




 本文深入探讨了Java中的Set接口,包括HashSet和TreeSet的特性,以及Map接口的使用,如HashMap、Hashtable和Properties。HashSet是非线程安全、无序且不可重复的,而TreeSet则额外提供了自动排序功能。Map接口以键值对形式存储元素,HashMap和Hashtable是其常见实现,Properties则用于存储配置信息。TreeMap基于二叉树,保证了元素排序。
本文深入探讨了Java中的Set接口,包括HashSet和TreeSet的特性,以及Map接口的使用,如HashMap、Hashtable和Properties。HashSet是非线程安全、无序且不可重复的,而TreeSet则额外提供了自动排序功能。Map接口以键值对形式存储元素,HashMap和Hashtable是其常见实现,Properties则用于存储配置信息。TreeMap基于二叉树,保证了元素排序。
关于java.util.Set接口(单个方式存储元素)
一、HashSet集合
- HashSet集合是非线程安全的。
- HashSet集合存储元素的特点:无序不可重复。
——无序:存进去的顺序和取出来的顺序不一定相同。
——不可重复:存进去一个1,不能再存进去一个1。- 放到HashSet集合中的元素实际上是放到HashMap集合中的key部分,底层是哈希表。
二、TreeSet集合
- TreeSet集合存储元素的特点:无序不可重复的,储存的元素是可以自动按照大小顺序排序的。
——无序:存进去的顺序和取出来的顺序不一定相同。
——不可重复:存进去一个1,不能再存进去一个1。
——可排序:储存的元素可以自动按照大小顺序排序。- 放到TreeSet集合中的元素实际上是放到TreeMap集合中的key部分,底层是二叉树。
关于java.util.Map接口(以key和value这种键值对的方式存储元素)
一、Map集合接口中常用的方法
- Map接口和Collection接口没有继承关系。
- Map集合是以key和value这种键值对的方式存储元素。
——key和value都是引用数据类型,都是存储对象的内存地址。
——key起到主导的地位,value是key的一个附属品。- Map集合接口中的常用方法:
Vput(K key, V value):向Map集合中添加键值对Vget(Object key):通过指定的key,获得其所对应的valuevoidclear():清空Map集合booleancontainsKey(Object key):判断Map集合中是否包含指定的keybooleancontainsValue(Object value):判断Map集合中是否包含指定的valuebooleanisEmpty():判断Map集合中的元素个数是否为0Set<K>keySet():获得Map集合中所有的key(所有的key是一个Set集合)Vremove(Object key):删除指定key所对应的键值对intsize():获取Map集合中键值对的个数Collection<V>values():获得Map集合中所有的value,返回一个Collection集合Set<Map.Entry<K,V>>entrySet():将Map集合转换成Set集合
—— Map集合通过entrySet()方法转换成的这个Set集合,集合中的元素类型是 Map.Entry<K,V>
—— Map.Entry<K,V>和String一样都是一种类型的名字(类名),只不过 Map.Entry<K,V>是Map中的静态内部类
public class MapTest01 {
public static void main(String[] args) {
//创建一个Map集合对象
Map<Integer, String> map = new HashMap<>();
//put() 添加元素
map.put(1, "张三");
map.put(2, "李四");
map.put(3, "王五");
map.put(4, "陈六");
//size() 获得Map集合中键值对的个数
System.out.println("集合中键值对的个数:"+map.size());//集合中键值对的个数:4
//get() 获得指定key所对应的value
System.out.println(map.get(2));//李四
//remove() 删除集合中指定key的键值对
map.remove(2);
System.out.println("集合中键值对的个数:"+map.size());//集合中键值对的个数:3
//containsKey() 集合中是否包含指定key
System.out.println(map.containsKey(3));//true
//containsValue() 集合中是否包含指定Value
System.out.println(map.containsValue("陈六"));//true
//values() 获得集合中所有的value
Collection<String> values = map.values();
for (String value : values) {
System.out.print(value+" ");//张三 王五 陈六
}
System.out.println();
//clear() 清空集合
map.clear();
System.out.println("集合中键值对的个数:"+map.size());//集合中键值对的个数:0
//isEmpty() 判断集合中键值对个数是否为0
System.out.println(map.isEmpty());//true
//========================================================================================================
//以下两个方法可以用作Map集合的遍历(重点)
map.put(1, "张三");
map.put(2, "李四");
map.put(3, "王五");
map.put(4, "陈六");
//第一个:keySet() 获得集合中所有的key,通过遍历key获得所有的value
//获得所有的key,所有的key是一个Set集合
Set<Integer> set = map.keySet();
//foreach循环
for (Integer key : set) {
System.out.print(key+"="+map.get(key)+" ");//1=张三 2=李四 3=王五 4=陈六
}
System.out.println();
//迭代器循环
Iterator<Integer> it = set.iterator();
while (it.hasNext()) {
Integer key = it.next();
System.out.print(key+"="+map.get(key)+" ");//1=张三 2=李四 3=王五 4=陈六
}
System.out.println();
//第二种(建议):entrySet() 将Map集合转换为Set集合
Set<Map.Entry<Integer, String>> set1 = map.entrySet();
//使用迭代器循环
Iterator<Map.Entry<Integer, String>> it1 = set1.iterator();
while (it1.hasNext()) {
Map.Entry<Integer, String> node = it1.next();
System.out.print(node.getKey()+"="+node.getValue()+" ");//1=张三 2=李四 3=王五 4=陈六
}
System.out.println();
//使用foreach循环
for (Map.Entry<Integer, String> node : set1) {
System.out.print(node.getKey()+"="+node.getValue()+" ");//1=张三 2=李四 3=王五 4=陈六
}
}
}
二、HashMap集合
- HashMap集合的默认初始化容量是16,默认加载因子是0.75。
——默认加载因子是当HashMap集合底层数组的容量达到75%的时候,数组开始扩容。
注:HashMap集合初始化容量必须是2的倍数- HashMap集合的扩容:默认扩容到原容量的2倍。
- HashMap集合的key和value允许为null。
- HashMap集合的底层是哈希表/散列表的数据结构。
- 哈希表是一个怎样的数据结构?
- 哈希表/散列表:底层实际上是一个一维数组,这个数组中每一个元素是一个单向链表。
——数组和单向链表的结合体
- 数组:在查询方面效率较高,随机增删方面效率很低。
- 单向链表:在随机增删方面效率较高,查询方面效率很低。
——哈希表将以上两种数据结构融合在一起,充分发挥它们各自的优点。- HashMap集合底层的源代码
public class HashMap{ // HashMap底层实际上就是一个数组。(一维数组) Node<K,V>[] table; // 静态的内部类HashMap.Node,每个节点中有四个属性 static class Node<K,V> { final int hash; // 哈希值(哈希值是key的hashCode()方法的执行结果。hash值通过哈希函数/算法,可以转换存储成数组的下标。) final K key; // 存储到Map集合中的那个key V value; // 存储到Map集合中的那个value Node<K,V> next; // 下一个节点的内存地址。 } }- 哈希表数据结构示意图
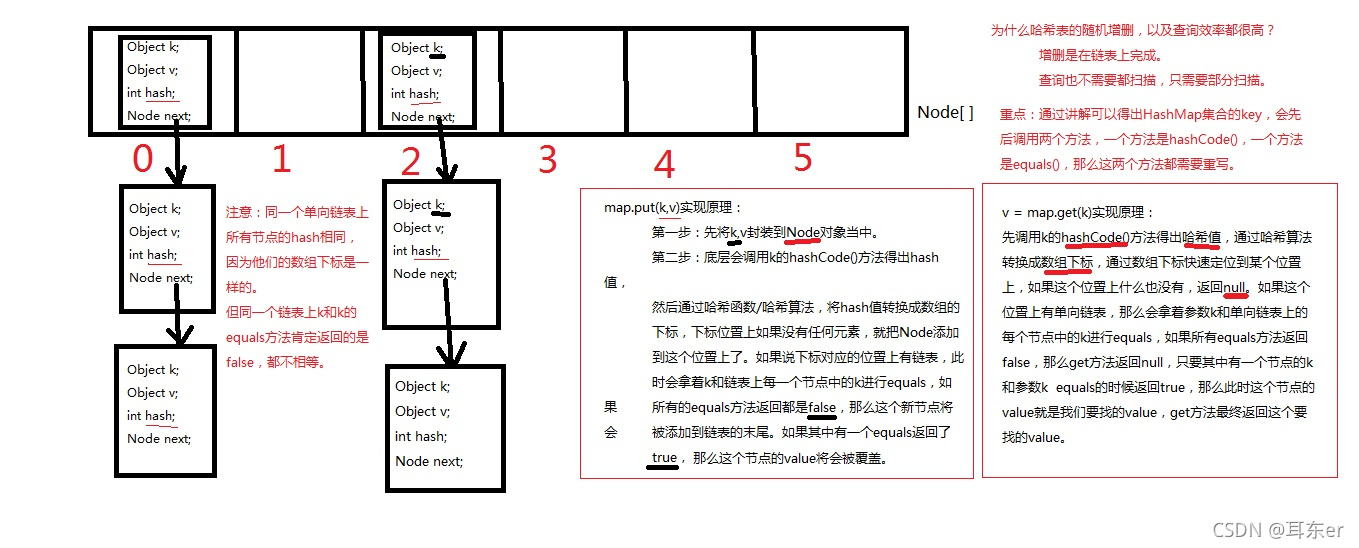
- HashMap集合的key部分(HashSet集合)的特点:无序不可重复。
- 无序的原理:
—— 底层会调用 key 的 hashCode() 方法得出 hash值,然后通过哈希函数/哈希算法将hash值转换成数组的下标,如果该下标上没有任何元素,就把Node添加到这个位置上;如果此下标上有链表,则会拿key跟链表上每一个节点中的key进行equals,再进行添加或覆盖。- 不可重复的原理:
—— 在添加时,key和链表上每一个节点的key会进行equals,如果key相同会覆盖,key不相同会在链表尾部进行添加。
注(重点):
————放在HashMap集合中key部分的元素,以及放在HashSet集合中的元素,需要同时重写hashCode()+equals()方法。- 哈希表HashMap集合在重写hashCode()方法时,hashCode()方法返回值不能设定成固定值和不能设定为都不一样的值,造成这种情况称为:散列分布不均匀。
——设定为固定值:变为纯单向链表
——设定为都不一样的值:变为纯一维数组
注:最好是每一单向链表中存储的元素个数都差不多,这样散列分布才均匀。- 向Map集合中存,以及从Map集合中取,都是先调用key的hashCode方法,然后再调用equals方法!
——因为equals()方法有可能调用,也有可能不调用例:
调用 put(k,v) 和 get(k) 方法时,什么时候equals()方法不会调用?
—— k.hashCode()方法返回哈希值,哈希值经过哈希算法转换成数组下标。 数组下标位置上如果是null,equals不需要执行。- 如果一个类的equals方法重写了,那么hashCode()方法必须重写。并且equals方法返回如果是true,hashCode()方法返回的值必须一样。
——equals方法返回true表示两个对象相同,则在同一个单向链表上比较。那么对于同一个单向链表上的节点来说,他们的哈希值都是相同的。所以hashCode()方法的返回值也应该相同。
注:如果两个节点的hash值相同,一定放到同一个单向链表上;如果两个节点的hash值不同,但由于哈希算法执行结束之后转换的数组下标可能相同,也会放到同一个单向链表上,这种现象称为"哈希碰撞"。- HashMap在JDK8之后,如果哈希表单向链表中节点(元素)超过8个,单向链表这种数据结构会变成红黑树数据结构;当红黑树上的节点(元素)数量少于6时,会重新把红黑树数据结构变成单向链表数据结构。
——这种方式是为了提高检索效率,二叉树的检索会再次缩小扫描范围,提高效率。
三、Hashtable集合
- Hashtable集合默认初始容量为11,默认加载因子为0.75
——默认加载因子是当Hashtable集合底层数组的容量达到75%的时候,数组开始扩容。- Hashtable集合的扩容:默认扩容到原容量的2倍再加1((原容量*2)+1)。
- Hashtable集合的key和value不能为null。(为null会出现空指针异常)
——HashMap集合的key和value可以为null。- Hashtable集合的底层是哈希表/散列表的数据结构。
四、Properties集合
- Properties集合是一个Map集合,继承于Hashtable集合,Properties集合的key和value都是String类型。
- Properties集合被称为属性类对象。
- Properties集合是线程安全的。
- Properties集合中常用的方法:
ObjectsetProperty(String key, String value):相当于put方法,往集合中存储元素。StringgetProperty(String key): 根据指定的key获得key相对应的value。
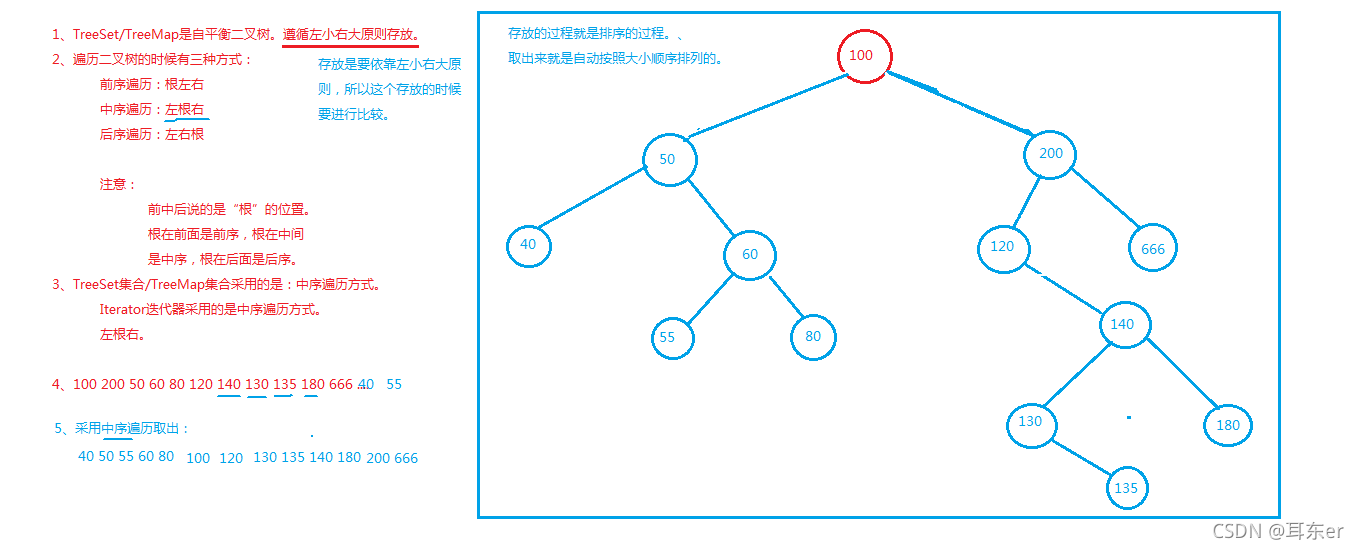
五、TreeMap集合
- TreeMap集合底层是一个二叉树数据结构。
- 放到TreeMap集合中key部分的元素相当于放到TreeSet集合中。
- TreeMap集合中存储元素的特点:与TreeSet相同,无序不可重复,元素可按照大小顺序自动排序,称为可排序集合。
- 对于自定义的类型,放到TreeSet或者TreeMap集合key部分的元素可以自动排序吗?
——不能,因为没有指定自定义类型对象之间的比较规则,会出现异常:java.lang.ClassCastException- 放到TreeSet或者TreeMap集合key部分的元素要想做到自动排序,包括两种方式:
—— 第一种:放在集合中的元素实现java.lang.Comparable接口。
—— 第二种:在构造TreeSet或者TreeMap集合的时候给它传一个Comparator比较器对象。
Comparable和Comparator怎么选择呢?
————当比较规则不会发生改变的时候,或者说当比较规则只有1个的时候,建议实现Comparable接口。
————如果比较规则有多个,并且需要多个比较规则之间频繁切换,建议使用Comparator接口。(Comparator接口的设计符合OCP原则。)public class TreeSetTest02 { public static void main(String[] args) { /* 1.放在集合中的元素实现java.lang.Comparable接口。 TreeSet<Vip> vips = new TreeSet<>(); */ //2.在构造TreeSet或者TreeMap集合的时候给它传一个比较器对象。 TreeSet<Vip> vips = new TreeSet<>(new VipComparator()); } } //1.实现Comparable比较接口 class Vip implements Comparable<Vip>{ private String name; private int age; @Override public int compareTo(Vip o) { //比较规则:先比较年龄顺序,如果年龄相同则比较姓名顺序 //return this.age == o.getAge() ? this.name.compareTo(o.getName()) : this.age - o.getAge(); if (this.age == o.getAge()) {//如果年龄相等,就比较姓名顺序 return this.name.compareTo(o.getName()); } else { return this.age - o.getAge(); } } } //2.编写Comparator比较器 class VipComparator implements Comparator<Vip> { @Override public int compare(Vip o1, Vip o2) { //先比较年龄顺序,如果年龄相同则比较姓名顺序 if (o1.getAge() == o2.getAge()) { return o1.getName().compareTo(o2.getName()); } else { return o1.getAge() - o2.getAge(); } } }

















 1552
1552

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









