










本科生毕业设计选题大全——计算机类(Python/Java)
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人 。
1、项目介绍
(1)技术栈:
Python语言 MySQL数据库 Django框架 协同过滤推荐算法 requests网络爬虫 pyecharts数据可视化 html页面
爬取院校信息:https://yz.chsi.com.cn/sch/(研招网)
考研院校推荐系统 爬虫+混合推荐+协同过滤推荐算法+Echarts可视化
基于Python考研院校推荐系统 爬虫+混合推荐+协同过滤推荐算法+Echarts可视化 考研推荐 专业推荐 计算机毕业设计
2、项目界面
(1)数据可视化分析
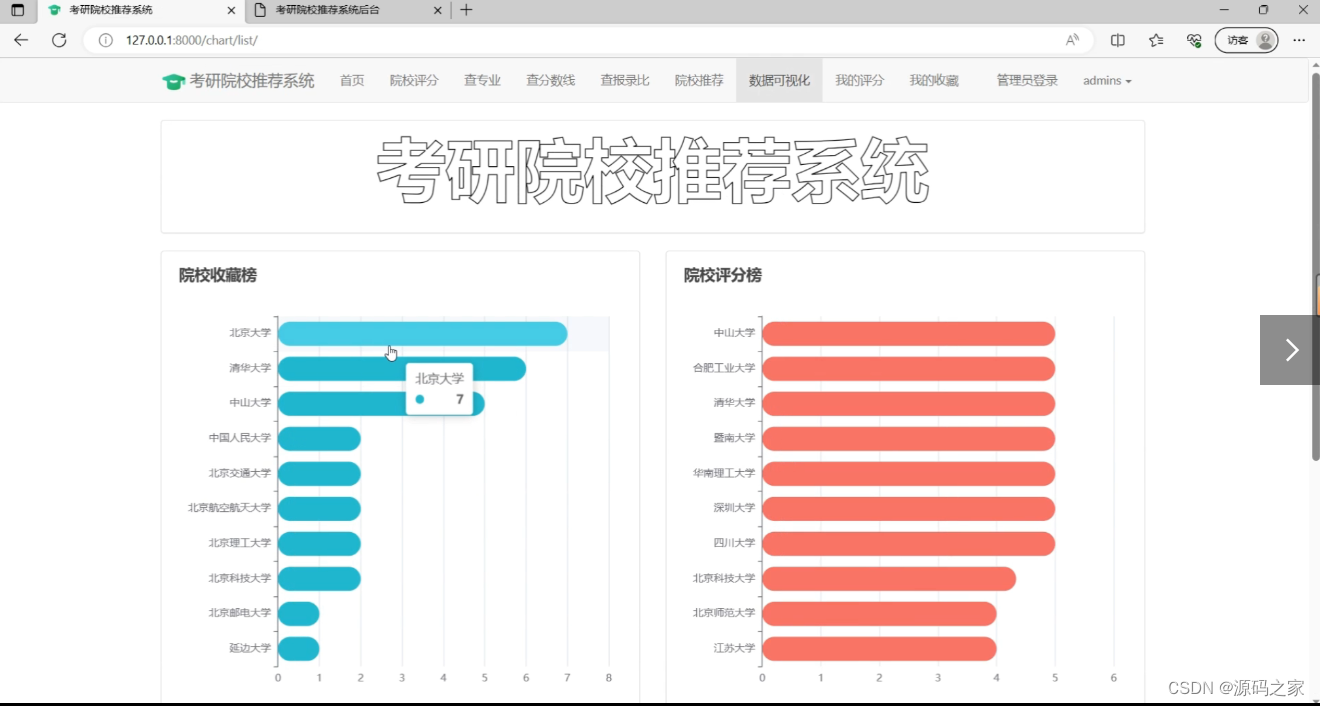
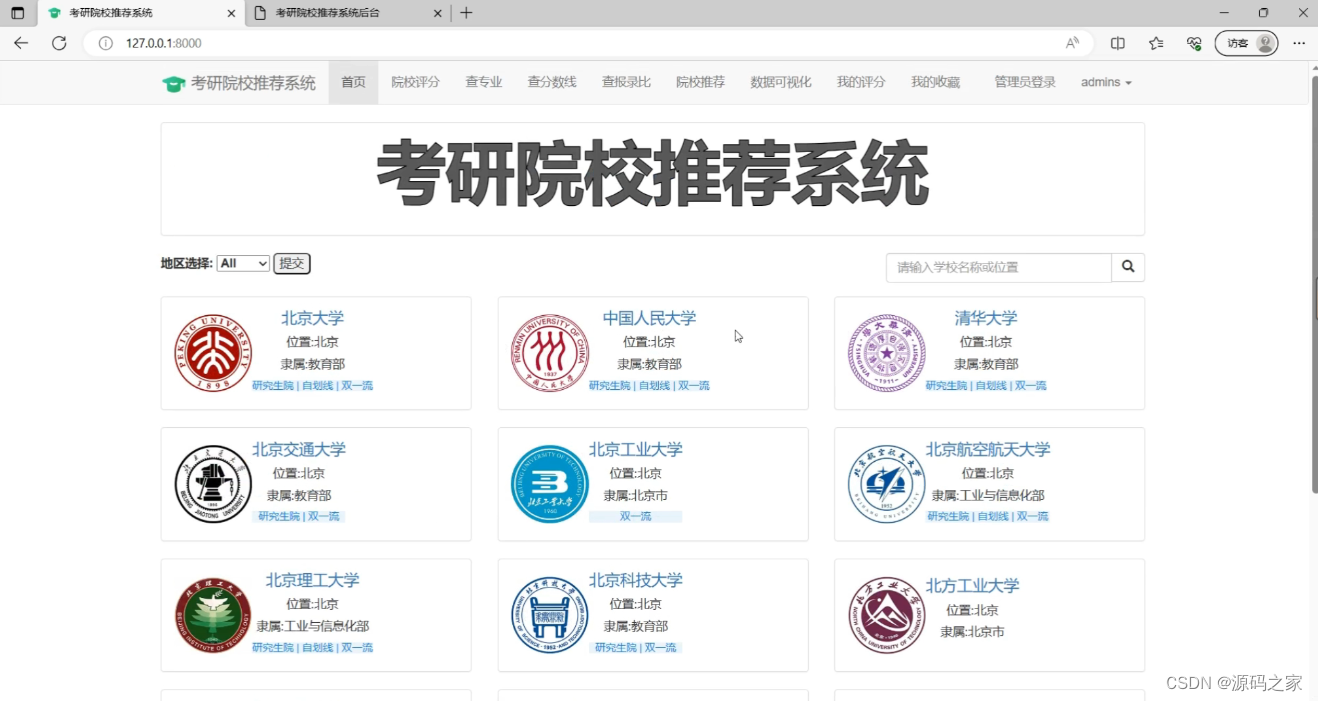
(2)系统首页—高校信息
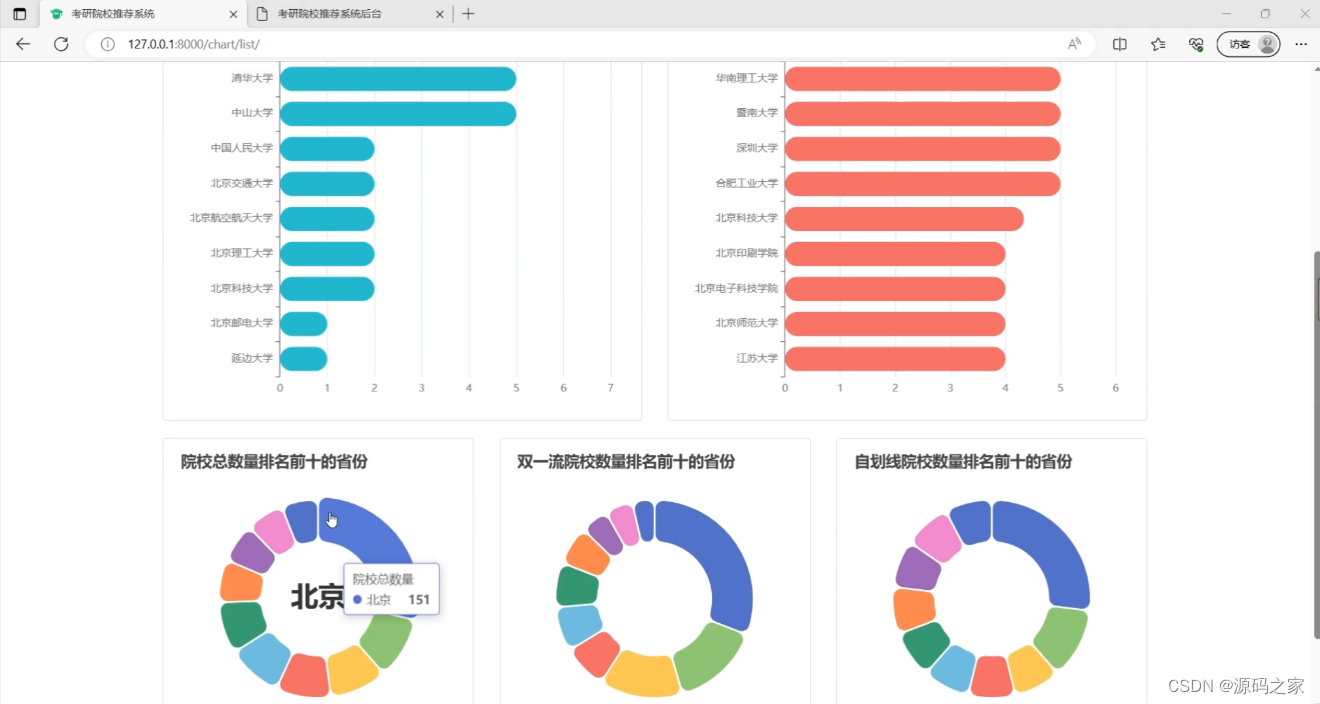
(3)高校信息排行榜可视化分析
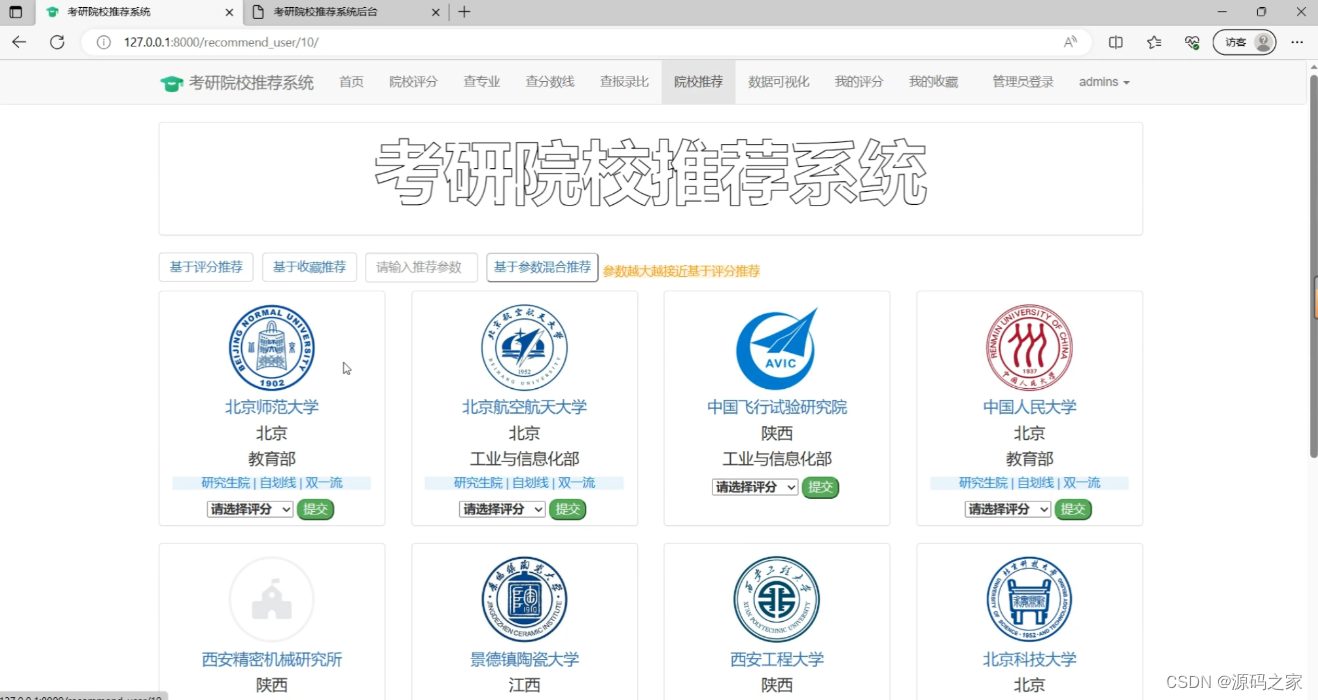
(4)院校推荐模块
(5)高校院校页面
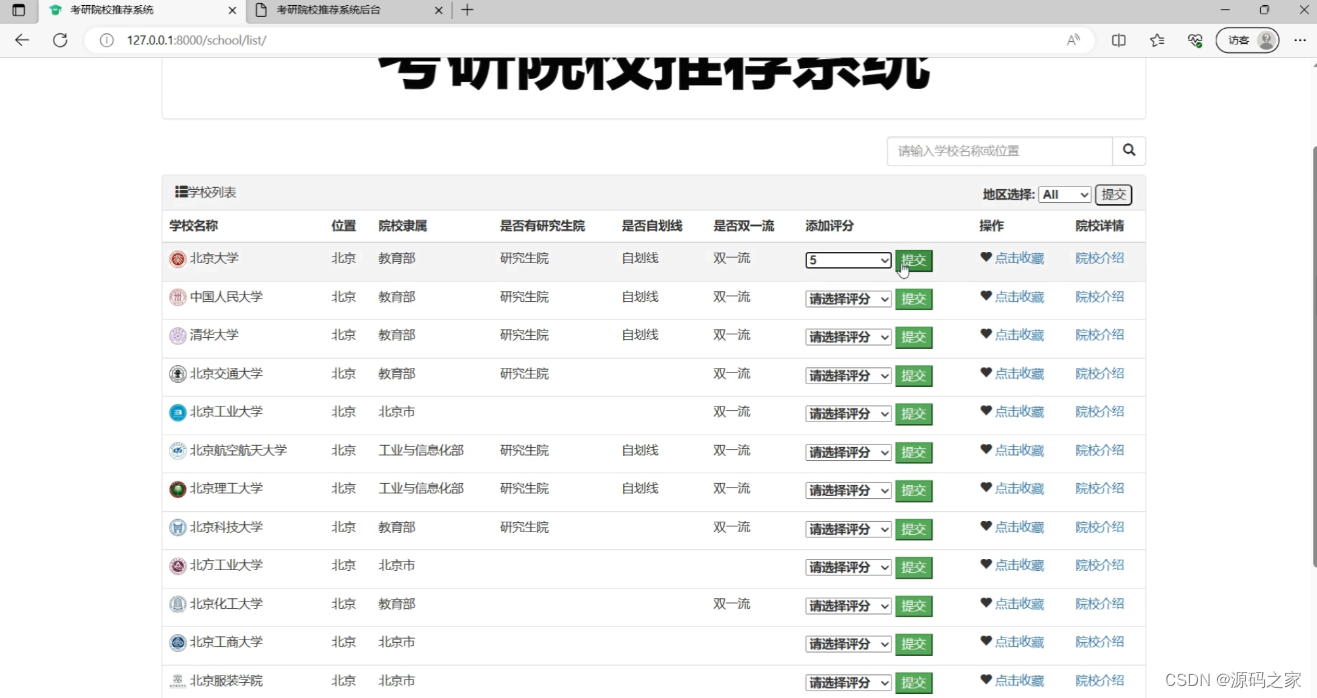
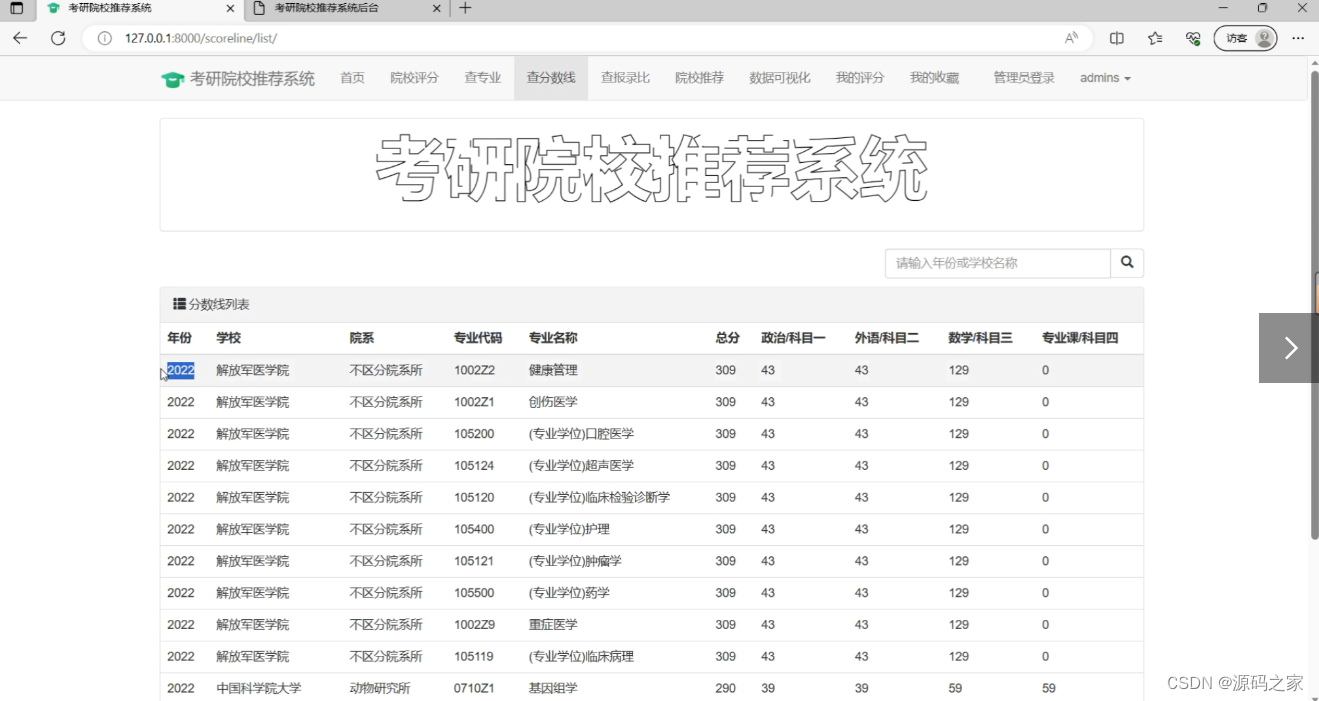
(6)高校分数线页面
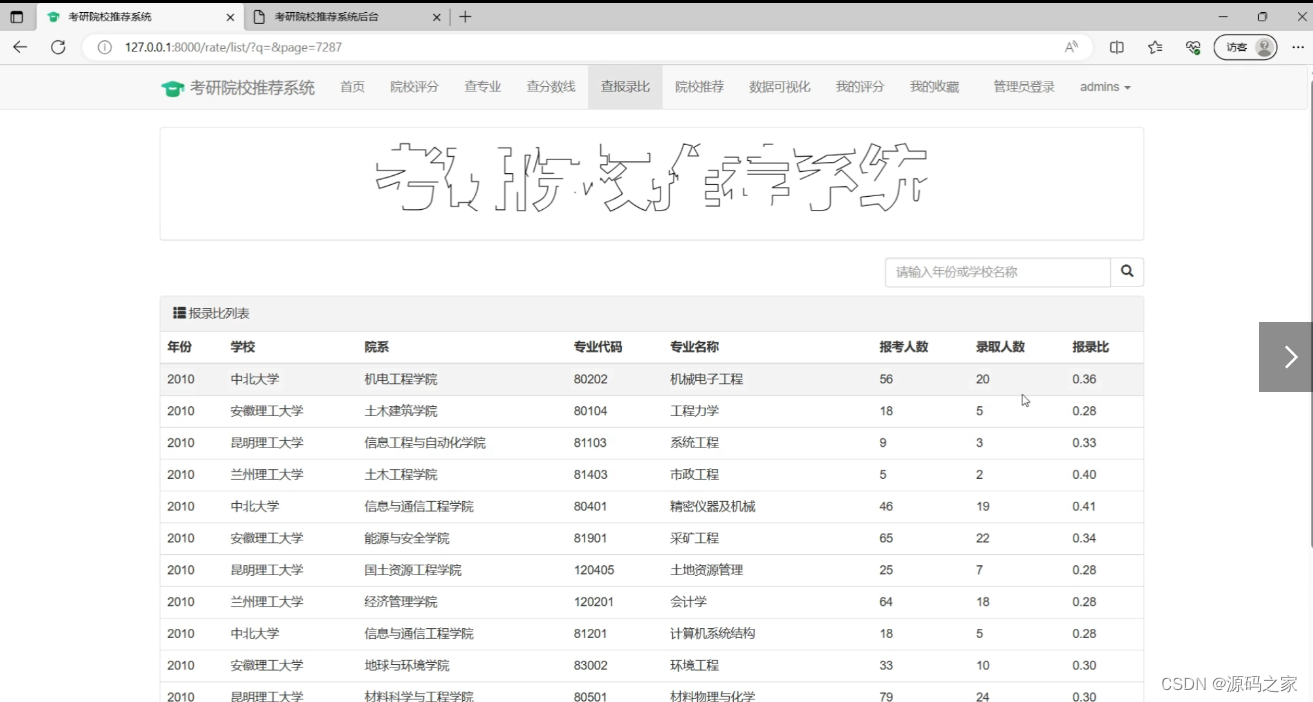
(7)查高校录取比页面
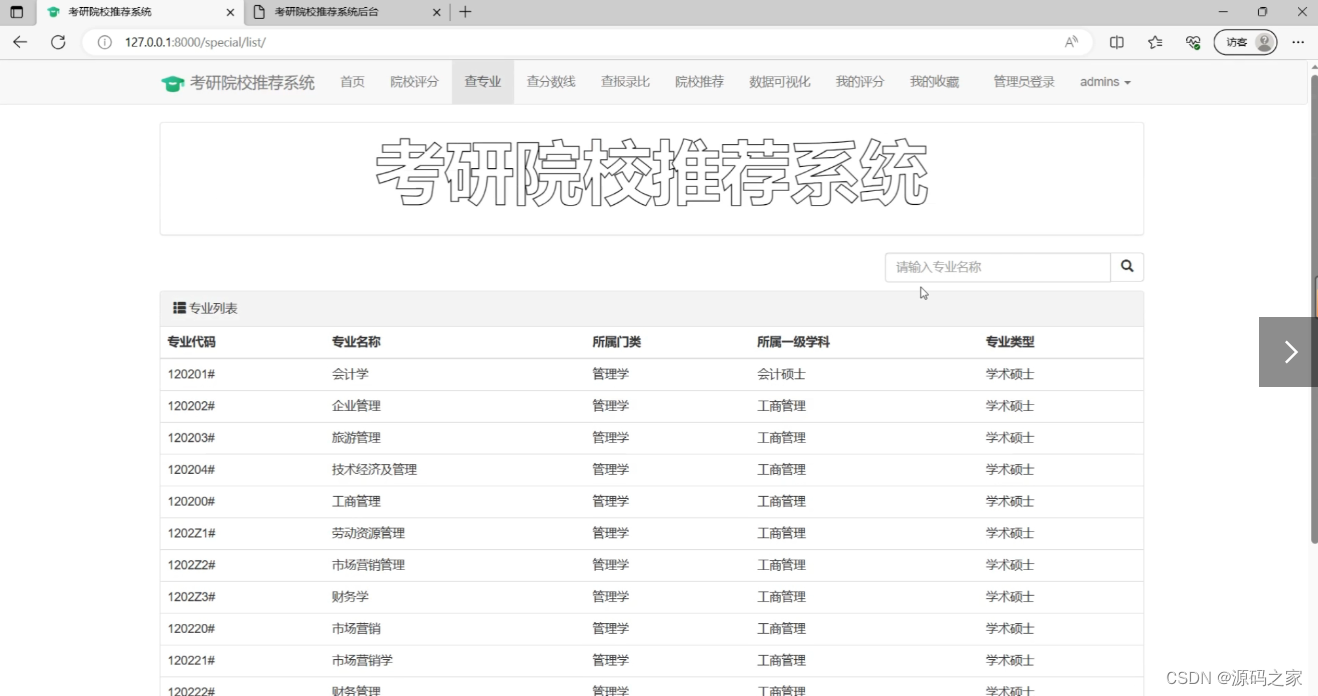
(8)查高校专业页面
(9)我的评分页面
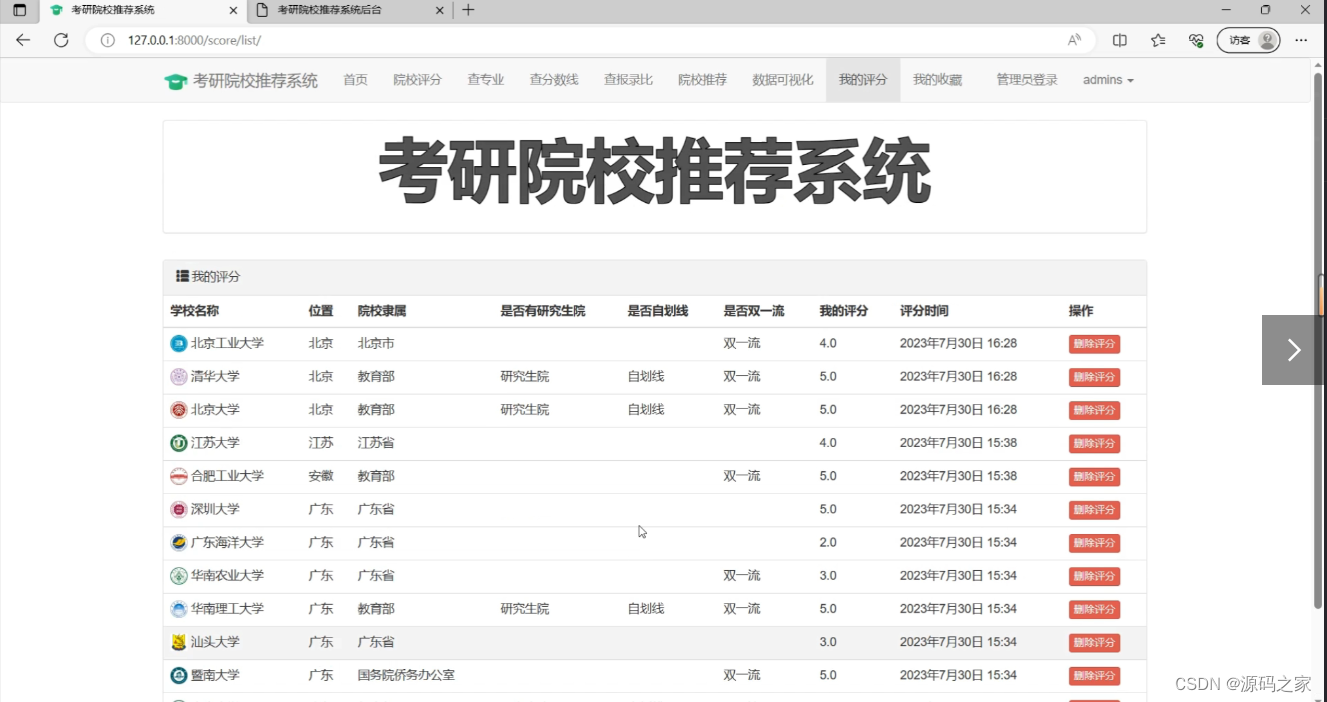
(10)我的收藏页面
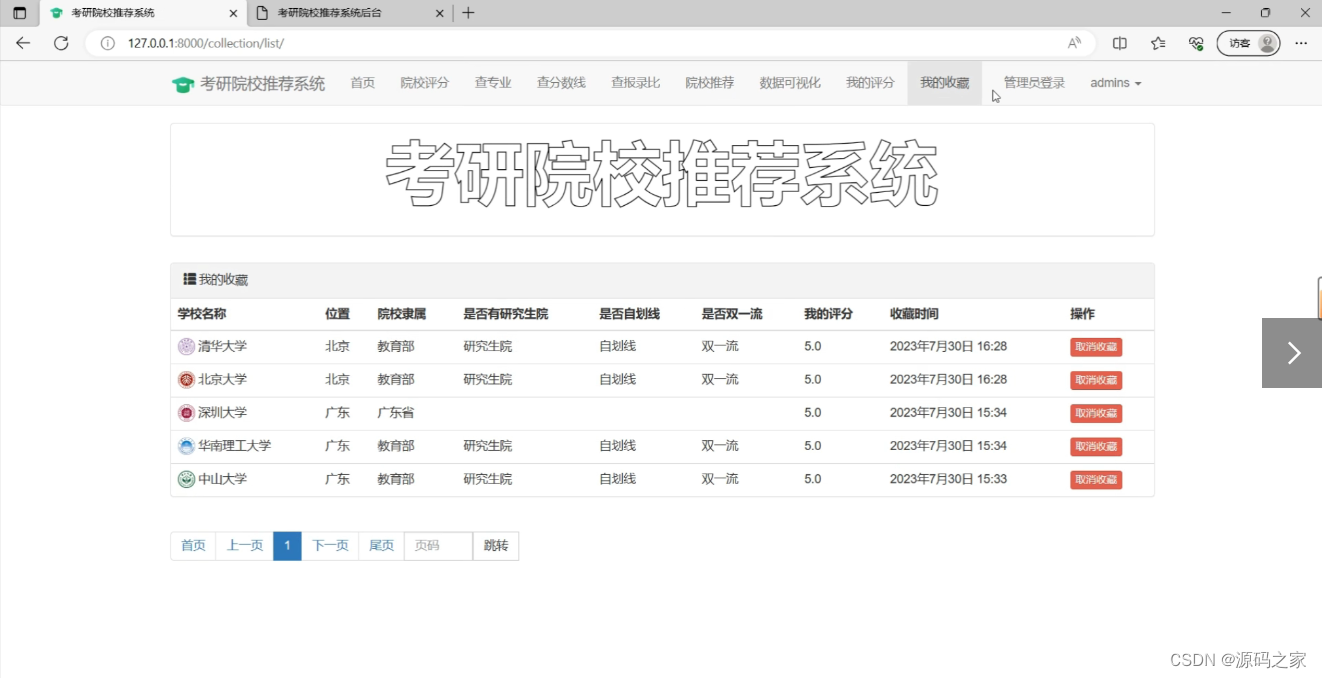
(11)后台数据管理页面

(12)数据采集爬虫页面
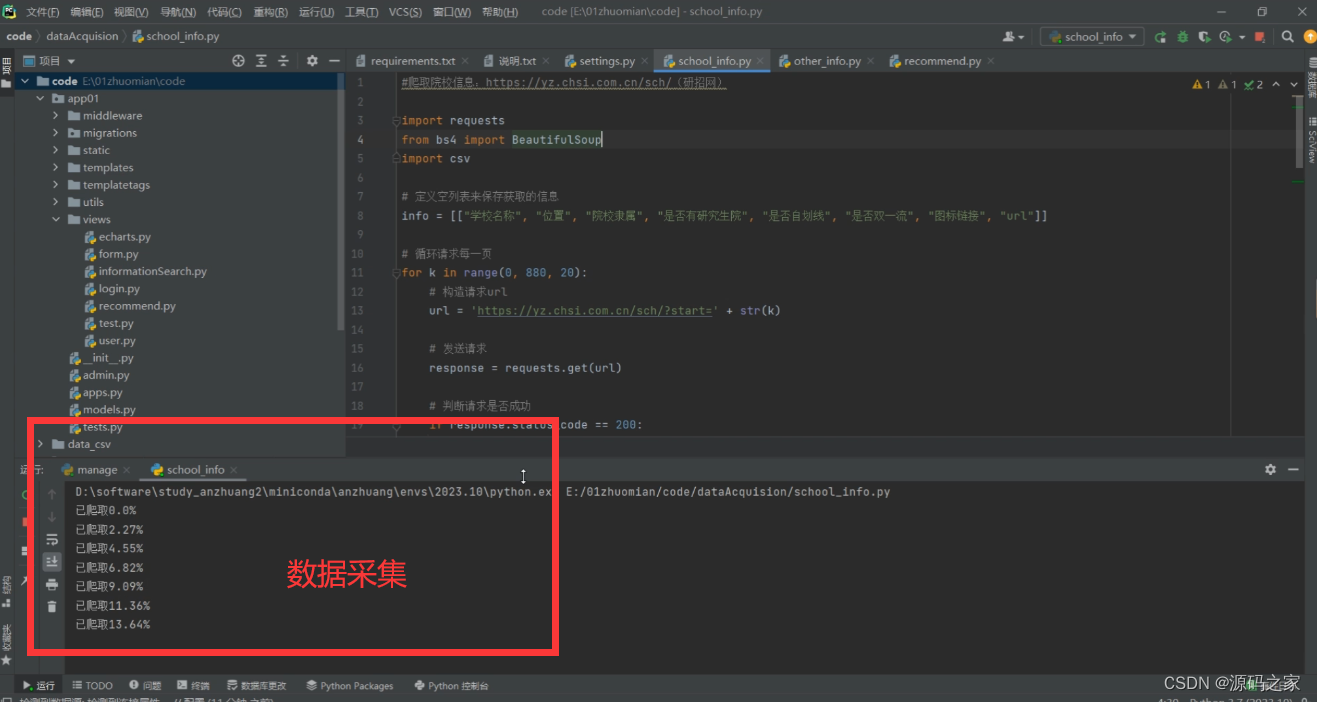
3、项目说明
基于Python的考研院校推荐系统是一款利用Python语言和相关技术,为考生提供个性化院校推荐服务的应用系统。以下是该系统的主要介绍:
数据收集:系统采集了全国各地公布的考研数据,包括历年各省份考研报名人数、报考人数、录取分数线等信息,以及各高校的专业、科研情况、学术声誉等数据。通过对这些数据进行整合处理,系统建立了一个完整的数据仓库。
数据挖掘:系统利用机器学习和数据挖掘技术,对用户输入的专业、成绩、地区等信息进行分析,确定用户的兴趣和需求,以此为基础,利用协同过滤算法、基于内容的推荐算法等多种算法方法,实现个性化的院校推荐。
推荐算法:系统根据用户的输入信息,利用机器学习算法对已有的数据进行模型训练和预测,计算出与用户最匹配的院校推荐结果。
用户界面和交互设计:系统提供友好的用户界面和交互设计,用户可以根据自己的需求输入专业、成绩、地区等信息,同时还可以根据自己的偏好进行院校筛选和优化。
可视化展示:系统采用图表和图形等方式,直观地呈现推荐结果,使用户能够更加清晰明了地理解推荐结果,并进一步提高决策效率。
综上所述,基于Python的考研院校推荐系统是一款利用Python技术进行开发的应用系统,旨在为考生提供个性化的院校推荐服务。通过数据挖掘和机器学习技术,系统可以根据用户的兴趣和需求,给出符合用户背景和选校要求的院校推荐,提高用户决策效率,帮助他们实现顺利升学。
4、部分源码
import random
from django.shortcuts import render
import math
from app01 import models
from app01.models import School, UserScore, User, UserCollection
from app01.utils.pagination import Pagination
def jaccard_similarity(a, b):
计算杰卡德相似度
将布尔向量转换为集合
set_a = set(i for i, x in enumerate(a) if x)
print("set_a:", set_a)
set_b = set(i for i, x in enumerate(b) if x)
print("set_b:", set_b)
计算交集和并集的大小
intersection = len(set_a.intersection(set_b))
print("a和b交集:", set_a.intersection(set_b))
union = len(set_a.union(set_b))
print("a和b并集:", set_a.union(set_b))
计算相似度
similarity = intersection / union if union else 0
return similarity
重载字典计算方法
class MyDict(dict):
def __add__(self, other):
res = MyDict(self)
for key, val in other.items():
if key in res:
res[key] += val
else:
res[key] = val
return res
def __mul__(self, factor):
res = MyDict()
for key, val in self.items():
res[key] = val * factor
return res
def __rmul__(self, factor):
return self.__mul__(factor)
def cosine_similarity(v1, v2):
计算余弦相似度
numerator = sum([a * b for a, b in zip(v1, v2)]) 两向量的内积作为分子
denominator = math.sqrt(sum([a ** 2 for a in v1])) * math.sqrt(sum([b ** 2 for b in v2])) 两向量模长的乘积作为分母
if denominator > 0:
return numerator / denominator
else:
return 0
基于用户收藏计算当前用户与其他用户的杰卡德相似度
def user_jaccard_similarity_collections(user_id, default_similarity_jaccard=0):
获取当前用户的收藏数据
user_collections = UserCollection.objects.filter(user_id=user_id).values('school_id', 'collection')
获取当前用户收藏的学校id
user_collections_school_id = [user_collection['school_id'] for user_collection in user_collections]
print("当前用户收藏情况:")
print(user_collections_school_id)
print("基于用户收藏的邻居用户收藏情况:")
构造当前用户收藏向量
user_collection_vector = [0 for i in range(999)]
for school_id in user_collections_school_id:
user_collection_vector[school_id] = 1
similarities_jaccard = {} 定义字典来存放与当前用户相似用户的id和相似度
for user in User.objects.exclude(id=user_id):
获取当前用户与其他用户共同收藏的物品的id
collections = user.usercollections.filter(school_id__in=user_collections_school_id).values('school_id')
if collections: 如果当前用户与该用户有共同收藏的学校,则计算当前用户与该用户的相似度,这里使用杰卡德
获取该用户所有的收藏情况:(school_id)
collections = user.usercollections.filter().values('school_id')
collections_school_id = [(collection['school_id']) for collection in collections]
print(collections_school_id)
构造该用户收藏向量:collection_vector
collection_vector = [0 for i in range(999)]
for school_id in collections_school_id:
collection_vector[school_id] = 1
collection_vector[0] = user.id
print(collection_vector)
计算两用户之间的杰卡德相似度
similarity_jaccard = jaccard_similarity(user_collection_vector, collection_vector)
if similarity_jaccard > default_similarity_jaccard:
similarities_jaccard[user.id] = similarity_jaccard
return similarities_jaccard
基于用户收藏计算当前用户对邻居收藏院校的jaccard兴趣度
def user_recommendations_jaccard_collections(user_id, similarities, similarities_jaccard):
获取当前用户的收藏数据
user_collections = UserCollection.objects.filter(user_id=user_id).values('school_id', 'collection')
获取当前用户收藏的学校id
user_collections_school_id = [user_collection['school_id'] for user_collection in user_collections]
recommendations_jaccard = {}
print("邻居用户已收藏的学校中目标用户未收藏的学校:",
UserCollection.objects.filter(user_id__in=similarities).exclude(
school_id__in=user_collections_school_id).values_list('school_id', flat=True).distinct())
邻居用户已收藏的学校中目标用户未收藏的学校
for school_id in UserCollection.objects.filter(user_id__in=similarities).exclude(
school_id__in=user_collections_school_id).values_list('school_id', flat=True).distinct():
获取收藏了当前物品的用户:用户id和收藏情况(collection = 1)
item_collections = UserCollection.objects.filter(school_id=school_id).values('user_id', 'collection')
初始化一个空列表
weighted_scores = []
遍历 item_ratings 中的每一条记录
for collection in item_collections:
如果该收藏记录对应的用户在 similarities_jaccard 字典中,则计算该收藏记录对该物品的权重得分
if collection['user_id'] in similarities_jaccard:
获取该收藏记录对应用户与目标用户的相似度
similarity = similarities_jaccard[collection['user_id']]
计算该收藏记录对该物品的权重得分
weighted_score = similarity * collection['collection']
将该权重得分添加到列表中
weighted_scores.append(weighted_score)
numerator = sum(weighted_scores)
denominator = sum(similarities_jaccard.values())
if denominator > 0:
recommendations_jaccard[school_id] = round(numerator / denominator, 2)
print("邻居用户已收藏的学校中目标用户未收藏的学校:", UserCollection.objects.filter(user_id__in=similarities).exclude(
school_id__in=user_collections_school_id).values_list('school_id', flat=True).distinct())
print("基于用户收藏的兴趣度得分情况:",recommendations_jaccard)
return recommendations_jaccard
基于用户评分计算当前用户和其他用户的余弦相似度
def user_cosine_similarity_ratings(user_id, default_similarity_cosine=0):
获取当前用户评分数据
user_ratings = UserScore.objects.filter(user_id=user_id).values('school_id', 'score')
user_ratings_school_id = [user_rating['school_id'] for user_rating in user_ratings]
获取当前用户评分学校的评分情况:(school_id,score)
user_ratings_school = [(user_rating['school_id'], user_rating['score']) for user_rating in user_ratings]
print("当前用户评分情况:")
print(user_ratings_school)
print("基于用户评分的邻居用户评分情况:")
构造当前用户评分向量:user_rating_vector
user_rating_vector = [0 for i in range(999)]
for school_id, score in user_ratings_school:
user_rating_vector[school_id] = score
根据评分情况计算所有用户的相似度:如果两用户之间没有共同评分的学校,则相似度为0
similarities_cosine = {}
for user in User.objects.exclude(id=user_id):
获取当前用户与其他用户共同评价的物品的评分数据
ratings = user.userscores.filter(school_id__in=user_ratings_school_id).values('school_id', 'score')
if ratings: 如果当前用户与该用户有共同评分的学校,则计算当前用户与该用户的相似度,这里使用余弦相似度
获取该用户所有的评分学校的评分情况:(school_id,score)
ratings = user.userscores.filter().values('school_id', 'score')
ratings_school = [(rating['school_id'], rating['score']) for rating in ratings]
print(ratings_school)
构造该用户评分向量:rating_vector
rating_vector = [0 for i in range(999)]
for school_id, score in ratings_school:
rating_vector[school_id] = score
print(rating_vector)
计算两用户之间的余弦相似度
similarity_cosine = cosine_similarity(user_rating_vector, rating_vector)
if similarity_cosine > default_similarity_cosine:
similarities_cosine[user.id] = similarity_cosine
return similarities_cosine
基于用户评分计算当前用户对邻居评分院校的cosine兴趣度
def user_recommendations_cosine_ratings(user_id, similarities, similarities_cosine):
获取当前用户评分数据
user_ratings = UserScore.objects.filter(user_id=user_id).values('school_id', 'score')
user_ratings_school_id = [user_rating['school_id'] for user_rating in user_ratings]
根据相似度值为用户推荐物品
recommendations_cosine = {} 定义字典存放物品id和物品相似度
邻居用户已评分的学校中目标用户未评分的学校
for school_id in UserScore.objects.filter(user_id__in=similarities).exclude(
school_id__in=user_ratings_school_id).values_list('school_id', flat=True).distinct():
获取评价了当前物品的用户和评分数据
item_ratings = UserScore.objects.filter(school_id=school_id).values('user_id', 'score')
print("item_ratings:", item_ratings)
初始化一个空列表
weighted_scores = []
遍历 item_ratings 中的每一条记录
for rating in item_ratings:
如果该评分记录对应的用户在 similarities 字典中,则计算该评分记录对该物品的权重得分
if rating['user_id'] in similarities_cosine:
获取该评分记录对应用户与目标用户的相似度
similarity = similarities_cosine[rating['user_id']]
计算该评分记录对该物品的权重得分
weighted_score = similarity * rating['score']
将该权重得分添加到列表中
weighted_scores.append(weighted_score)
numerator = sum(weighted_scores)
denominator = sum(similarities_cosine.values())
if denominator > 0:
recommendations_cosine[school_id] = round(numerator / denominator, 2)
print("邻居用户已评分的学校中目标用户未评分的学校:", UserScore.objects.filter(user_id__in=similarities).exclude(
school_id__in=user_ratings_school_id).values_list('school_id', flat=True).distinct())
print("基于用户评分的兴趣度得分情况:", recommendations_cosine)
return recommendations_cosine
补充推荐结果
def recommendations_supply(user_id, top_items: [tuple], top_n):
print("top_items:", top_items)
user_ratings = UserScore.objects.filter(user_id=user_id).values('school_id', 'score')
user_ratings_school_id = [user_rating['school_id'] for user_rating in user_ratings]
获取当前用户的收藏数据
user_collections = UserCollection.objects.filter(user_id=user_id).values('school_id', 'collection')
获取当前用户收藏的学校id
user_collections_school_id = [user_collection['school_id'] for user_collection in user_collections]
if len(top_items) < top_n:
rest = top_n - len(top_items)
exists_school_id = list(
[top_item[0] for top_item in top_items]) + user_ratings_school_id + user_collections_school_id
rest_id = set()
while len(rest_id) < rest:
random_id = random.randint(1, 855)
if random_id not in exists_school_id:
rest_id.add(random_id)
recommendations_id = [item[0] for item in top_items] + list(rest_id)
else:
recommendations_id = [item[0] for item in top_items][:top_n]
return recommendations_id
def user_based_recommend(request, default_similarity_jaccard=0, default_similarity_cosine=0, alpha=10):
alpha_user = request.GET.get('alpha_user', '')
if alpha_user != '':
alpha_user = int(float(alpha_user))
if 0 <= alpha_user <= 10:
alpha = alpha_user
elif alpha_user < 0:
alpha_user = 0
elif alpha_user > 10:
alpha_user = 10
alpha = alpha / 10
print("推荐依据:评分情况:{0},收藏情况:{1}".format(alpha, 1 - alpha))
top_n = 12
获取当前用户id
user_id = list(request.session.values())[0].get('id')
similarities_cosine = user_cosine_similarity_ratings(user_id, default_similarity_cosine=default_similarity_cosine)
similarities_jaccard = user_jaccard_similarity_collections(user_id,
default_similarity_jaccard=default_similarity_jaccard)
print("similarities_cosine:", similarities_cosine)
print("similarity_jaccard:", similarities_jaccard)
similarities = alpha * MyDict(similarities_cosine) + (1 - alpha) * MyDict(similarities_jaccard)
print("similarities:", similarities)
测试:打印基于用户评分的用户相似度矩阵:
print("基于用户评分的用户相似度矩阵:")
print("user_id:", [i for i in similarities_cosine])
print("similarity:", [round(i, 2) for i in similarities_cosine.values()])
测试:打印基于用户收藏的用户相似度矩阵:
print("基于用户收藏的用户相似度矩阵:")
print("user_id:", [i for i in similarities_jaccard])
print("similarity:", [round(i, 2) for i in similarities_jaccard.values()])
根据相似度值为用户推荐物品
打印推荐字典
recommendations_cosine = user_recommendations_cosine_ratings(user_id=user_id, similarities=similarities,
similarities_cosine=similarities_cosine)
recommendations_jaccard = user_recommendations_jaccard_collections(user_id=user_id, similarities=similarities,
similarities_jaccard=similarities_jaccard)
print("当alpha=0.5时基于评分的兴趣度得分情况:\n", recommendations_cosine)
print("当alpha=0.5时基于收藏的兴趣度得分情况:\n", recommendations_jaccard)
测试:打印目标用户对于邻居用户中未评分学校的兴趣度得分
recommendations = alpha * MyDict(recommendations_cosine) + (1 - alpha) * MyDict(recommendations_jaccard)
recommendations = dict(filter(lambda item: item[1] > 0, recommendations.items()))
print("当alpha=0.5时的加权兴趣度得分情况:\n", recommendations)
返回前 top_n 个物品
top_items = sorted(recommendations.items(), key=lambda x: x[1], reverse=True)
print("Top items:", top_items)
如果返回的数量不够top_n,就去随机补充一些没有被推荐和没有被当前用户评分过的学校id,补充至top_n个,返回top_n个被推荐学校的id
如果够,直接返回top_n个被推荐学校的id
recommendations_id = recommendations_supply(user_id=user_id, top_items=top_items, top_n=top_n)
从数据库中根据id找到被推荐的学校,打乱顺序返回
recommended_schools = models.School.objects.filter(id__in=recommendations_id).order_by('?')
不打乱顺序,得分较高的排在前面
recommended_schools = models.School.objects.filter(id__in=[item[0] for item in top_items])
2.实例化分页对象
page_object = Pagination(request, recommended_schools, page_size=12)
context = {
"alpha": alpha_user,
"a5": "active",
"title": "基于用户推荐",
"link": "https://yz.chsi.com.cn/",
"recommended_schools": page_object.page_queryset,
"page_string": page_object.html() 生成页码
}
return render(request, 'recommend_base.html', context)
def user_based_recommend_ratings(request, default_similarity=0):
top_n = 12
获取当前用户id
user_id = list(request.session.values())[0].get('id')
获取当前用户评分数据
user_ratings = UserScore.objects.filter(user_id=user_id).values('school_id', 'score')
获取当前用户评分的学校id
user_ratings_school_id = [user_rating['school_id'] for user_rating in user_ratings]
获取当前用户评分学校的评分情况:(school_id,score)
user_ratings_school = [(user_rating['school_id'], user_rating['score']) for user_rating in user_ratings]
print("目标用户评分情况:")
print(user_ratings_school)
测试:打印所有用户评分信息
print("所有用户评分信息:")
all_user_score = UserScore.objects.filter().order_by('user_id')
print("user_id"+'\t\t'+"school_id"+"\t\t\t\t"+"score")
for user in all_user_score:
print(str(user.user_id) + "\t\t\t" + str(user.school)+"\t\t\t\t" + str(user.score))
测试:构造用户评分矩阵
print("用户评分矩阵:")
print("user_id" + "\t" + "score_list")
构造当前用户评分向量:user_rating_vector
user_rating_vector = [0 for i in range(999)]
for school_id, score in user_ratings_school:
user_rating_vector[school_id] = score
user_rating_vector[0] = user_id
print(user_rating_vector)
计算所有用户的相似度:如果两用户之间没有共同评分的学校,则相似度为0
similarities = {} 定义字典来存放与当前用户相似用户的id和相似度
print("邻居用户评分情况:")
for user in User.objects.exclude(id=user_id):
获取当前用户与其他用户共同评价的物品的评分数据
ratings = user.userscores.filter(school_id__in=user_ratings_school_id).values('school_id', 'score')
if ratings: 如果当前用户与该用户有共同评分的学校,则计算当前用户与该用户的相似度,这里使用余弦相似度
获取该用户所有的评分学校的评分情况:(school_id,score)
ratings = user.userscores.filter().values('school_id', 'score')
ratings_school = [(rating['school_id'], rating['score']) for rating in ratings]
print(ratings_school)
构造该用户评分向量:rating_vector
rating_vector = [0 for i in range(999)]
for school_id, score in ratings_school:
rating_vector[school_id] = score
rating_vector[0] = user.id
print(rating_vector)
计算两用户之间的余弦相似度
similarity = cosine_similarity(user_rating_vector, rating_vector)
if similarity > default_similarity:
similarities[user.id] = similarity
打印相似度字典
print("Similarities:", similarities)
测试:打印用户相似度矩阵
print("用户相似度矩阵:")
print("用户id:", [round(i,2) for i in similarities])
print("相似度:",[round(i,2) for i in similarities.values()])
根据相似度值为用户推荐物品
recommendations = {} 定义字典存放物品id和物品相似度
print("邻居用户中目标用户未评分的学校:",UserScore.objects.filter(user_id__in=similarities).exclude(
school_id__in=user_ratings_school_id).values_list('school_id', flat=True).distinct())
for school_id in UserScore.objects.filter(user_id__in=similarities).exclude(
school_id__in=user_ratings_school_id).values_list('school_id', flat=True).distinct():
获取当前物品被评价的用户和评分数据
item_ratings = UserScore.objects.filter(school_id=school_id).values('user_id', 'score')
print("item_ratings:", item_ratings)
初始化一个空列表
weighted_scores = []
遍历 item_ratings 中的每一条记录
for rating in item_ratings:
如果该评分记录对应的用户在 similarities 字典中,则计算该评分记录对该物品的权重得分
if rating['user_id'] in similarities:
获取该评分记录对应用户与目标用户的相似度
similarity = similarities[rating['user_id']]
计算该评分记录对该物品的权重得分
weighted_score = similarity * rating['score']
将该权重得分添加到列表中
weighted_scores.append(weighted_score)
numerator = sum(weighted_scores)
denominator = sum(similarities.values())
if denominator > 0:
recommendations[school_id] = round(numerator / denominator, 2)
打印推荐字典
print("Recommendations:", recommendations)
测试:打印目标用户对于邻居用户中未评分学校的兴趣度得分
print("兴趣度得分情况:",recommendations)
返回前 top_n 个物品
top_items = sorted(recommendations.items(), key=lambda x: x[1], reverse=True)
print("Top items:", top_items)
如果返回的数量不够top_n,就去随机补充一些没有被推荐和没有被当前用户评分过的学校id,补充至top_n个
if len(top_items) < top_n:
rest = top_n - len(top_items)
exists_school_id = list(recommendations.keys()) + user_ratings_school_id
rest_id = set()
while len(rest_id) < rest:
random_id = random.randint(1, 855)
if random_id not in exists_school_id:
rest_id.add(random_id)
recommendations_id = [item[0] for item in top_items] + list(rest_id)
else:
recommendations_id = [item[0] for item in top_items][:12]
从数据库中根据id找到被推荐的学校
recommended_schools = models.School.objects.filter(id__in=recommendations_id).order_by('?')
2.实例化分页对象
page_object = Pagination(request, recommended_schools, page_size=12)
context = {
"a5": "active",
"title": "基于用户推荐",
"link": "https://yz.chsi.com.cn/",
"recommended_schools": page_object.page_queryset,
"page_string": page_object.html() 生成页码
}
return render(request, 'recommend_base.html', context)
def user_based_recommend(request):
top_n = 12
获取当前用户id
user_id = list(request.session.values())[0].get('id')
获取当前用户评分数据
user_ratings = UserScore.objects.filter(user_id=user_id).values('school_id', 'score')
获取当前用户评分的学校id
user_ratings_school_id = [user_rating['school_id'] for user_rating in user_ratings]
user_ratings_school = [(user_rating['school_id'],user_rating['score']) for user_rating in user_ratings]
print(user_ratings_school)
获取当前用户评分的学校分数
构造当前用户评分向量:
user_rating_vector = [ 0 for i in range(1000)]
for school_id,score in user_ratings_school:
user_rating_vector[school_id] = score
计算所有用户的相似度:如果两用户之间没有共同评分的学校,则相似度为0
similarities = {}
for user in User.objects.exclude(id=user_id):
获取当前用户与其他用户共同评价的物品的评分数据
ratings = user.userscores.filter(school_id__in=user_ratings_school_id).values('school_id','score')
print("{0}:{1}".format(user, ratings))
if ratings:如果当前用户与该用户有共同评分的学校,则计算当前用户与该用户的相似度,这里使用余弦相似度
构造该用户评分向量:
ratings_school = [(rating['school_id'], rating['score']) for rating in ratings]
rating_vector = [0 for i in range(1000)]
for school_id, score in ratings_school:
rating_vector[school_id] = score
print("当前用户:",user_rating_vector)
print("该用户:",rating_vector)
similarity = cosine_similarity(user_rating_vector, rating_vector)
similarities[user.id] = similarity
打印相似度字典
print("Similarities:", similarities)
根据相似度值为用户推荐物品
recommendations = {}
for school_id in UserScore.objects.filter(user_id__in=similarities.keys()).exclude(
school_id__in=user_ratings_school_id).values_list('school_id', flat=True).distinct():
获取当前物品被评价的用户和评分数据
print(school_id)
item_ratings = UserScore.objects.filter(school_id=school_id).values('user_id', 'score')
print("item_ratings:", item_ratings)
初始化一个空列表
weighted_scores = []
遍历 item_ratings 中的每一条记录
for rating in item_ratings:
如果该评分记录对应的用户在 similarities 字典中,则计算该评分记录对该物品的权重得分
if rating['user_id'] in similarities:
获取该评分记录对应用户与目标用户的相似度
similarity = similarities[rating['user_id']]
计算该评分记录对该物品的权重得分
weighted_score = similarity * rating['score']
将该权重得分添加到列表中
weighted_scores.append(weighted_score)
numerator = sum([similarities[user_id] * score for user_id, score in item_ratings if user_id in similarities])
numerator = sum(weighted_scores)
print("numerator:", numerator)
denominator = sum([similarities[user_id] for user_id in similarities])
denominator = sum(similarities.values())
print("denominator:", denominator)
if denominator > 0:
recommendations[school_id] = numerator / denominator
打印推荐字典
print("Recommendations:", recommendations)
返回前 top_n 个物品
top_items = sorted(recommendations.items(), key=lambda x: x[1], reverse=True)[:top_n]
top_items = sorted(recommendations.items(), key=lambda x: x[1], reverse=True)
print("top_items", top_items)
recommended_schools = models.School.objects.filter(id__in=[item[0] for item in top_items]).order_by("?")[:top_n]
recommended_schools = models.School.objects.filter(id__in=[item[0] for item in top_items])
print(recommended_schools)
2.实例化分页对象
page_object = Pagination(request, recommended_schools, page_size=12)
context = {
"title": "基于用户推荐",
"link": "https://yz.chsi.com.cn/",
"recommended_schools": page_object.page_queryset,
"page_string": page_object.html() 生成页码
}
return render(request, 'recommend_base.html', context)
注释调试版
def user_based_recommend(request, default_similarity_jaccard=0, default_similarity_cosine=0, alpha=1):
top_n = 12
获取当前用户id
user_id = list(request.session.values())[0].get('id')
获取当前用户评分数据
user_ratings = UserScore.objects.filter(user_id=user_id).values('school_id', 'score')
获取当前用户收藏数据
user_collections = UserCollection.objects.filter(user_id=user_id).values('school_id', 'collection')
获取当前用户评分的学校id
user_ratings_school_id = [user_rating['school_id'] for user_rating in user_ratings]
获取当前用户收藏的学校id
user_collections_school_id = [user_collection['school_id'] for user_collection in user_collections]
获取当前用户评分学校的评分情况:(school_id,score)
user_ratings_school = [(user_rating['school_id'], user_rating['score']) for user_rating in user_ratings]
获取当前用户的收藏情况:(school_id,1)
user_collections_school = [(user_collection['school_id'], user_collection['collection']) for user_collection in
user_collections]
print("目标用户评分情况:")
print(user_ratings_school)
测试:打印所有用户评分信息
print("所有用户评分信息:")
all_user_score = UserScore.objects.filter().order_by('user_id')
print("user_id"+'\t\t'+"school_id"+"\t\t\t\t"+"score")
for user in all_user_score:
print(str(user.user_id) + "\t\t\t" + str(user.school)+"\t\t\t\t" + str(user.score))
测试:构造用户评分矩阵
print("用户评分矩阵:")
print("user_id" + "\t" + "score_list")
构造当前用户评分向量:user_rating_vector
user_rating_vector = [0 for i in range(999)]
for school_id, score in user_ratings_school:
user_rating_vector[school_id] = score
构造当前用户收藏向量
user_collection_vector = [0 for i in range(999)]
for school_id in user_collections_school_id:
user_collection_vector[school_id] = 1
user_rating_vector[0] = user_id
print(user_rating_vector)
计算所有用户的相似度:如果两用户之间没有共同评分的学校,则相似度为0
similarities_jaccard = {} 定义字典来存放与当前用户相似用户的id和相似度
print("邻居用户评分情况:")
for user in User.objects.exclude(id=user_id):
获取当前用户与其他用户共同收藏的物品的id
collections = user.usercollections.filter(school_id__in=user_ratings_school_id).values('school_id')
if collections: 如果当前用户与该用户有共同收藏的学校,则计算当前用户与该用户的相似度,这里使用杰卡德
获取该用户所有的收藏情况:(school_id,score)
collections = user.usercollections.filter().values('school_id')
collections_school_id = [(collection['school_id']) for collection in collections]
print(ratings_school)
构造该用户收藏向量:collection_vector
collection_vector = [0 for i in range(999)]
for school_id in collections_school_id:
collection_vector[school_id] = 1
rating_vector[0] = user.id
print(rating_vector)
计算两用户之间的杰卡德相似度
similarity_jaccard = jaccard_similarity(user_rating_vector, collection_vector)
if similarity_jaccard > default_similarity_jaccard:
similarities_jaccard[user.id] = similarity_jaccard
similarities_cosine = {}
for user in User.objects.exclude(id=user_id):
获取当前用户与其他用户共同评价的物品的评分数据
ratings = user.userscores.filter(school_id__in=user_ratings_school_id).values('school_id', 'score')
if ratings: 如果当前用户与该用户有共同评分的学校,则计算当前用户与该用户的相似度,这里使用余弦相似度
获取该用户所有的评分学校的评分情况:(school_id,score)
ratings = user.userscores.filter().values('school_id', 'score')
ratings_school = [(rating['school_id'], rating['score']) for rating in ratings]
print(ratings_school)
构造该用户评分向量:rating_vector
rating_vector = [0 for i in range(999)]
for school_id, score in ratings_school:
rating_vector[school_id] = score
rating_vector[0] = user.id
print(rating_vector)
计算两用户之间的余弦相似度
similarity_cosine = cosine_similarity(user_rating_vector, rating_vector)
if similarity_cosine > default_similarity_cosine:
similarities_cosine[user.id] = similarity_cosine
打印相似度字典
print("Similarities:", similarities)
测试:打印用户相似度矩阵
print("用户相似度矩阵:")
print("用户id:", [round(i,2) for i in similarities])
print("相似度:",[round(i,2) for i in similarities.values()])
print("similarities_cosine:", similarities_cosine)
print("similarity_jaccard:", similarities_jaccard)
similarities = alpha * MyDict(similarities_cosine) + (1 - alpha) * MyDict(similarities_jaccard)
print("similarities:", similarities)
根据相似度值为用户推荐物品
recommendations_cosine = {} 定义字典存放物品id和物品相似度
print("邻居用户已评分的学校中目标用户未评分的学校:", UserScore.objects.filter(user_id__in=similarities).exclude(
school_id__in=user_ratings_school_id).values_list('school_id', flat=True).distinct())
邻居用户已评分的学校中目标用户未评分的学校
for school_id in UserScore.objects.filter(user_id__in=similarities).exclude(
school_id__in=user_ratings_school_id).values_list('school_id', flat=True).distinct():
获取评价了当前物品的用户和评分数据
item_ratings = UserScore.objects.filter(school_id=school_id).values('user_id', 'score')
print("item_ratings:", item_ratings)
初始化一个空列表
weighted_scores = []
遍历 item_ratings 中的每一条记录
for rating in item_ratings:
如果该评分记录对应的用户在 similarities 字典中,则计算该评分记录对该物品的权重得分
if rating['user_id'] in similarities_cosine:
获取该评分记录对应用户与目标用户的相似度
similarity = similarities_cosine[rating['user_id']]
计算该评分记录对该物品的权重得分
weighted_score = similarity * rating['score']
将该权重得分添加到列表中
weighted_scores.append(weighted_score)
numerator = sum(weighted_scores)
denominator = sum(similarities_cosine.values())
if denominator > 0:
recommendations_cosine[school_id] = round(numerator / denominator, 2)
recommendations_jaccard = {}
print("邻居用户已收藏的学校中目标用户未收藏的学校:",
UserCollection.objects.filter(user_id__in=similarities).exclude(
school_id__in=user_collections_school_id).values_list('school_id', flat=True).distinct())
邻居用户已收藏的学校中目标用户未收藏的学校
for school_id in UserCollection.objects.filter(user_id__in=similarities).exclude(
school_id__in=user_collections_school_id).values_list('school_id', flat=True).distinct():
获取收藏了当前物品的用户:用户id和收藏情况(collection = 1)
item_collections = UserCollection.objects.filter(school_id=school_id).values('user_id', 'collection')
print("item_ratings:", item_ratings)
初始化一个空列表
weighted_scores = []
遍历 item_ratings 中的每一条记录
for collection in item_collections:
如果该收藏记录对应的用户在 similarities_jaccard 字典中,则计算该收藏记录对该物品的权重得分
if collection['user_id'] in similarities_jaccard:
获取该评分记录对应用户与目标用户的相似度
similarity = similarities_jaccard[collection['user_id']]
计算该评分记录对该物品的权重得分
weighted_score = similarity * collection['collection']
将该权重得分添加到列表中
weighted_scores.append(weighted_score)
numerator = sum(weighted_scores)
denominator = sum(similarities_jaccard.values())
if denominator > 0:
recommendations_jaccard[school_id] = round(numerator / denominator, 2)
打印推荐字典
print("Recommendations_cosine:", recommendations_cosine)
print("Recommendations_jaccard:", recommendations_jaccard)
测试:打印目标用户对于邻居用户中未评分学校的兴趣度得分
recommendations = alpha * MyDict(recommendations_cosine) + (1 - alpha) * MyDict(recommendations_jaccard)
recommendations = dict(filter(lambda item: item[1] > 0, recommendations.items()))
print("兴趣度得分情况:", recommendations)
返回前 top_n 个物品
top_items = sorted(recommendations.items(), key=lambda x: x[1], reverse=True)
print("Top items:", top_items)
如果返回的数量不够top_n,就去随机补充一些没有被推荐和没有被当前用户评分过的学校id,补充至top_n个
if len(top_items) < top_n:
rest = top_n - len(top_items)
exists_school_id = list(recommendations.keys()) + user_ratings_school_id
rest_id = set()
while len(rest_id) < rest:
random_id = random.randint(1, 855)
if random_id not in exists_school_id:
rest_id.add(random_id)
recommendations_id = [item[0] for item in top_items] + list(rest_id)
else:
recommendations_id = [item[0] for item in top_items][:12]
从数据库中根据id找到被推荐的学校
recommended_schools = models.School.objects.filter(id__in=recommendations_id).order_by('?')
2.实例化分页对象
page_object = Pagination(request, recommended_schools, page_size=12)
context = {
"a5": "active",
"title": "基于用户推荐",
"link": "https://yz.chsi.com.cn/",
"recommended_schools": page_object.page_queryset,
"page_string": page_object.html() 生成页码
}
return render(request, 'recommend_base.html', context)
源码获取:
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看主页【专栏名称】或者【用户名】或者顶部的【选题链接】就可以找到我获取项目源码学习啦~🍅
大家点赞、收藏、关注、评论啦 !


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









