







一、思考:数组也可以存储数据,为什么会出现集合?
原因:
1.数组的长度是固定的,集合长度是可变的
2.数组不擅长插入、删除等操作,而集合有一系列方法。
3.使用Java类封装一个个容器,开发者只需要调用即可,不需要手动创建容器类
数组:存储一组相同类型数据的数据容器,在内存中分配"连续空间"进行保存
集合:是Java中提供的一种容器,可以用来存储多个数据,根据不同存储方式形成的体系结构,就叫做集合框架体系(掌握)。集合也时常被称为容器。
二、集合框架
分为 Collection 接口和 Map 接口

图1 集合框架分类
1.Collection的子接口分为list接口和Set接口
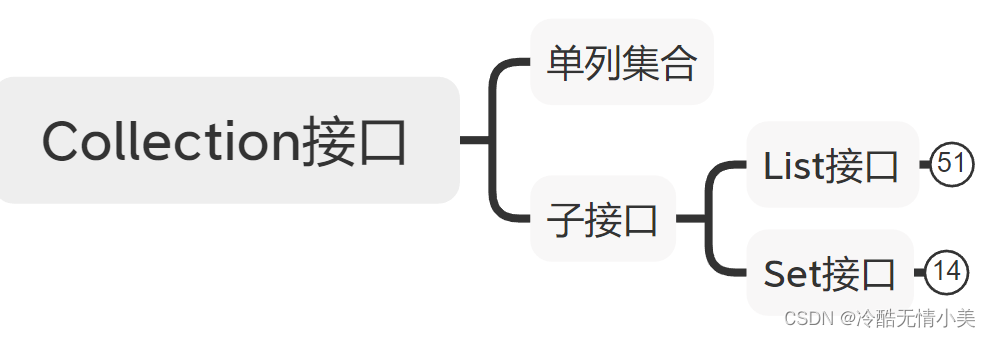
图2 Collection接口分类
2.list接口
(1)包括ArrayList、LinkedList、Vector;
(2)特点:有序,值允许重复
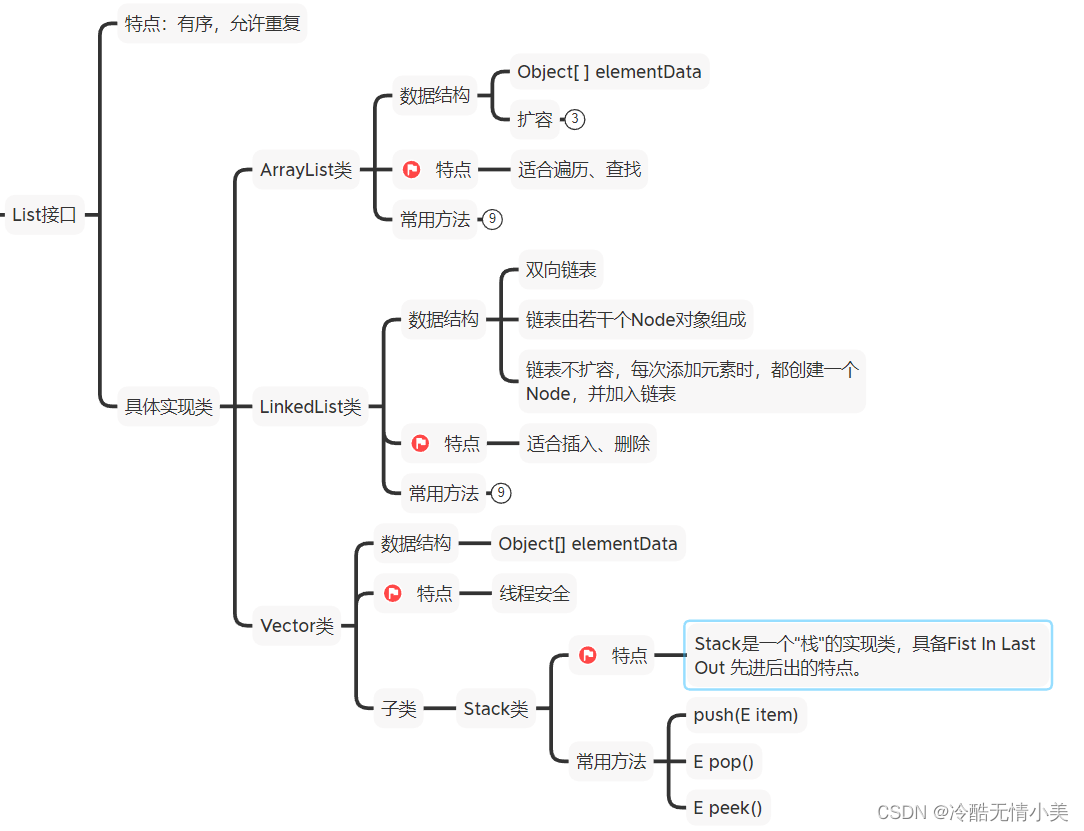
图3 list接口的特点及具体实现类
(1)ArrayList
A.特点:
a.有序,值允许重复
b.适合遍历、查找(原因:ArrayList是数组,下标是有序的)
B.数据结构:
Object[] 数组
C.扩容方式
无参构造,数组初始化容量为空
添加第一个元素时,数组容量扩容到10
容量不足时,数组容量按原容量的1.5倍扩容

图4 ArrayList 常用方法
(2)LinkedList类
A.特点
a.有序,值允许重复
b.适合插入、删除(原因:链表形式,插入删除只影响相邻节点)
B.数据结构
双向链表
C.扩容方式
不扩容!每次添加元素时,都创建Node(节点),并加入链表

图5 LinkedList类常用方法
(3)Vector类(不常用)
A.特点
线程安全
B.数据结构
Object[] 数组
C.扩容方式
初始容量是10
容量不足时,按原容量的2倍扩容
D:常用子类Stack
特点:Stack是一个"栈"的实现类具备 "First in Last Out" (先进后出) 的特点
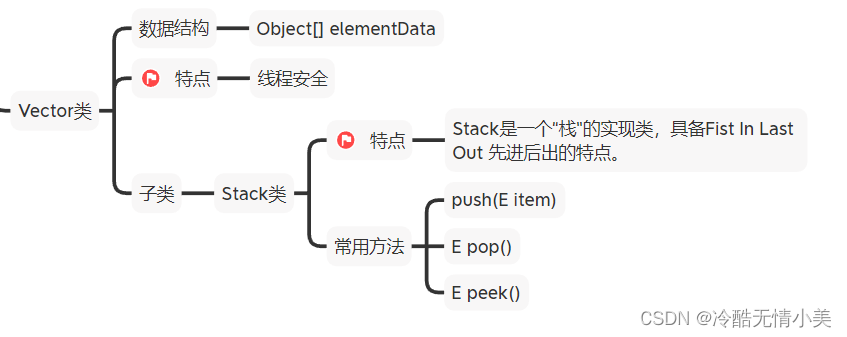
图6 Vector的子类Stack 常用方法
3.Set接口
特点:无序,值唯一
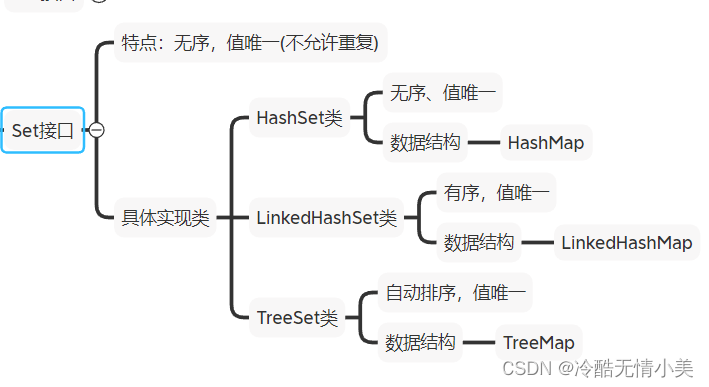 图7 Set接口的特点及具体实现类
图7 Set接口的特点及具体实现类
(1)HashSet类
A.特点
无序,值唯一
B.数据结构
HashMap
(2)LinkedHashSet类
A.特点
有序,值唯一
B.数据结构
LinkedHashMap
(3)TreeSet类
A.特点
自动排序,值唯一
B.数据结构
TreeMap
4.Map接口
特点:key-value键值对集合,键key唯一,值Value不唯一
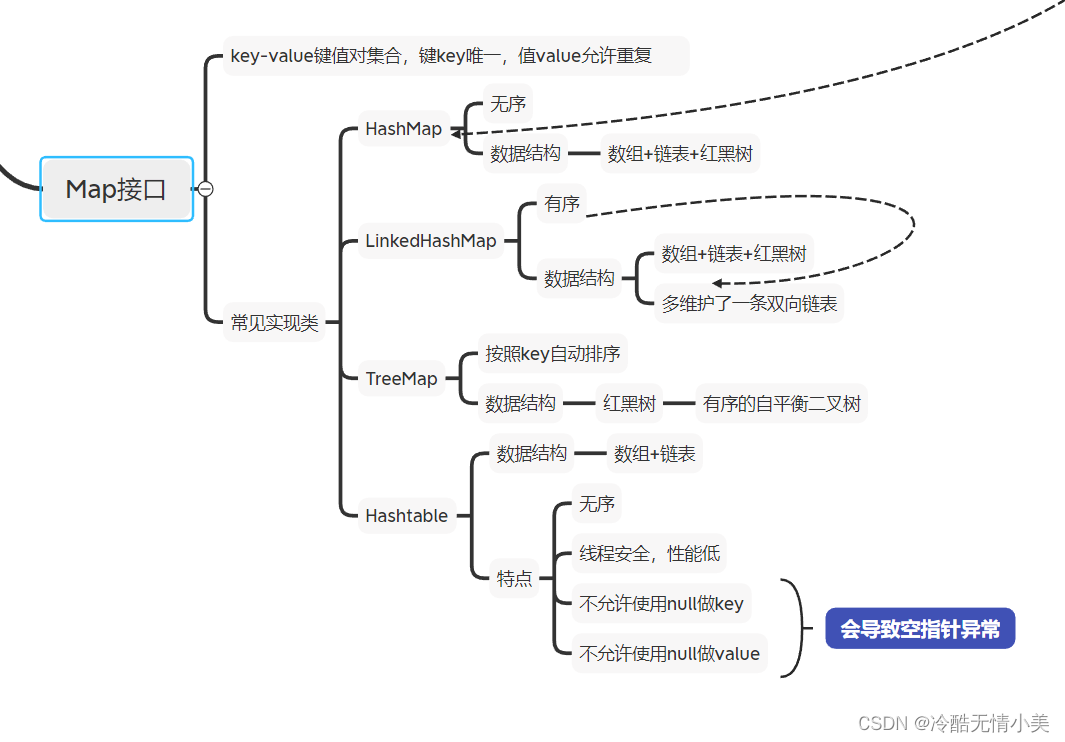
图8 Map接口的特点及具体实现类
(1)HashMap类
A.特点
无序
B.数据结构
数组(哈希表)+链表(解决哈希冲突)+红黑树(自平衡二分查找树)
C.扩容方式
- 默认情况下,数组初始容量为16(自定义扩容时,必须保证数组长度为2^n次幂 )
- 当数组元素 >= 数组长度*加载因子(0.75)时,就要扩容。
- 当链表长度大于8,但是数组容量小于64,则需扩容。
(2)LinkedHashMap类
A.特点
有序
B.数据结构
数组+链表+红黑树
多维护了一条双向链表 (有序的原因)
(3)TreeMap类
A.特点
根据 Key 自动排序
B.数据结构
红黑树---有序的自平衡二叉树
(4)HashTable
A.特点
a.无序
b.线程安全,性能低
c.不允许使用Null值作Key (会引发空指针异常)
d.不允许使用Null值作Value (会引发空指针异常)
B.数据结构
数组+链表
自此:集合框架已介绍完毕!附上完整框架图以及面试常问问题!
完整框架图:

图9 集合框架完整图
面试常问?
1.哈希冲突是什么?怎么解决?
答:哈希冲突是指不同的输入数据经过哈希函数计算后得到了相同的哈希值的情况。由于哈希函数的输出值域通常要小于输入数据的集合所以哈希冲突是不可避免的。
解决:1.链地址法(拉链法):将哈希表中的每个槽都设置为一个链表或其他数据结构,当有冲突发生时,便将冲突的元素添加到对应槽的链表中。这种方法是最常见和简单的解决哈希冲突的方法。
2.开放地址法:在发生哈希冲突时,通过一个探测函数计算出一个新的位置,并将冲突元素存储到新的位置上。常见的开放地址法包括线性探测、二次探测和双重哈希。
3.再哈希法:当发生哈希冲突时,使用一个不同的哈希函数计算一个新的哈希值,然后将冲突元素存储到新的位置上。再哈希法的关键在于选择合适的哈希函数,使得冲突几率减小。
4.建立公共溢出区:将所有冲突的元素都存储到一个公共的溢出区中。当需要查找某个元素时,首先通过哈希函数计算出该元素在哈希表中的位置,如果该位置为空,则直接返回查找失败,如果该位置不为空,则在溢出区中查找该元素。
2.ArrayList减少扩容的途径?
答:预先规划,预估元素数量;通过有参构造,设置一个合适的初始容量。(每次扩容都会造成空间浪费)
3.ArrayList类、LinkedList类 和Vector类的扩容?
答:(1)ArrayList初始化时,若是有参构造方法,则根据指定值进行初始化;若是无参构造方法,则初始化为空,当输入第一个元素时,数组容量扩容到10。
若容量不足时,按照数组现有容量的1.5倍扩容。
(2)LinkedList不存在扩容,每次添加元素时,都创建Node(节点),并加入链表。
(3)Vector初始化时,若是有参构造方法,则根据指定容量初始化;若是无参构造方法,初始化为10。若容量不足时,按照数组现有容量的2倍扩容。
4.Set里的值为什么是唯一的?
答:Set借助了Map里的Key,Map里的Key值是唯一的
5.Set里存了一个值,怎么存到Map里了?
答:Set借助了Map里的Key,Map将Key值给了Set里的Value,Value为Present常量。
6.按照Hash,重新计算Hash值有什么好处?
答:让新的哈希值冲突概率更低、更散列。
7.Hash哈希下标怎么计算?
答:(1)Hash % 数组长度
(2)(数组长度 - 1)& Hash
注:数组长度必须是2的n次方
8.计算出来的Hash下标怎么?
答:判断该下标是否存在元素:
(1)若存在,则以链表形式,将当前键值保存至链表尾部(尾插法)
(2)若不存在,则直接存入
8.链表有什么缺点?用什么方法改变?
答:缺点:链表不方便查找,查找效率低
解决方法:当链表长度大于8时,使用红黑树进行存
好处:红黑树是一个有序、自平衡的二叉树,适合二分查找!用它找可以提高查找效率!
8.HashSet为什么无序?
答:哈希值不同,算出来的下标不同
9.HashMap和HashTable区别?
答:(1)特点:
HashMap:允许NULL作key和value
HashTable:不允许NULL作key和value
(2)数据结构
HashMap:数组+链表+红黑树
HashTable:数组+链表
(3)线程安全
HashMap:线程不安全
HashMap:线程安全
(4)执行效率
因为HashTable加了一个同步锁synchronized实现了线程安全,所以执行效率略低。
(5)扩容方式
hashMap:初始容量是16,再次进行扩充时,变为原来的2倍
HashTable:初始容量为11,再洗扩充时,变为原来的2n+1
10.红黑树变链表以及链表变红黑树的条件和使用红黑树的好处?
答:链表 ===》 红黑树:链表长度大于8并且数组容量大于64。
红黑树 ===》 链表:红黑树子节点数小于6。
使用红黑树的好处:
红黑树是一个自平衡二叉查找树,所有节点均可自动排序,并且自平衡,可以使用二分查找法,可以提高查找效率。当链表过长,会导致搜索效率降低,利用二叉树提高搜索效率。
11.影响性能关键参数?
答:(1)数组容量(默认16):数组容量越大,哈希冲突概率越小。
(2)加载因子(默认0.75):加载因子越大,哈希冲突越大;加载因子越小,哈希冲突越小。















 1705
1705

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









