










毕业设计:2023-2024年计算机专业毕业设计选题汇总(建议收藏)
毕业设计:2023-2024年最新最全计算机专业毕设选题推荐汇总
🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、项目介绍
技术栈:
Python语言、Flask框架、MySQL数据库、Bootstrap框架、css+js+HTML
天气预测: weather_yuce.py
机器学习——线性回归(Linear Regression) 预测算法
2、项目界面
(1)系统首页
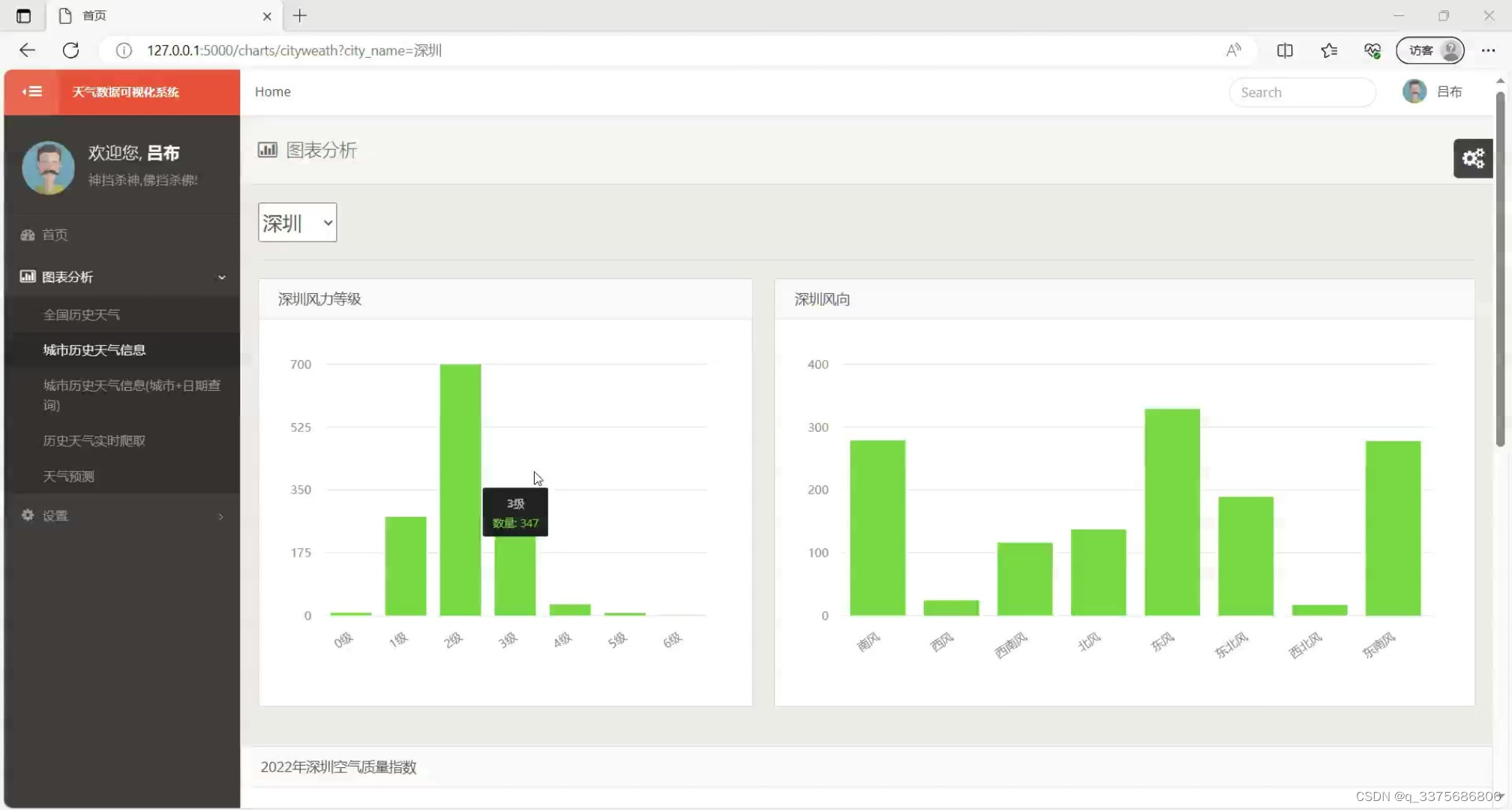
(2)空气质量指数曲线和全国历史天气数据查询

(3)全国风力等级饼状图
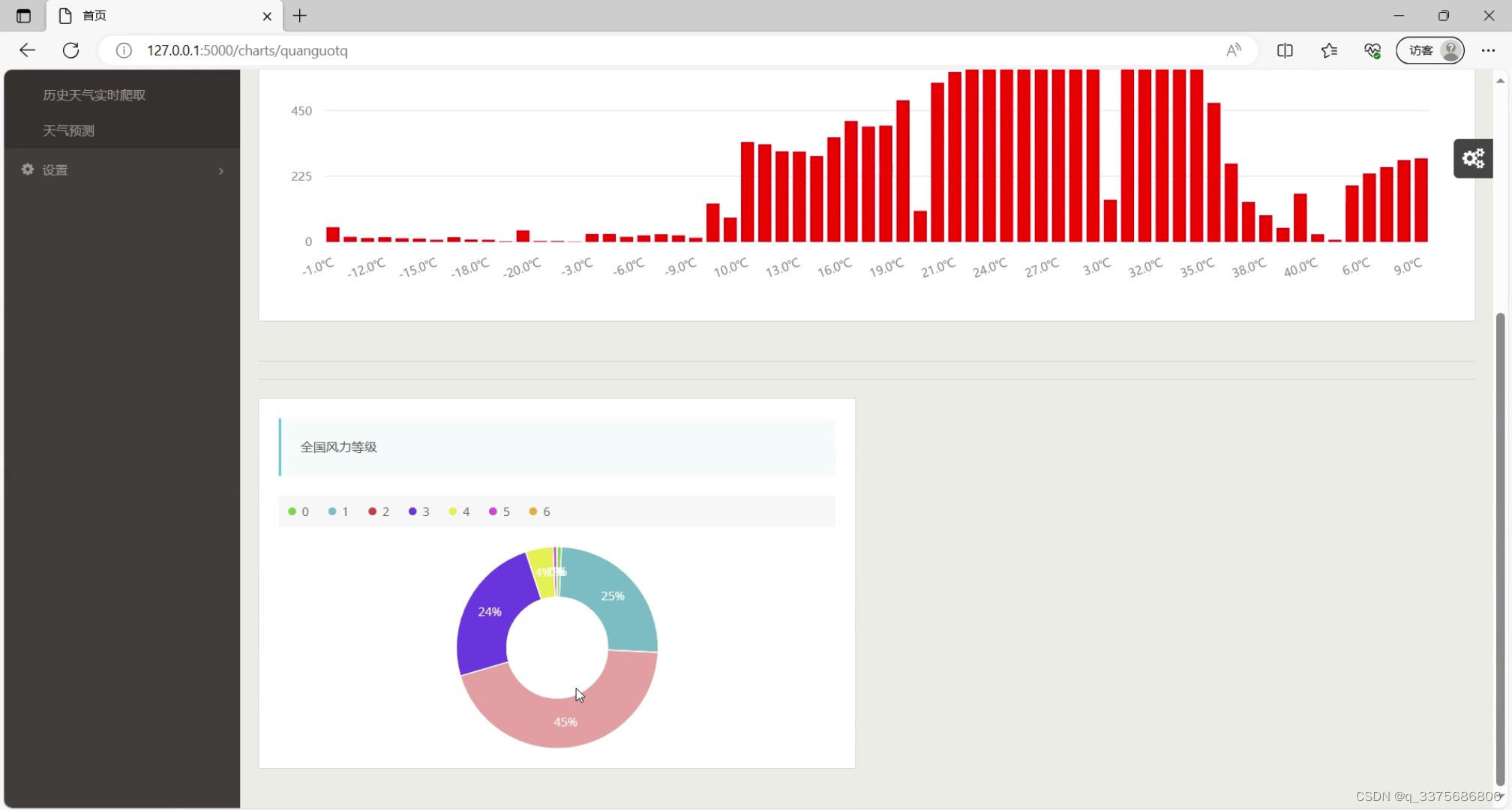
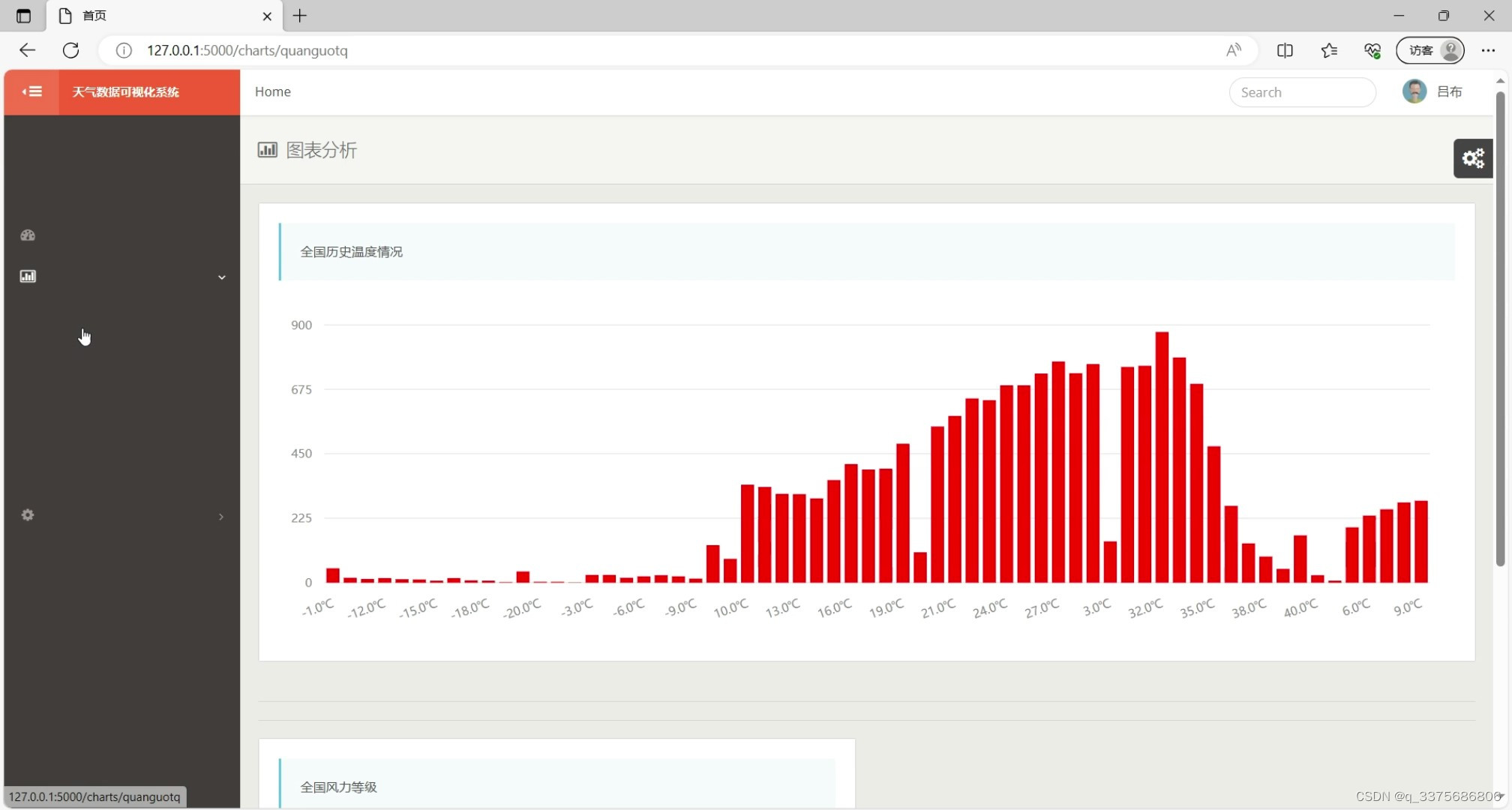
(4)全国历史温度情况柱状图
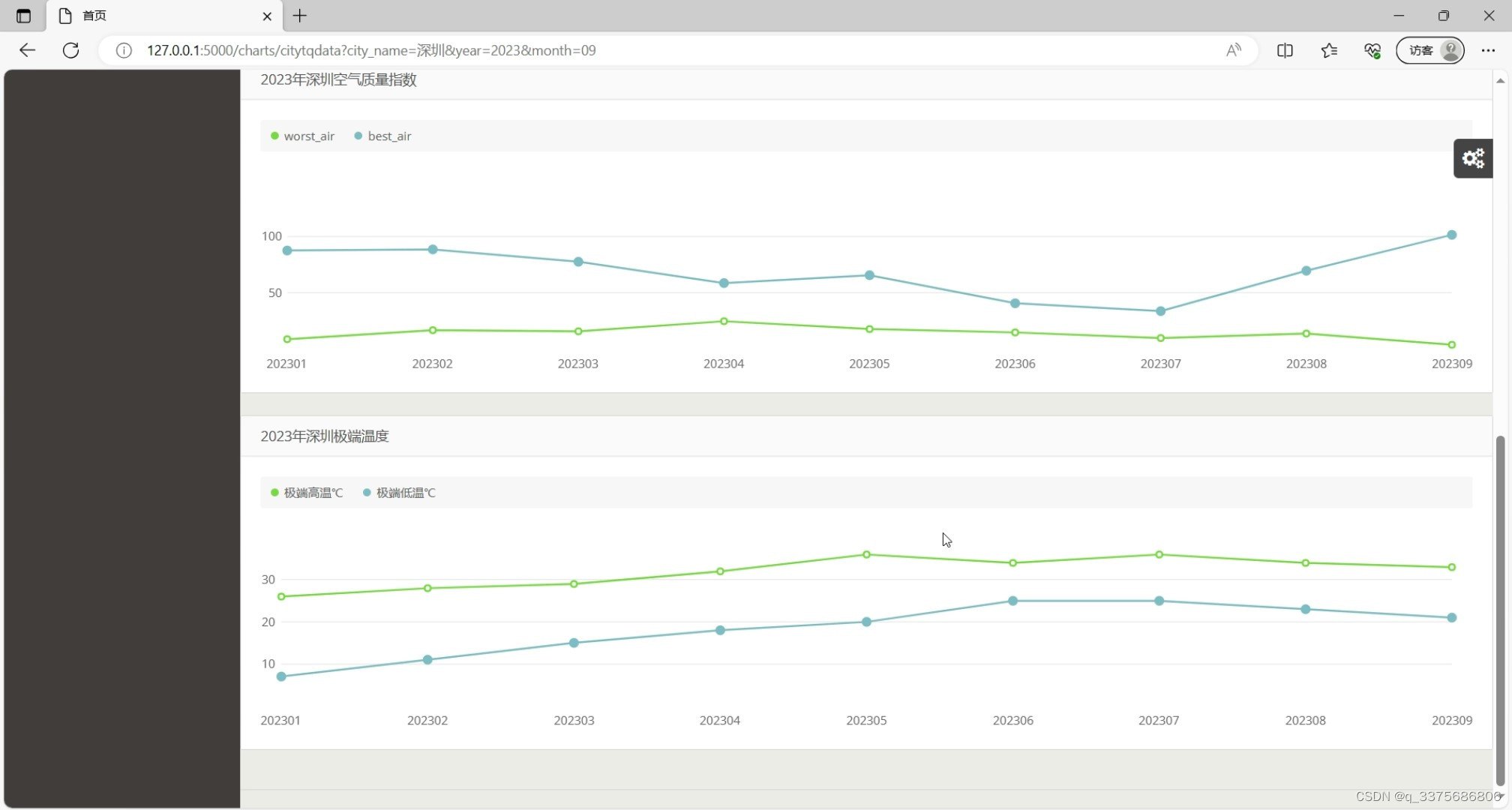
(5)空气质量指数和极端温度曲线图
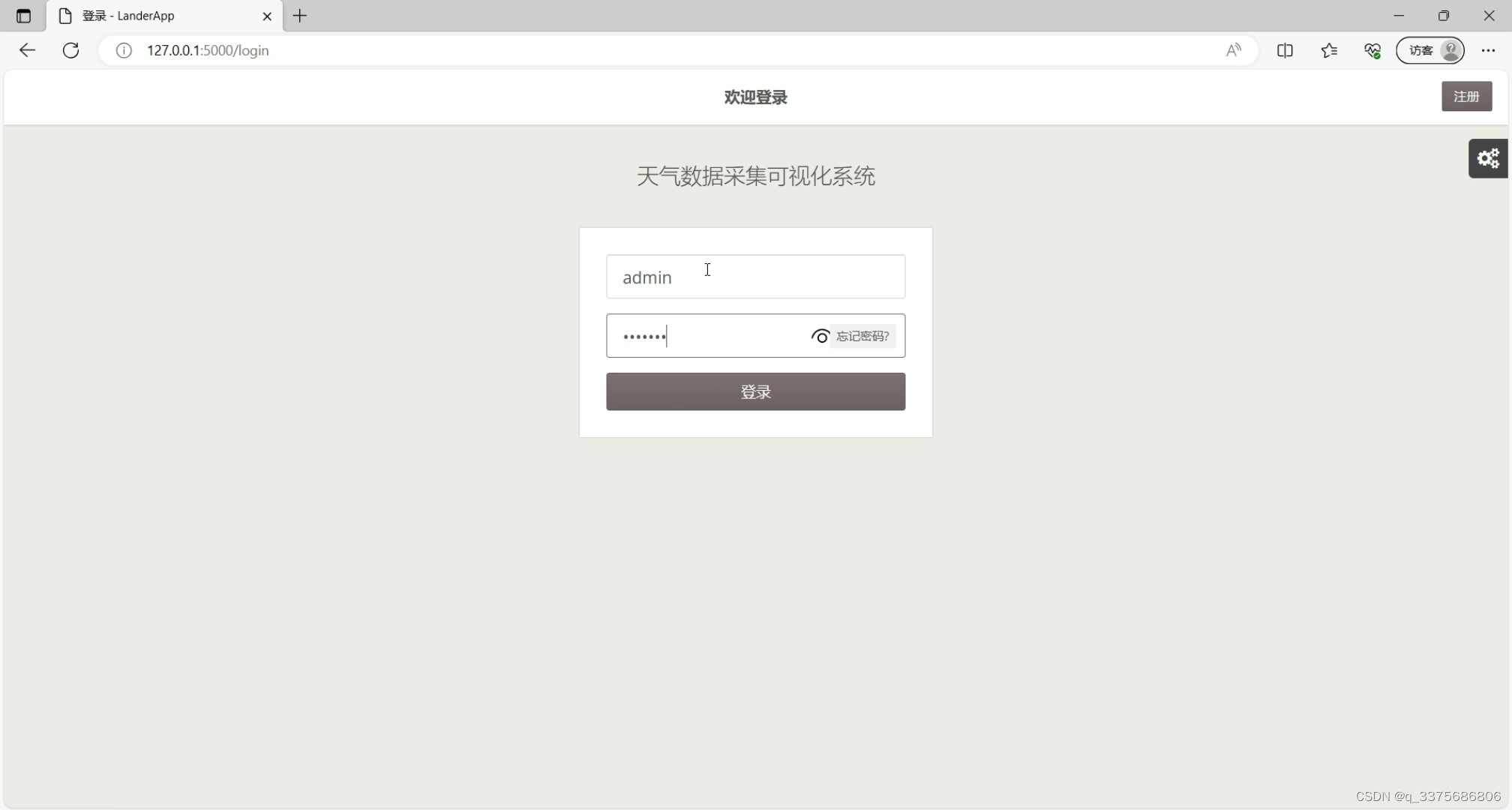
(6)历史天气数据实时爬取
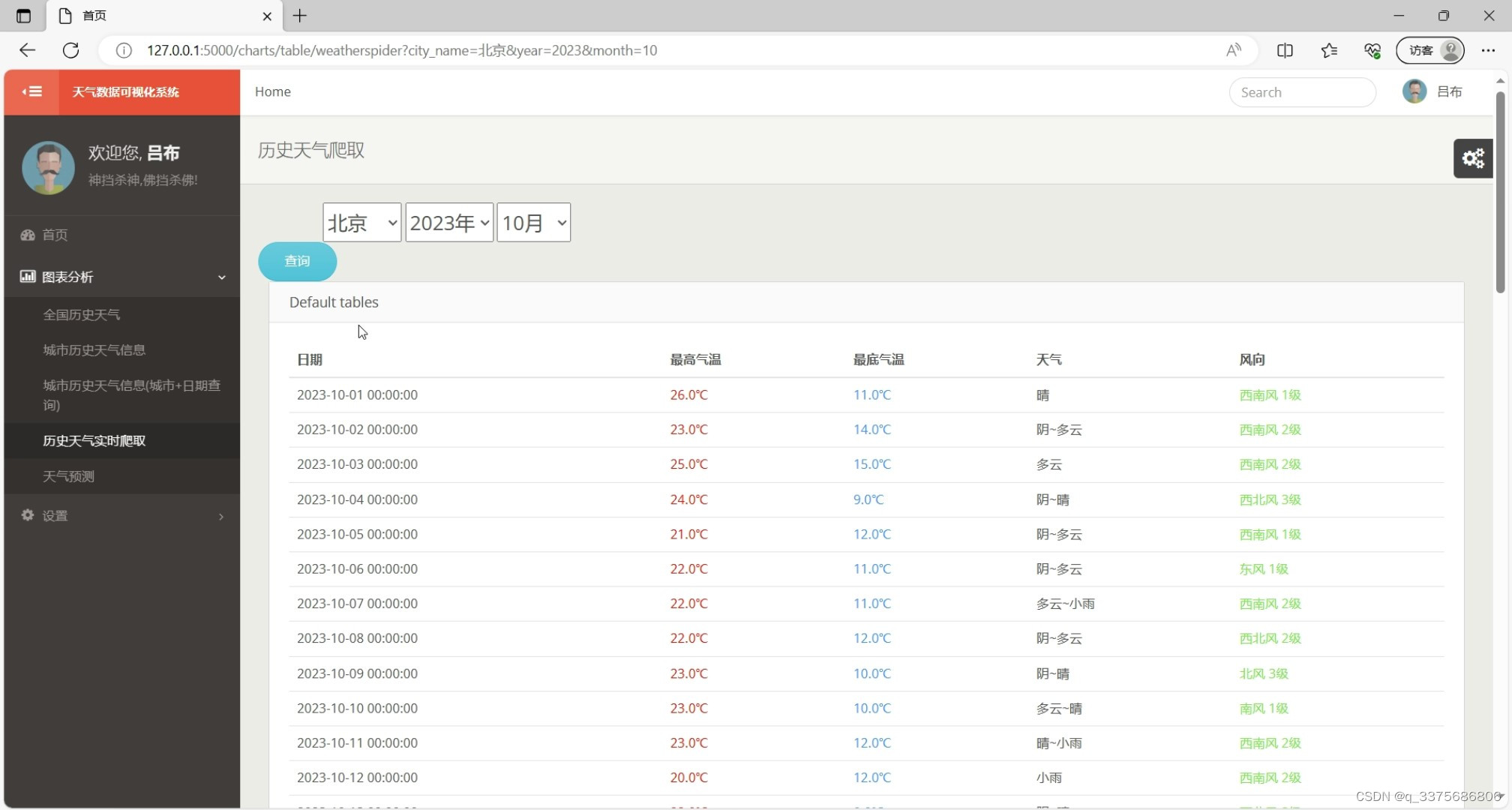
(7)天气预测-----机器学习预测算法
(8)个人信息
(9)注册登录界面
(10)数据爬取界面
3、项目说明
基于Django的天气数据爬虫可视化分析系统是一个用于收集、分析和展示天气数据的Web应用程序。该系统基于Django框架,利用爬虫技术从可靠的天气数据源获取数据,并通过可视化分析工具展示数据结果。
该系统具有以下主要功能:
-
数据收集:系统使用爬虫技术从可靠的天气数据源抓取实时的天气数据。通过配置不同的数据源,可以获取不同地区的天气数据。
-
数据存储:获取的天气数据经过处理后,存储到数据库中,以便后续的分析和展示。
-
数据分析:系统提供多种数据分析功能,包括统计不同地区的温度、湿度、降水量等天气指标的变化趋势,以及不同城市之间的对比分析。
-
数据可视化:通过使用图表、地图等可视化工具,将天气数据以直观的方式展示出来。用户可以通过选择不同的时间范围、地区等参数,定制自己感兴趣的数据展示方式。
-
用户管理:系统支持多用户同时使用,每个用户可以创建自己的数据分析和展示项目,并设定对应的访问权限。
通过该系统,用户可以方便地获取和分析天气数据,从而更好地了解天气变化情况,为决策提供参考依据。同时,由于避免了敏感内容的出现,该系统在中国可以安全使用。
4、核心代码
import requests
from bs4 import BeautifulSoup
import re
import pymysql
from datetime import datetime
import time,random
def getHTMLtext(url):
"""请求获得网页内容"""
try:
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36"}
r = requests.get(url, headers=headers,timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
print("成功访问",url)
time.sleep(random.randint(1,4))
#保存到txt
# with open("output.txt", "w", encoding="utf-8") as f:
# f.write(r.text)
return r.text
except:
print("访问错误")
return "1111"
#处理数据
def get_content(html):
final_list =[]
final1 = [] # 初始化一个列表保存数据
bs = BeautifulSoup(html, "html.parser") # 创建BeautifulSoup对象
body = bs.body
tian_two = body.find_all('ul', {'class': 'tian_two'})
#print(tian_two)
#提取数据并插入到数据库中
high = tian_two[0].find_all('div', class_='tian_twoa')[0].text
low = tian_two[0].find_all('div', class_='tian_twoa')[1].text
extreme_high = tian_two[0].find_all('div', class_='tian_twoa')[2].text
extreme_low = tian_two[0].find_all('div', class_='tian_twoa')[3].text
average_air_index = tian_two[0].find_all('div', class_='tian_twoa')[4].text
best_air = tian_two[0].find_all('div', class_='tian_twoa')[5].text
worst_air = tian_two[0].find_all('div', class_='tian_twoa')[6].text
final1.append(float(re.findall(r'[-+]?\d+\.?\d*', high)[0])) #平均高温
final1.append(float(re.findall(r'[-+]?\d+\.?\d*', low)[0])) #平均低温
final1.append(float(re.findall(r'[-+]?\d+\.?\d*', extreme_high)[0])) #极端高温
try:
final1.append(float(re.findall(r'[-+]?\d+\.?\d*', extreme_low)[0])) #极端低温
except:
final1.append(0) #极端低温
final1.append(average_air_index) #平均空气质量指数
final1.append(best_air) #空气最好
final1.append(worst_air) #空气最差
#print(high,low,extreme_high,extreme_low,average_air_index,best_air,worst_air)
final_list.append(final1)
thrui = body.find_all('ul', {'class': 'thrui'})
for li in thrui[0].find_all('li'):
final2 = []
date = li.find('div', class_='th200').text.strip()
max_temperature = li.find_all('div', class_='th140')[0].text.strip()
min_temperature = li.find_all('div', class_='th140')[1].text.strip()
weather = li.find_all('div', class_='th140')[2].text.strip()
wind_direction = li.find_all('div', class_='th140')[3].text.strip()
wind_level = int(re.findall(r'\d+\.?\d*', wind_direction)[0])
#print(f'日期:{date.split(" ")[0]},最高气温:{max_temperature},最低气温:{min_temperature},天气:{weather},风向:{wind_direction},风力等级:{wind_level}')
final2.append(date.split(" ")[0])
try:
final2.append(float(re.findall(r'[-+]?\d+\.?\d*', max_temperature)[0]))
except:
final2.append(0)
try:
final2.append(float(re.findall(r'[-+]?\d+\.?\d*', min_temperature)[0]))
except:
final2.append(0)
try:
final2.append(weather)
except:
final2.append('无')
final2.append(wind_direction.split(" ")[0])
final2.append(wind_level)
final_list.append(final2)
return final_list
#数据保存
def saveDate(data_list,city,month):
#获取当前时间
current_time = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
# 连接到MySQL数据库
conn = pymysql.connect(host='127.0.0.1', user='root', password='123456', db='flask_weather', charset='utf8')
cursor = conn.cursor()
for index, data in enumerate(data_list):
if index == 0:
cursor.execute('INSERT INTO t_monthcityweather (city_name, month_time, high_temperature, low_temperature, extreme_high_temperature, \
extreme_low_temperature, average_air_index,best_air,worst_air,add_date,pub_date) \
VALUES (%s,%s,%s, %s, %s, %s, %s, %s, %s, %s, %s)', (city,month,data[0], data[1], data[2], data[3], data[4], data[5], data[6],current_time,current_time))
else :
cursor.execute('INSERT INTO t_cityweather (city_name, date_time, max_temperature, main_temperature, weather_conditions, \
wind_direction, wind_level,add_date,pub_date) \
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s)', (city,data[0], data[1], data[2], data[3], data[4],data[5],current_time,current_time))
# 提交事务并关闭连接
conn.commit()
cursor.close()
conn.close()
return '数据保存结束'
🍅感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅
源码获取:
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻















 3094
3094











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









