










博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2025年计算机专业毕业设计选题汇总(建议收藏)✅
2、大数据毕业设计:2025年选题大全 深度学习 python语言 JAVA语言 hadoop和spark(建议收藏)✅
1、项目介绍
技术栈:
Python语言、Django框架、MySQL数据库、Echarts可视化、HTML、词云分析、协同过滤推荐算法
2、项目界面
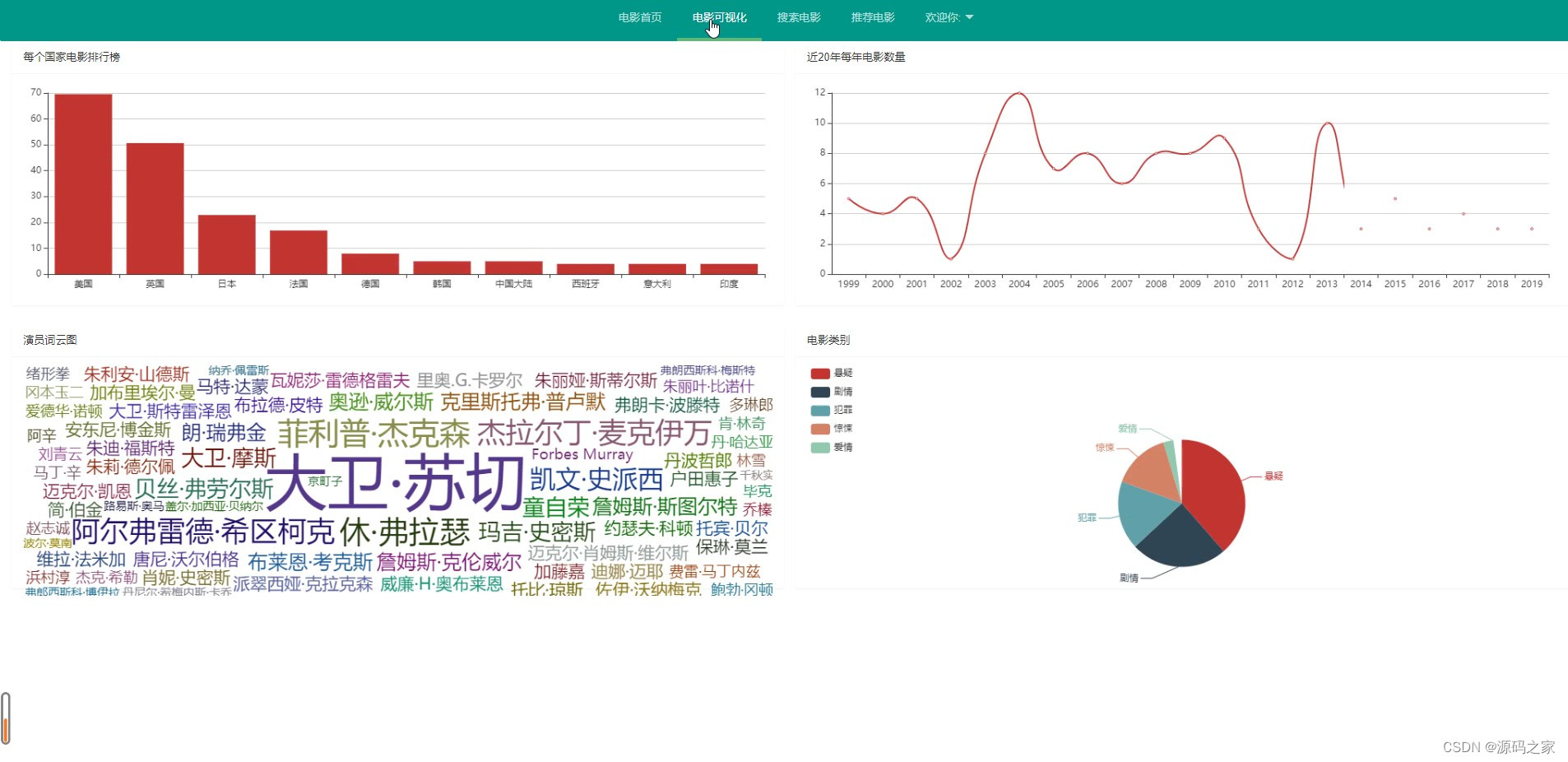
(1)电影数据可视化分析
(2)电影首页
(4)我的收藏
(5)电影搜索查询
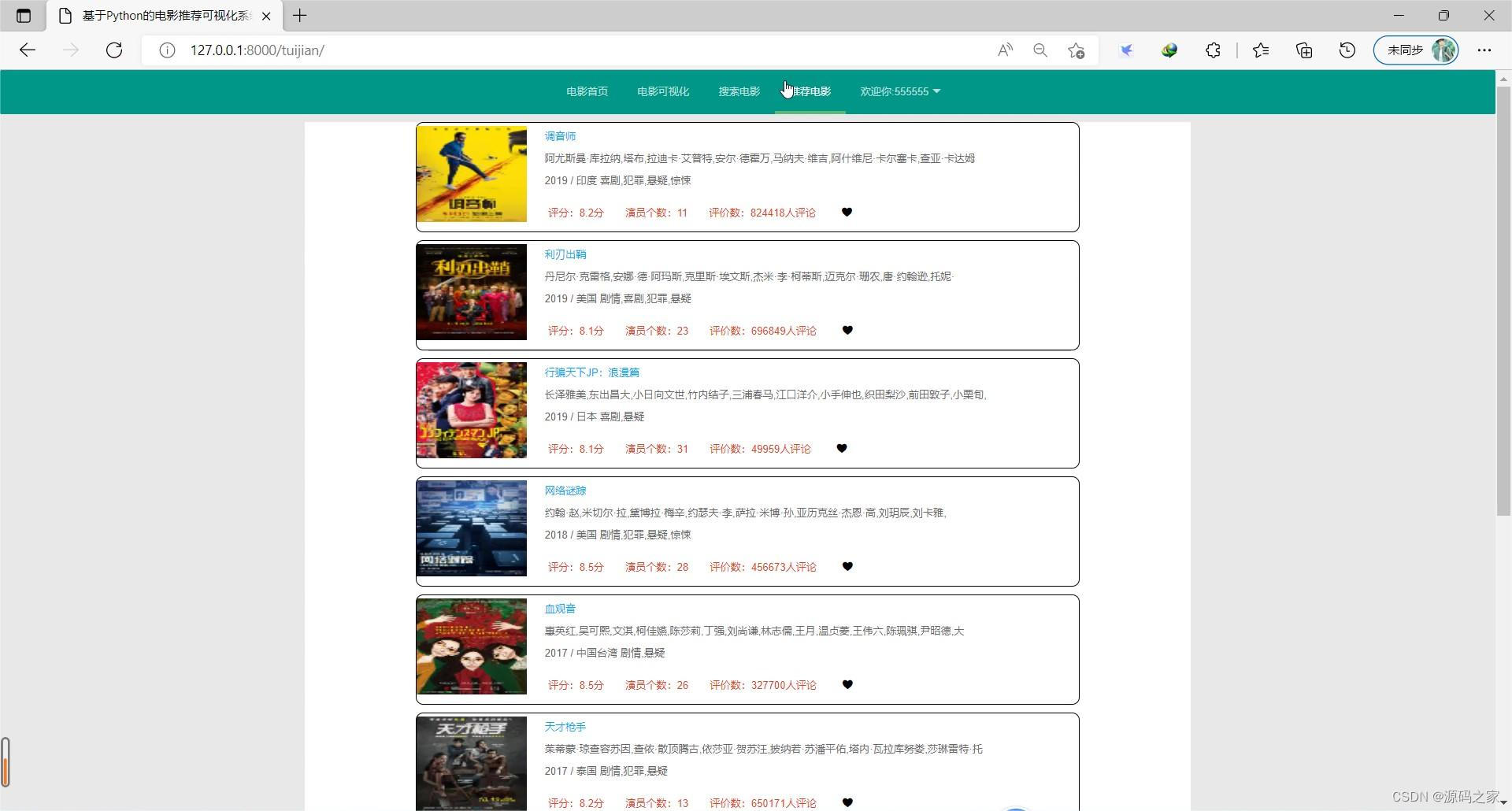
(6)电影推荐—协同过滤推荐算法
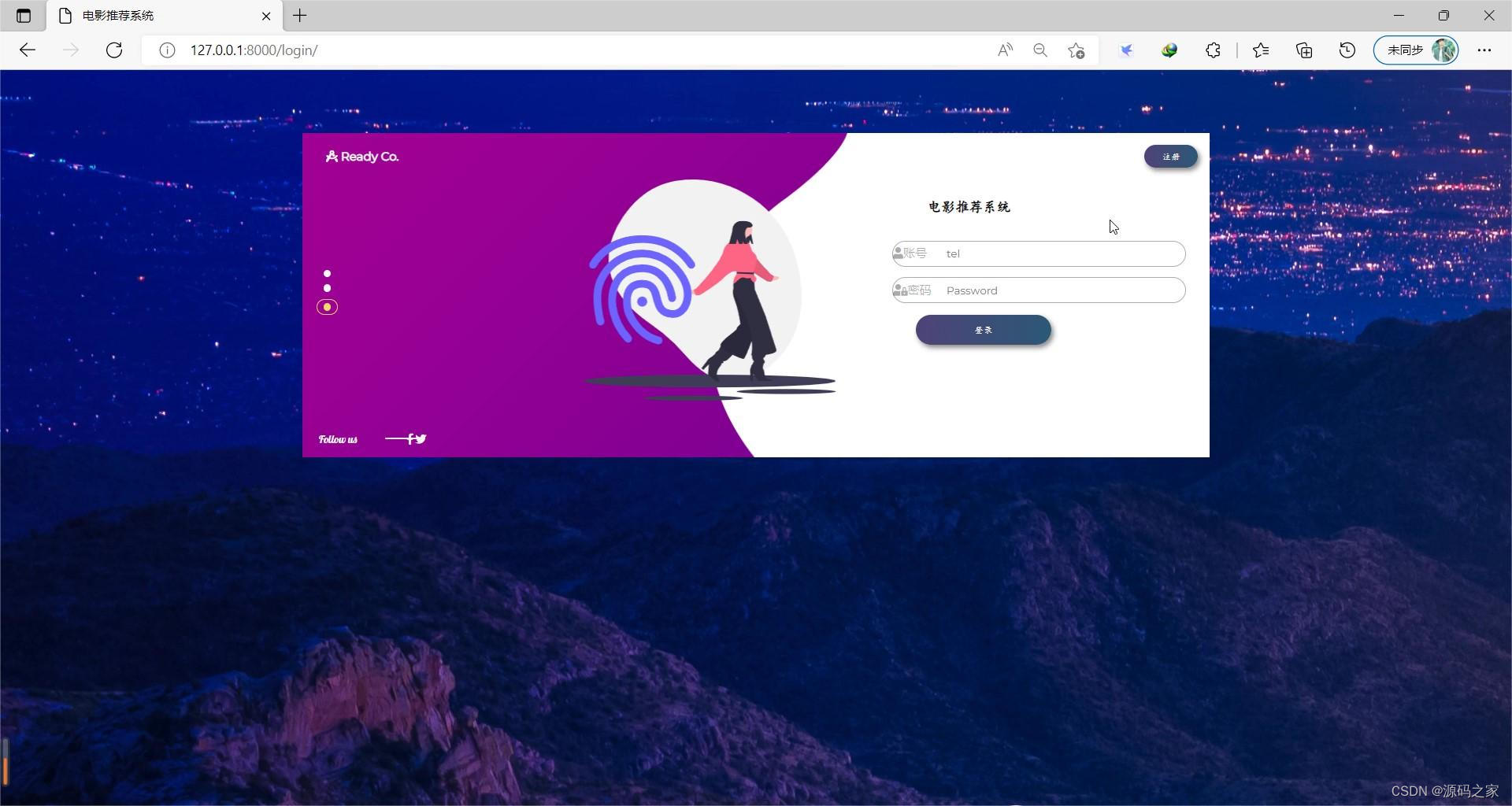
(7)注册登录界面
3、项目说明
协同过滤推荐算法是一种常见的推荐算法,可以用于搭建豆瓣电影推荐系统。在这个系统中,我们使用Django作为后端框架,以实现用户之间的协同过滤推荐。
首先,我们需要搜集用户的电影评分数据,包括用户对电影的打分和评论。可以通过用户注册和登录功能,让用户在豆瓣电影推荐系统中进行操作。用户可以通过搜索电影、查看电影详情、给电影打分和撰写评论等。
接下来,我们需要构建一个电影推荐的算法模型。协同过滤算法可以分为基于用户的协同过滤和基于物品的协同过滤。在基于用户的协同过滤中,我们可以使用用户的历史评分数据来计算相似用户,然后给用户推荐与他们相似度高的其他用户喜欢的电影。在基于物品的协同过滤中,我们可以根据电影的评分数据计算电影之间的相似度,并给用户推荐与他们喜欢的电影相似度高的其他电影。
在Django中,我们可以使用数据库来存储用户的电影评分数据和电影信息。可以使用ORM(对象关系映射)来操作数据库,方便地进行数据的增删改查操作。同时,我们可以使用Django的视图函数来处理用户的请求,并将推荐结果返回给用户。
为了提高推荐的准确性和多样性,我们可以使用一些优化方法。例如,可以引入时间衰减因子,对用户历史评分数据进行加权处理,使最近的评分具有更大的影响力。另外,可以引入随机推荐,给用户推荐一些与他们兴趣不完全相似的电影,以增加推荐的多样性。
最后,为了提高用户体验,可以使用前端技术来设计用户界面。可以使用HTML、CSS和JavaScript等技术来实现用户的交互功能,如搜索电影、查看电影详情和提交评分等。
总而言之,通过使用协同过滤推荐算法和Django框架,我们可以构建一个功能完善的豆瓣电影推荐系统,为用户提供个性化的电影推荐服务。
4、核心代码
# 验证登录
def check_login(func):
def wrapper(request):
# print("装饰器验证登录")
cookie = request.COOKIES.get('uid')
if not cookie:
return redirect('/login/')
else:
return func(request)
return wrapper
# Create your views here.
@check_login
def index(request):
uid = int(request.COOKIES.get('uid', -1))
if uid != -1:
username = User.objects.filter(id=uid)[0].name
relions = Movie.objects.all()
all_type = {item.regions for item in relions}
# all_type = ['历城', '天桥', '长清', '章丘', '高新', '市中', '济阳', '槐荫', '历下']
if 'type' not in request.GET: # 新闻类别
type_ = '中国大陆'
newlist = Movie.objects.filter(regions__contains=type_).values()
else:
type_ = request.GET.get('type')
newlist = Movie.objects.filter(regions__contains=type_).values()
tmp = []
for item in newlist:
if Like.objects.filter(uid_id=uid, hid_id=item['id']):
is_like = 1
else:
is_like = 0
item['is_like'] = is_like
tmp.append(item)
newlist = tmp
return render(request, 'index.html', locals())
def star_ajax(request):
res = {}
yid = int(request.POST.get('id'))
uid = int(request.COOKIES.get('uid', -1))
if Like.objects.filter(uid_id=uid, hid_id=yid):
Like.objects.filter(uid_id=uid, hid_id=yid).delete()
res['color'] = 'black'
else:
Like.objects.create(uid_id=uid, hid_id=yid)
res['color'] = 'red'
return JsonResponse(res)
def my_shoucang(request):
uid = int(request.COOKIES.get('uid', -1))
if uid != -1:
username = User.objects.filter(id=uid)[0].name
newlist = []
if Like.objects.filter(uid_id=uid):
newlist = Like.objects.filter(uid_id=uid)
id_list = [item.hid_id for item in newlist]
newlist = Movie.objects.filter(id__in=id_list).values()
tmp = []
for item in newlist:
if Like.objects.filter(uid_id=uid, hid_id=item['id']):
is_like = 1
else:
is_like = 0
item['is_like'] = is_like
tmp.append(item)
newlist = tmp
return render(request, 'my_shoucang.html', locals())
@check_login
def detail(request):
uid = int(request.COOKIES.get('uid', -1))
if uid != -1:
username = User.objects.filter(id=uid)[0].name
id_ = request.GET.get('id')
info = House.objects.get(id=int(id_))
if See.objects.filter(uid_id=uid):
See.objects.filter(uid_id=uid).update(num=F('num') + 1)
else:
See.objects.create(uid_id=uid,hid_id=int(id_),num=1)
return render(request, 'detail_new.html', locals())
def scrawl_item(request):
"""
爬取所有的电影元数据
:param request:
:return:
"""
for i in tqdm( range(0,201,20)):
# url = f'https://movie.douban.com/j/chart/top_list?type=10&interval_id=10:90&action=None&start={i}&limit=20'
url = "https://movie.douban.com/j/chart/top_list"
payload = {
"type": 10,
"interval_id": "100:90",
"action": None,
"start": i,
"limit": 20
}
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36"
}
res = requests.get(url=url, params=payload, headers=headers, )
time.sleep(10)
data_jsons = res.json()
for data_json in data_jsons:
id_ = data_json['id']# int
id_ = int(id_)
# rating = data_json['rating'][0]# float
rank = data_json['rank']# int
rank = int(rank)
img = data_json['cover_url']
isPlayable = data_json['is_playable']
kind = data_json['types'] # list
kind = ','.join(kind)
regions = data_json['regions'][0]
title = data_json['title']
url = data_json['url']
releaseDate = data_json['release_date']
actorCount = data_json['actor_count']# int
actorCount = int(actorCount)
voteNum = data_json['vote_count']# int
voteNum = int(voteNum)
score = data_json['score'] # float
score = float(score)
actors = data_json['actors'] # list
actors = ','.join(actors)
# print(id_,rank,img,isPlayable,kind,regions,title,url,releaseDate,actorCount,voteNum,score,actors)
if not Movie.objects.filter(id=id_):
try:
Movie.objects.create(id=id_,rank=rank,img=img,isPlayable=isPlayable,kind=kind,
regions=regions,title=title,url=url,releaseDate=releaseDate,actorCount=actorCount,voteNum=voteNum,score=score,actors=actors)
except:
continue
return HttpResponse('全部电影元数据已经爬取OK')
def scrawl_comment(request):
"""
爬取所有的电影元数据
:param request:
:return:
"""
return HttpResponse('全部电影评论已经爬取OK')
@check_login
def tuijian(request):
uid = int(request.COOKIES.get('uid', -1))
if uid != -1:
username = User.objects.filter(id=uid)[0].name
train = dict()
history = Like.objects.all() # 0.1
for item in history:
if item.uid_id not in train.keys():
train[item.uid_id] = {item.hid_id: uid}
else:
train[item.uid_id][item.hid_id] = train[item.uid_id].get(item.hid_id, 0) + 10
history = See.objects.all() # 0.1
for item in history:
if item.uid_id not in train.keys():
train[item.uid_id] = {item.hid_id: 0.1 * item.num}
else:
train[item.uid_id][item.hid_id] = train[item.uid_id].get(item.hid_id, 0) + 1 * item.num
# 声明一个的对象
newlist = []
try:
item = KNN(train)
item.ItemSimilarity()
recommedDict = item.Recommend(int(uid)) # 字典
newlist = Movie.objects.filter(id__in=list(recommedDict.keys()))
except:
print("协同过滤异常啦")
pass
if len(newlist) == 0:
msg = "你还没有在该网站有过评论、浏览行为,请去浏览吧!"
newlist = Movie.objects.order_by('-id')[:10].values()
else:
msg = ""
#
tmp = []
print(newlist)
for item in newlist:
try:
id = item["id"]
except:
id = item.id
if Like.objects.filter(uid_id=uid, hid_id=id):
is_like = 1
else:
is_like = 0
try:
item['is_like'] = is_like
except:
item.is_like = is_like
tmp.append(item)
newlist = tmp
return render(request, 'tuijian.html', locals())
def test(request):
return HttpResponse('测试完成')
@check_login
def search(request):
uid = int(request.COOKIES.get('uid', -1))
if uid != -1:
username = User.objects.filter(id=uid)[0].name
newlist = []
if request.method == 'POST':
keywords = request.POST.get('keywords')
newlist = Movie.objects.filter(title__contains=keywords).values()
tmp = []
for item in newlist:
if Like.objects.filter(uid_id=uid, hid_id=item['id']):
is_like = 1
else:
is_like = 0
item['is_like'] = is_like
tmp.append(item)
newlist = tmp
else:
keywords = ''
return render(request, 'search.html', locals())
def login(request):
if request.method == "POST":
tel, pwd = request.POST.get('tel'), request.POST.get('pwd')
if User.objects.filter(tel=tel, password=pwd):
obj = redirect('/')
obj.set_cookie('uid', User.objects.filter(tel=tel, password=pwd)[0].id, max_age=60 * 60 * 24)
return obj
else:
msg = "用户信息错误,请重新输入!!"
return render(request, 'login.html', locals())
else:
return render(request, 'login.html', locals())
def register(request):
if request.method == "POST":
name, tel, pwd = request.POST.get('name'), request.POST.get('tel'), request.POST.get('pwd')
print(name, tel, pwd)
if User.objects.filter(tel=tel):
msg = "你已经有账号了,请登录"
else:
User.objects.create(name=name, tel=tel, password=pwd)
msg = "注册成功,请登录!"
return render(request, 'login.html', locals())
else:
msg = ""
return render(request, 'register.html', locals())
def logout(request):
obj = redirect('/')
obj.delete_cookie('uid')
return obj
def plot(request):
raw_data = Movie.objects.all()
# 1 每个国家 电影排行榜
main1 = raw_data.values('regions').annotate(count=Count('regions')).order_by('-count')[:10]
main1_x = [item['regions'] for item in main1]
main1_y = [item['count'] for item in main1]
# 2 每年电影排行
year_list = list(range(1999,2020))
main2_x = year_list
main2_y = []
for year in year_list:
main2_y.append(raw_data.filter(releaseDate__year=year).count())
# print(main1)
# 3 类别被购买前十
tmp = [item.actors for item in raw_data]
result_list = []
for item in tmp:
result_list = result_list + item.split(',')
result_dict = {k: result_list.count(k) for k in result_list}
result_dict = sorted(result_dict.items(), key=lambda x: x[1], reverse=True) # 最大到最小
print(result_dict)
main3 = [{'value': item[1], 'name': item[0]}
for item in result_dict
]
tmp = [item.kind for item in raw_data]
result_list = []
for item in tmp:
result_list = result_list + item.split(',')
result_dict = {k: result_list.count(k) for k in result_list}
result_dict = sorted(result_dict.items(),key=lambda x:x[1],reverse=True)[:5] # 最大到最小
print(result_dict)
main4 = [{'value': item[1],'name': item[0]}
for item in result_dict
]
main4_x = [item['name'] for item in main4]
return render(request,'plot.html',locals())
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻

















 639
639

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









