







博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
2、大数据毕业设计:2026年选题大全 深度学习 python语言 JAVA语言 hadoop和spark(建议收藏)✅
1、项目介绍
技术栈:
python语言、Django框架、neo4j图形数据库、Echarts可视化、HTML、协同过滤推荐算法
基于知识图谱电影推荐问答系统
2、项目界面
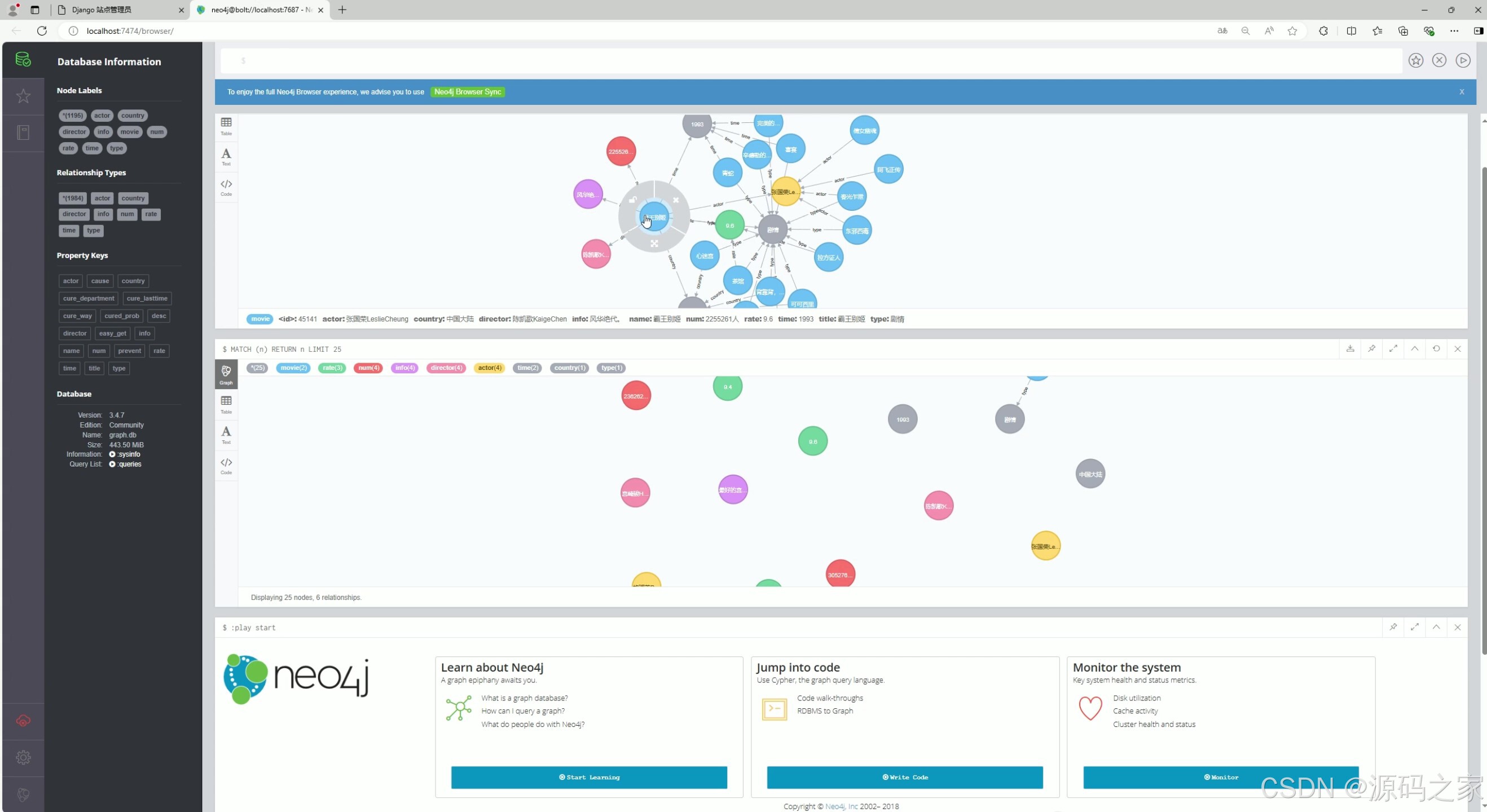
(1)电影知识图谱
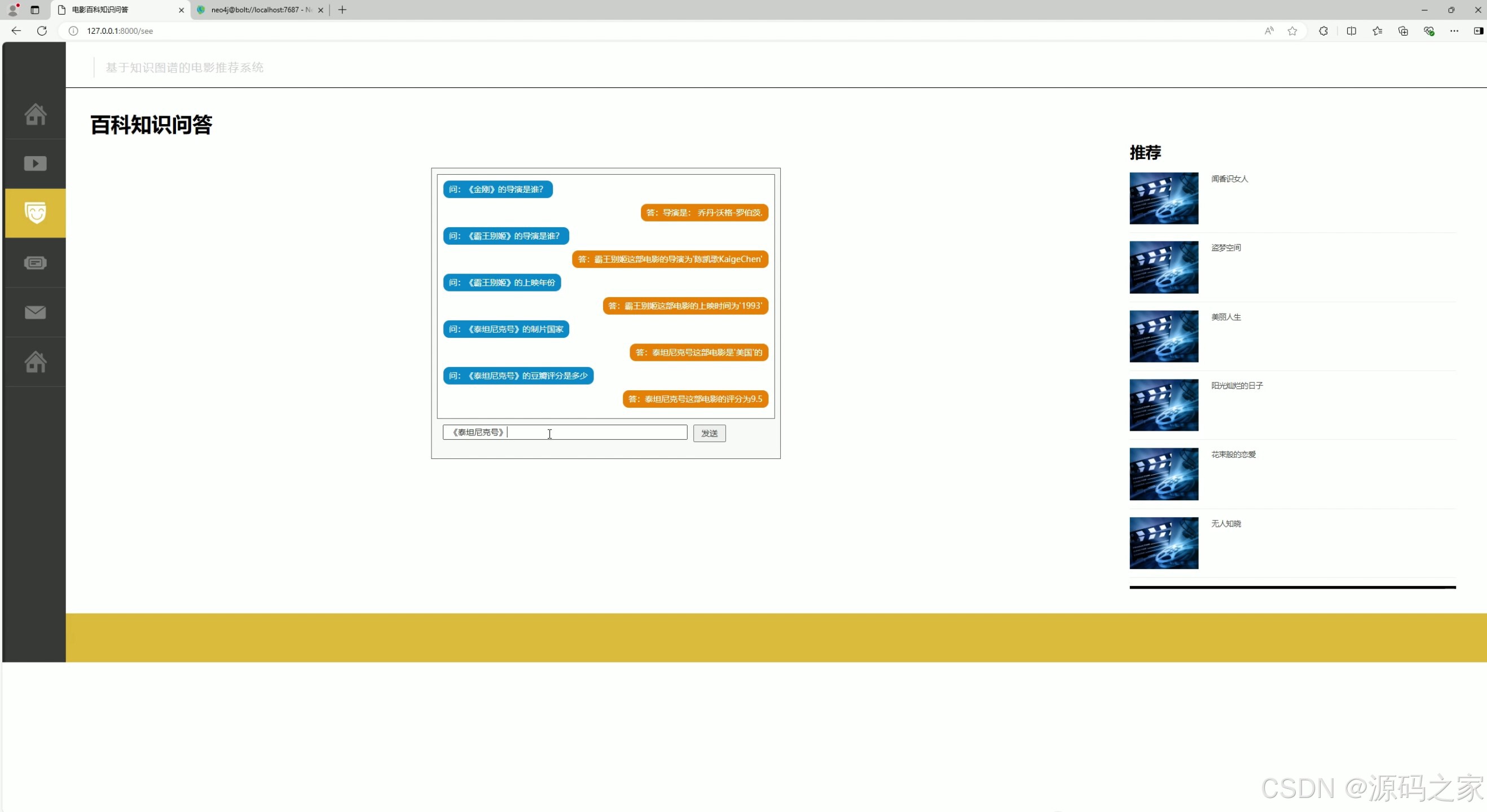
(2)电影问答系统
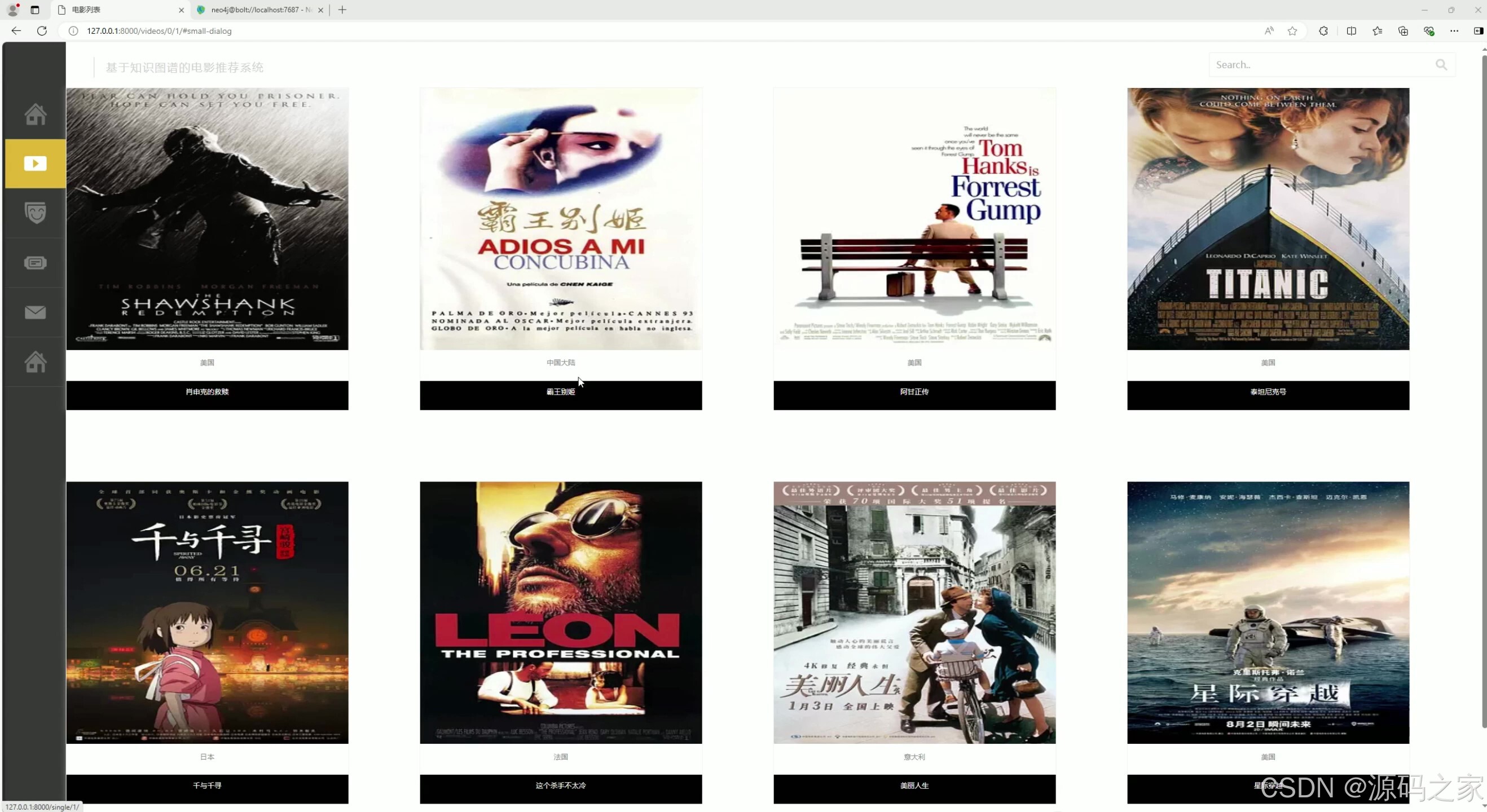
(3)电影列表
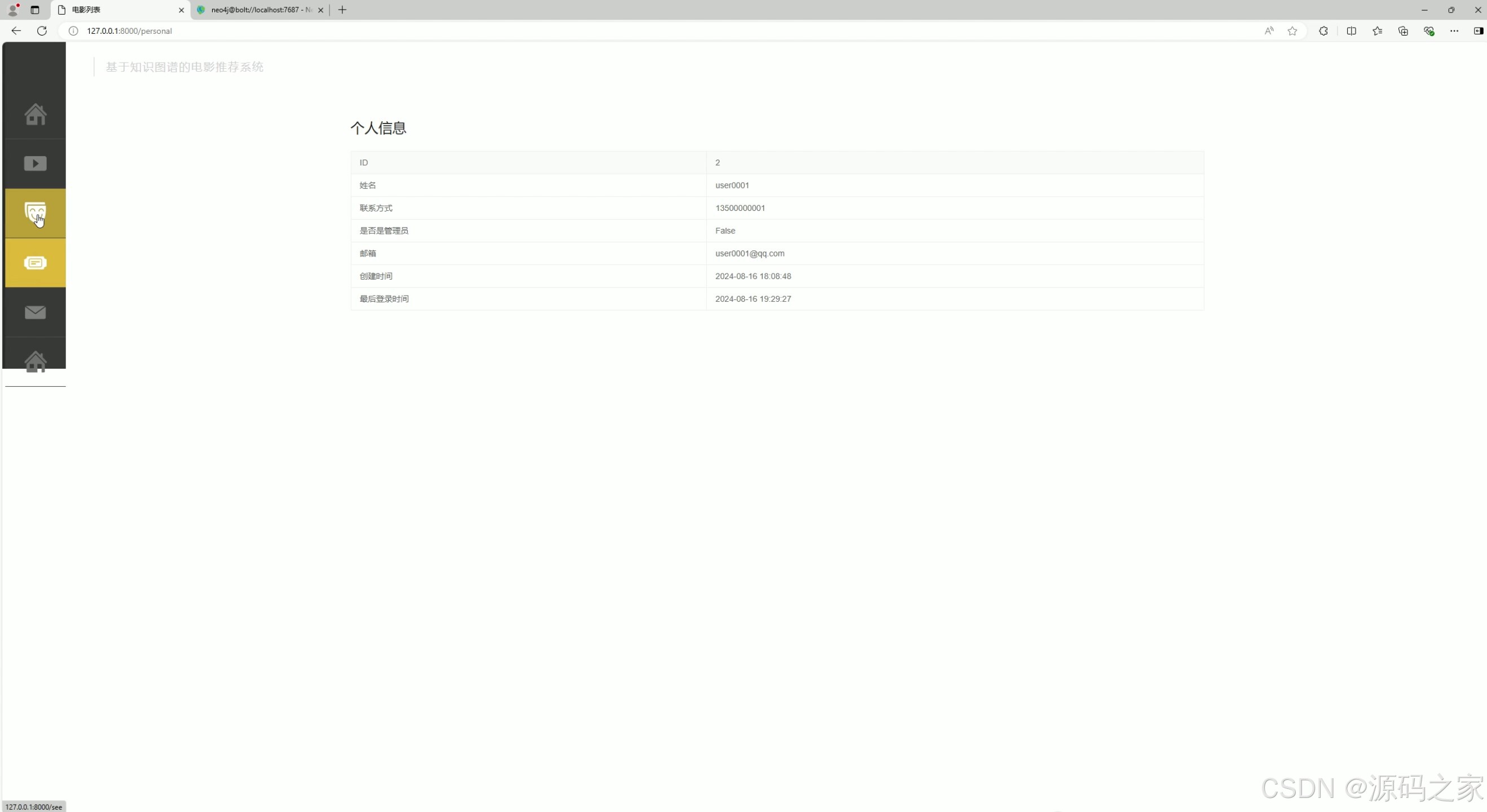
(4)个人信息
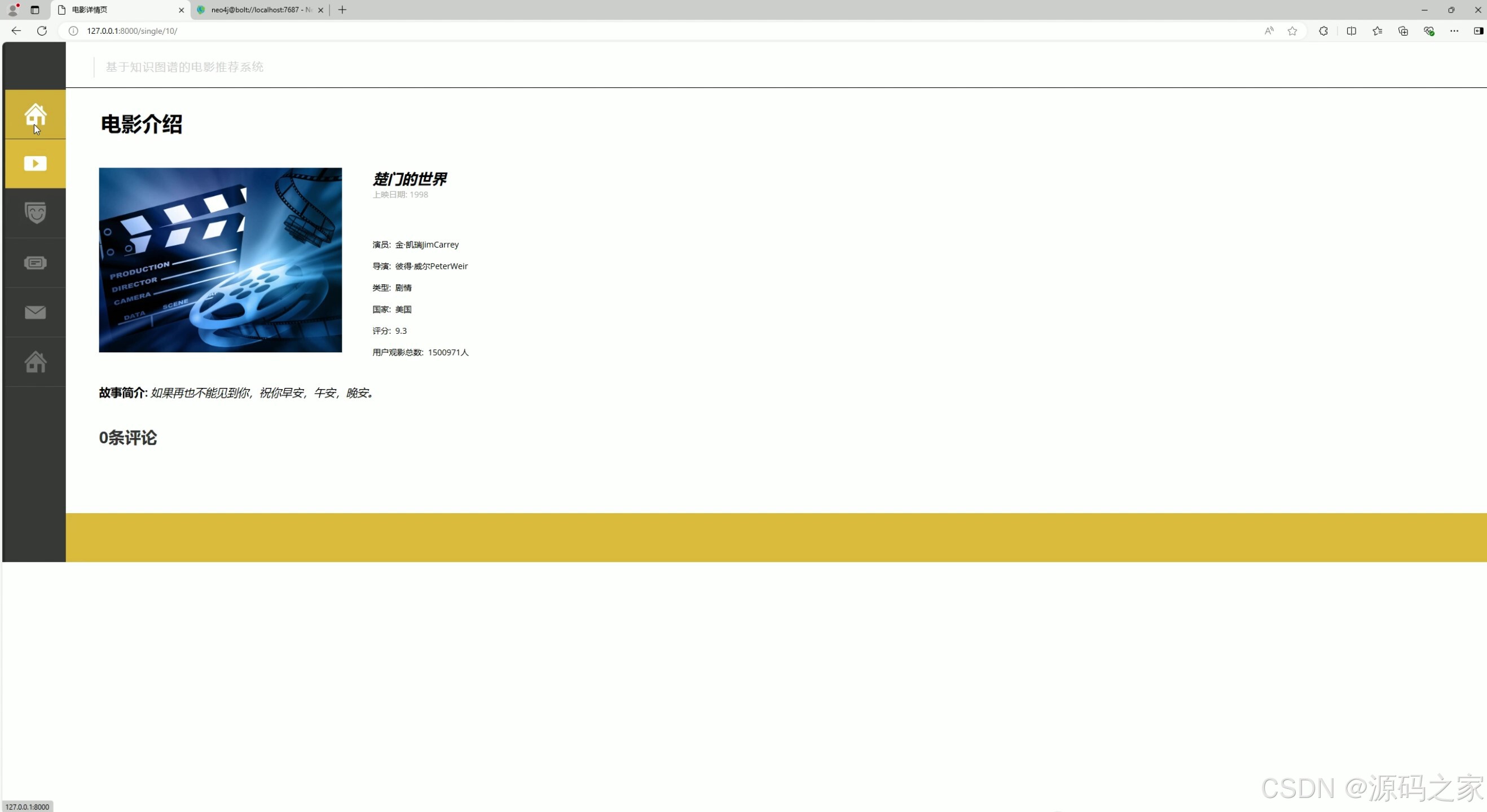
(5)电影详情页
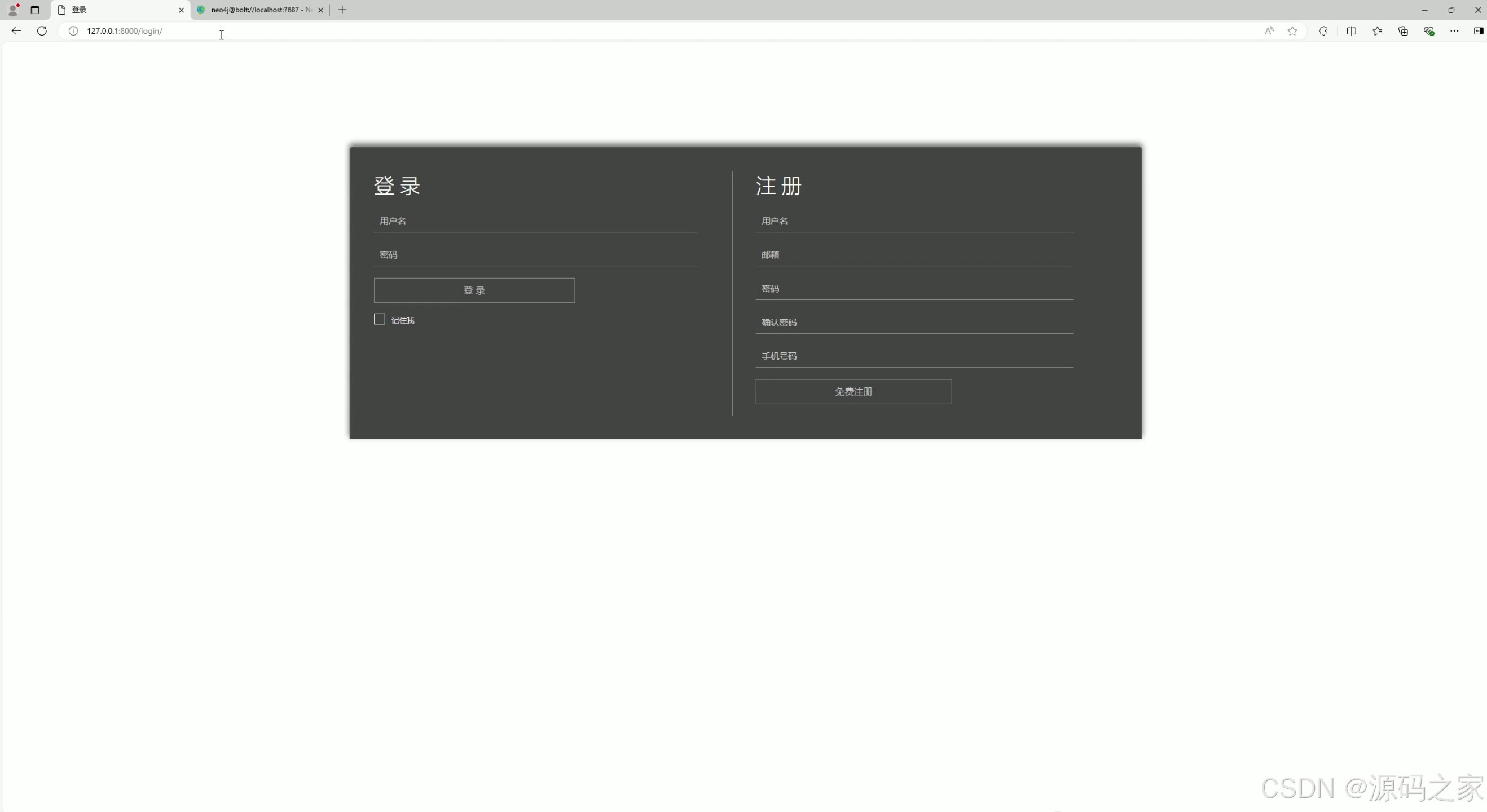
(6)注册登录
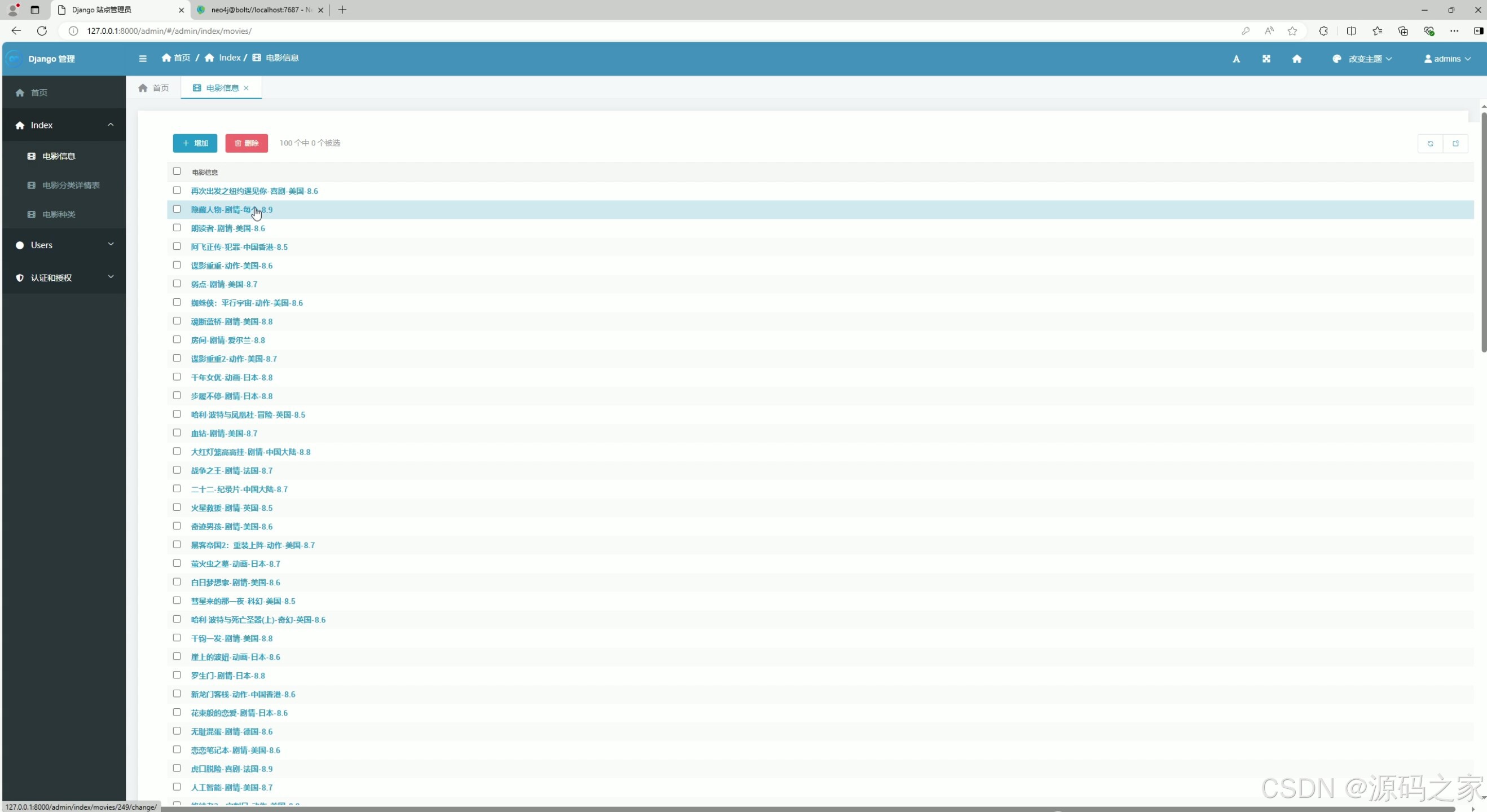
(7)后台管理
3、项目说明
进入二十一世纪之后,网络发展越来越迅速,人们的很多生活与消费习惯都随之发生了改变。在计算机技术或推荐算法不发达的年代,人们是无法通过电脑获取某部电影的相关知识的,也没法通过电脑进行在线的问答,人们通常是要去各地区的音像店或者通过报纸和杂志进行信息的获取,如果有问题也是通过人工的方式进行询问和解答的。但这种形式费事费力,因为一个地区的大型音像店和报亭的数量是有限的,人们并不能自由的进行电影相关知识的了解,而且每一个地方的工作人员的数量肯定是有限的,所以如果想通过询问管理人员获取相关问题的答案也是不方便的,并且对工作人员来说强度和难度也非常的大。还有一个原因,不同的人对同一部电影的看法是不一样的,电影市场也是经常变化的,所以无法保证相关工作人员可以在不同的市场环境下对客户进行电影的推荐。不过随着许多传统的行业逐渐与互联网接轨,各种推荐算法技术越来越发达,电影等信息的推荐也逐渐被网络化的推荐系统所替代了。在计算机刚开始发展的时候就出现了许多的电影评分或电影推荐系统,但是因为技术的限制导致系统并不完美,有很多不符合使用者使用习惯的瑕疵,也有很多的功能缺陷。随着计算机编程语言的不断发展和移动设备的出现,电影推荐及电影知识问答等服务逐渐朝着更专业、更精准、更效率的方向发展。
本系统前台界面使用了最新的HTML5技术,使用DIV+CSS进行布局,使整个前台页面变得更美观,极大的提高了用户的体验,另外本系统无论是使用电脑的浏览器进行访问还是使用移动设备进行访问,都可以保证网站正确的排版。后端的代码技术选择的是PYTHON,PYTHON语言是当下最常用的编程语言之一,可以保证系统的稳定性和流畅性,PYTHON可以灵活的与数据库进行连接。本系统的数据使用的MYSQL数据库,它可以提高查询的速度,增强系统数据存储的稳定性和安全性。本系统的核心算法是知识图谱和协同过滤算法,是当下很流行的一种算法模式,也是未来很多行业的发展趋势,利用此方法可以准确的对用户进行电影的推荐和问答。
关键词:知识图谱;协同过滤算法;电影推荐;PYTHON;MySQL
4、核心代码
# -*- coding = utf-8 -*-
"""
User-based Collaborative filtering.
"""
import collections
from operator import itemgetter
import math
from collections import defaultdict
from . import similarity
from . import utils
from .utils import LogTime
class UserBasedCF:
"""
User-based Collaborative filtering.
Top-N recommendation.
"""
def __init__(self, k_sim_user=20, n_rec_movie=10, use_iif_similarity=False, save_model=True):
"""
Init UserBasedCF with n_sim_user and n_rec_movie.
@return: None
"""
print("UserBasedCF start...\n")
self.k_sim_user = k_sim_user
self.n_rec_movie = n_rec_movie
self.trainset = None
self.save_model = save_model
self.use_iif_similarity = use_iif_similarity
def fit(self, trainset):
"""
Fit the trainset by calculate user similarity matrix.
@param trainset: train dataset
@return: None
"""
model_manager = utils.ModelManager()
try:
self.user_sim_mat = model_manager.load_model(
'user_sim_mat-iif' if self.use_iif_similarity else 'user_sim_mat')
self.movie_popular = model_manager.load_model('movie_popular')
self.movie_count = model_manager.load_model('movie_count')
self.trainset = model_manager.load_model('trainset')
print('User origin similarity model has saved before.\nLoad model success...\n')
except OSError:
print('No model saved before.\nTrain a new model...')
self.user_sim_mat, self.movie_popular, self.movie_count = \
similarity.calculate_user_similarity(trainset=trainset,
use_iif_similarity=self.use_iif_similarity)
self.trainset = trainset
print('Train a new model success.')
if self.save_model:
model_manager.save_model(self.user_sim_mat,
'user_sim_mat-iif' if self.use_iif_similarity else 'user_sim_mat')
model_manager.save_model(self.movie_popular, 'movie_popular')
model_manager.save_model(self.movie_count, 'movie_count')
print('The new model has saved success.\n')
def recommend(self, user):
"""
Find K similar users and recommend N movies for the user.
@param user: The user we recommend movies to.
@return: the N best score movies
"""
if not self.user_sim_mat or not self.n_rec_movie or \
not self.trainset or not self.movie_popular or not self.movie_count:
raise NotImplementedError('UserCF has not init or fit method has not called yet.')
K = self.k_sim_user
N = self.n_rec_movie
predict_score = collections.defaultdict(int)
if user not in self.trainset:
print('The user (%s) not in trainset.' % user)
return
# print('Recommend movies to user start...')
watched_movies = self.trainset[user]
for similar_user, similarity_factor in sorted(self.user_sim_mat[user].items(),
key=itemgetter(1), reverse=True)[0:K]:
for movie, rating in self.trainset[similar_user].items():
if movie in watched_movies:
continue
# predict the user's "interest" for each movie
# the predict_score is sum(similarity_factor * rating) 预测分数为加权(相似度*评分)求和
predict_score[movie] += similarity_factor * rating
# log steps and times.
# print('Recommend movies to user success.')
# return the N best score movies
return [movie for movie, _ in sorted(predict_score.items(), key=itemgetter(1), reverse=True)[0:N]]
def test(self, testset):
"""
Test the recommendation system by recommending scores to all users in testset.
@param testset: test dataset
@return:
"""
if not self.n_rec_movie or not self.trainset or not self.movie_popular or not self.movie_count:
raise ValueError('UserCF has not init or fit method has not called yet.')
self.testset = testset
print('Test recommendation system start...')
N = self.n_rec_movie
# varables for precision and recall
hit = 0
rec_count = 0
test_count = 0
# varables for coverage
all_rec_movies = set()
# varables for popularity
popular_sum = 0
# record to calculate time has spent.
test_time = LogTime(print_step=1000)
for i, user in enumerate(self.trainset):
test_movies = self.testset.get(user, {})
rec_movies = self.recommend(user) # type:list
for movie in rec_movies:
if movie in test_movies:
hit += 1
all_rec_movies.add(movie)
popular_sum += math.log(1 + self.movie_popular[movie])
# log steps and times.
rec_count += N
test_count += len(test_movies)
# print time per 500 times.
test_time.count_time()
precision = hit / (1.0 * rec_count)
recall = hit / (1.0 * test_count)
coverage = len(all_rec_movies) / (1.0 * self.movie_count)
popularity = popular_sum / (1.0 * rec_count)
print('Test recommendation system success.')
test_time.finish()
print('precision=%.4f\trecall=%.4f\tcoverage=%.4f\tpopularity=%.4f\n' %
(precision, recall, coverage, popularity))
def predict(self, testset):
"""
Recommend movies to all users in testset.
:param testset: test dataset
:return: `dict` : recommend list for each user.
"""
movies_recommend = defaultdict(list)
print('Predict scores start...')
# record the calculate time has spent.
predict_time = LogTime(print_step=500)
for i, user in enumerate(testset):
rec_movies = self.recommend(user) # type:list
movies_recommend[user].append(rec_movies)
# log steps and times.
predict_time.count_time()
print('Predict scores success.')
predict_time.finish()
return movies_recommend
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻


















 3097
3097

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









