










毕业设计:2023-2024年计算机专业毕业设计选题汇总(建议收藏)
毕业设计:2023-2024年最新最全计算机专业毕设选题推荐汇总
🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、项目介绍
Python网易云音乐评论数据爬取清洗可视化是一种结合Python编程语言和相关库的方法,可以帮助我们获取、处理、分析和可视化网易云音乐评论数据,从而更好地理解用户行为和市场趋势。
技术栈: Python语言、requests爬虫、数据清洗、numpy、pandas、matplotlib
2、项目界面
(1)词云图分析
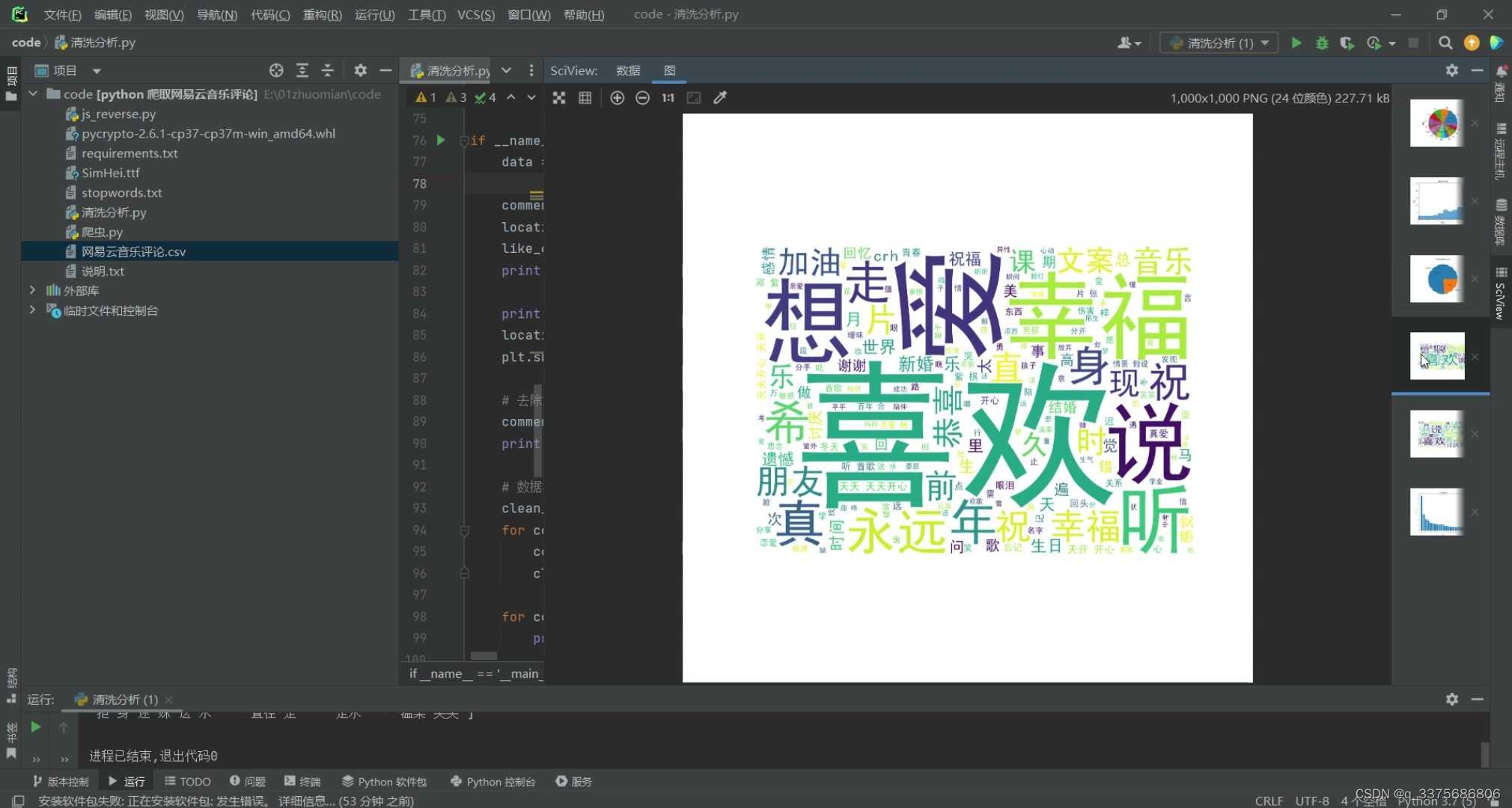
# 绘制词云图
def generate_wordcloud(text):
wordcloud = WordCloud(width=1000,
height=700,
background_color='white', # 背景颜色
font_path='simhei.ttf', # 字体
scale=15, # 间隔
contour_width=5, # 整个内容显示的宽度
contour_color='red', # 内容显示的颜色 红色边境
).generate(text)
# wordcloud = WordCloud(font_path="simhei.ttf", background_color='white')
plt.figure(figsize=(10, 10))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()
(2)情感分析
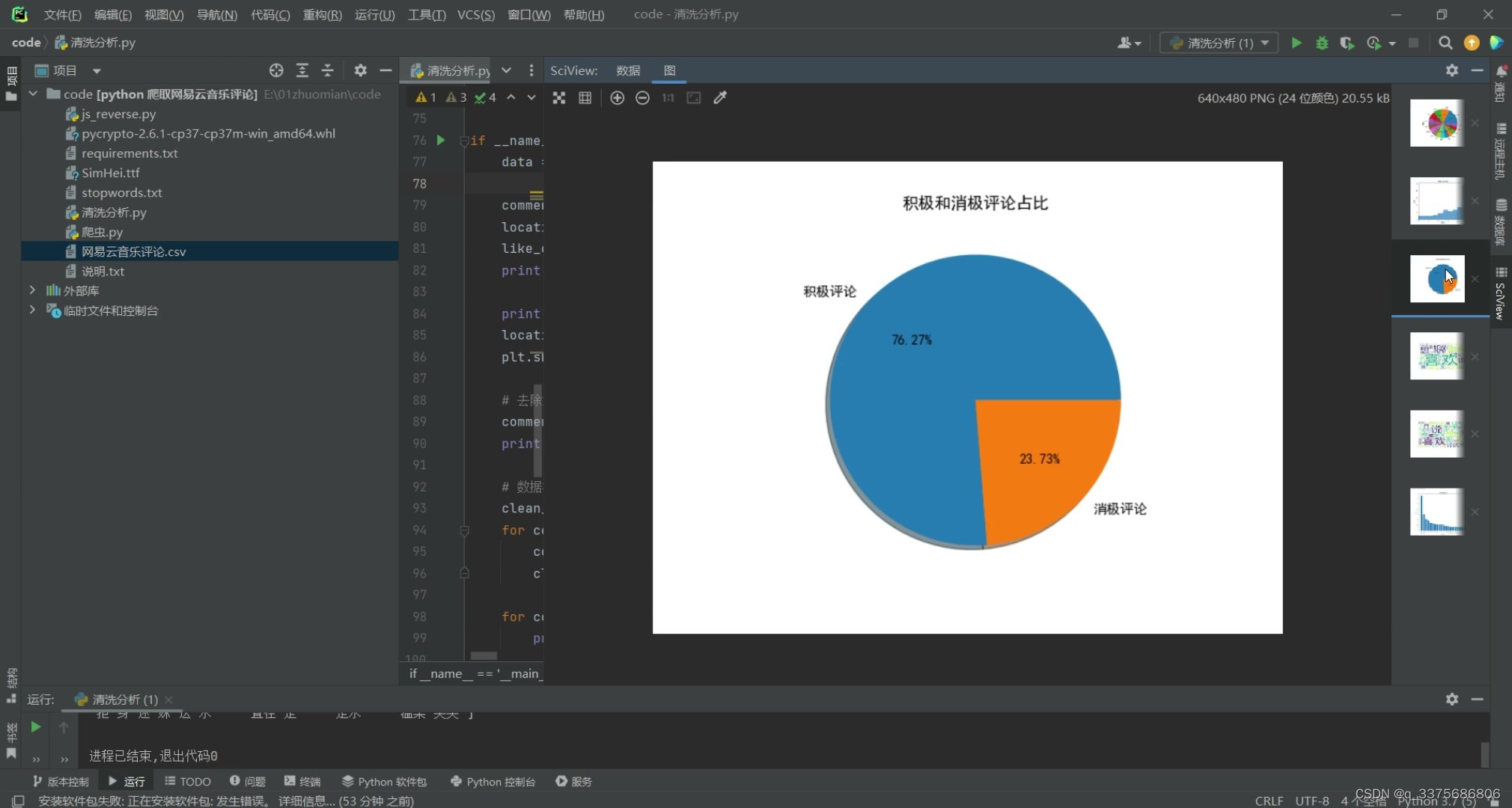
# 根据情感倾向分数将评论分类为积极和消极
positive_comments = [comment for comment, score in zip(segmented_comments, sentiment_scores) if score > 0.5]
negative_comments = [comment for comment, score in zip(segmented_comments, sentiment_scores) if score <= 0.5]
# 积极消极评论占比
pie_labels = ['积极评论', '消极评论']
plt.pie([len(positive_comments), len(negative_comments)],
labels=pie_labels, autopct='%1.2f%%', shadow=True)
plt.title("积极和消极评论占比")
plt.show()
(3)评论词频图
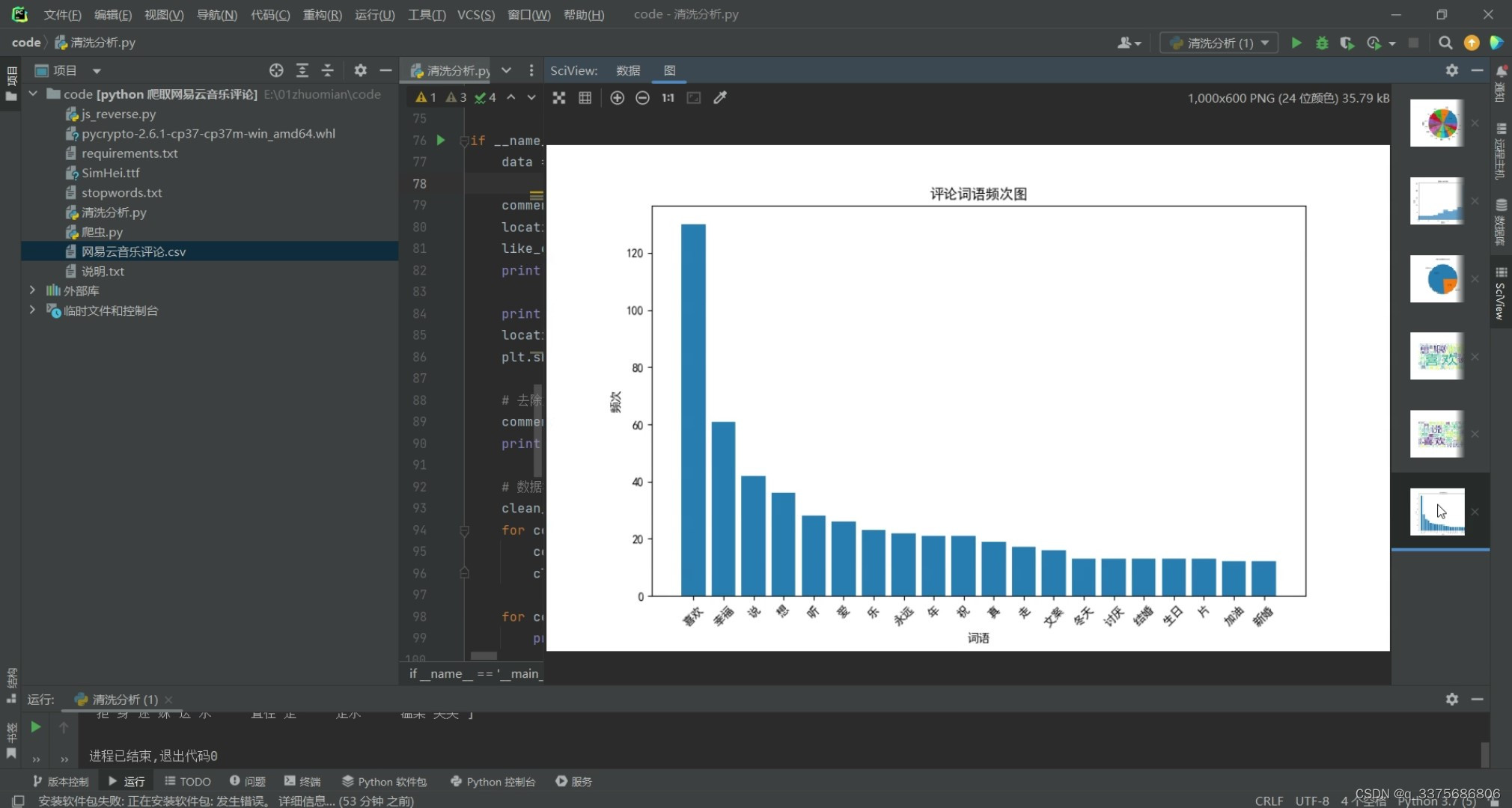
# 绘制词频图
def plot_word_frequency(text):
word_list = jieba.lcut(text)
word_counter = Counter(word_list)
word_freq = word_counter.most_common(21)[1:21] # 取出现频率最高的前20个词语及其频次
words, freqs = zip(*word_freq)
plt.figure(figsize=(10, 6))
plt.bar(words, freqs)
plt.xticks(rotation=45)
plt.xlabel('词语')
plt.ylabel('频次')
plt.title('评论词语频次图')
plt.show()
(4)评论IP属地分析
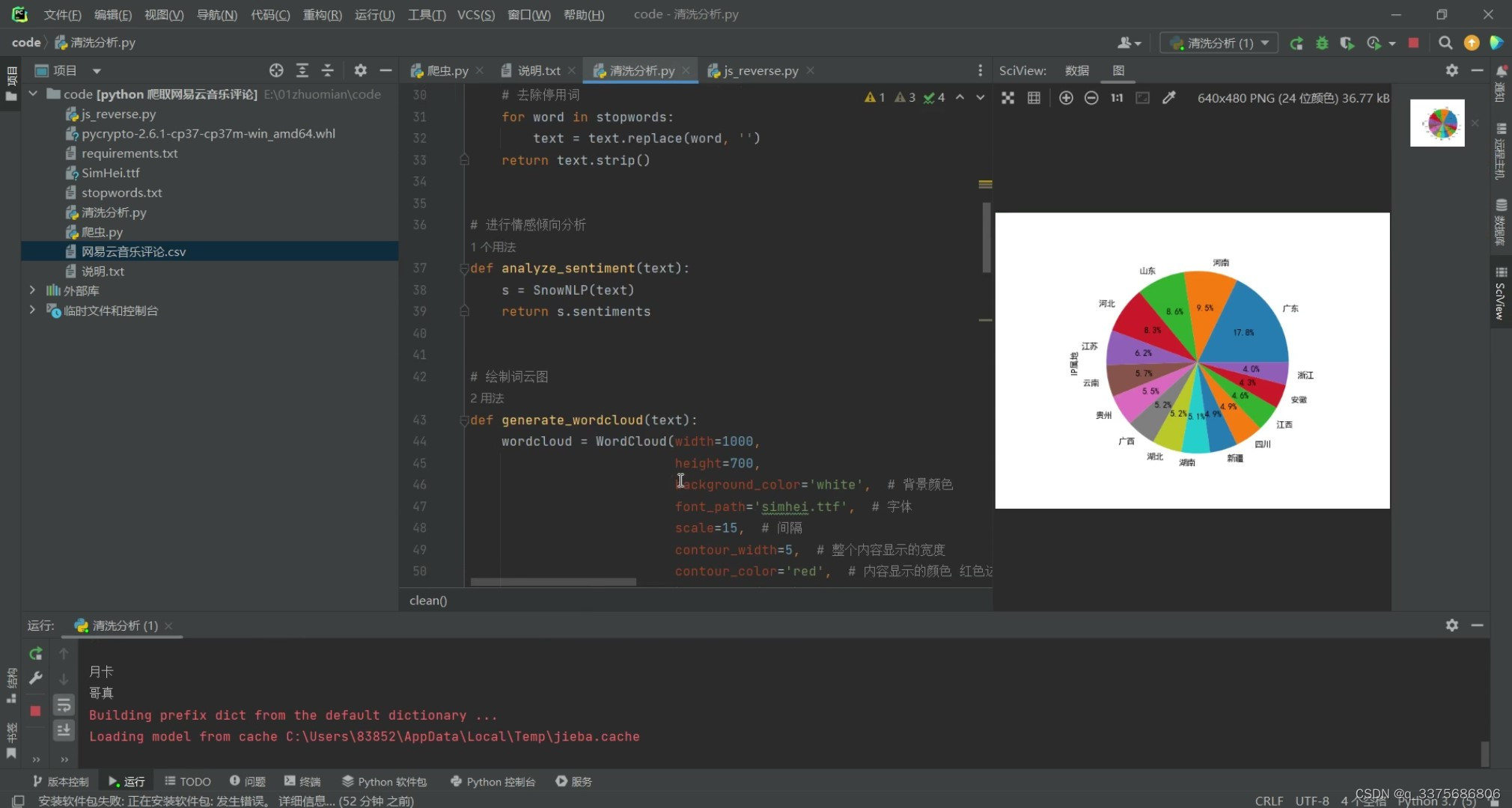
# 数据清洗
def clean(text):
text = re.sub(r"\[\S+\]", "", text) # 去除表情符号
URL_REGEX = re.compile(
r'(?i)\b((?:https?://|www\d{0,3}[.]|[a-z0-9.\-]+[.][a-z]{2,4}/)(?:[^\s()<>]+|\(([^\s()<>]+|(\([^\s()<>]+\)))*\))+(?:\(([^\s()<>]+|(\([^\s()<>]+\)))*\)|[^\s`!()\[\]{};:\'".,<>?«»“”‘’]))',
re.IGNORECASE)
text = re.sub(URL_REGEX, "", text) # 去除网址
text = re.sub(r"\s+", " ", text) # 合并正文中过多的空格
# 去除停用词
for word in stopwords:
text = text.replace(word, '')
return text.strip()
3、项目说明
Python网易云音乐评论数据爬取清洗可视化是一种利用Python编程语言爬取网易云音乐评论数据,然后对数据进行清洗和处理,最后使用可视化工具将数据呈现出来的方法。
首先,我们可以使用Python的爬虫库(如requests、BeautifulSoup等)来获取网易云音乐的评论数据。可以通过模拟用户登录、发送HTTP请求、解析HTML等步骤获取评论数据。
接下来,我们需要对获取到的评论数据进行清洗。这包括去除重复数据、去除无效数据、处理缺失值等步骤。可以使用Python的数据处理库(如pandas)来进行数据清洗。
最后,我们可以使用Python的数据可视化库(如matplotlib、seaborn等)来将清洗后的数据进行可视化。可以绘制柱状图、折线图、散点图等图表,以展示评论数据的分布、趋势等信息。
通过Python网易云音乐评论数据爬取清洗可视化,我们可以更好地理解和分析网易云音乐用户的评论行为。例如,我们可以通过可视化图表了解哪些歌曲受欢迎,哪些歌曲的评论数量最多,评论的情感倾向等等。
总之,Python网易云音乐评论数据爬取清洗可视化是一种结合Python编程语言和相关库的方法,可以帮助我们获取、处理、分析和可视化网易云音乐评论数据,从而更好地理解用户行为和市场趋势。
源码获取:
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻














 373
373











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









