







二叉树
定义
- 一个空节点是二叉树(即什么都没有)
- 一棵二叉树有一个根节点,可以有左、右子树,而子树本身也是二叉树
遍历
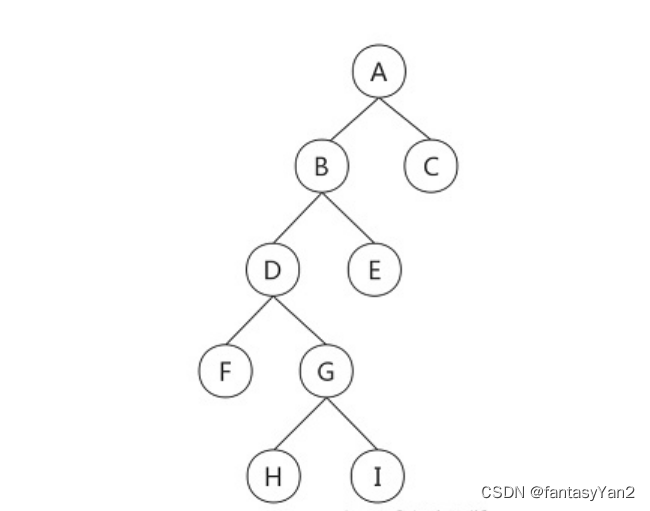
前序遍历
先遍历根节点,再遍历左子树,再遍历右子树即:
A-B-D-F-G-H-I-E-C
中序遍历
先遍左子树,再遍历根节点,再遍历右子树:
A-B-D-F-G-H-I-E-C
后序遍历
先遍左子树,再遍历右子树,再遍历根节点:
F-H-I-G-D-E-B-C-A
层序遍历
一层一层的遍历:
A-B-C-D-E-F-G-H-I
遍历代码
public class Node {
private String data;
private Node leftNode;
private Node rightNode;
public Node(String data,Node leftNode,Node rightNode){
this.data = data;
this.leftNode = leftNode;
this.rightNode = rightNode;
}
public String getData(){
return this.data;
}
public Node getLeftNode(){
return this.leftNode;
}
public Node getRightNode(){
return this.rightNode;
}
}
import java.util.Queue;
import java.util.concurrent.LinkedBlockingQueue;
public class TraverseTool {
//前序遍历
public void preTraverse(Node node){
System.out.print(node.getData());
if(node.getLeftNode() != null){
preTraverse(node.getLeftNode());
}
if(node.getRightNode() != null){
preTraverse(node.getRightNode());
}
}
//中序遍历
public void midTraverse(Node node){
if(node.getLeftNode() != null){
midTraverse(node.getLeftNode());
}
System.out.print(node.getData());
if(node.getRightNode() != null){
midTraverse(node.getRightNode());
}
}
//后续遍历
public void postTraverse(Node node){
if(node.getLeftNode() != null){
postTraverse(node.getLeftNode());
}
if(node.getRightNode() != null){
postTraverse(node.getRightNode());
}
System.out.print(node.getData());
}
//层序遍历,利用队列先进先出的功能,每一次都先遍历上一层的子节点
public void seqTraverse(Node node){
Queue<Node> queue = new LinkedBlockingQueue<>();
queue.add(node);
Node nextNode;
while (!queue.isEmpty()){
nextNode = queue.remove();
if(nextNode.getLeftNode() !=null){
queue.add(nextNode.getLeftNode());
}
if(nextNode.getRightNode() !=null){
queue.add(nextNode.getRightNode());
}
System.out.print(nextNode.getData());
}
}
}
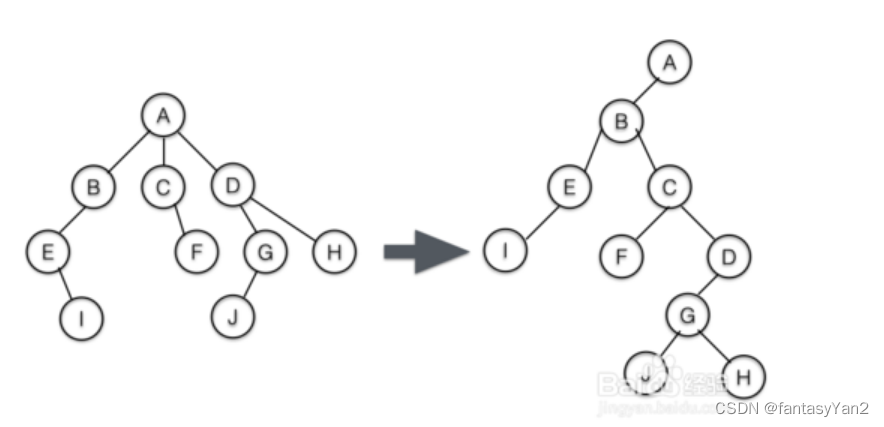
把任意树转化为二叉树
用以下方法可以将任意树转化成二叉树,且可以恢复到之前的树
- 对每一个节点,将其的第一棵子树变为左子树,如图中的B
- 将上述产生的左子树节点右边的兄弟树变为该左子树节点的右子树如C,D
平衡二叉树AVL
定义
任意节点左右子树高度差不超过1的二叉树
插入
参考:https://jarvan.blog.csdn.net/article/details/112428036
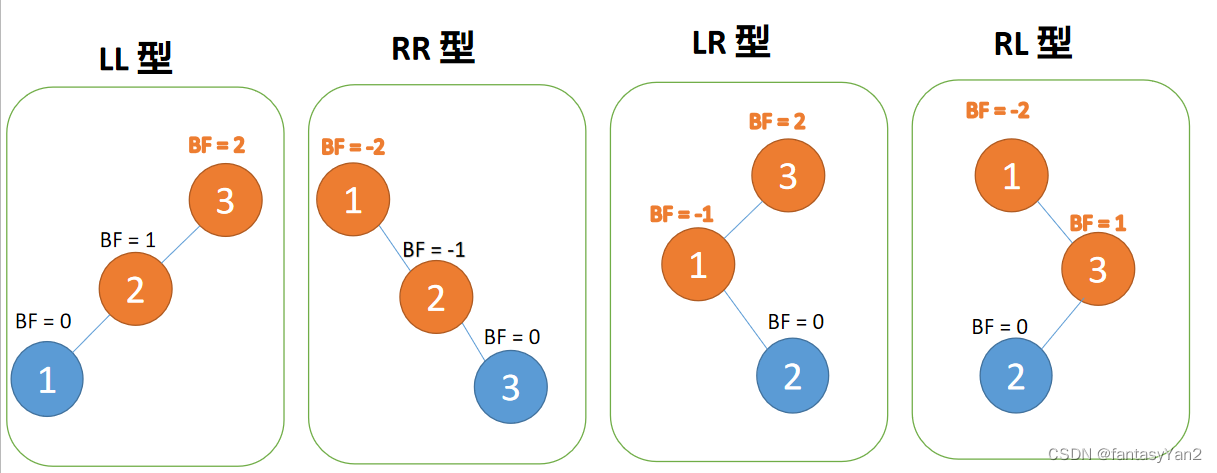
插入可以分为4中情况即:
LL 型:插入左孩子的左子树,右旋
RR 型:插入右孩子的右子树,左旋
LR 型:插入左孩子的右子树,先左旋,再右旋
RL 型:插入右孩子的左子树,先右旋,再左旋
删除
参考:https://zhuanlan.zhihu.com/p/454080520
思路
如果删除节点为叶子节点,直接删除;
如果删除节点为非叶节点,左子树较高则用前驱节点(左子树中最大的节点)替换删除节点;右子树较高则用后继节点(右子树中最小的节点)替换删除节点;
回溯,更新高度并恢复平衡性质。
简单列子
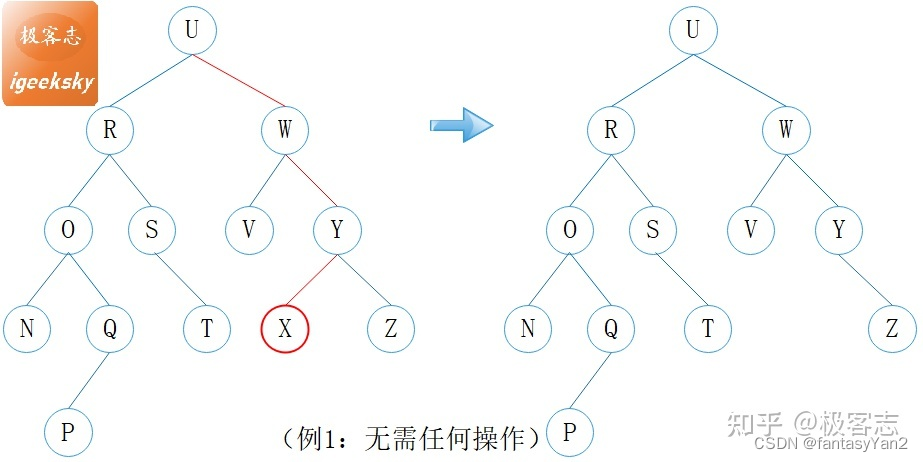
如例1,X 为叶子节点,直接删除。删除节点 X 之后,Y 的高度不变,且 Y 仍处于平衡状态,因此无需任何其它操作。

如例2,R 为非叶子节点,R 的左子树较高,找到其前驱节点 Q,然后用 Q 替换 R。替换之后,O, Q, U 的高度都需要更新。
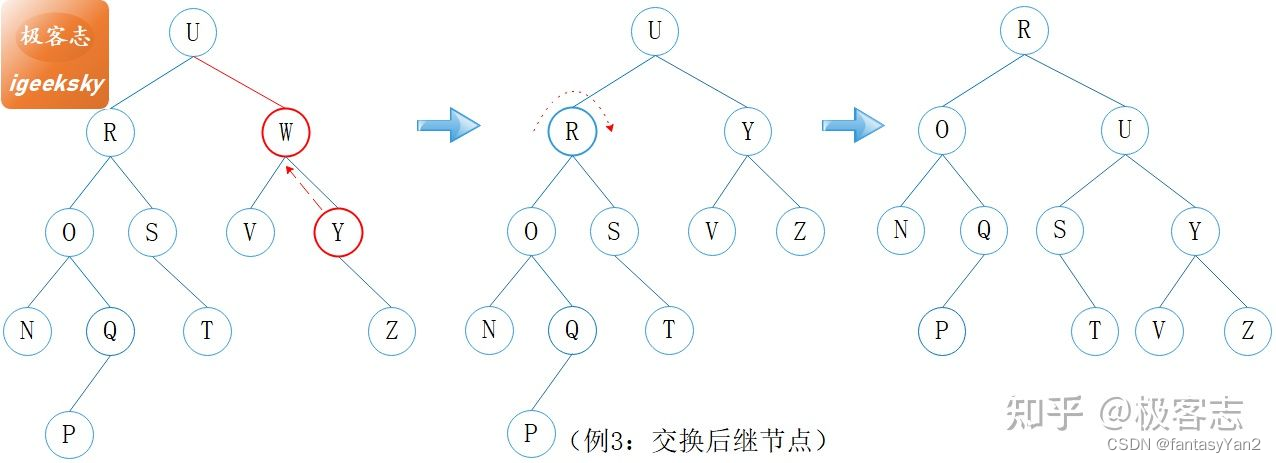
如例3,W 为非叶子节点,W 的右子树较高,找到其后继结点 Y,然后用 Y 替换 W。替换之后,U 处于不平衡状态,旋转恢复平衡。
调整平衡最坏情况
删除一个节点后,最坏情况下需要logN次旋转才能重新平衡。如:
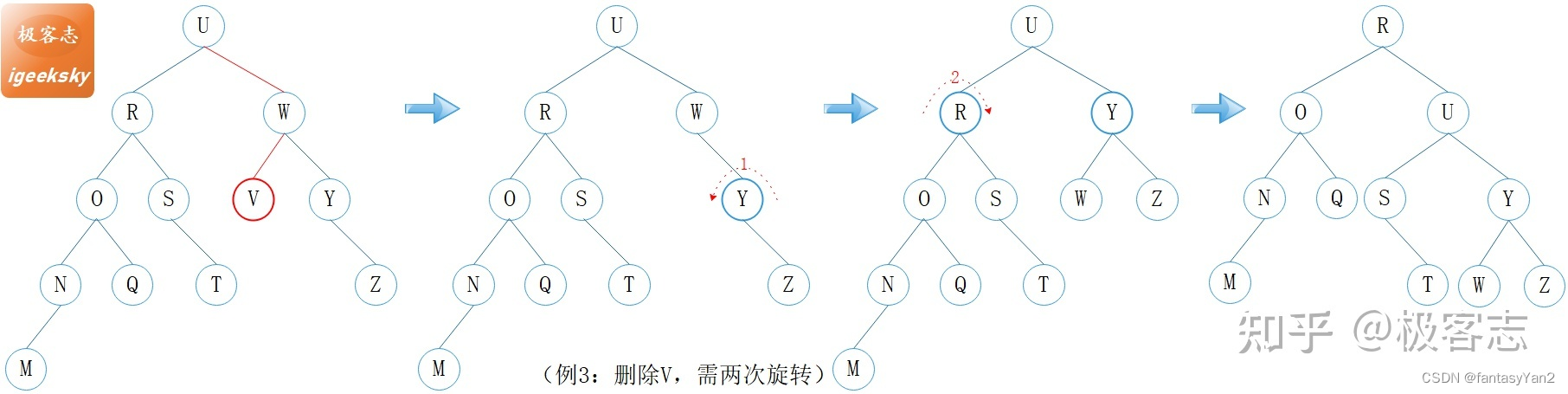
如例 3 所示:
W 的初始平衡因子为 -1,U 的平衡因子为 +1;
当删除 V 之后,W 的平衡因子变为 -2,触发第1次旋转;
第 1 次旋转完成之后,U 的平衡因子变为 2,触发第2次旋转。
我们可以用一个比较抽象的方式来表示这个规律:
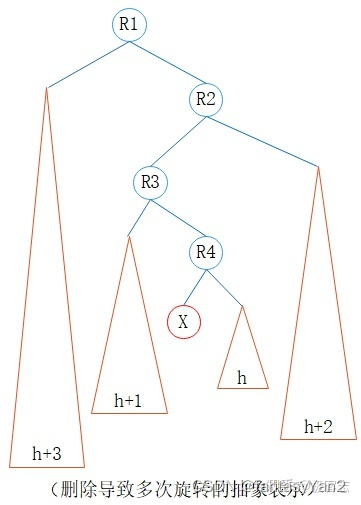
删除节点 X 之后,R4的平衡因子变为 -2,R4 左旋;R3 的平衡因子变为 2,R3 右旋;R2 的平衡因子变为 -2, R2左旋;R1的平衡因子变为2,R1 右旋……
当从根节点至待删除节点的父节点平衡因子交替为 -1 和 +1,删除该节点一旦触发旋转就需要logn次旋转 (回溯至根节点)。
红黑树
定义
其实就是在平衡二叉树的基础上加入了红色与黑色的节点概念,满足以下要求的树:
1、节点颜色必须是红色或者黑色
2、根节点是黑色
3、每个叶子节点(NIL节点、空节点)是黑色的
4、每个红色节点的两个子节点都是黑色
5、从任一节点到每个叶子的所有路径都包含数目相同的黑色节点
插入
参考:https://blog.csdn.net/Lyt15829797751/article/details/81054920

上图就是一颗红黑树,所有的空节点都指向最后这个黑色节点,称它为哨兵节点,从根节点沿任一路径出发到达哨兵节点,路径上的黑色节点总数是相同的。
了解完红黑树的基本性质,我们就开始插入数据,为了防止违反性质5,所以我们插入的数据都是为红色。
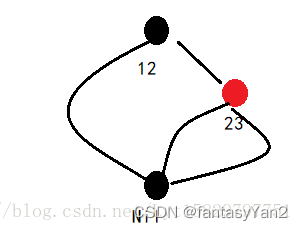
假设我们插入这些数据:12 23 34 40 45 67 78 89 90 100 110 120 130 140
1、插入12,12为根节点,根节点一定为黑;插入23,符合红黑树的基本性质,无需做出调整
2、插入45
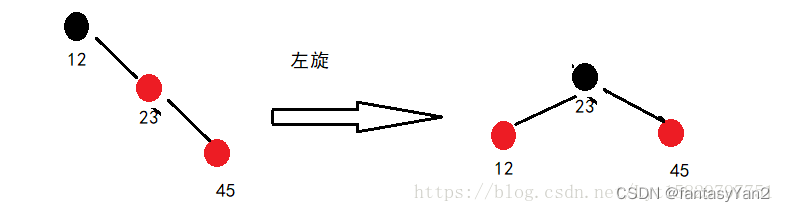
3、插入34

插入34,不满足红色节点一定有两个黑色子节点,所以将34的父节点和叔叔节点 涂成 黑色,祖父节点变成红色,但23是根,必须为黑色,所以如上图所示 23,12,45节点颜色为黑色
4、插入40
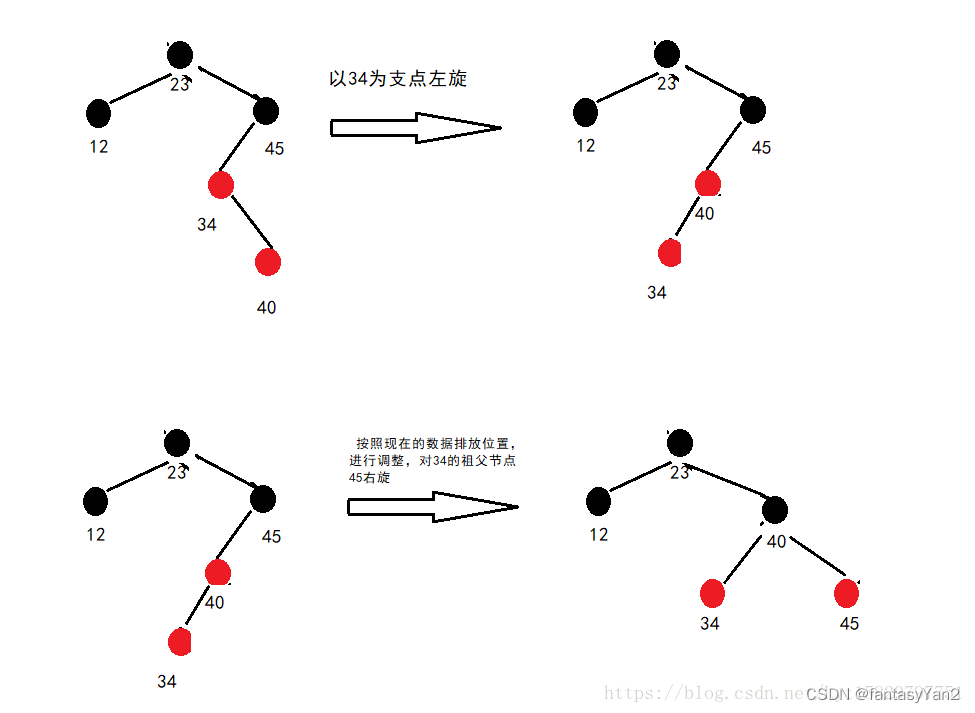
删除
与平衡二叉树的删除情况类似,只是在这个基础上需要:1. 每个红色节点的两个子节点都是黑色 2.计算是否失衡时只需考虑黑色的节点,具体的删除情况可以参考:https://blog.csdn.net/weixin_45960212/article/details/124443730
红黑树与平衡二叉树AVL的比较
- 查询效率avl比红黑树高,avl的查询效率是logN,红黑树的最坏查询效率为2logN(在节点和子节点都是一黑一红的情况下),也就是avl的2倍
- 红黑树的插入效率和删除效率要比avl高:
插入节点快的原因为,每次插入时的默认颜色为红色,对于avl左右子树相差为1的情况,此时需要旋转才能保持平衡,而对于红黑树而言如果插入节点的父节点为黑色可以不用做旋转。因为只会去计算深度时只计算黑色节点。
删除节点快的原因为:类似插入的情况,因为在计算深度时只计算黑色节点,所以对于红黑树而言他不会像平衡二叉树一样,最坏情况下,会出现需要旋转logN次的情况。
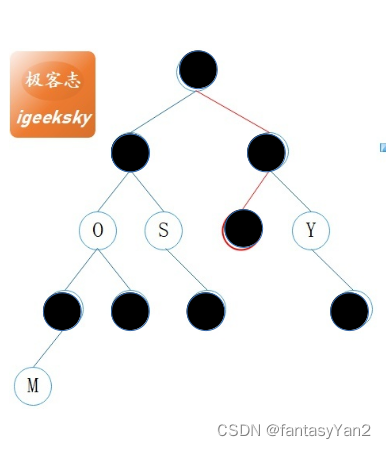
举个例子:
在上图中avl需要旋转两次,而如果是下面的红黑树,就只需要一次:
HashMap中红黑树的应用
HashMap使用了哈希算法,两个不同的 key 计算出来的哈希值有可能被分配到同一个位置,那就会在对应的位置使用链表管理。有的时候这样的数量比较多,所以此时的查询一个 key 的过程会变成了,先计算 key 的哈希值,然后发现这个值对应的位置是一条链表,然后再遍历这个链表,直到找到(或者找不到)对应的 key。这样一来,如果冲突很多的话,多了这个遍历链表的过程,查询效率就降低了,所以在 JDK1.8 之后引入了一个优化,如果这个冲突的链表比较多的话(多于 8 个),就把这个链表转换成红黑树.
B树
定义
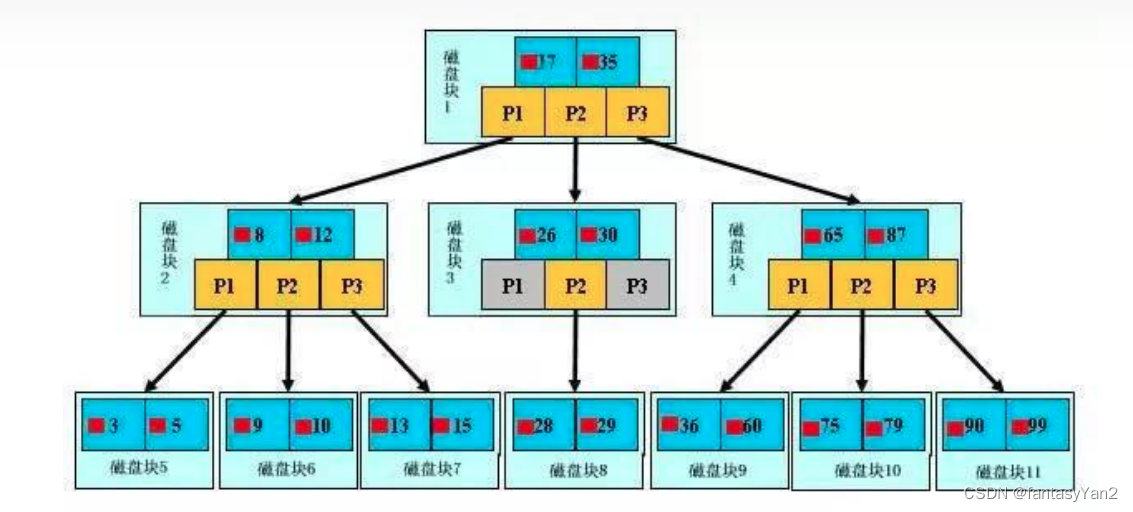
- b树是一种受限的n叉树
- b树的非叶子节点限制在d和2d之间。那么子节点就是d+1到2d+1之间
- 根节点要有2到2d个子节点
- 每个节点中,第一个子节点下面的所有键都要小于这个节点的第一个键;第二个子节点的所有键,在第一和第二个节点之间,以此类推,最后一个子节点的所有键,都大于最后一个键
插入与删除数据
插入如果被插入的节点数量大于2d就分裂成2个节点,删除时小于d就需要合并
B+树
定义
b+树其实是对b树的进一步改进,改进主要有以下2点:
- 所有非叶子节点只保留键,所有内容都必须保留在叶子节点里
- 用一个指针将所有叶子节点从头到尾连起来

mysql为什么要用B+树
- 因为相比二叉树b+树可以减少查询的层级。且可以控制每个节点子节点的数量,让查询频繁或者数量比较多的数据多一些子节点,已减少查询的不平衡。
- 相比与B树,B+树节点存的是键值(以及指向下一级的指针),更干净,占用空间少。子节点从头到尾相连,查询between之类的范围数据效率会很高















 339
339











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









