










博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2025年计算机专业毕业设计选题汇总(建议收藏)✅
2、大数据毕业设计:2025年选题大全 深度学习 python语言 JAVA语言 hadoop和spark(建议收藏)✅
1、项目介绍
一、技术栈:
Python语言、数据库、Django框架、机器学习随机森林算法数据分析、echarts可视化、HTML、阿里云-天池比赛、40w数据
二、赛题背景
本次新人赛是Datawhale与天池联合发起的0基础入门系列赛事第一场 —— 零基础入门数据挖掘之二手车交易价格预测大赛。
赛题以二手车市场为背景,要求选手预测二手汽车的交易价格,这是一个典型的回归问题。
任务: 预测二手车的交易价格。
该数据来自某交易平台的二手车交易记录,总数据量超过40w,包含31列变量信息,其中15列为匿名变量。
为了保证比赛的公平性,将会从中抽取15万条作为训练集,5万条作为测试集A,5万条作为测试集B,同时会对name、model、brand和regionCode等信息进行脱敏。
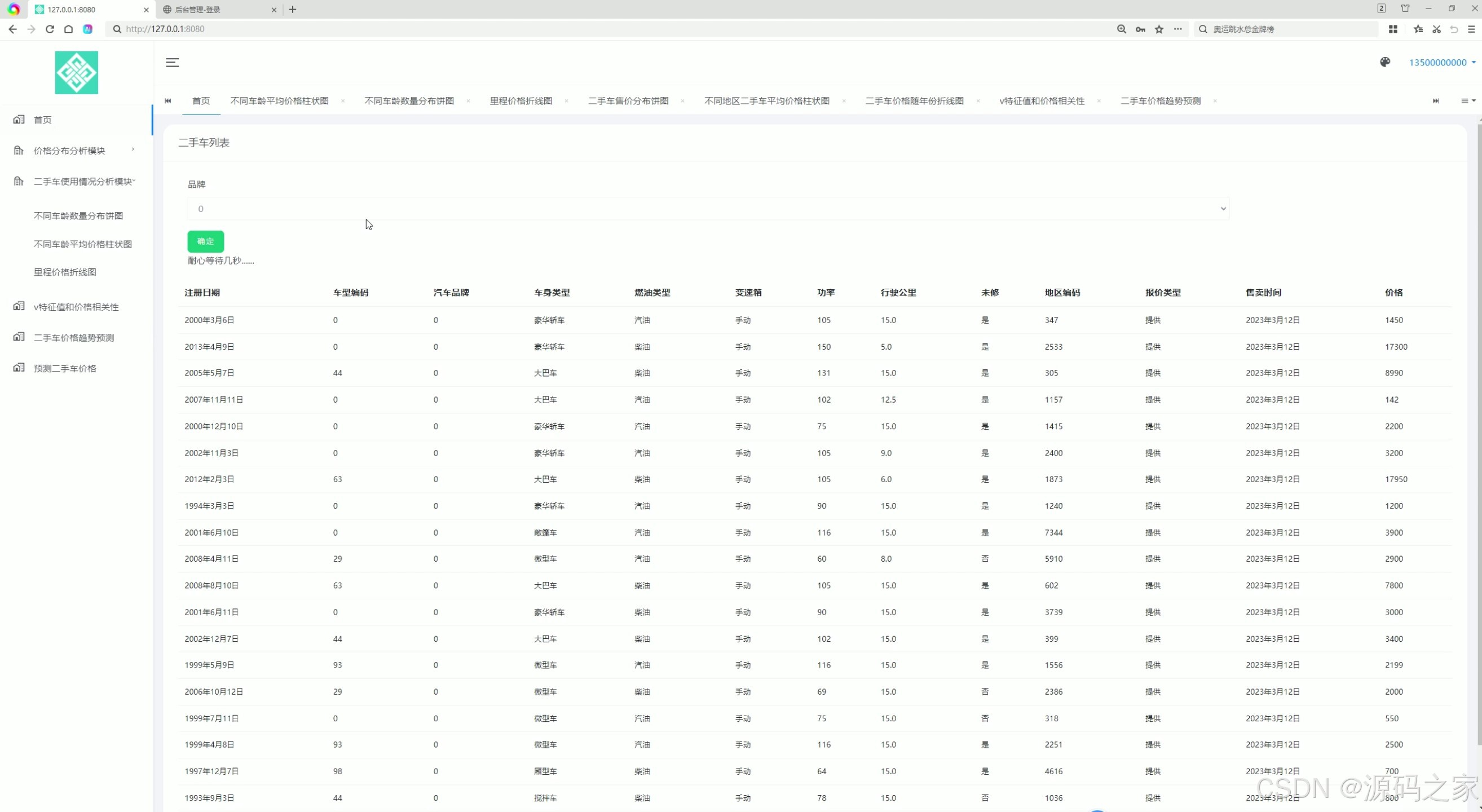
2、项目界面
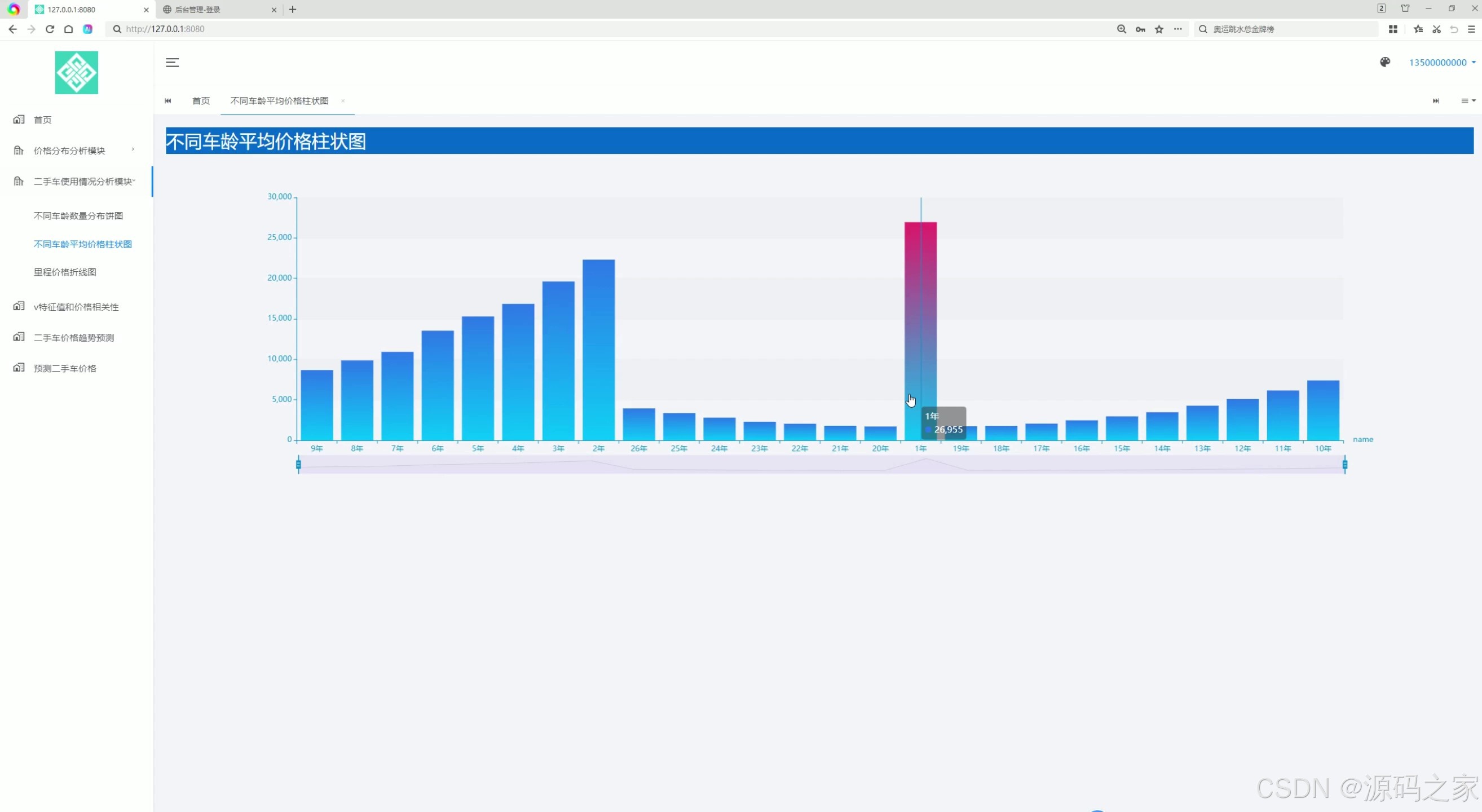
(1)不同车龄平均价格柱状图分析
(2)不同车龄数量分布饼图

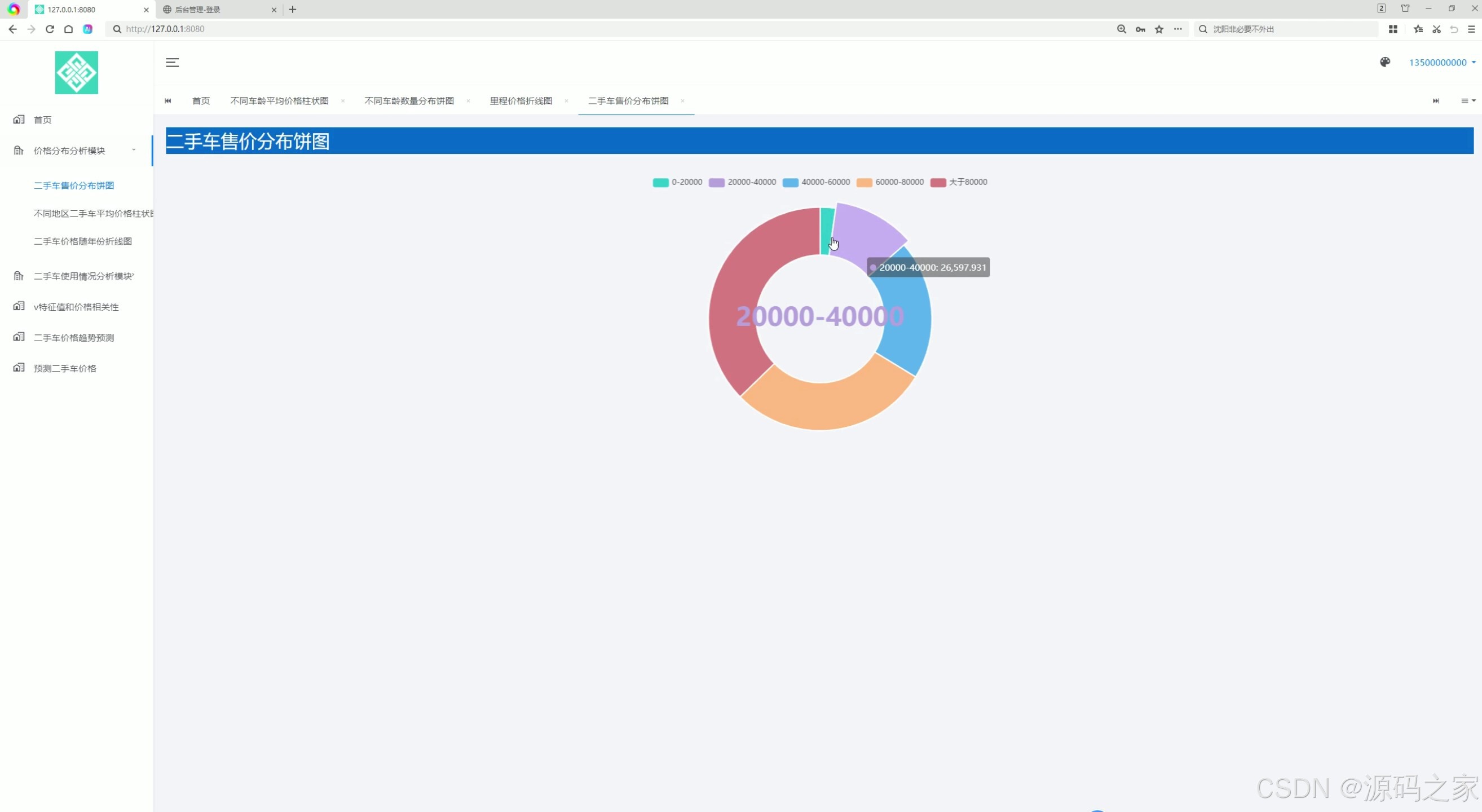
(3)二手车售价分布饼图
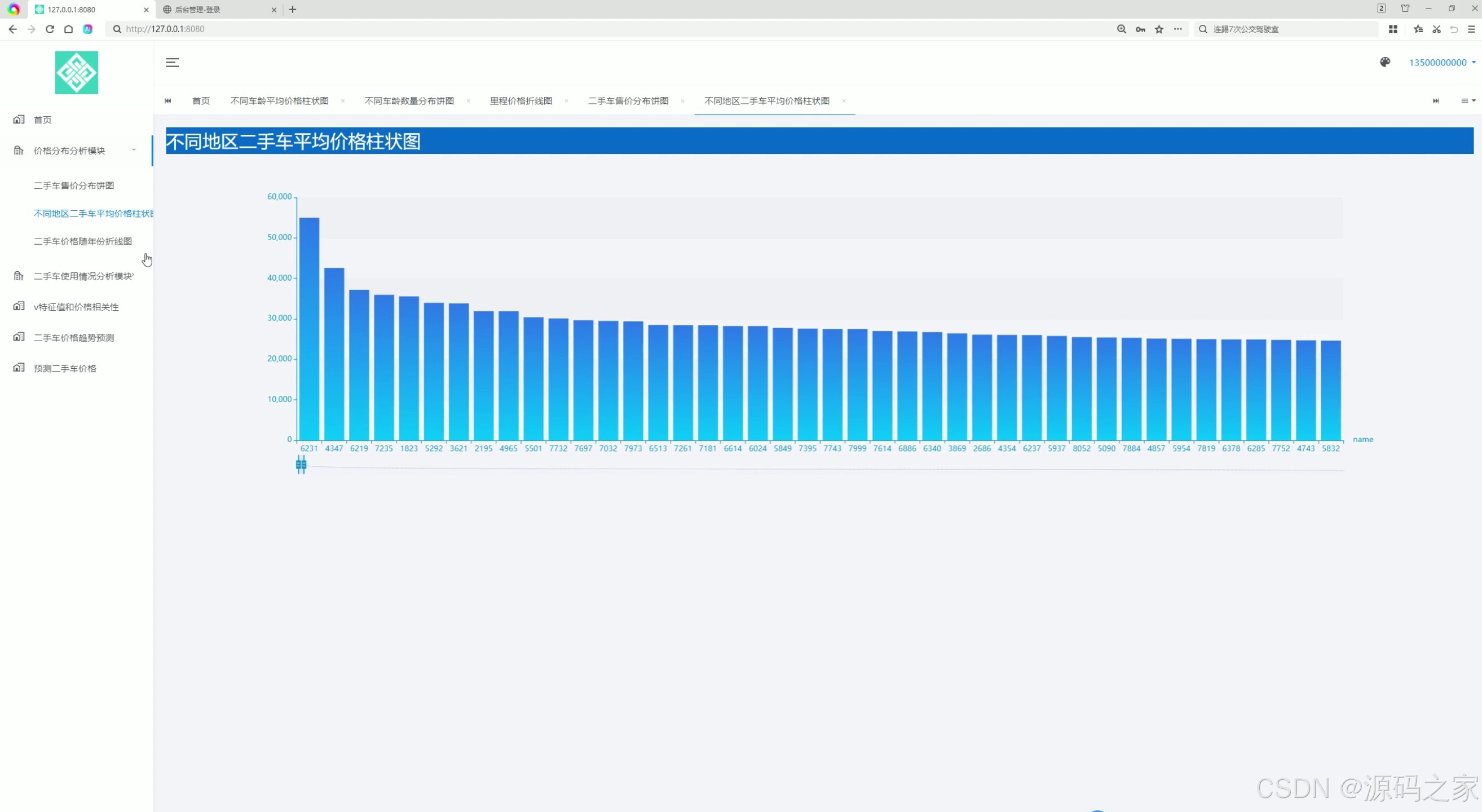
(4)不同地区二手车平均价格柱状图分析
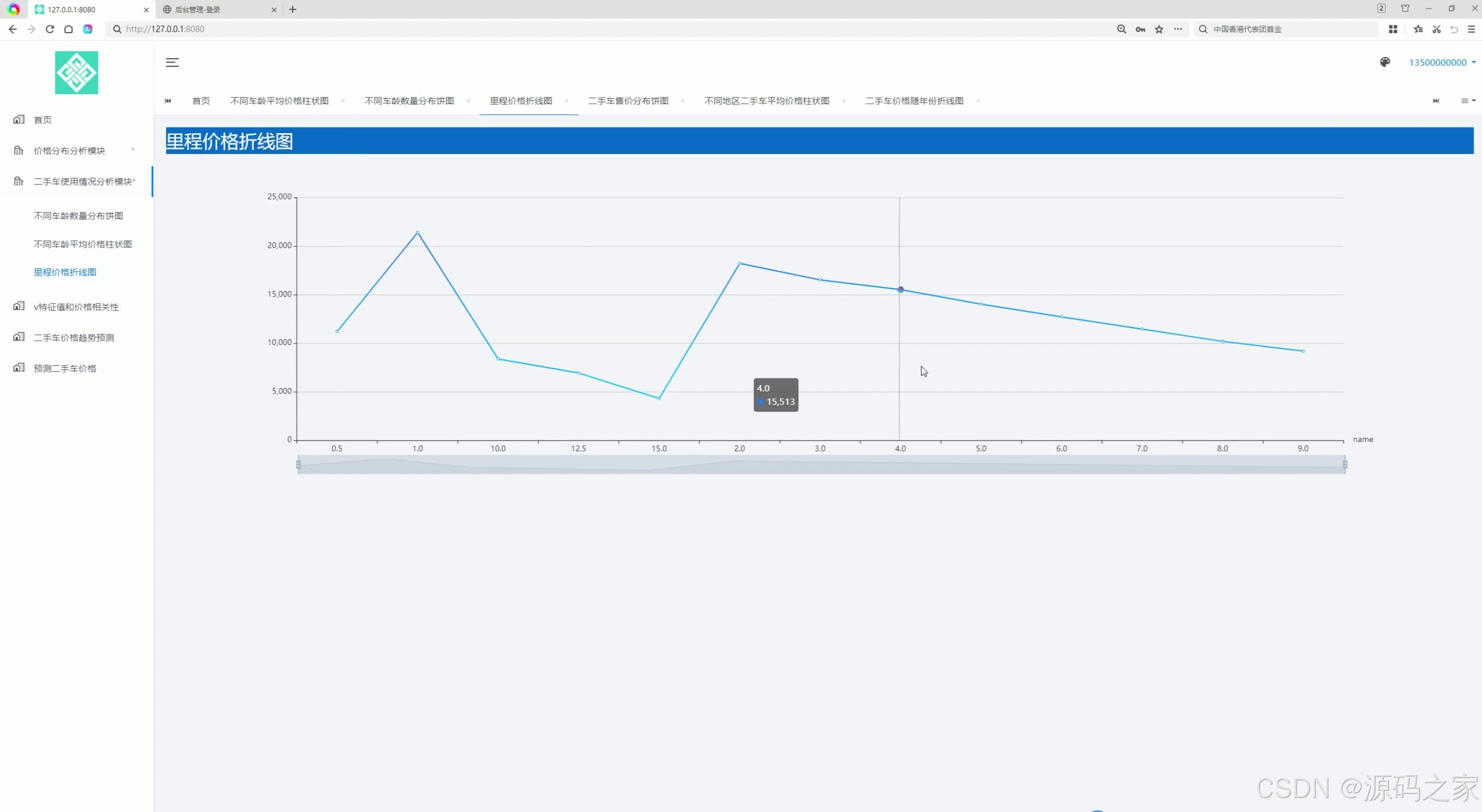
(5)里程价格折线图分析
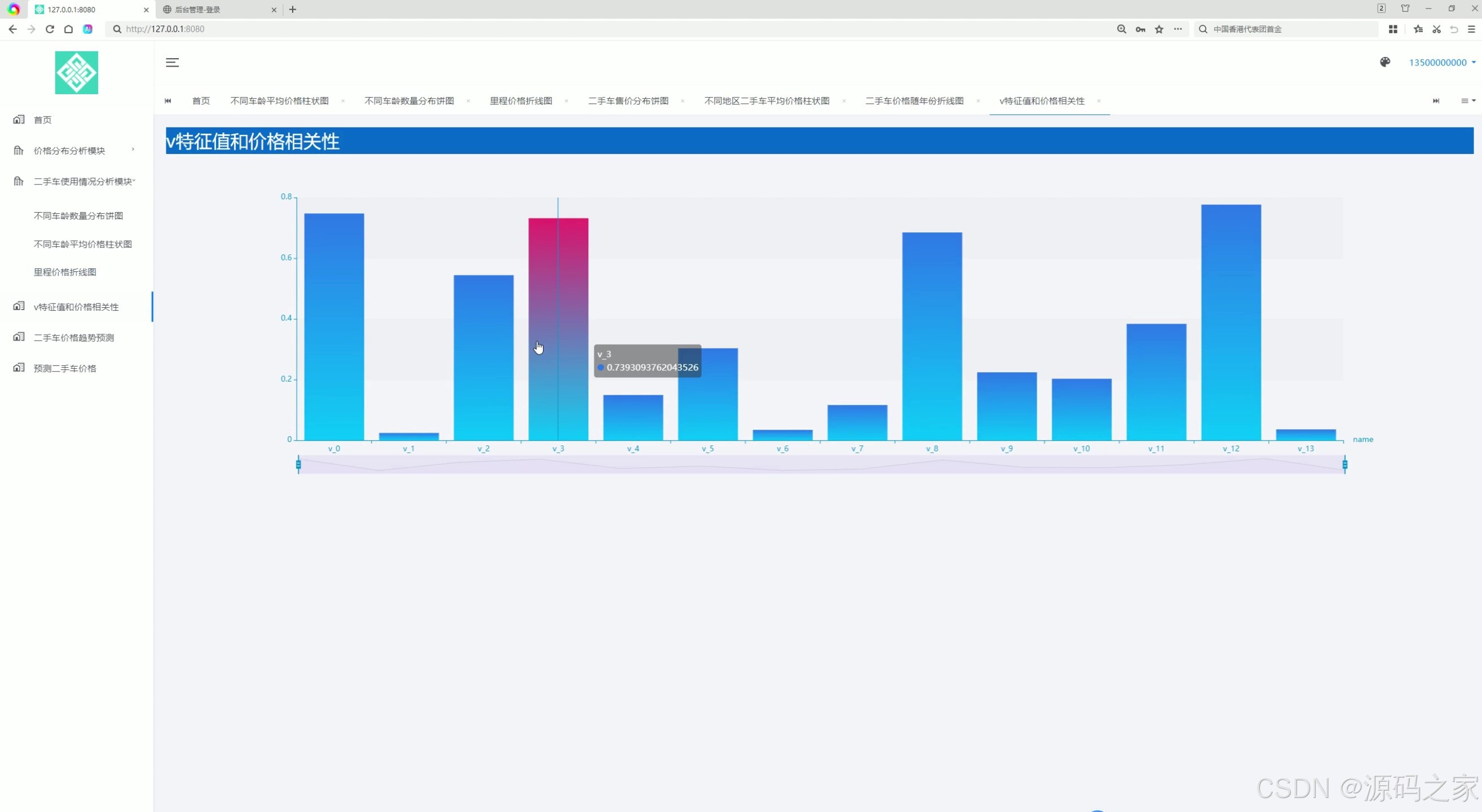
(6)特征值和价格相关性分析
(7)二手车价格预测
(8)注册登录界面
3、项目说明
1. 不同车龄平均价格柱状图分析
- 功能描述:通过柱状图展示不同车龄的二手车平均价格。用户可以直观地看到车龄与价格之间的关系,例如车龄越长,平均价格通常越低。
- 应用场景:帮助用户了解车龄对二手车价格的影响,为购车决策提供参考。
2. 不同车龄数量分布饼图
- 功能描述:以饼图的形式展示不同车龄的二手车数量分布。通过饼图可以直观地看出各个车龄段的占比情况。
- 应用场景:帮助用户了解二手车市场的车龄分布情况,为市场分析提供数据支持。
3. 二手车售价分布饼图
- 功能描述:展示二手车售价的分布情况,通过饼图将价格区间进行分类展示,用户可以快速了解不同价格区间的二手车占比。
- 应用场景:为用户和卖家提供价格分布的直观信息,帮助他们了解市场定价范围。
4. 不同地区二手车平均价格柱状图分析
- 功能描述:分析不同地区的二手车平均价格差异,通过柱状图展示各地区的价格对比。
- 应用场景:帮助用户了解地区差异对二手车价格的影响,为跨区域购车或卖车提供参考。
5. 里程价格折线图分析
- 功能描述:通过折线图展示里程与价格之间的关系。用户可以直观地看到里程增加对二手车价格的影响。
- 应用场景:为用户和卖家提供里程与价格关系的直观展示,帮助他们更好地评估车辆价值。
6. 特征值和价格相关性分析
- 功能描述:分析车辆的各种特征(如车龄、里程、品牌等)与价格之间的相关性。通过图表展示哪些特征对价格影响较大。
- 应用场景:为数据分析和模型训练提供依据,帮助用户了解哪些因素对二手车价格的影响最为显著。
7. 二手车价格预测
- 功能描述:基于机器学习算法(如随机森林)对二手车价格进行预测。用户输入车辆的相关特征后,系统会给出预测价格。
- 应用场景:为用户提供价格预测服务,帮助他们更好地评估车辆价值,为买卖双方提供参考。
8. 注册登录界面
- 功能描述:用户可以通过注册和登录功能访问系统,系统会为用户提供个性化的服务和数据存储功能。
- 应用场景:保障用户数据的安全性和隐私性,同时为用户提供便捷的操作体验。
4、核心代码
def plot5(request):
os.makedirs('plot', exist_ok=True)
filename = 'plot/plot5.pkl'
if os.path.exists(filename):
x_data,y_data = joblib.load(filename)
else:
raw_data = CarHand.objects.all()
tmp_dict = {}
for i in raw_data:
year = (i.days - 1) // 360 + 1
year = f'{year}年'
# 对年份字符串进行排序
year = sorted(year)
print(year)
tmp_dict.setdefault(year,[])
tmp_dict[year] = tmp_dict.get(year) + [i.price, ]
#
tmp_dict = {
k: sum(v)//len(v)
for k, v in tmp_dict.items()
}
# 排序
sort_list = sorted(tmp_dict.items(), key=lambda x: x[1],reverse=True)
print(sort_list)
x_data = [i[0] for i in sort_list]
y_data = [i[1] for i in sort_list]
data = [x_data,y_data]
joblib.dump(data, filename)
return render(request, 'plot5.html', locals())
def plot6(request):
os.makedirs('plot', exist_ok=True)
filename = 'plot/plot6.pkl'
if os.path.exists(filename):
x_data, y_data = joblib.load(filename)
else:
raw_data = CarHand.objects.all()
tmp_dict = {}
for i in raw_data:
licheng = str(i.kilometer)
tmp_dict.setdefault(licheng, [])
tmp_dict[licheng] = tmp_dict.get(licheng) + [i.price, ]
#
tmp_dict = {
k: sum(v) // len(v)
for k, v in tmp_dict.items()
}
# 排序
sort_list = sorted(tmp_dict.items(), key=lambda x: x[0])
print(sort_list)
x_data = [i[0] for i in sort_list]
y_data = [i[1] for i in sort_list]
data = [x_data, y_data]
joblib.dump(data, filename)
return render(request, 'plot6.html', locals())
def plot7(request):
os.makedirs('plot', exist_ok=True)
filename = 'plot/plot7.pkl'
if os.path.exists(filename):
x_data, y_data = joblib.load(filename)
else:
raw_data = CarHand.objects.all()
# 分组
tmp_data = raw_data.values('gearbox').annotate(count=Avg('price'))
tmp_data = {i['gearbox']: i['count'] for i in tmp_data}
# 排序
sort_list = sorted(tmp_data.items(), key=lambda x: x[0], reverse=True)
x_data = [str(i[0]) for i in sort_list]
y_data = [i[1] for i in sort_list]
data = [x_data, y_data]
joblib.dump(data, filename)
return render(request, 'plot7.html', locals())
def plot8(request):
os.makedirs('plot', exist_ok=True)
filename = 'plot/plot8.pkl'
if os.path.exists(filename):
x_data, y_data = joblib.load(filename)
else:
raw_data = CarHand.objects.all()
# 分组
tmp_data = raw_data.values('bodyType').annotate(count=Avg('price'))
tmp_data = {i['bodyType']: i['count'] for i in tmp_data}
# 排序
sort_list = sorted(tmp_data.items(), key=lambda x: x[0], reverse=True)
x_data = [str(i[0]) for i in sort_list]
y_data = [i[1] for i in sort_list]
data = [x_data, y_data]
joblib.dump(data, filename)
return render(request, 'plot8.html', locals())
def plot9(request):
os.makedirs('plot', exist_ok=True)
filename = 'plot/plot9.pkl'
if os.path.exists(filename):
x_data, y_data = joblib.load(filename)
else:
raw_data = CarHand.objects.all()
# 分组
tmp_data = raw_data.values('brand').annotate(count=Count('brand'))
tmp_data = {i['brand']: i['count'] for i in tmp_data}
# 排序
sort_list = sorted(tmp_data.items(), key=lambda x: x[1], reverse=True)
data = [
{'value': v, 'name': k}
for k, v in sort_list
]
joblib.dump(data, filename)
return render(request, 'plot9.html', locals())
def plot10(request):
os.makedirs('plot', exist_ok=True)
filename = 'plot/plot10.pkl'
if os.path.exists(filename):
x_data, y_data = joblib.load(filename)
else:
raw_data = CarHand.objects.all()
# 分组
tmp_data = raw_data.values('power').annotate(count=Avg('price'))
tmp_data = {i['power']: i['count'] for i in tmp_data}
# 排序
sort_list = sorted(tmp_data.items(), key=lambda x: x[0])
x_data = [str(i[0]) for i in sort_list]
y_data = [i[1] for i in sort_list]
data = [x_data, y_data]
joblib.dump(data, filename)
return render(request, 'plot10.html', locals())
def plot11(request):
import datetime
now_time = datetime.datetime.now() # 日期对象
# 预测的数据
pre_data = []
for i in range(1,7):
tmp_date = now_time + datetime.timedelta(days=30 * i)
pre_data.append([
tmp_date.year, tmp_date.month, tmp_date.day
])
model = joblib.load('model/model_date.pkl')
pre_list = model.predict(pre_data)
x_data = [f'未来{i}月' for i in range(1,7)]
y_data = [int(i) for i in pre_list]
return render(request, 'plot11.html', locals())
def plot12(request):
x_data = [f'v_{i}' for i in range(14)] # v特征
y_data = [0.754941551268356, 0.024251731159680205, 0.5495943633382925, 0.7393093762043526, 0.1506070454983662, 0.30624676044263843, 0.03462380346459138, 0.11722533620326846, 0.6917814292781741, 0.22631654082941277, 0.204791017058243, 0.38750050009134884, 0.7844431919628817, 0.036181438327402775]
return render(request, 'plot12.html', locals())
class predict2(View):
# get请求
def get(self, request):
final_columns = ['brand', 'v_7', 'model', 'v_4', 'notRepairedDamage', 'fuelType', 'v_10',
'v_9', 'bodyType', 'power', 'v_5', 'gearbox', 'v_11', 'kilometer',
'v_2', 'days', 'v_8', 'v_3', 'v_0', 'v_12', ]
raw_data = CarHand.objects.all()
onedata = raw_data[0]
tmp_list = [item.brand for item in raw_data]
brand_list = list(sorted(list(set(tmp_list))))
tmp_list = [item.model for item in raw_data]
model_list = list(sorted(list(set(tmp_list))))
bodyType_dict = [{'name': '豪华轿车', 'value': 0}, {'name': '微型车', 'value': 1}, {'name': '厢型车', 'value': 2},
{'name': '大巴车', 'value': 3}, {'name': '敞篷车', 'value': 4}, {'name': '双门汽车', 'value': 5},
{'name': '商务车', 'value': 6}, {'name': '搅拌车', 'value': 7}]
bodyType_list = ['豪华轿车', '微型车', '厢型车', '大巴车', '敞篷车', '双门汽车', '商务车', '搅拌车']
fuelType_dict = [{'name': '汽油', 'value': 0}, {'name': '柴油', 'value': 1}, {'name': '液化石油气', 'value': 2},
{'name': '天然气', 'value': 3}, {'name': '混合动力', 'value': 4}, {'name': '其他', 'value': 5},
{'name': '电动', 'value': 6}]
fuelType_list = ['汽油', '柴油', '液化石油气', '天然气', '混合动力', '其他', '电动']
print(fuelType_dict)
return render(request, 'predict2.html', locals())
# psot请求
def post(self, request):
postdata = request.POST
postdata = dict(postdata)
print(postdata)
# 得到表单参数
for k, v in postdata.items():
postdata[k] = v[0]
print(postdata)
final_columns = ['brand', 'v_7', 'model', 'v_4', 'notRepairedDamage', 'fuelType', 'v_10',
'v_9', 'bodyType', 'power', 'v_5', 'gearbox', 'v_11', 'kilometer',
'v_2', 'days', 'v_8', 'v_3', 'v_0', 'v_12', ]
pre_data = [
eval(postdata[col])
for col in final_columns
]
pre_data = [pre_data,pre_data]
model = joblib.load('model/model.pkl')
result = model.predict(pre_data)[0]
result = int(result)
message = f"预测的价格为{result}"
return JsonResponse({'data': 'data', 'code': 200, 'message': message, 'count': 'total'})
5、源码获取方式
biyesheji0005 或 biyesheji0001 (绿色聊天软件)
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻

















 1258
1258

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









