指向本次操作的节点),然后修改setPosition函数使其每次定位从current开始。不过需要注意的是,由于需要在必要的时候修改current,该数据成员需要被定义为一个可被修改的项。C++提供了一个mutable qualifier来让我们实现这个目的。
下面为被修改后的链表结构的类定义。
class list
{
public:
list(void);
int size() const;
bool full() const;
bool empty() const;
void clear();
void traverse(void(*visit)(node&));
int retrieve(int pos, node &x) const;
int replace(int pos, const node &x);
int remove(int pos);
int insert(int pos, const node &x);
//为表结构增加的操作符重载及构析函数
~list(void);
list(const list ©);
void operator = (const list ©);
protected:
int count;
node *head;
mutable int currentPosition;
mutable node *current;
void setPosition(int position) const;
};注意,这里将所有的新成员都定义为protected。这是因为要将这种链表包装得与正常的链表完全一样,这样用户在原来链表上写的程序在这个新的类下仍然适用。而因为 有了这个新数据成员currentPosition,setPosition函数就无需返回指向某个节点的指针,而只需重新设定currentPosition即可。新的setPosition函数实现如下。
void list::setPosition(int position) const //新的setPosition函数实现
{
if (position < currentPosition)
{
currentPosition = 0;
current = head;
}
for (; currentPosition != position; currentPosition++)
current = current->next;
}双链表
#include<string>
const int SUCCESS = 0;
//const int OVERFLOW = 1;
//const int UNDERFLOW = 2;
const int INVALID_RANGE = 3;
//const int NULL = 0;
typedef char nodeEntry;
struct node
{
nodeEntry entry[20];
node * next;
node * back;
};
class duLinkList
{
public:
duLinkList();
~duLinkList();
int size()const;
bool empty()const;
void clear();
void traverse(void(*visit)(node &));
int retrieve(int pos, node * x)const;
int replace(int pos, const node * x);
int remove(int pos);
int insert(int pos, node * x);
protected:
int count;
mutable int currentPosition;
mutable node * current;
void setPosition(int position)const;
};
void duLinkList::setPosition(int position)const //新的setPosition函数
{
if (position < currentPosition) //反向查找
for (; currentPosition != position; --currentPosition)
current = current -> back;
if (position > currentPosition) //正向查找
for (; currentPosition != position; ++currentPosition)
current = current->next;
}
int duLinkList::insert(int position, node *x)
{
node * new_node, *following, *preceding;
if (position < 1)
return INVALID_RANGE;
if (position == 1)
{
if (count == 0)
following = NULL;
else
{
setPosition(position);
following = current;
}
preceding = NULL;
}
else
{
setPosition(position - 1);
preceding = current;
following = preceding->next;
}
new_node = new node;
if (new_node == NULL)
return OVERFLOW;
strcpy(new_node->entry, x->entry);
new_node->back = preceding;
new_node->next = following;
if (preceding != NULL)
preceding->next = new_node;
if (following != NULL)
following->back = new_node;
current = new_node;
currentPosition = position;
++count;
return SUCCESS;
}
int duLinkList::remove(int position)
{
if (position < 1)
return UNDERFLOW;
if (position > count)
return OVERFLOW;
node * preceding, *follwing;
if (position > 1)
{
setPosition(position - 1);
preceding = current;
if (position < count - 1)
{
setPosition(position - 1);
follwing = current;
}
else
follwing = NULL;
}
else
{
while (currentPosition != 1)
{
--currentPosition;
current = current->back;
}
preceding = current;
if (position < count - 1)
{
setPosition(position + 1);
follwing = current;
}
else
{
follwing = NULL;
}
}
preceding->next = follwing;
--count;
return SUCCESS;
}
int duLinkList::replace(int position, const node * x)
{
if (empty())
return UNDERFLOW;
if (position<1 || position>count)
return INVALID_RANGE;
setPosition(position);
strcpy(current->entry, x->entry);
return SUCCESS;
}
duLinkList::duLinkList()
{
count = 0;
current = NULL;
currentPosition = 1;
}
duLinkList::~duLinkList()
{
}
int duLinkList::size()const
{
return count;
}
bool duLinkList::empty()const
{
return (count == 0);
}
void duLinkList::clear()
{
node * old_node;
setPosition(1);
while (current != NULL)
{
old_node = current;
current = current->next;
delete old_node;
}
}
int duLinkList::retrieve(int position, node * x)const
{
if (empty())
return UNDERFLOW;
if (position<1 || position>count)
return INVALID_RANGE;
setPosition(position);
strcpy(x->entry, current->entry);
return SUCCESS;
}显然,双链表的节点定位时间成本只有单链表的一半^.^















 1921
1921











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









