






2024年4月3日,Peter R. Girguis、Sergey Ovchinnikov、Yunha Hwang、Andre L. Cornman和Elizabeth H. Kellogg几人在Nature Communications上发表了一篇题为“Genomic language model predicts protein co-regulation and function”的研究文章。
这项研究开发了一种基因组语言模型(gLM),通过训练数百万的宏基因组拼接片段,学习了基因之间的潜在功能和调控关系。这一模型不仅能够捕捉到蛋白质序列本身,还能编码生物学上有意义且与功能相关的信息,如酶功能、分类等。
通过对注意力模式的分析,研究揭示了gLM能够学习到协同调控的功能模块(即操纵子)。该研究表明,gLM的无监督深度学习方法有效且有前景,能够编码基因在其基因组上下文中的功能语义和调控句法,揭示复杂基因组区域中基因间的复杂关系。此项工作不仅为理解基因功能与调控提供了新视角,也为未来的迁移学习应用和研究方向奠定了基础。

引言
进化过程使蛋白质的序列、结构和功能相互关联。这种序列-结构-功能的理念帮助我们理解大量基因组数据。近期,基于神经网络的蛋白质结构预测方法和蛋白质语言模型(pLMs)的进展,显示了通过非监督学习处理复杂的生物进化关系的可能性。目前这些模型大多视蛋白质为独立实体,但实际上蛋白质是在基因组中与其他蛋白质一起存在的,它们所在的基因组环境是通过进化过程,包括基因的获得、丢失、复制和转位等事件形成的。特别是在细菌和古菌中,水平基因转移(HGT)显著影响了基因组的组织和多样性。因此,基因与其基因组环境和功能之间存在着进化上的内在联系,这可以通过分析大型宏基因组数据集来探索。
最近的研究表明,通过模拟基因组信息可以预测基因功能和细菌及古菌基因组中的代谢性状进化。但这些方法通常将基因作为分类实体来处理,没有考虑基因在连续空间中的多维特性,如系统发育、结构和功能。另一方面,也有研究通过非监督学习来分析核苷酸序列,预测基因表达水平和检测调控基序,但这些模型主要关注人类基因组的基因调控而非功能。
为了学习生物学中基因与基因环境互作的通用模式,需要一个模型能够预训练于1)多样的生物类群,2)丰富且连续的基因表示,3)包含多个基因的长基因组片段。目前尚无结合这三个方面来学习生物多样性中基因组信息的方法。
为了解决这一问题,研究团队开发了一种基因组语言模型(gLM),通过学习基因的上下文表示来弥合基因组环境与基因序列-结构-功能之间的关系。gLM利用pLM的嵌入作为输入,这些嵌入编码了基因产品的关系属性和结构信息。该模型基于Transformer架构,通过遮蔽语言建模任务,使用未标记的宏基因组序列进行训练,以学习基因功能语义和调控语法。研究团队展示了gLM在预测基因功能和共调控方面的潜力,并提出了未来的研究方向和应用,包括gLM的转移学习能力。
关键字:基因组语言模型、宏基因组、功能基因预测、蛋白质相互作用
研究内容
在这项研究中,研究团队采纳了一项创新方法来训练和实施基因组语言模型(gLM),旨在探索基因与其基因组上下文之间的复杂关联。
首先,他们构建了一个庞大的序列数据库,利用MGnify数据库为基础,并通过mmseqs/linclust工具将每个基因映射到对应的代表性蛋白质序列上。这个过程生成了超过七百三十万个包含15至30基因的子拼接片段,为研究提供了一个丰富的数据集。
随后,研究团队采用了基于RoBERTa transformer架构的gLM,该模型包含19层,每层有10个注意力头。通过掩码语言模型任务进行训练,大约15%的基因序列被随机掩码,模型被训练以预测这些被掩码的基因的标签。每个基因被表示为一个1281特征向量,其中1280个特征源自ESM2蛋白质语言模型产生的蛋白质嵌入,另外一个特征用于表示基因的方向。
研究团队展示了基因组语言模型(gLM)在捕捉基因与其基因组上下文之间复杂关系方面的显著成果。通过对超过730万个宏基因组拼接片段的深入学习,gLM成功地学习了基因之间的潜在功能和调控关系。特别是,gLM生成的上下文蛋白质嵌入能够捕获与生态环境相关的信息,例如在不同生物群系中相同蛋白质的不同表示,从而显示了基因表达的环境依赖性。
此外,gLM还展示了其在解析未知功能基因方面的潜力,通过减少注释和未注释基因分布之间的差异,为迁移已知生物学知识到未培养的宏基因组序列空间提供了可能性。研究团队还利用gLM改进了酶功能的预测,证明了gLM从基因组上下文中学习到的信息是有价值的,并且与蛋白质序列中捕获的信息互补。通过分析注意力模式,研究团队发现gLM能够识别出协同调控的功能模块,如操纵子,这进一步证实了模型在理解基因组结构和功能方面的能力。
总而言之,研究团队的方法结合了深度学习技术、大规模宏基因组数据集以及先进的模型架构,成功开发出一种强大的工具,能够洞察和揭示基因在其基因组上下文中的功能和调控关系。这种方法不仅为理解基因在复杂生物系统中的相互作用提供了新的视角,也为未来的生物学研究和应用铺平了道路。
研究结果
基因组序列的掩码语言建模
语言模型,如双向编码器表示变换器(BERT25),通过对大规模语料库进行无监督训练,学习自然语言的语义和句法。在掩码语言建模中,模型的任务是重构被破坏的输入文本,其中一部分词被掩盖。通过采用Transformer神经网络架构,在语言建模性能上取得了显著进展,每个标记(即单词)能够关注其他标记。这与长短期记忆网络(LSTMs)顺序处理标记形成对比。
为了建模基因组序列,研究团队在七百万个由15至30个基因组成的宏基因组拼接片段上训练了一个19层变换器模型(图1A),这些拼接片段来自MGnify数据库。基因组序列中的每个基因都由使用ESM2 pLM23生成的1280特征向量(上下文无关的蛋白质嵌入)表示,并与一个方向特征(向前或向后)相连。
对于每个序列,随机掩盖15%的基因,模型学习使用基因组上下文预测掩盖的标签。基于一个特定基因组上下文中可以发现多于一个基因的洞见,研究团队允许模型做出四个不同的预测,并且还预测它们的关联概率。因此,模型可以近似估计可以占据基因组生态位的多个基因的底层分布,而不是预测它们的平均值。
研究团队使用一个伪准确度指标评估模型的性能,如果预测与序列中编码的其他蛋白质相比,距离掩盖蛋白质的欧几里得距离最近,则认为预测是正确的。研究团队在大肠杆菌K-12基因组上验证模型的性能,从训练中排除了5.1%的MGnify亚拼接片段,这些片段中超过一半的蛋白质与大肠杆菌K-12蛋白质相似(>70%序列同一性)。
值得注意的是,研究团队的目标不是从训练中移除所有大肠杆菌K-12同源物,这样会移除绝大多数训练数据,因为许多基本基因在生物间是共享的。相反,研究团队的目标是从训练中移除尽可能多的大肠杆菌K-12类似的基因组上下文(亚拼接片段),这更适合训练目标。gLM在验证伪准确度中达到71.9%,在验证绝对准确度中达到59.2%。值得注意的是,在验证期间,53.0%的预测是高信心的(预测可能性>0.75),而75.8%的高信心预测是正确的,表明gLM能够学习一个与增加的准确度相对应的信心度量。研究团队将性能与使用相同的语言建模任务在相同的训练数据集上训练的双向LSTM模型作为基准,其中验证性能在28%的伪准确度和15%的绝对准确度上达到高点(请注意,biLSTM较小,因为在扩大层数时未能收敛)。研究团队通过将pLM表示作为输入到gLM的使用进行消融,将它们替换为一位热氨基酸表示,并报告性能等同于随机预测(3%伪准确度和0.02%绝对准确度)。
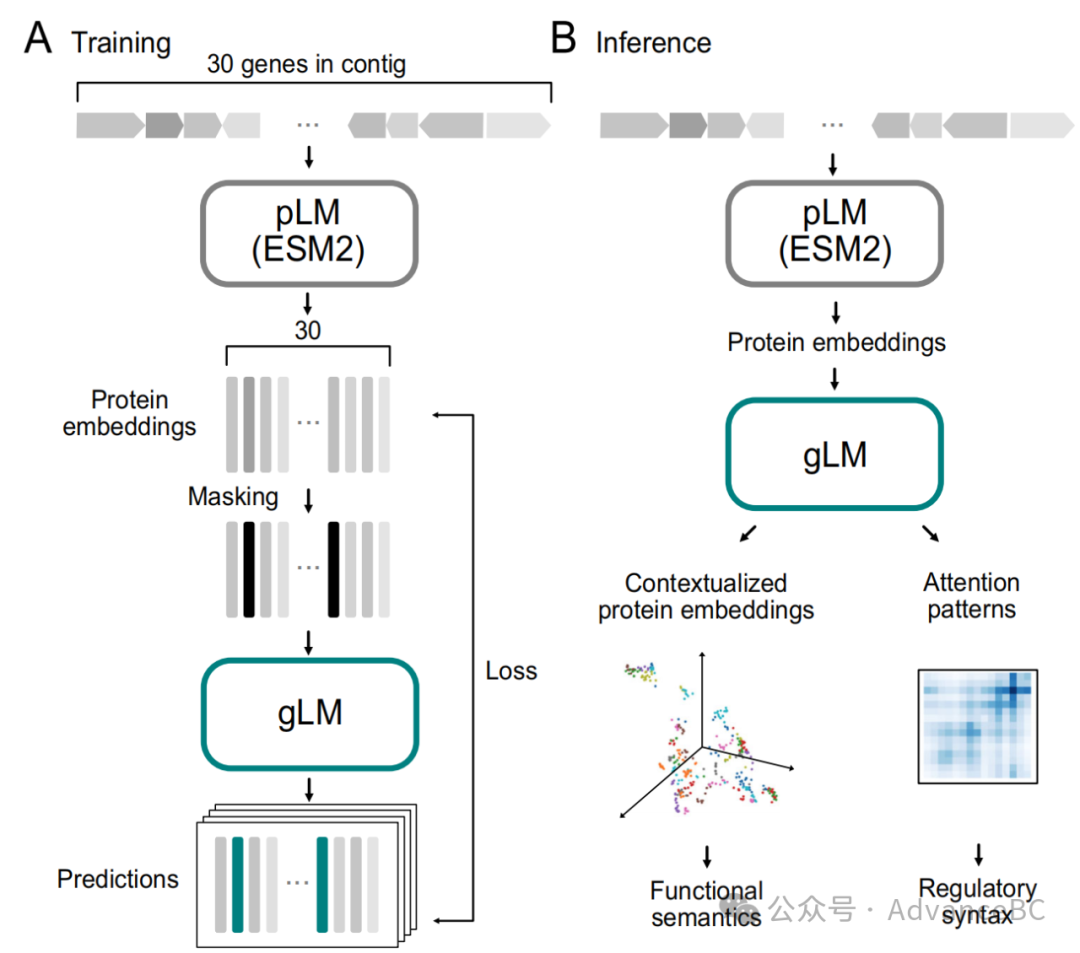
图1:gLM训练和推理示意图
上下文化的基因嵌入捕获基因语义
生物体中从基因到基因功能的映射并非一对一的。与自然语言中的词语类似,一个基因可以根据其上下文赋予不同的功能,许多基因赋予相似的功能(即收敛进化,远端同源性)。研究团队使用gLM在推理时生成1280特征的上下文化蛋白质嵌入(图1B),并检查这些嵌入中捕捉到的“语义”信息。类似于词语可能根据它们所处的文本类型而具有不同含义的方式(图2A),研究团队发现跨多个环境(生物群落)出现的基因的上下文化蛋白质嵌入倾向于根据生物群落类型进行聚类。
研究团队在训练数据库(MGYPs)中识别出31种蛋白质,这些蛋白质出现次数超过100次,并且在“宿主相关”、“环境”和“工程”生物群落中根据MGnify的指定分布,每种至少有20次出现。研究团队发现gLM的上下文化蛋白质嵌入对大多数(n=21)这些多生物群落MGYPs捕捉到了生物群落信息。例如,编码蛋白质注释为“翻译启动因子IF-1”的基因在多个生物群落中多次出现。虽然输入到gLM的(无上下文蛋白质嵌入;ESM2表示)在所有出现中都是相同的,但gLM的输出(上下文化蛋白质嵌入)根据生物群落类型聚类(图2B;轮廓得分=0.17,另见其他30个多生物群落MGYP可视化)。这表明基因占据的多样化基因组上下文对不同的生物群落具有特异性,暗示了生物群落特定的基因语义。
研究团队探讨了基因组“多义性”(同一个词赋予多个含义;图2C)在生态上的重要示例,即甲基辅酶M还原酶(MCR)复合体。MCR复合体能够进行一个可逆反应(图2D中的反应1),其中前向反应导致产生甲烷(产甲烷作用),而反向反应结果在甲烷氧化(甲烷营养作用)。研究团队首先检查在ANME(无氧甲烷氧化)和产甲烷古菌基因组的多样系中McrA(甲基辅酶M还原酶亚单位alpha)蛋白。这些古菌是多系的,并占据特定的生态位。值得注意的是,类似于一个词在语义上存在一个光谱,并且一个词在一个上下文中可以有多个语义上适当的含义(图2C),MCR复合体可以根据上下文赋予不同的功能。之前的报告展示了ANME(特别是ANME-2)进行产甲烷作用的能力和在特定生长条件下产甲烷菌进行甲烷氧化的能力。这些蛋白质的无上下文ESM2嵌入(图2E)显示出很少的组织,ANME-1和ANME-2的McrA蛋白之间几乎没有分离。然而,上下文化的gLM嵌入(图2F)显示出McrA蛋白的明显组织,其中ANME-1的McrA蛋白形成一个紧密的聚类,而ANME-2的McrA蛋白与产甲烷菌形成一个聚类(上下文化后的轮廓得分:0.24;上下文化前:0.027)。这种组织反映了McrAs所在的生物之间的系统发育关系,以及与ANME-2和产甲烷菌中发现的MCR复合体相比,ANME-1中MCR复合体的独特操纵子和结构分化。正如Shao等人所提议的,反应1(图2D)中的首选方向性在ANME-2和一些产甲烷菌中可能更依赖于热力学。
研究团队还展示了上下文化的gLM嵌入更适合确定基因类别之间的功能关系。类似于“狗”和“猫”的词语相对于“狗”和“火车”在含义上更接近的方式(图2G),研究团队看到一种模式,其中Cas1-和Cas2-编码基因在无上下文蛋白质嵌入空间中出现在多个子聚类中(图2H)在上下文化嵌入空间中聚类(图2I)。这反映了它们在功能上的相似性(例如,噬菌体防御)。这也在生物合成基因中得到证明,其中编码脂多糖合成酶(LPS)和聚酮合成酶(PKS)的基因在上下文化嵌入空间中比与Cas蛋白相比聚集得更紧密(图2I)。研究团队用更高的轮廓得分量化这种模式,测量噬菌体防御和生物合成基因分离(gLM表示:0.123 ± 0.021,pLM表示:0.085 ± 0.007;配对t检验,t统计量:5.30,双侧,p值=0.0005,n=10)。因此,上下文化的蛋白质嵌入能够捕捉与语义信息相似的关系属性,其中编码功能上更相似的蛋白质的基因在相似的基因组上下文中发现。
为了量化由于在基因组上下文上训练transformer而产生的信息增益,研究团队比较了2B、F和I中的聚类结果与在(亚)拼接片段平均pLM嵌入上进行的聚类。通过对给定亚拼接片段的pLM嵌入进行平均池化,研究团队可以将上下文信息总结为一个简单的基线。研究团队报告了与拼接片段平均pLM相比,gLM嵌入的聚类更一致(更高的轮廓得分)对于所有三个分析。研究团队展示了gLM变换器模型学习的表示与生物功能相关联,这些表示无法通过简单的基线捕捉到。
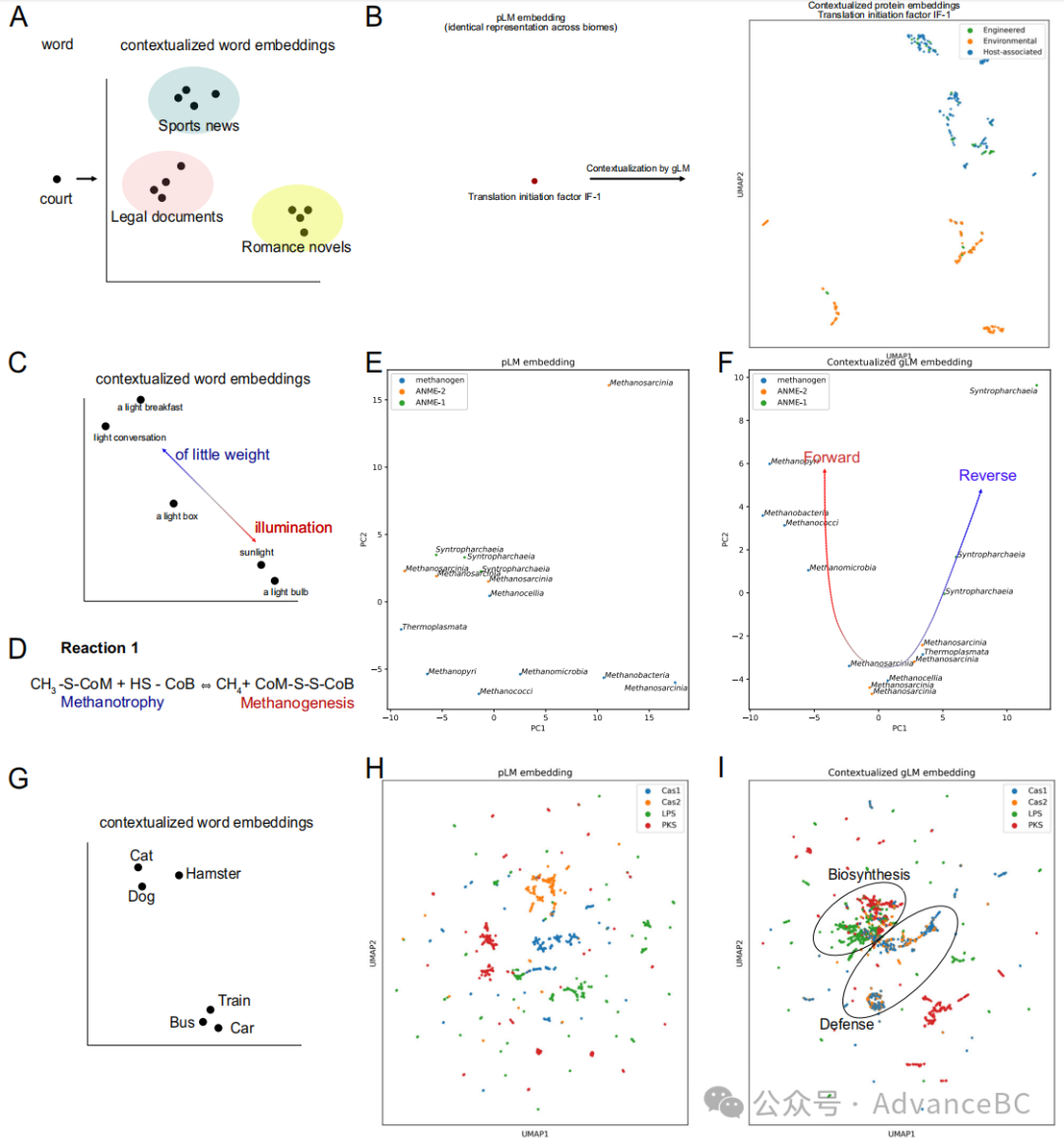
图2:上下文化蛋白质嵌入分析与自然语言建模中的概念比较
描述未知的特性
宏基因组序列特征许多具有未知或通用功能的基因,有些差异如此之大以致于它们与数据库注释部分的序列相似性不足。在我们的数据集中,3080万蛋白质序列中,19.8%不能与任何已知注释关联,27.5%不能使用最近的深度学习方法(ProtENN38)与任何已知的Pfam域关联。理解这些蛋白质在其生物体和环境上下文中的功能角色仍然是一个主要挑战,因为大多数寄宿这些蛋白质的生物体难以培养,实验室验证通常是低通量的。
在微生物基因组中,赋予相似功能的蛋白质由于功能关系(例如,蛋白质-蛋白质相互作用,共同调控)之间的选择压力而在相似的基因组上下文中被发现。基于这一观察,研究团队认为上下文化将提供更丰富的信息,将未注释基因的分布推向更接近于注释基因的分布。研究团队比较了他们数据集中未注释和注释蛋白质部分的分布,使用无上下文pLM嵌入和上下文化gLM嵌入。研究团队发现在gLM嵌入中未注释和注释基因分布之间的发散性显著降低,与pLM嵌入相比(成对t检验的Kullback-Leibler发散,t检验统计量=7.61,双侧,p值<1e-4,n=10)。这表明使用gLM嵌入转移在可培养且研究良好的菌株(例如,E. coli K-12)中验证的知识到广泛未培养的宏基因组序列空间的潜力更大。基因组上下文,连同分子结构和系统发育,似乎是重要信息,需要抽象化以有效代表序列,以便我们可以揭示生物学已知和未知部分之间的隐藏关联。
上下文化改善酶功能预测
为了测试蛋白质的基因组上下文能否被用来帮助功能预测的假设,研究团队评估了上下文化如何提高蛋白质表示的表现力,用于酶功能预测。首先,研究团队生成了一个自定义的MGYP-EC数据集,其中训练和测试数据按每个EC类别的30%序列同一性进行了划分。其次,研究团队应用线性探针(LP)比较每个gLM层的表示的表现力,无论是否掩蔽查询的蛋白质。通过掩蔽查询的蛋白质,研究团队可以评估gLM从其基因组上下文中,仅学习给定蛋白质的功能信息的能力,而不是从蛋白质的pLM嵌入中传播信息。研究团队观察到大部分与酶功能相关的上下文信息是在gLM的前六层学习的。研究团队还展示了单独的上下文信息可以预测蛋白质功能,准确度达到了24.4 ± 0.8%。相比之下,未进行掩蔽的情况下,gLM可以结合上下文中存在的信息和每个查询蛋白质的原始pLM信息。研究团队还观察到在更浅层的gLM嵌入的表现力增加,准确度在第一个隐藏层达到了51.6 ± 0.5%。这标志着与无上下文pLM预测准确度(图3A)相比增加了4.6 ± 0.5%,并且在平均精度均值(图3C)中增加了5.5 ± 1.0%。因此,研究团队展示了gLM从上下文中学到的信息与pLM嵌入捕获的信息是正交的。研究团队还观察到在gLM的更深层中酶功能信息的表现力递减;这与之前对大型语言模型(LLMs)的检查一致,其中更深层被专门用于预训练任务(掩蔽标记预测),并且与先前对LLMs的检查一致,其中最佳表现的层取决于特定的下游任务。最后,为了进一步检查这些表示的表现力,研究团队比较了每类F1分数的增益(图3B)。研究团队观察到在测试集中有超过十个样本的73个EC类别中的36个类别之间的两个模型的F1分数(t检验,双侧,Benjamini/Hochberg校正后的p值< 0.05,n = 5)存在统计学显著差异。大多数的统计差异导致在gLM表示上训练的LP中F1分数提高。
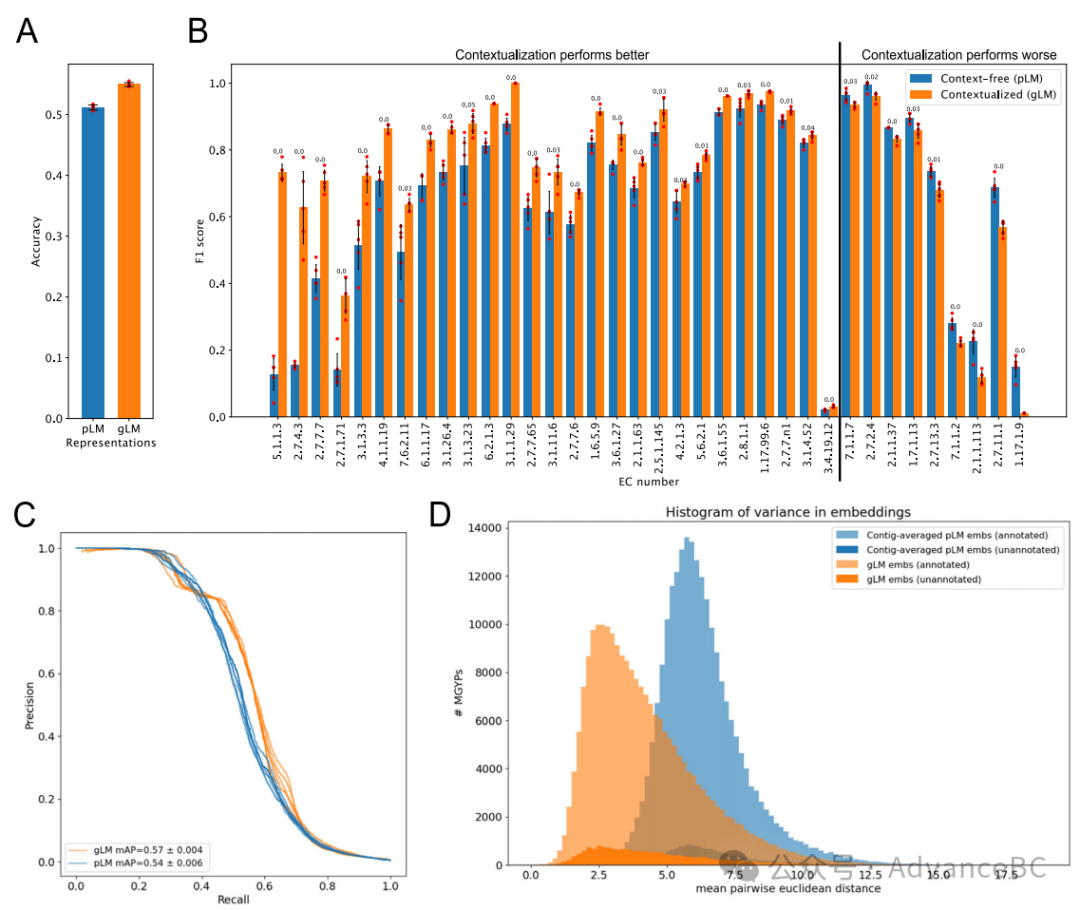
图3:基因功能的上下文化
水平转移频率对应于基因组上下文嵌入的变异
塑造微生物基因组组织和进化的一个关键过程是水平基因转移(HGT)。基因在生命之树上分布的分类范围取决于它们的功能以及它们在不同环境中带来的选择优势。关于基因跨系统发育距离转移到基因组区域的特异性,目前了解甚少。研究团队检查了在数据库中至少出现一百次的蛋白质的gLM嵌入的变异。通过随机抽取100次出现然后计算一百个gLM嵌入之间的平均成对距离来计算gLM学习到的基因组上下文的变异。研究团队对每个基因进行此类独立的随机抽样和距离计算十次,然后计算平均值。作为基线,研究团队使用相同的抽样方法计算亚拼接片段平均pLM嵌入的变异,以比较从训练gLM中学到的信息。研究团队的结果显示,gLM学习到的基因组上下文变异具有更长的右侧尾部(峰度=1.02,偏度=1.08)与更尖峰的拼接片段平均pLM基线(峰度=2.2,偏度=1.05)相比(图3D)。值得注意的是,在gLM学习到的上下文变异分布的右侧尾部(橙色)中,最具上下文变异性的基因包括噬菌体基因和转座酶,反映了它们自我移动的能力。有趣的是,尽管研究团队在拼接片段平均pLM嵌入变异分布的最右侧尾部找到了涉及转位的基因,但没有发现任何噬菌体基因。gLM学习到的基因组上下文变异可以作为水平转移频率的代理,可以用来比较基因组上下文对基因的进化轨迹(例如,基因流)的适应性效应,以及识别特性不明和功能性的可转座元件。
Transformer的注意力捕捉操纵子
Transformer的注意力机制模拟输入序列中不同标记之间的成对互动。先前对自然语言处理(NLP)中变换器模型的注意力模式的检查表明,不同的头部似乎专门用于句法功能。随后,在pLMs40中的不同注意力头被显示与蛋白质中的特定结构元素和功能位点相关联。对于gLM,研究团队假设特定的注意力头专注于学习操纵子,这是微生物基因组中突出的“句法”特征,其中多个相关功能的基因作为单个多基因转录本表达。操纵子在细菌、古菌及其病毒基因组中普遍存在,而在真核生物基因组中则罕见。研究团队使用由817个操纵子组成的大肠杆菌K-12操纵子数据库进行验证。gLM包含19层中的190个注意力头。研究团队发现较浅层的头与操纵子的相关性更强(图4A,第二层的第七个头[L2-H7]中的原始注意力得分与操纵子的线性相关性为0.44相关系数(皮尔逊的rho,Bonferroni调整后的p值< 1E-5)(图4B)。研究团队进一步使用所有头部的所有注意力模式训练了一个逻辑回归分类器(操纵子预测器)。他们的分类器以高精度预测序列中一对相邻蛋白质之间操纵子关系的存在(平均精度均值=0.775 ± 0.028,五折交叉验证)(图4C)。研究团队以在基于一位热氨基酸表示的gLM消融训练的操纵子预测器为基准来评估这一性能(平均精度均值=0.426 ± 0.015,五折交叉验证),它从方向和共现信息中学习,但不能完全利用基因的丰富表示。
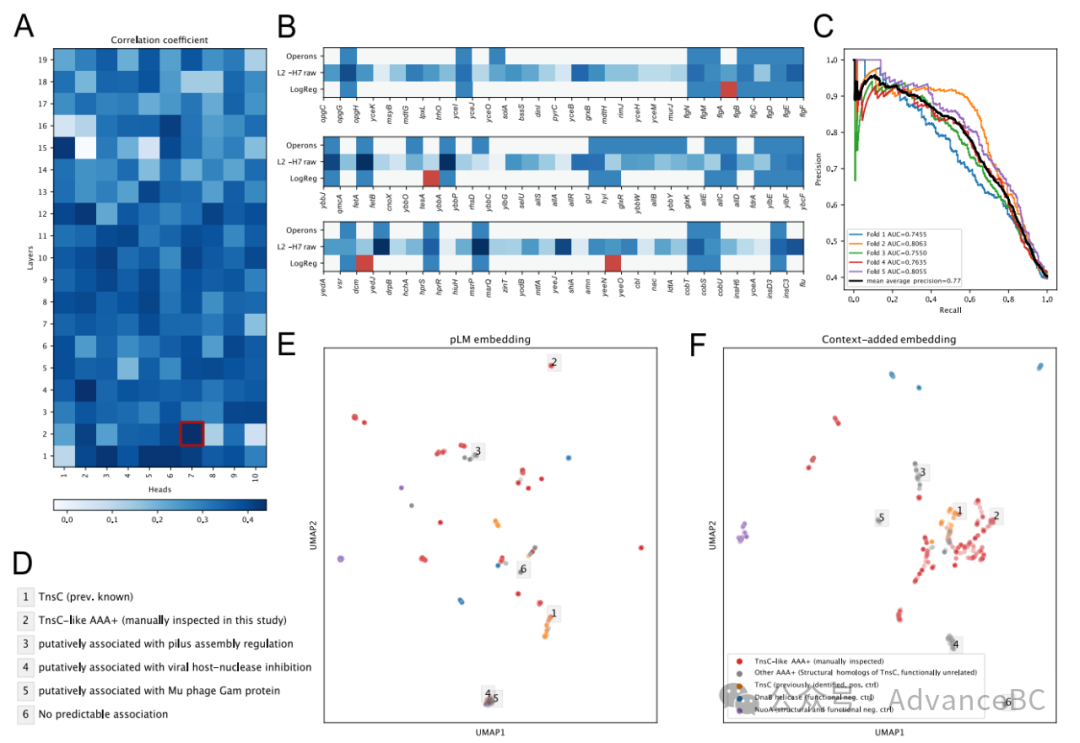
图4:注意力分析
AAA+调控因子在复杂遗传系统中的上下文依赖性功能
理解调控蛋白在生物体中的功能角色仍然是一个具有挑战性的任务,因为相同的蛋白折叠可能根据上下文执行不同的功能。例如,AAA+蛋白(与多种细胞活动相关的ATP酶)利用来自ATP水解的化学能来赋予多种机械细胞功能。然而,AAA+调控因子也可以根据它们的细胞相互作用伙伴从蛋白质降解和DNA复制到DNA转位扮演非常不同的、广泛的功能角色。一个特别有趣的例子是TnsC蛋白,它在Tn7类转座子系统中调节DNA插入活动。多项生物信息学努力专注于通过宏基因组搜索和组装基因组的序列搜索发现以前未表征的转座子,旨在为基因组编辑应用识别合适的同源物。为了测试这里开发的方法是否能识别Tn7类转位系统以及将这些与其他功能上下文区分开,研究团队探索了MGnify数据库中TnsC的结构同源物的上下文化语义。在没有上下文化的情况下,似乎没有与相关转座酶活动的聚类(KL发散比=1.03;见方法计算此指标,图4E)。然而,添加上下文化后,先前识别的TnsC(橙色)和手动检查的TnsC样结构同源物(红色,标记为“TnsC样”)聚集在一起(KL发散比=0.38;图4F)。研究团队进一步使用基于嵌入距离的聚类验证了这种可视化。许多TnsC的结构同源物并未参与转位,这反映在图4F中远离已知TnsC(橙色)和TnsC样结构同源物(红色)的灰色数据点的独特聚类中。这些聚类代表了多样化和上下文依赖的AAA+调节活动,这些活动不能仅凭结构或原始序列预测。研究团队预测了这些AAA+调控因子与它们邻近基因之间的操纵子关系,并发现许多与功能多样的基因模块处于操纵子关系中,包括菌毛组装和病毒宿主核酸酶抑制(图4D)。在某些情况下,查询的AAA+蛋白似乎并未与邻近蛋白形成操纵子关联,这表明一些AAA+蛋白与它们的邻居的功能关联可能不如其他蛋白那样可能。使用AAA+调控因子的这个例子,研究团队说明了结合上下文化的蛋白质嵌入和基于注意力的操纵子互动可能为探索和表征调控蛋白的功能多样性提供了一个重要途径。
gLM预测蛋白质-蛋白质相互作用中的旁系同源性
生物体内的蛋白质以复合体的形式存在,并且相互之间进行物理相互作用。最近在蛋白质-蛋白质相互作用(PPI)预测和结构复合体研究方面取得的进展主要是通过识别interologs(跨生物体保守的PPI)和残基间的共演化信号来指导的。然而,区分旁系同源物和正系同源物(又称为“旁系匹配”问题)在不断扩大的序列数据集中仍然是一个需要在整个数据库和/或系统遗传分析中进行查询的计算挑战。在一个生物体内发现多个相互作用对(例如组氨酸激酶(HK)和响应调节器(RR))的情况下,预测相互作用对尤其困难。他们推断,尽管gLM并没有直接针对这一任务进行训练,但可能已经学习到了旁系同源物与正系同源物之间的关系。为了测试这一能力,研究团队使用了一个研究良好的旁系同源物交互作用的例子(ModC和ModA,图5A),它们形成了一个ABC转运复合体。他们查询gLM预测相互作用对的嵌入,除了蛋白质序列外没有其他上下文。他们发现,即使没有任何微调,gLM的表现至少比随机机会好一个数量级。具体来说,对于2700对相互作用对中的398对,gLM作出了属于同一群组(50%序列同一性,n=2100群组)的预测作为真实标签,并且在73对中,gLM预测的标签最接近确切的相互作用对(模拟随机机会预期匹配=1.6±1.01,n=10)(图5B)。重要的是,在只考虑非常高信心的预测(预测可能性>0.9,n=466)时,gLM能够将旁系同源物匹配起来,准确率提高了25.1%。当旁系同源物正确配对时,gLM对预测更有信心(正确预测的平均信心=0.79,所有预测的平均信心=0.53),而不太确定的预测要么超出分布,要么更接近标签的平均值(图5C)。研究团队认为预测不准确的部分原因是gLM没有接受过只用单个基因作为基因组上下文来预测掩码基因的任务训练,尽管他们期望随着训练序列长度范围的扩大和专门针对“旁系匹配”问题的模型微调,性能将得到改善。
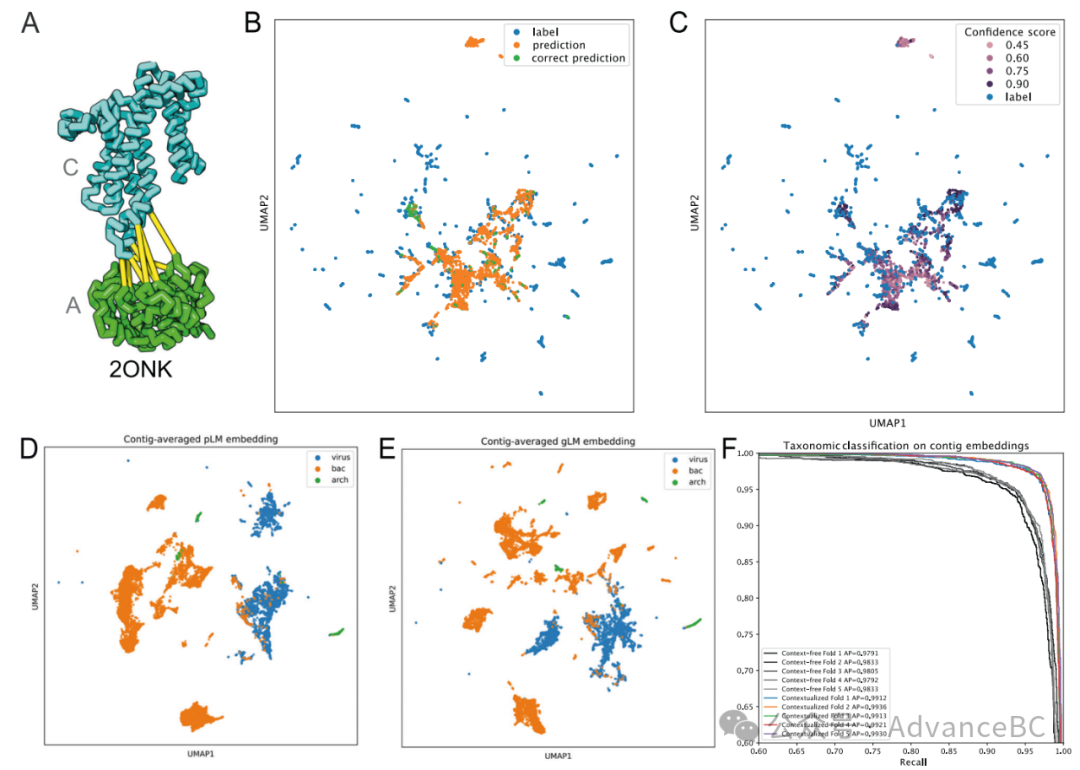
图5:迁移学习的潜力
上下文化的拼接片段嵌入和迁移学习的潜力
上下文化蛋白质嵌入编码了特定蛋白质与其基因组上下文之间的关系,保持了拼接片段内的顺序信息。研究团队假设,这种上下文化添加了生物学意义上有用的信息,可以用于多基因基因组拼接片段的进一步表征。在此,他们定义了一种上下文化拼接片段嵌入,作为平均汇总隐藏层的拼接片段中所有蛋白质的嵌入,以及一个无上下文的拼接片段嵌入,作为平均汇总ESM2蛋白质嵌入跨越整个序列。两种嵌入均包含1280个特征。他们通过检验这些嵌入能否线性区分细菌和古菌序列与病毒序列的能力来验证他们的假设。
在宏基因组数据集中,组装序列的分类必须事后推断,因此病毒序列的鉴定是基于病毒基因和病毒基因组特征的存在来进行的。然而,这样的分类任务尤其对于较小的拼接片段和较少表征的病毒序列来说仍然是一个挑战。在这里,研究团队从代表性的细菌和古菌基因组数据库以及NCBI中的参考病毒基因组随机采样了30个蛋白质拼接片段,并可视化了它们的无上下文拼接片段嵌入(图5D)和上下文化拼接片段嵌入(图5E)。他们在域和类别级别上观察到了更多的分离和分类聚集,这表明分类签名通过编码蛋白质间潜在的关系而得到增强。这进一步通过在无上下文和上下文化拼接片段嵌入上训练逻辑回归分类器来验证类别级别分类,其中他们看到了平均精确度的统计上显著提升(图5F)。这强调了蛋白质在基因组中的相对位置及其与基因组上下文的关系的生物学重要性,并进一步表明这些信息可以通过gLM有效编码。上下文化的拼接片段嵌入为转移学习提供了可能性,这种学习超出了简单的病毒序列预测,例如改进宏基因组装配的基因组(MAG)分箱和组装校正。
结论与前景
研究团队在这项研究中开发的基因组语言模型(gLM)标志着在理解基因与其基因组上下文之间复杂关系方面的一个重要进展。通过对大量宏基因组数据的深入分析和学习,gLM成功揭示了基因间的潜在功能和调控关系,提供了一种全新的方法来深入理解生物基因组的组织和功能。这一工作不仅增强了我们对于生物系统复杂性的理解,还为生物科学的未来研究方向和应用开拓了新的途径。
未来,随着计算能力的提升和算法的进一步优化,研究团队预计gLM及其改进版本将在基因功能注释、基因组结构解析以及生物系统工程等领域发挥更大的作用。gLM的发展将为解锁宏基因组数据中蕴含的丰富生物信息、加速生物学发现,并为生物技术创新提供强大的支持,开辟广阔的研究和应用前景。
思考与挑战
尽管gLM在捕捉基因组数据复杂性方面取得了显著成果,但研究团队也认识到在将这一模型推向更广泛应用的道路上仍面临诸多挑战。首先,模型的高计算需求可能限制了其在资源受限环境下的应用。因此,如何优化模型以降低其对计算资源的需求,是未来需要解决的关键问题之一。其次,提高模型的解释性,让研究人员能够更好地理解模型学习到的生物学知识,是推动gLM在生物学研究中应用的重要方向。
此外,尽管gLM已经展现出对未知基因功能预测的潜力,如何进一步提高其预测的准确性和泛化能力,特别是在数据稀疏或生物学多样性极高的情况下,也是未来研究的重点。最后,探索gLM在多种生物学问题上的应用,包括但不限于疾病机理研究、新药发现、生态系统分析等,将是研究团队未来工作的重要方向。
综上所述,gLM的开发为理解和应用基因组数据提供了新的工具和思路,研究团队对其未来的发展和应用充满期待。面对挑战,持续的技术创新和方法优化将是推动gLM及其相关技术前进的关键。
链接
引文:Hwang, Y., Cornman, A.L., Kellogg, E.H. et al. Genomic language model predicts protein co-regulation and function. Nat Commun 15, 2880 (2024).
原文链接:https://doi.org/10.1038/s41467-024-46947-9
代码链接:https://github.com/y-hwang/gLM (https://doi.org/10.5281/zenodo.10512240)
数据链接:http://ftp.ebi.ac.uk/pub/databases/metagenomics/peptide_database/2022_05/
启发
这篇文章通过开发和应用基因组语言模型(gLM)揭示基因与其基因组上下文之间的复杂关系,为我们提供了多方面的深刻启发,具有实际意义和深远影响:
深度学习在生物信息学中的应用潜力:文章展现了深度学习技术,特别是语言模型在解读生物数据复杂性方面的巨大潜力。这提示我们,未来可以进一步探索和开发深度学习模型,以解决生物信息学和基因组学中的其他复杂问题。
未知基因功能的预测与注释:gLM在揭示未知或功能不明基因潜在功能方面显示出的优异性能,为加速基因功能注释提供了新的思路。这种方法可以帮助生物学家更快地理解未知基因在生物系统中的作用,加速基础生物学研究和应用生物技术的发展。
基因组数据的深层次挖掘:通过学习基因在其基因组上下文中的表达和调控模式,gLM为我们打开了一个深入挖掘和理解基因组数据的新视角。这种深层次的数据挖掘方法可能揭示出新的生物学规律和机制,为疾病机理研究、新药发现等领域带来新的启示。
模型解释性与生物学知识的结合:尽管gLM展现了强大的学习和预测能力,如何提高模型的解释性,使其学习到的知识更容易被生物学家理解和验证,是未来研究的一个重要方向。这一挑战的解决将有助于更紧密地结合计算模型和实验生物学,促进生物学知识的发现和创新。
生物数据的综合利用:这篇文章还启发我们,通过综合利用不同类型的生物数据(如宏基因组数据、蛋白质序列数据等),并结合深度学习模型,可以大大提升我们理解和应用这些数据的能力。这种跨数据类型的综合分析方法,为未来生物学研究提供了新的方向和可能性。
综上所述,这篇文章不仅在技术层面上展现了创新,更重要的是,它为我们提供了一种新的思考生物数据和生物系统复杂性的方式,为未来的生物学研究和生物技术应用提供了新的启示和可能性。
高颜值免费 SCI 在线绘图(点击图片直达)
最全植物基因组数据库IMP (点击图片直达)
往期精品(点击图片直达文字对应教程)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|















































 2811
2811

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









