










[毕业设计]2023-2024年最新最全计算机专业毕设选题推荐汇总
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人 。
1、项目介绍
Python语言、Flask框架、MySQL数据库、
Echarts可视化、网络爬虫技术、豆瓣电影数据
requests爬虫框架、HTML
(包含文档+源码+部署教程)
2、项目界面
(1)系统首页----数据概况
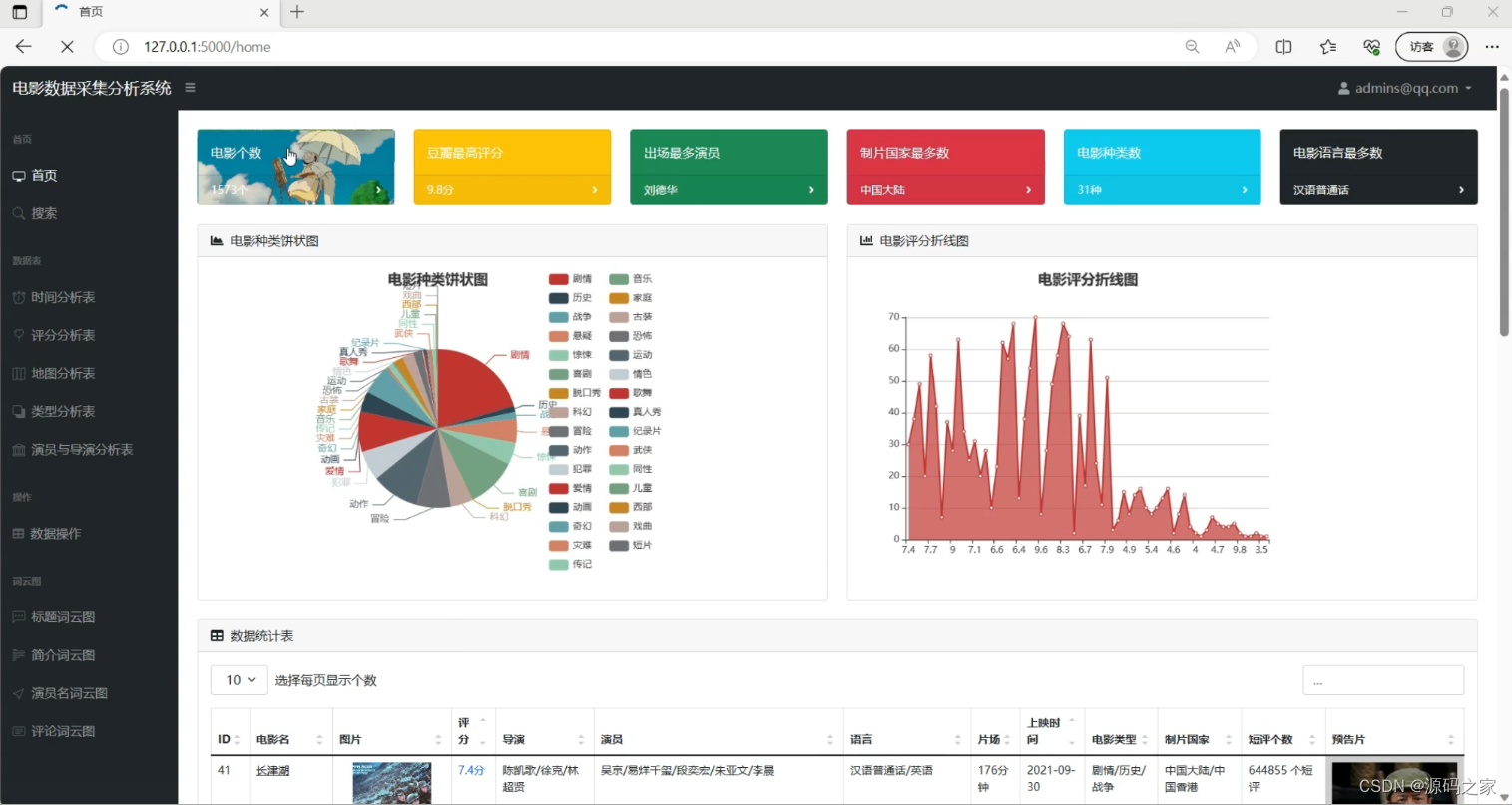
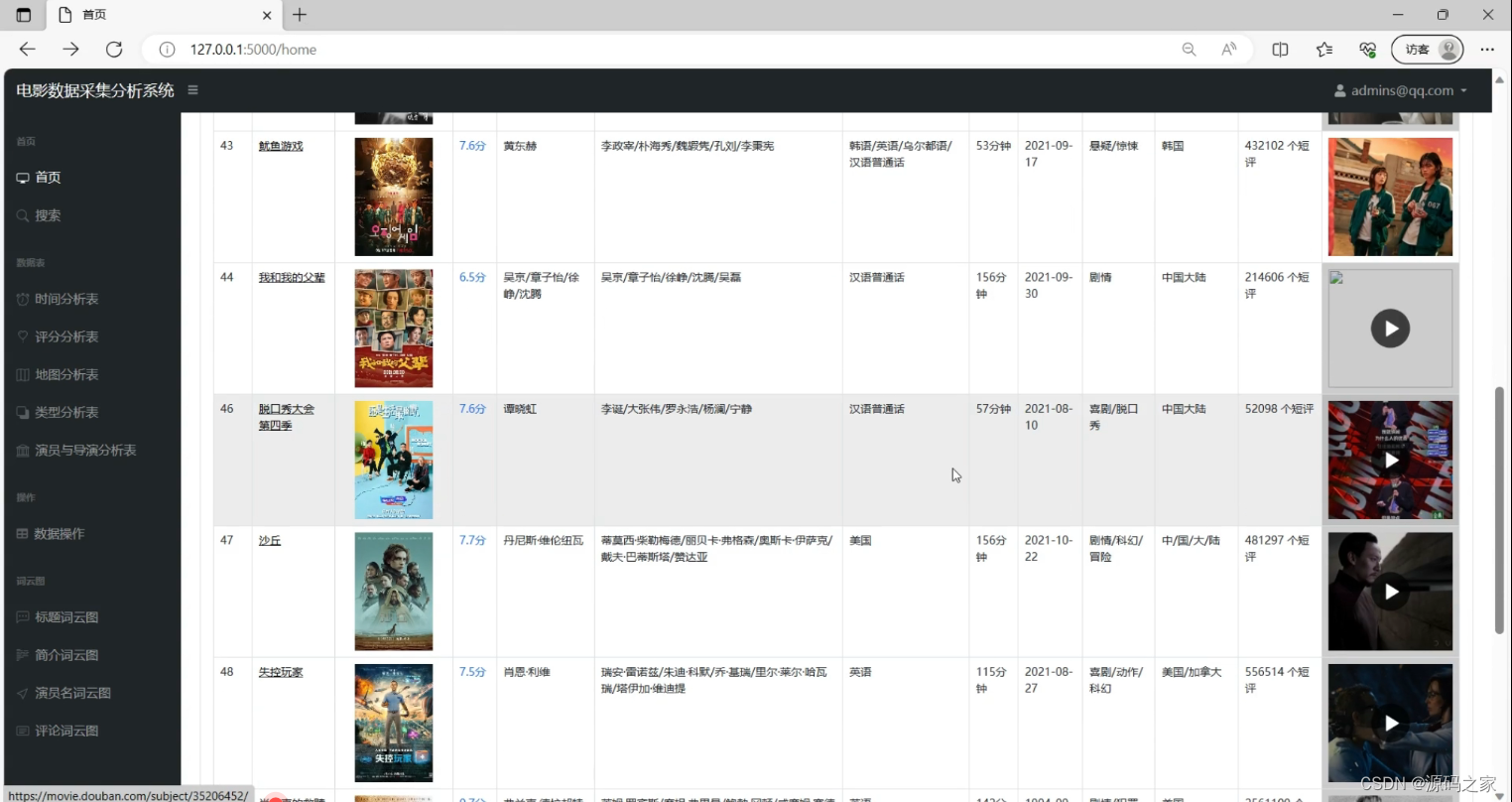
(2)电影数据
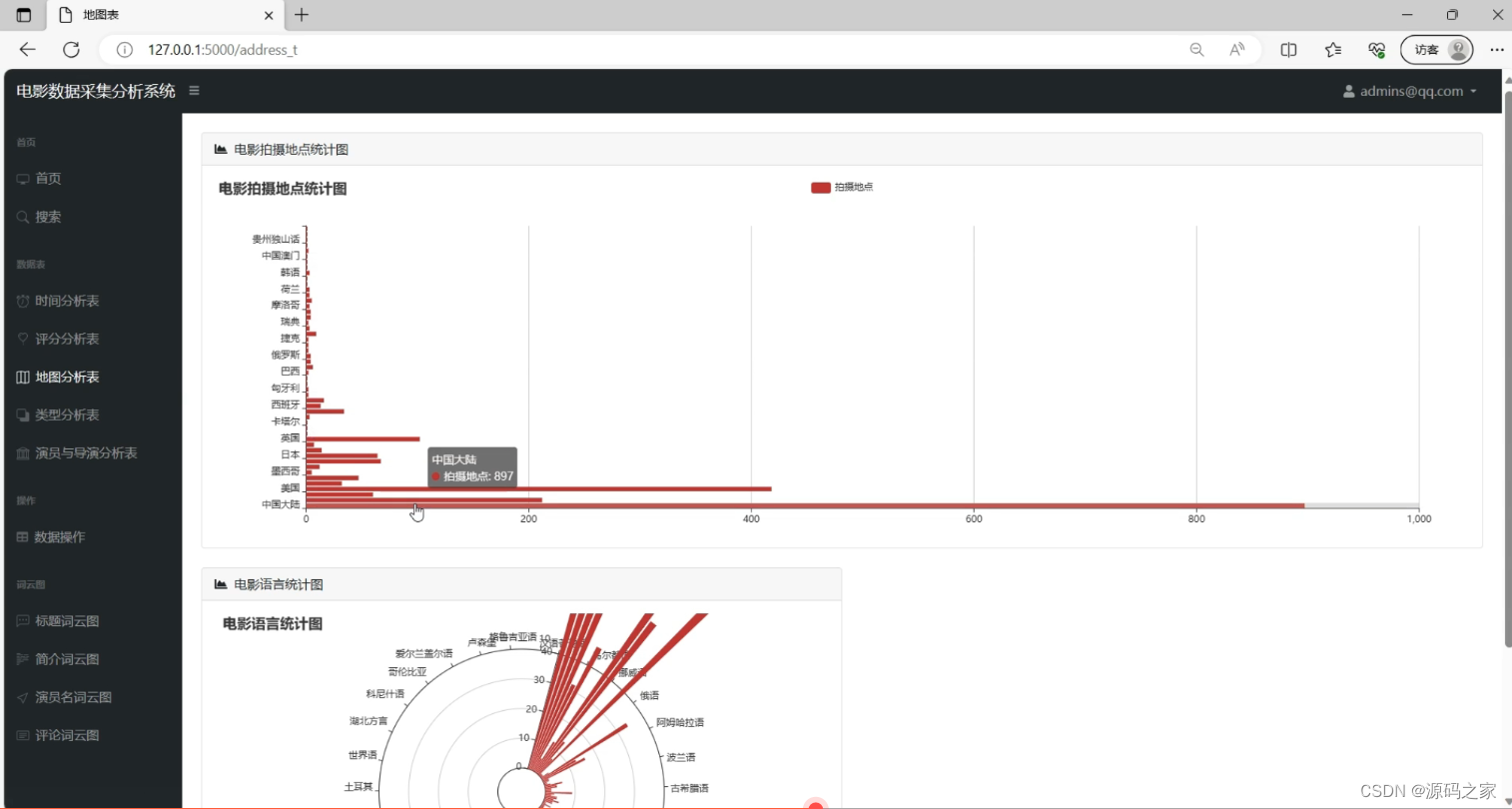
(3)电影拍摄地点分析、电影语言分析
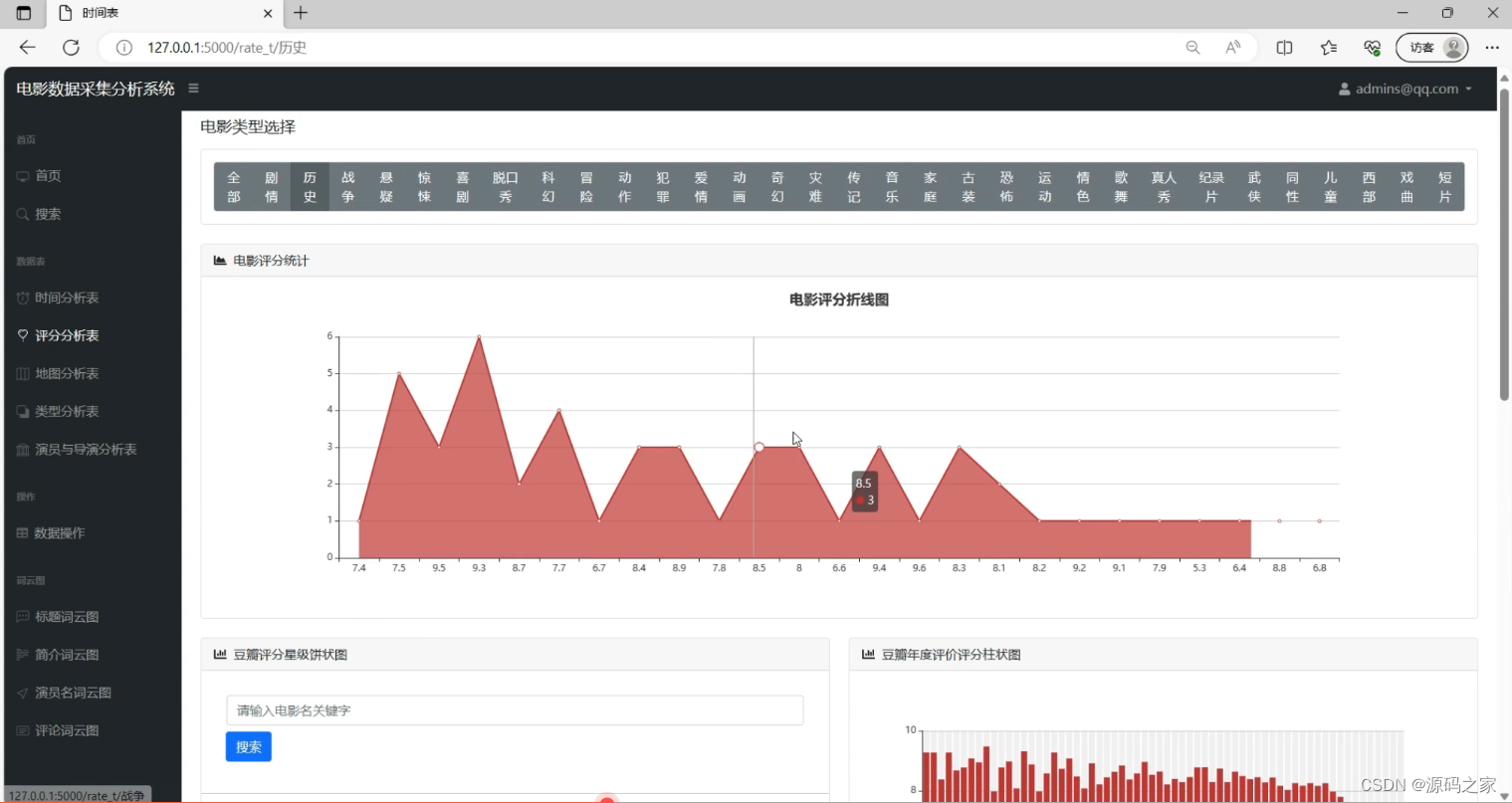
(4)评分分析、豆瓣评分星级、年度评价评分分析
(5)电影时长分布、电影数量统计分析
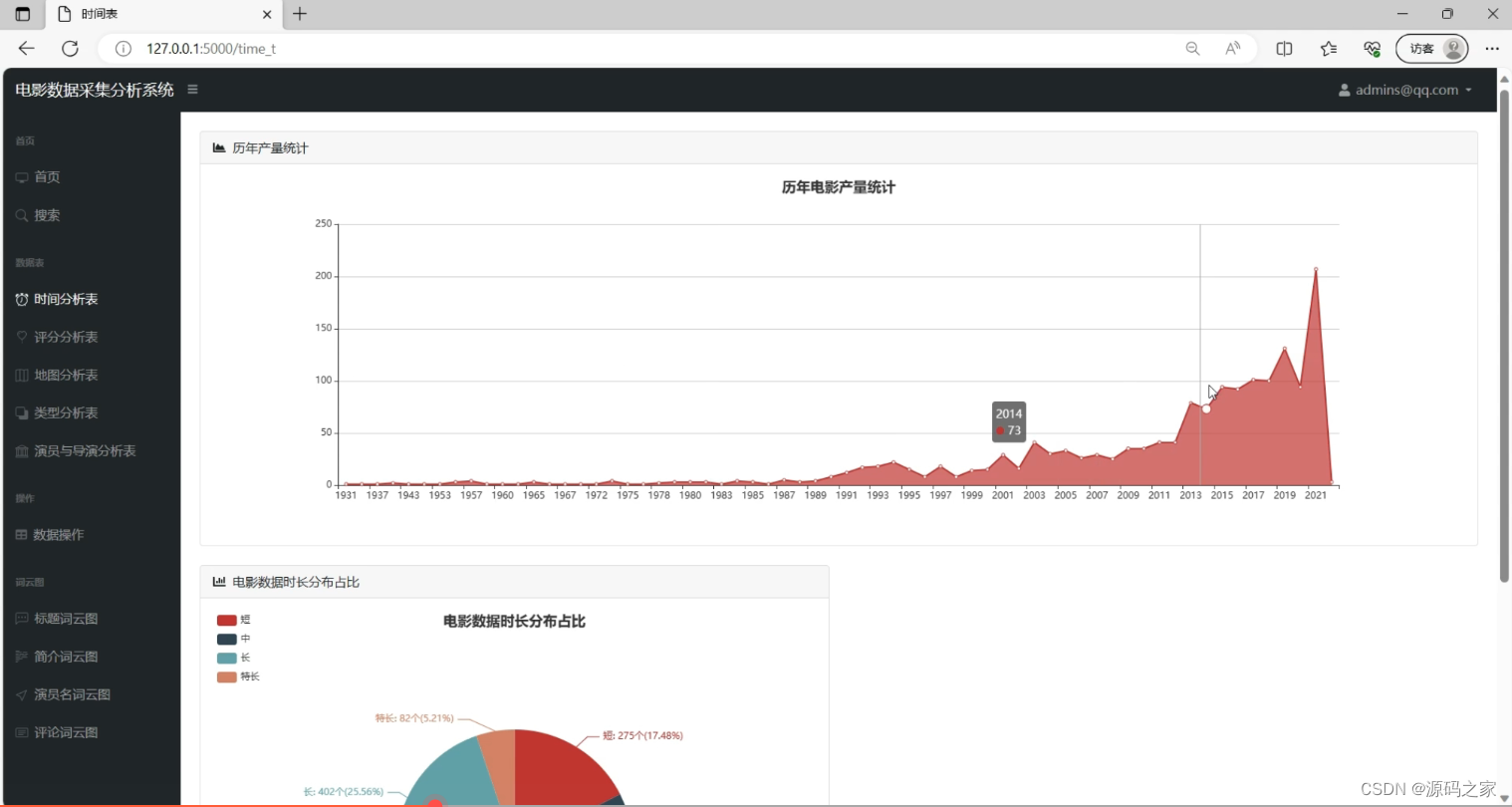
(6)电影类型饼图
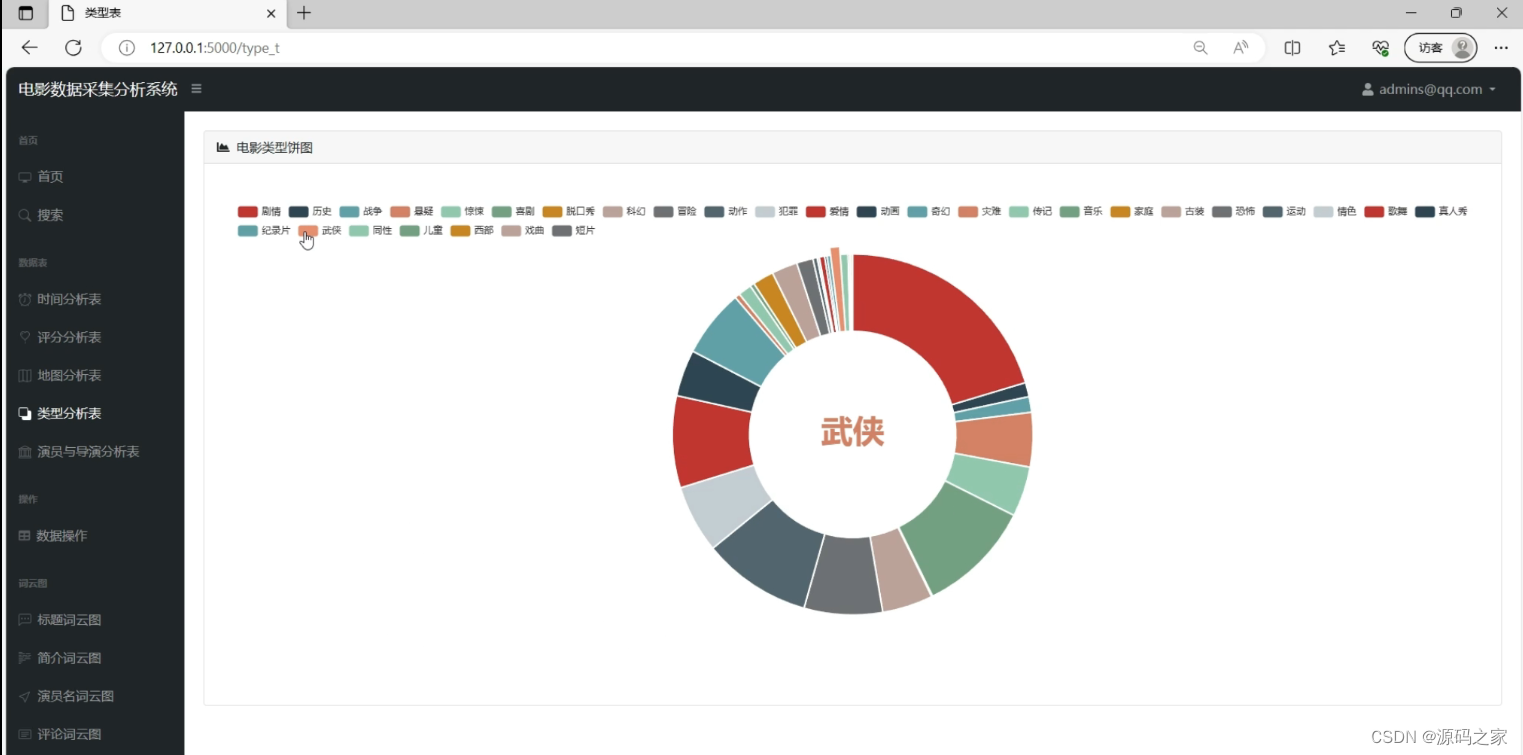
(7)电影数据搜索
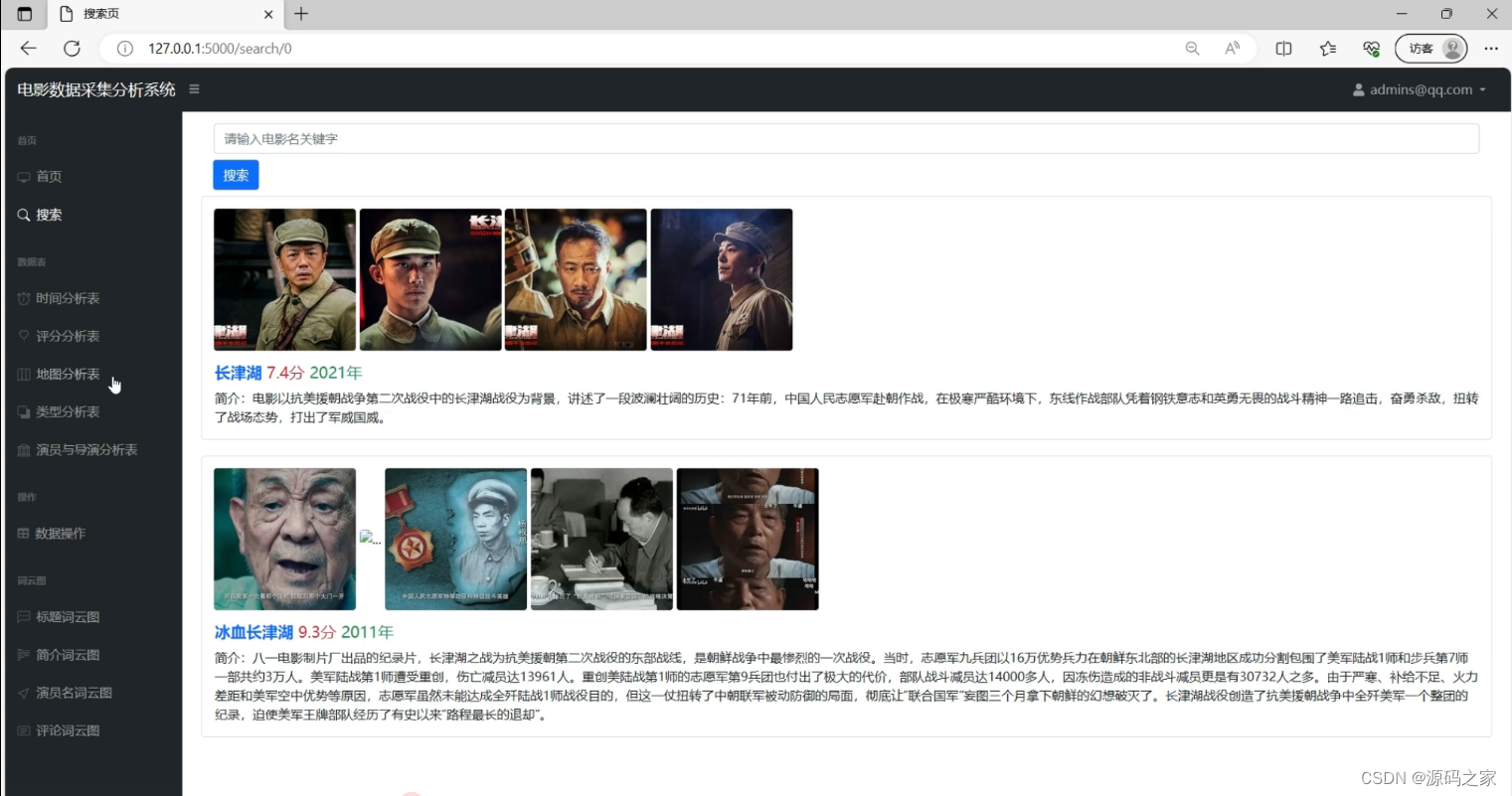
(8)词云图分析
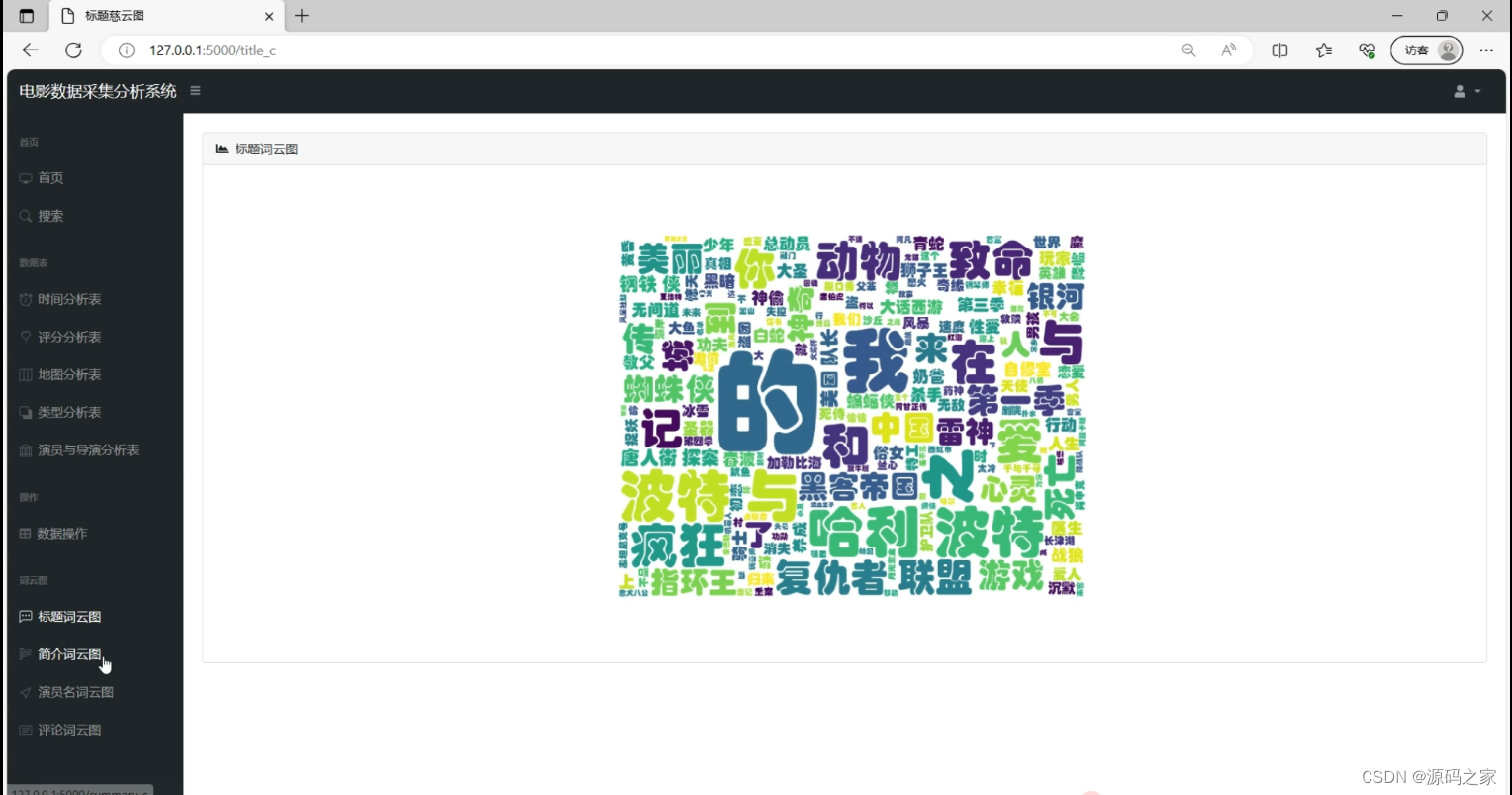
(9)电影数据
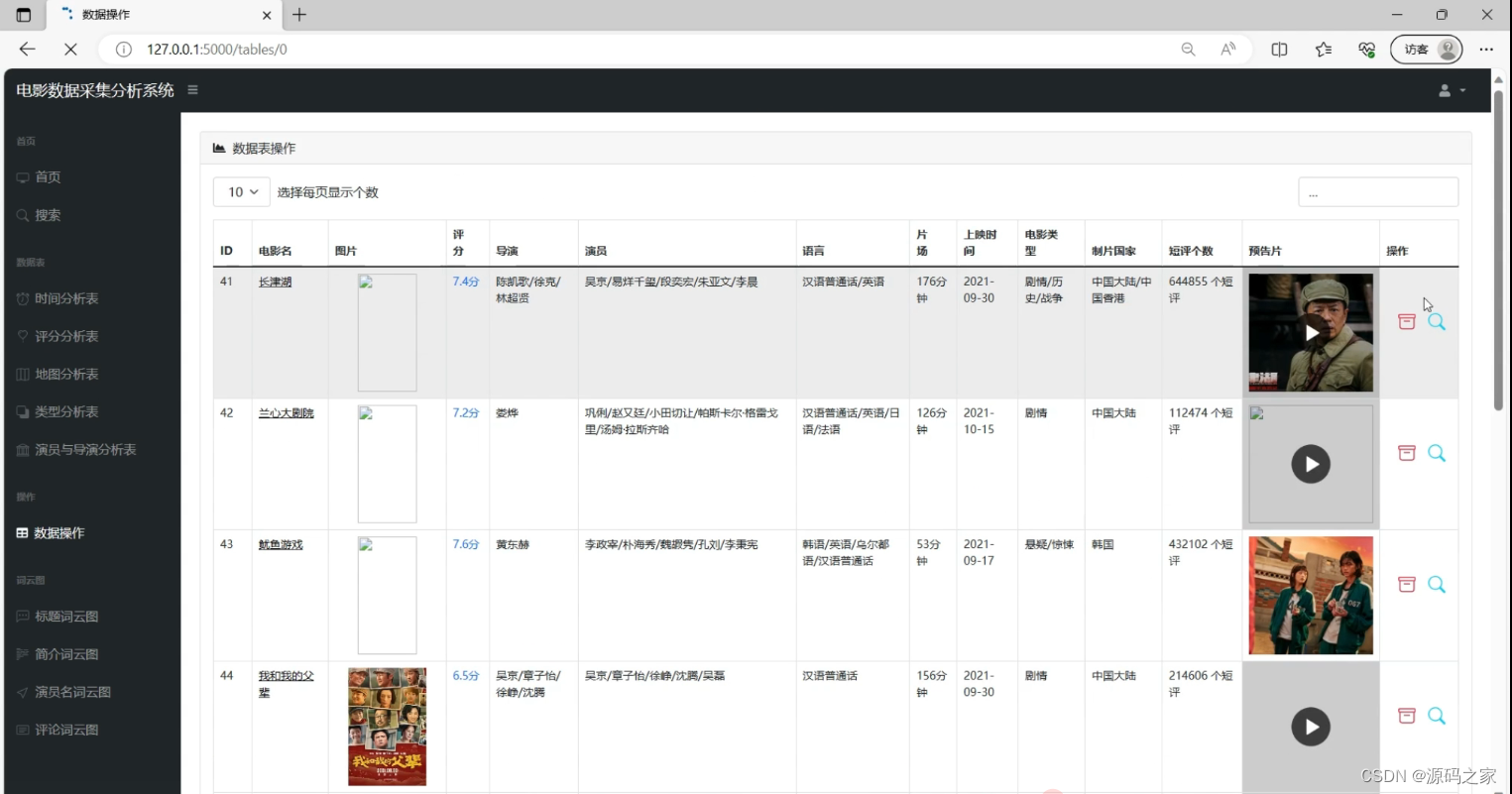
(10)数据采集爬虫
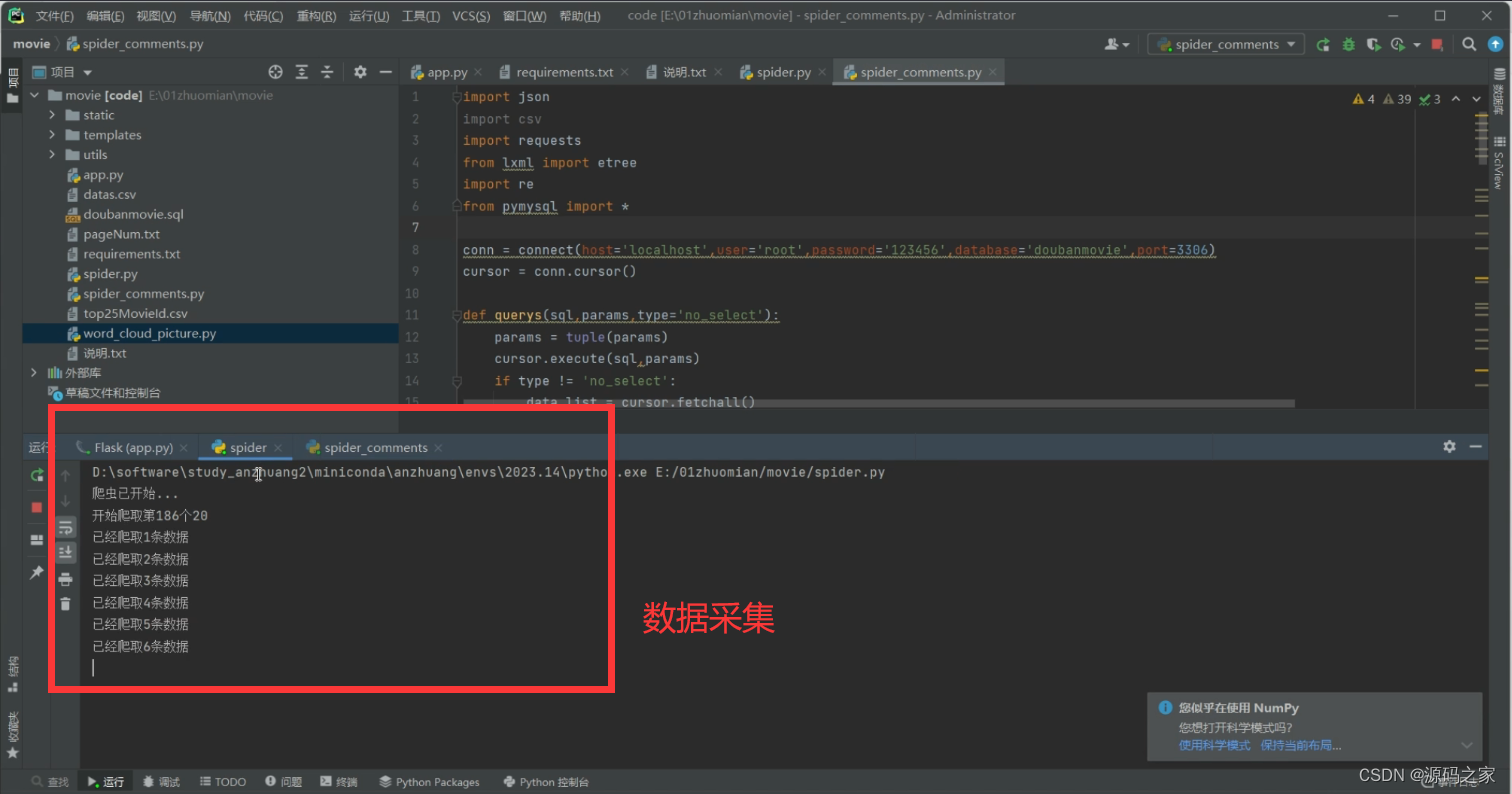
3、部分代码
import json
from flask import Flask,request,render_template,session,redirect
import re
from utils.query import querys
from utils.homeData import *
from utils.timeData import *
from utils.rateData import *
from utils.addressData import *
from utils.typeData import *
from utils.tablesData import *
from utils.actor import *
from word_cloud_picture import get_img
import random
app = Flask(__name__)
app.secret_key = 'This is a app.secret_Key , You Know ?'
@app.route('/')
def every():
return render_template('login.html')
@app.route("/home")
def home():
email = session['email']
allData = getAllData()
maxRate = getMaxRate()
maxCast = getMaxCast()
typesAll = getTypesAll()
maxLang = getMaxLang()
types = getType_t()
row,column = getRate_t()
tablelist = getTableList()
return render_template(
"index.html",
email=email,
dataLen = len(allData),
maxRate=maxRate,
maxCast=maxCast,
typeLen = len(typesAll),
maxLang = maxLang,
types=types,
row=list(row),
column=list(column),
tablelist=tablelist
)
@app.route("/login",methods=['GET','POST'])
def login():
if request.method == 'POST':
request.form = dict(request.form)
def filter_fns(item):
return request.form['email'] in item and request.form['password'] in item
users = querys('select * from user', [], 'select')
login_success = list(filter(filter_fns, users))
if not len(login_success):
return '账号或密码错误'
session['email'] = request.form['email']
return redirect('/home', 301)
else:
return render_template('./login.html')
@app.route("/registry",methods=['GET','POST'])
def registry():
if request.method == 'POST':
request.form = dict(request.form)
if request.form['password'] != request.form['passwordCheked']:
return '两次密码不符'
else:
def filter_fn(item):
return request.form['email'] in item
users = querys('select * from user', [], 'select')
filter_list = list(filter(filter_fn, users))
if len(filter_list):
return '该用户名已被注册'
else:
querys('insert into user(email,password) values(%s,%s)',
[request.form['email'], request.form['password']])
session['email'] = request.form['email']
return redirect('/home', 301)
else:
return render_template('./register.html')
@app.route("/search/<int:searchId>",methods=['GET','POST'])
def search(searchId):
email = session['email']
allData = getAllData()
data = []
if request.method == 'GET':
if searchId == 0:
return render_template(
'search.html',
idData=data,
email=email
)
for i in allData:
if i[0] == searchId:
data.append(i)
return render_template(
'search.html',
data=data,
email=email
)
else:
searchWord = dict(request.form)['searchIpt']
def filter_fn(item):
if item[3].find(searchWord) == -1:
return False
else:
return True
data = list(filter(filter_fn,allData))
return render_template(
'search.html',
data=data,
email=email
)
@app.route("/time_t",methods=['GET','POST'])
def time_t():
email = session['email']
row,column = getTimeList()
moveTimeData = getMovieTimeList()
return render_template(
'time_t.html',
email=email,
row=list(row),
column=list(column),
moveTimeData=moveTimeData
)
@app.route("/rate_t/<type>",methods=['GET','POST'])
def rate_t(type):
email = session['email']
typeAll = getTypesAll()
rows,columns = getMean()
x,y,y1 = getCountryRating()
if type == 'all':
row, column = getRate_t()
else:
row,column = getRate_tType(type)
if request.method == 'GET':
starts,movieName = getStart('长津湖')
else:
searchWord = dict(request.form)['searchIpt']
starts,movieName = getStart(searchWord)
return render_template(
'rate_t.html',
email=email,
typeAll=typeAll,
type=type,
row=list(row),
column=list(column),
starts=starts,
movieName=movieName,
rows = rows,
columns = columns,
x=x,
y=y,
y1=y1
)
@app.route("/address_t",methods=['GET','POST'])
def address_t():
email = session['email']
row,column = getAddressData()
rows,columns = getLangData()
return render_template('address_t.html',row=row,column=column,rows=rows,columns=columns,email=email)
@app.route('/type_t',methods=['GET','POST'])
def type_t():
email = session['email']
result = getMovieTypeData()
return render_template('type_t.html',result=result,type_t=type_t,email=email)
@app.route('/actor_t')
def actor_t():
email = session['email']
x,y = getAllActorMovieNum()
x1,y1 = getAllDirectorMovieNum()
return render_template('actor_t.html',email=email,x=x,y=y,x1=x1,y1=y1)
@app.route("/movie/<int:id>")
def movie(id):
allData = getAllData()
idData = {}
for i in allData:
if i[0] == id:
idData = i
return render_template('movie.html',idData=idData)
@app.route('/tables/<int:id>')
def tables(id):
if id == 0:
tablelist = getTableList()
else:
deleteTableId(id)
tablelist = getTableList()
return render_template('tables.html',tablelist=tablelist)
@app.route('/title_c')
def title_c():
return render_template('title_c.html')
@app.route('/summary_c')
def summary_c():
return render_template('summary_c.html')
@app.route('/casts_c')
def casts_c():
return render_template('casts_c.html')
@app.route('/comments_c',methods=['GET','POST'])
def comments_c():
email = session['email']
if request.method == 'GET':
return render_template('comments_c.html', email=email)
else:
searchWord = dict(request.form)['searchIpt']
randomInt = random.randint(1,10000000)
get_img('commentContent','./static/4.jpg',f'./static/{randomInt}.jpg',searchWord)
return render_template('comments_c.html', email=email,imgSrc=f'{randomInt}.jpg')
@app.before_request
def before_requre():
pat = re.compile(r'^/static')
if re.search(pat,request.path):
return
if request.path == "/login" :
return
if request.path == '/registry':
return
uname = session.get('email')
if uname:
return None
return redirect("/login")
if __name__ == '__main__':
app.run()
4、项目说明
基于Flask电影数据采集可视化系统是一款利用Python的Flask框架,对电影相关数据进行采集、整理和可视化展示的应用系统。以下是该系统的主要介绍:
数据采集:系统利用网络爬虫技术,从电影相关网站上获取电影信息。这些信息包括电影名称、导演、演员、评分、票房、发行日期、类型等。用户可以根据个人需求,设置搜索的关键词、时间范围、地区限制等参数,以获取感兴趣的电影信息。
数据处理:系统对采集到的电影数据进行清洗、整理和转换,以确保数据的准确性和一致性。包括处理缺失值、异常值和重复值,进行数据格式转换等操作。
数据可视化:系统使用Python中的数据可视化库(如Matplotlib、Seaborn等),将电影数据以图表、图形等形式直观地展示出来。包括电影类型分布、票房排行榜、评分分布等。同时,用户可以根据自己的需求进行图表的定制和设置,以满足个性化的展示需求。
用户交互:系统提供友好的用户界面和交互设计,用户可以搜索、排序、过滤,选择不同的时间范围、地区、类型等维度,获取感兴趣的数据和分析结果。用户还可以根据展示效果进行图表的调整和定制。
数据分析:系统还可以利用Python中的数据分析库(如Pandas等),对电影数据进行统计和分析,例如:评分和票房之间的关系,不同类型电影的市场占比,不同导演或演员的平均评分等。这些分析结果可以帮助用户更全面地了解电影市场的状况和变化。
综上所述,基于Flask电影数据采集可视化系统是一款利用Python技术进行开发的应用系统,旨在通过数据可视化和分析提供电影市场的信息和趋势。该系统可以帮助用户更直观地了解电影市场的情况,同时也对电影从业者、研究人员等提供有价值的参考信息。该系统通过友好的用户界面和交互设计,使得用户可针对个人需求进行定制,是一款十分实用的电影数据可视化工具。
源码获取:
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看主页【专栏名称】或者【用户名】或者顶部的【选题链接】就可以找到我获取项目源码学习啦~🍅
大家点赞、收藏、关注、评论啦 、















 4756
4756











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









