







毕业设计:2023-2024年计算机专业毕业设计选题汇总(建议收藏)
毕业设计:2023-2024年最新最全计算机专业毕设选题推荐汇总
🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、项目介绍
技术栈:
Python语言、Flask框架、 requests爬虫、协同过滤推荐算法、sqlite数据库、bilibili数据、前台+后台
B站数据采集分析、推荐与可视化分析系统是一个强大的工具,它利用Python语言、Flask框架、requests爬虫技术、协同过滤推荐算法以及sqlite数据库等关键技术栈,实现了对Bilibili(B站)数据的深度采集、智能分析和精准推荐,并通过丰富的可视化界面展示了分析结果。
数据分析
在数据分析环节,系统利用Python强大的数据处理能力,对采集到的数据进行清洗、整合和挖掘。特别是协同过滤推荐算法的应用,使得系统能够根据用户的历史行为和偏好,为用户推荐与其兴趣相似的视频、UP主或话题。这种个性化推荐功能,不仅提高了用户的使用体验,还增强了用户与B站平台的黏性。
可视化分析
系统的可视化分析功能是其一大亮点。通过丰富的图表和界面设计,系统能够将分析结果以直观、易懂的方式呈现出来。无论是用户行为分析、内容热度评估还是推荐算法效果验证,都能够通过可视化界面进行快速查看和理解。这不仅方便了数据分析师和决策者的工作,也使得普通用户能够更深入地了解B站平台的数据情况。
总之,B站数据采集分析、推荐与可视化分析系统是一个功能强大、易于使用的数据分析工具。它不仅能够为B站平台提供精准的用户推荐和数据分析支持,还能够为数据分析师和决策者提供有力的决策依据。随着B站平台的不断发展和壮大,该系统将继续发挥其在数据分析和推荐领域的重要作用。
2、项目界面
(1)各视频类型数据可视化分析------类型选择分析
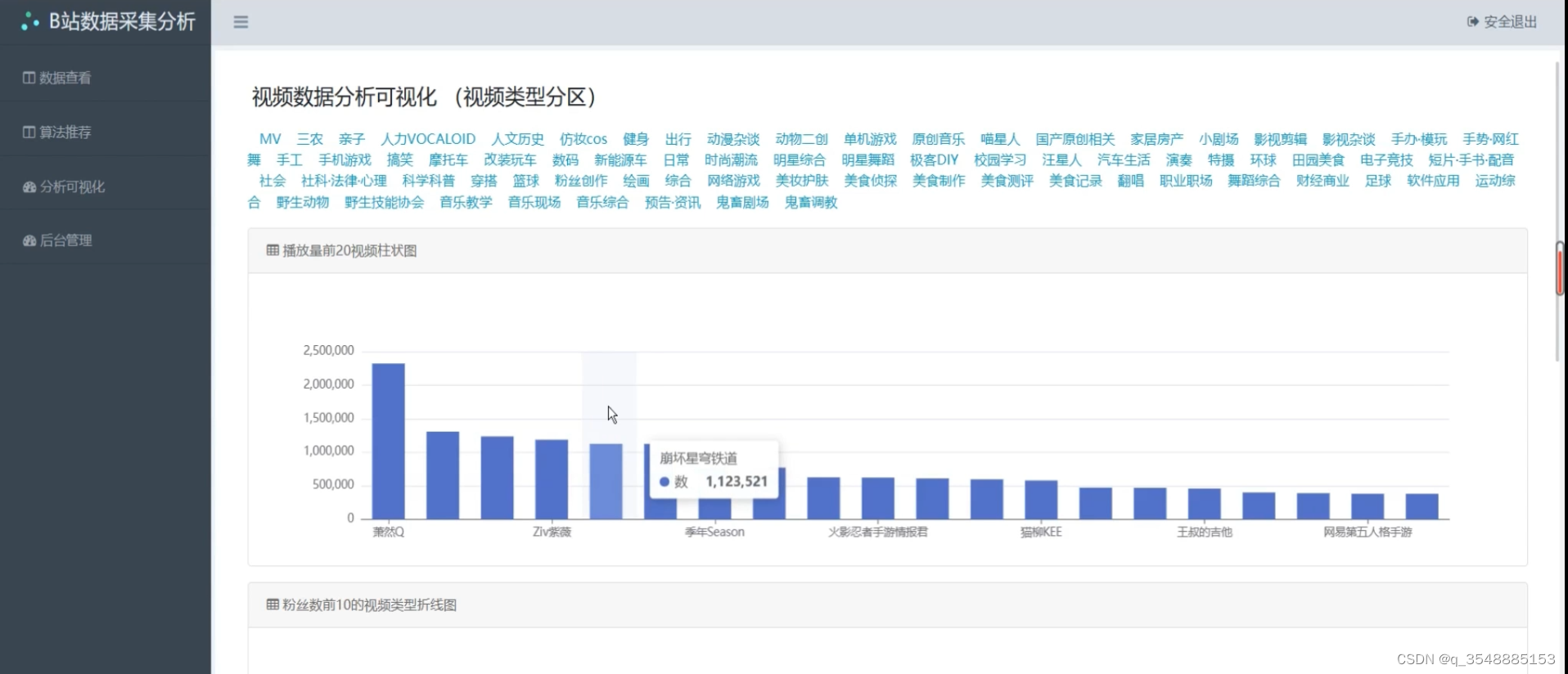
(2)各视频类型数据可视化分析2----折线图
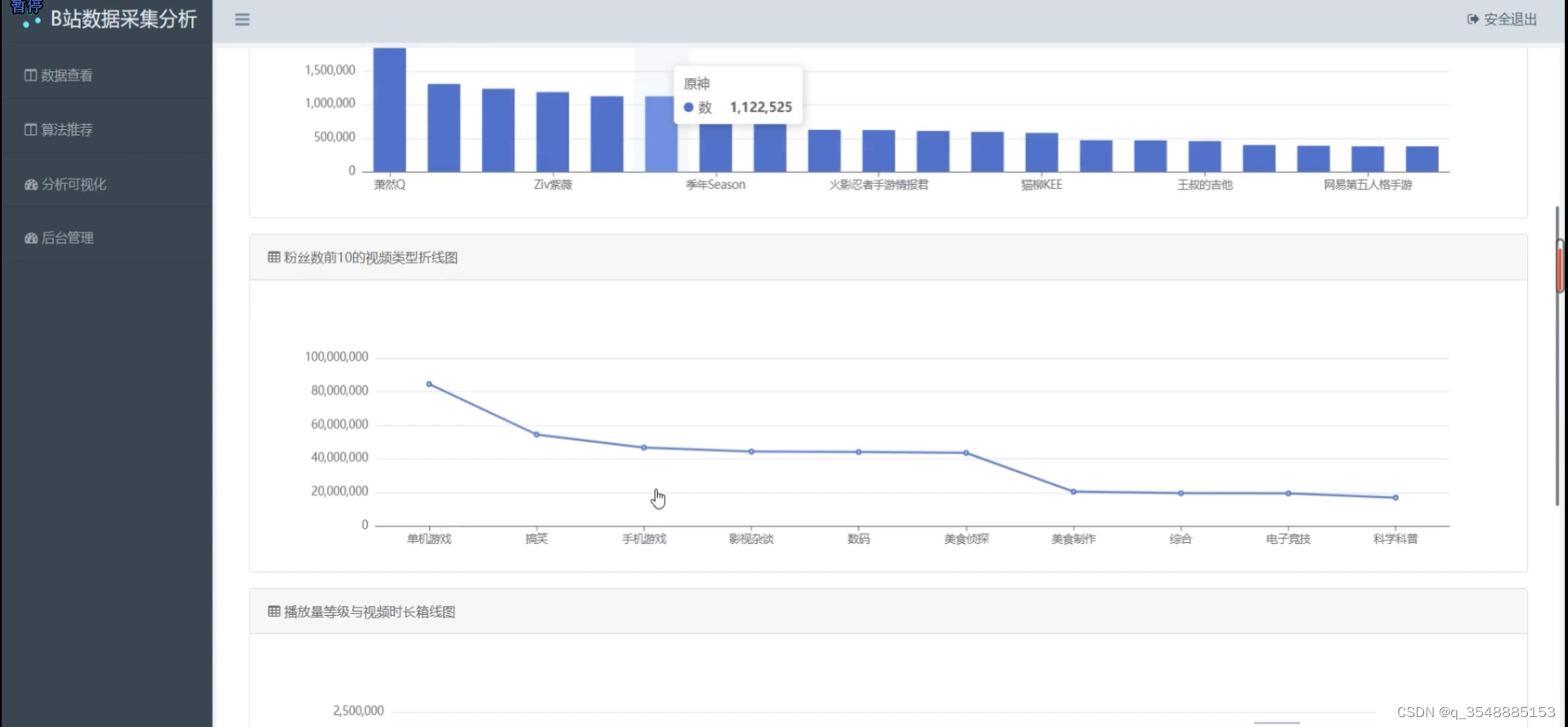
(3)各视频类型数据可视化分析3----散点图
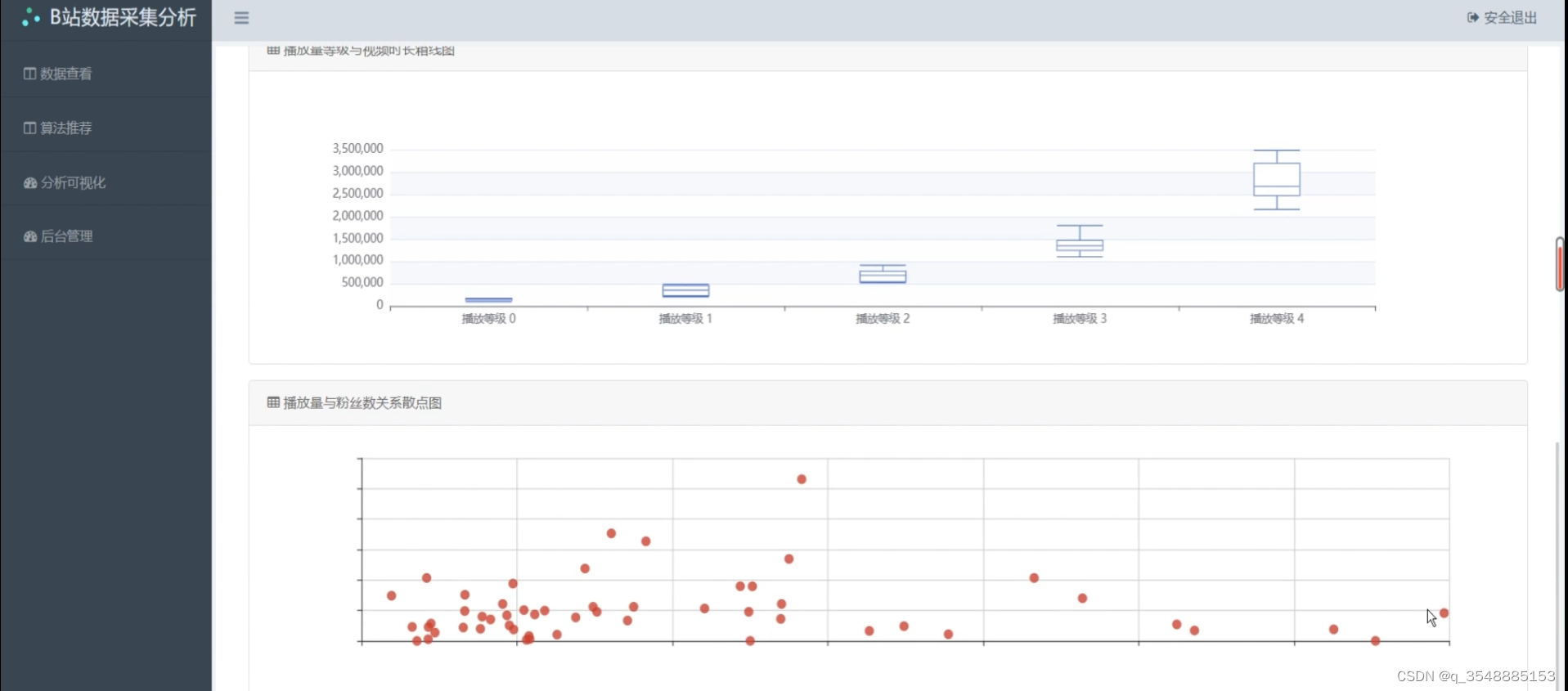
(4)B站数据展示
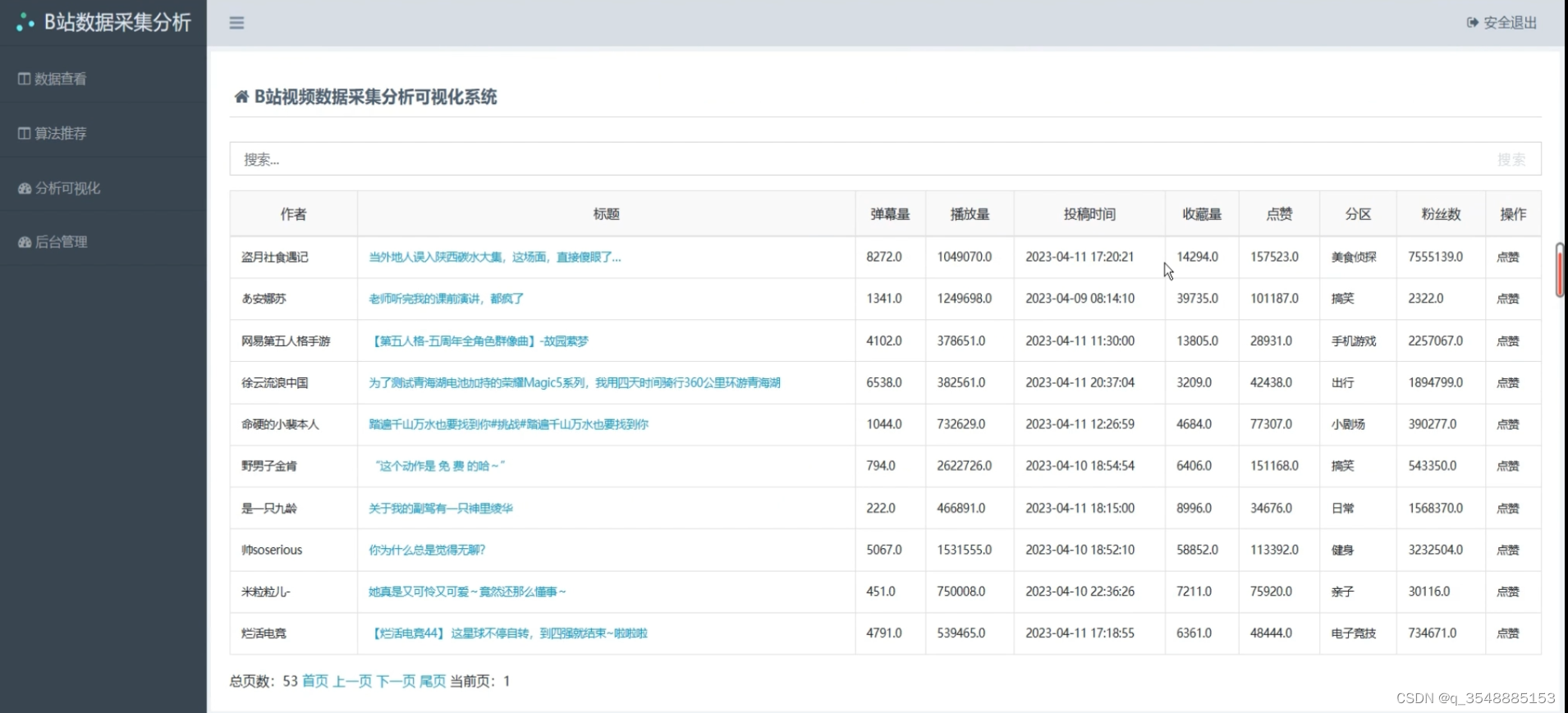
(5)后台数据管理
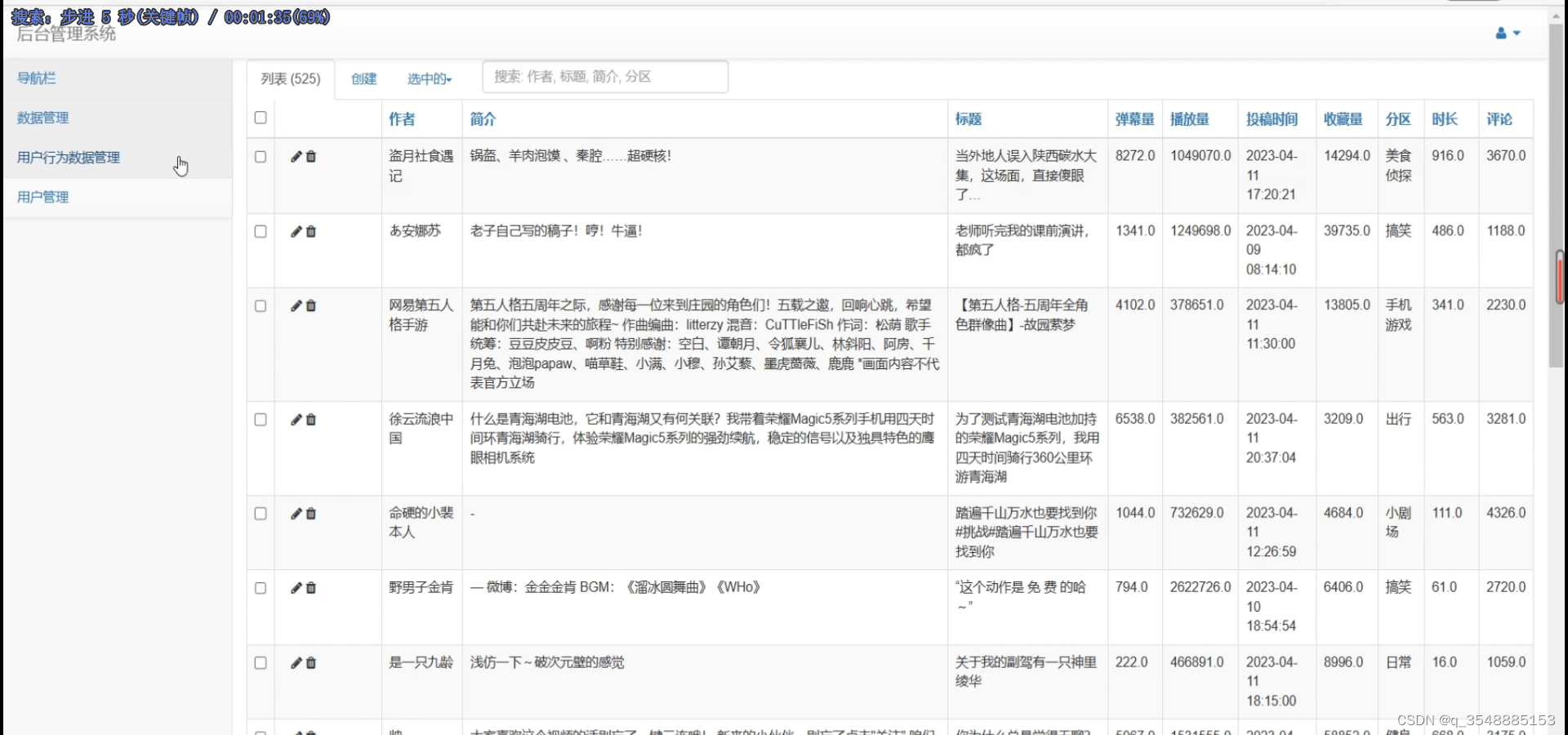
(6)注册登录界面
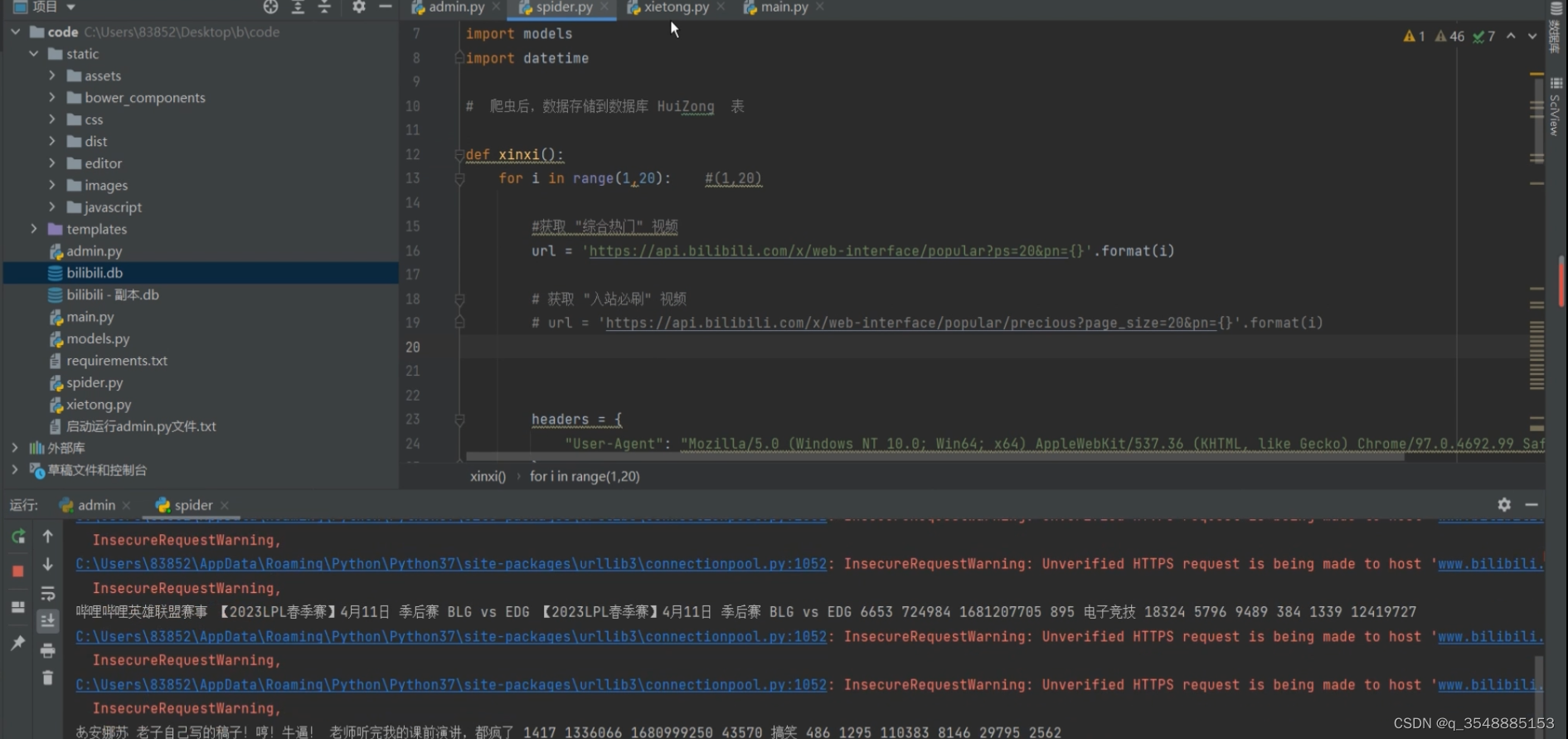
(7)数据爬取界面展示
3、项目说明
B站数据采集分析、推荐与可视化分析系统是一个强大的工具,它利用Python语言、Flask框架、requests爬虫技术、协同过滤推荐算法以及sqlite数据库等关键技术栈,实现了对Bilibili(B站)数据的深度采集、智能分析和精准推荐,并通过丰富的可视化界面展示了分析结果。
数据采集
系统首先通过requests爬虫技术,对B站进行网络爬虫操作,获取包括视频、弹幕、评论、用户信息等多种类型的数据。这些数据不仅反映了B站用户的观看习惯、兴趣爱好,还包含了大量有价值的用户行为信息。
数据存储
采集到的数据被存储到sqlite数据库中,sqlite作为一个轻量级的数据库解决方案,能够在保证数据完整性和安全性的同时,提供高效的数据查询和检索功能。
数据分析
在数据分析环节,系统利用Python强大的数据处理能力,对采集到的数据进行清洗、整合和挖掘。特别是协同过滤推荐算法的应用,使得系统能够根据用户的历史行为和偏好,为用户推荐与其兴趣相似的视频、UP主或话题。这种个性化推荐功能,不仅提高了用户的使用体验,还增强了用户与B站平台的黏性。
可视化分析
系统的可视化分析功能是其一大亮点。通过丰富的图表和界面设计,系统能够将分析结果以直观、易懂的方式呈现出来。无论是用户行为分析、内容热度评估还是推荐算法效果验证,都能够通过可视化界面进行快速查看和理解。这不仅方便了数据分析师和决策者的工作,也使得普通用户能够更深入地了解B站平台的数据情况。
前台与后台
系统分为前台和后台两个部分。前台主要面向普通用户,提供了视频推荐、热门话题、用户关注等功能,使用户能够更加方便地浏览和发现感兴趣的内容。后台则面向管理员和数据分析师,提供了数据管理、数据分析、推荐算法配置等功能,使管理员能够实时监控系统的运行状态,数据分析师能够深入挖掘数据背后的价值。
总之,B站数据采集分析、推荐与可视化分析系统是一个功能强大、易于使用的数据分析工具。它不仅能够为B站平台提供精准的用户推荐和数据分析支持,还能够为数据分析师和决策者提供有力的决策依据。随着B站平台的不断发展和壮大,该系统将继续发挥其在数据分析和推荐领域的重要作用。
4、核心代码
#!/usr/bin/python
# -*- coding: UTF-8 -*-
from math import sqrt
import operator
#1.构建用户-->视频的倒排
def loadData(files):
data ={
};
for line in files:
user,score,item=line 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2105
2105

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









