






大数据OLAP常用的技术
大规模并行处理:
可以通过增加机器的方式来扩容处理速度,
在相同的时间里处理更多的数据。列式存储:
通过按列存储提高单位时间里数据的I/O吞吐率,
还能跳过不需要访问的列。索引:
利用索引配合查询条件,
可以迅速跳过不符合条件的数据块,
仅扫描需要扫描的数据内容。压缩:
压缩数据然后存储,
使得存储的密度更高,
在有限的I/O速率下,在单位时间里读取更多的记录。
以上是在大数据处理方面常用的四种技术原理,
上面这些处理数据的方式极大程度的提高了单位时间内数据处理的能力,
但是其还是没有摆脱数据量和查询时间的线性关系。
于是在OLAP处理方式上,
我们多了一种:
- 维度聚合,预计算
该方式是通过预先组合好的维度,
来离线预计算需要处理的数据,
这样就可以实现在实时查询的实时响应,
并且数据量只和组合的维度有关系,
而不再受限于数据的体量。
但是该方式也有其自身的劣势,
那就是不够灵活,
超出预计算的维度将无法再被实时响应。
目前还没有一个OLAP系统能够满足各种场景的查询需求。
其本质原因是,
没有一个系统能同时在数据量、性能、和灵活性三个方面做到完美,
每个系统在设计时都需要在这三者间做出取舍。
这个就有点像我们的CAP理论了~~~

- 数据组织方式
传统OLAP根据数据存储组织方式的不同分为
ROLAP(relational olap)以及 MOLAP(multi-dimension olap)- ROLAP 以关系模型的方式存储用作多维分析用的数据,
优点在于存储体积小,查询方式灵活,
然而缺点也显而易见,每次查询都需要对数据进行聚合计算,
为了改善短板,ROLAP使用了列存、并行查询、查询优化、位图索引等技术。 - MOLAP 将分析用的数据物理上存储为多维数组的形式,
形成CUBE结构。维度的属性值映射成多维数组的下标或者下标范围,
事实以多维数组的值存储在数组单元中,优势是查询快速,
缺点是数据量不容易控制,可能会出现维度爆炸的问题。
- ROLAP 以关系模型的方式存储用作多维分析用的数据,
目前市面上常用的OLAP框架
-
基于MPP (Massively Parallel Processing) 和 ROLAP
Presto
Presto 是由 Facebook 开源的大数据分布式 SQL 查询引擎,
适用于交互式分析查询,可支持众多的数据源,包括 HDFS,RDBMS,KAFKA 等,
而且提供了非常友好的接口开发数据源连接器。
Presto支持标准的ANSI SQL,
包括复杂查询、聚合(aggregation)、连接(join)和窗口函数(window functions)。
Presto 本身并不存储数据,但是可以接入多种数据源,
并且支持跨数据源的级联查询。clickHouse
ClickHouse是一个开源的面向列基于MPP的数据库管理系统,
能够使用SQL 查询实时生成分析数据报告。Impala
Impala也是一个SQL on Hadoop的查询工具,
底层采用MPP技术,支持快速交互式SQL查询。
与Hive共享元数据存储。SparkSQL
SparkSQL的前身是Shark,
它将 SQL 查询与 Spark 程序无缝集成,
可以将结构化数据作为 Spark 的 RDD 进行查询。
SparkSQL作为Spark生态的一员继续发展,
而不再受限于Hive,只是兼容Hive。HAWQ
Hawq是一个Hadoop原生大规模并行SQL分析引擎,
Hawq采用 MPP 架构,
改进了针对 Hadoop 的基于成本的查询优化器。
除了能高效处理本身的内部数据,
还可通过 PXF 访问 HDFS、Hive、HBase、JSON 等外部数据源。-
Greenplum
Greenplum是一个开源的大规模并行数据分析引擎。
借助MPP架构,在大型数据集上执行复杂SQL分析的速度比很多解决方案都要快。
GPDB完全支持ANSI SQL 2008标准和SQL OLAP 2003 扩展;
从应用编程接口上讲,它支持ODBC和JDBC。
完善的标准支持使得系统开发、维护和管理都大为方便。
支持分布式事务,支持ACID。
保证数据的强一致性。
做为分布式数据库,拥有良好的线性扩展能力。
GPDB有完善的生态系统,可以与很多企业级产品集成,
譬如SAS,Cognos,Informatic,Tableau等;
也可以很多种开源软件集成,譬如Pentaho,Talend 等。Greenplum基于Postgresql
-
基于预计算的 和 MOLAP
kylin
Kylin自身就是一个MOLAP系统,
多维立方体(MOLAP Cube)的设计,
使得用户能够在Kylin里为百亿以上数据集定义数据模型,
并构建立方体进行数据的预聚合。
并提供ANSI-SQL接口交互式查询能力-
Druid
Druid 是一种能对历史和实时数据提供亚秒级别的查询的数据存储。
Druid 支持低延时的数据摄取,灵活的数据探索分析,
高性能的数据聚合,简便的水平扩展。
适用于数据量大,可扩展能力要求高的分析型查询系统。
Druid解决的问题包括:数据的快速摄入和数据的快速查询。Druid保证数据实时写入,但查询上对SQL支持的不够完善
- MPP 和 预计算的 方式差异:
MPP非常灵活,
其数据是基于数据表的分析,
支持数据实时导入实时分析,
并且可以查询任意想要查询的数据。
但是其缺点也很明显,
内存资源需求大,
MPP的OLAP一般都是基于内存的,
所以对于机器内存要求很大,
对于过大的数据量,会极大的影响性能.
基于预计算的方式,
则略微显得不太灵活,
无法查询预计算外的数据,
但是其优点是相对稳定,
数据量的增大不会对查询速度造成很大的影响,
其需要的存储空间也不会随着数据量增大而膨胀。

OLAP测评报告
前两份主要是针对基于MPP方式的OLAP框架的测评,
HAWQ、Presto、ClickHouse
HAWQ 性能大部分情况下是低于 Presto和 ClickHouse,
而Presto的速度比较依赖网络,因为其本身并不具备存储数据的功能,
ClickHouse目前是MPP速度最快的引擎,不过其在多表查询上性能也并不好。-
Hive Hawq、Presto、Impala、Sparksql、Clickhouse、Greenplum
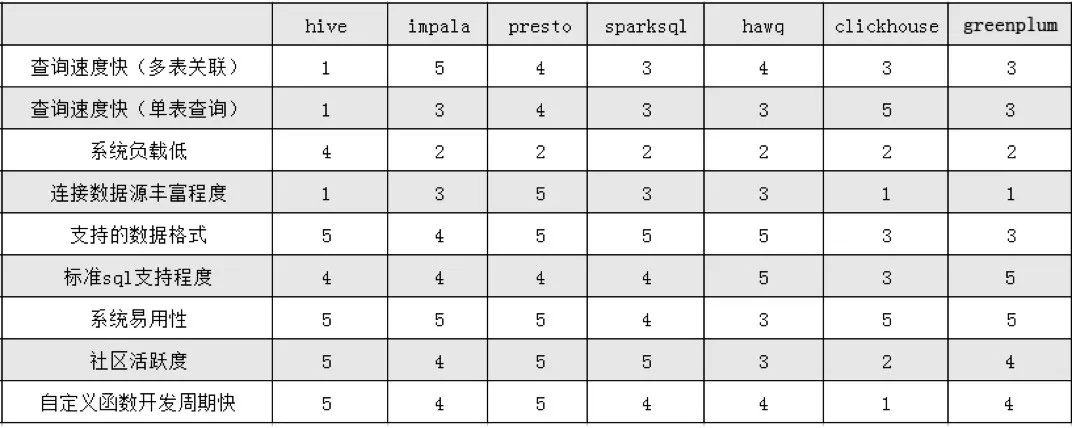 image.png
image.png
-
kylin presto druid
这是美团16年初的报告,
时间比较久远,
不具备太大的参考意义,不过大致也表明 kylin和druid 在速度响应上是要更快的。
而Kylin提供了更加完善的功能和SQL支持,
Druid则提供了数据实时摄入,
二者在查询性能上基本是一个量级
 image.png
image.png
总结
MPP虽然看起来是更好的选择,
但是因为其是基于内存计算的,
会相对的比较不太稳定,
比如遇到数据倾斜导致内存崩溃,
又比如数据量的大小改变,
和查询语句的不同,
都可能导致查询时间的起伏,
也许很快,但也可能会出现半天出不来数据的情况
预计算则相对的放弃了灵活的查询,
但是却节省了大量的内存计算带来的开销,
而且因为是属于预计算范畴,
对于不支持的数据那就是不支持,
但是对于支持的查询则是可以达到一个比较稳定的查询速度,
对于稳定的天级任务,
我们完全可以使用预计算的方式,
而对于一些类似偶尔的临时任务,
那么可以通过MPP的方式进行导出,
没有必要为了一些特殊的需求而加大机器资源的开销。
而在基于预计算的框架,
我更趋向于kylin,
因为他可以更好的管理数据,
具有更好的SQL支持,
并且其社区在国内比较活跃,
然后有中文文档~~~~~
还有一点就是,现在很多培训机构已经把kylin拉上课程安排了....















 2078
2078











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









