






文章题目:A pan-genome of 69 Arabidopsis thaliana accessions reveals a conserved genome structure throughout the global species range
杂志:Nature Genetics
影响因子:30.8
发表时间:2024.04
文章链接:https://www.nature.com/articles/s41588-024-01715-9

摘要
虽然最初主要是用于功能生物学,但由于其广泛的地理分布和对不同环境的适应,拟南芥已经成为了种群基因组学中一个强大的模型。在这里,呈现了来自全球物种范围的 69 个群体的染色体水平的基因组组装。发现即使在地理上和遗传上距离很远的群体中,基因组的同源性都是非常保守的。沿着染色体臂,Mb级别的重排很少见,通常只存在于单个群体中。这表明染色体核型是准固定的,染色体臂上的重排受到了反选择。着丝粒区域显示出更高的结构动态性,并且核心着丝粒区域的差异占据了大部分基因组大小的变异。泛基因组分析揭示了 32,986 个不同的基因家族,其中 60% 在所有群体中都存在,而 40% 看起来是可以省略的,其中包括 18% 是特定于单个群体的,表明了未被探索的基因多样性。这 69 个新的拟南芥基因组组装将为未来的遗传研究提供支持。
01
72 个拟南芥种质的基因组关系
通过对来自全球不同地理起源的 72 个拟南芥种质进行SNP分析,确定了四个主要遗传群体:“欧洲”、“非洲”、“马德拉”和“亚洲”,以及三个“混合”种质。进化关系分析显示非洲种群可能是最古老和最不同化的谱系,与先前研究结果一致。
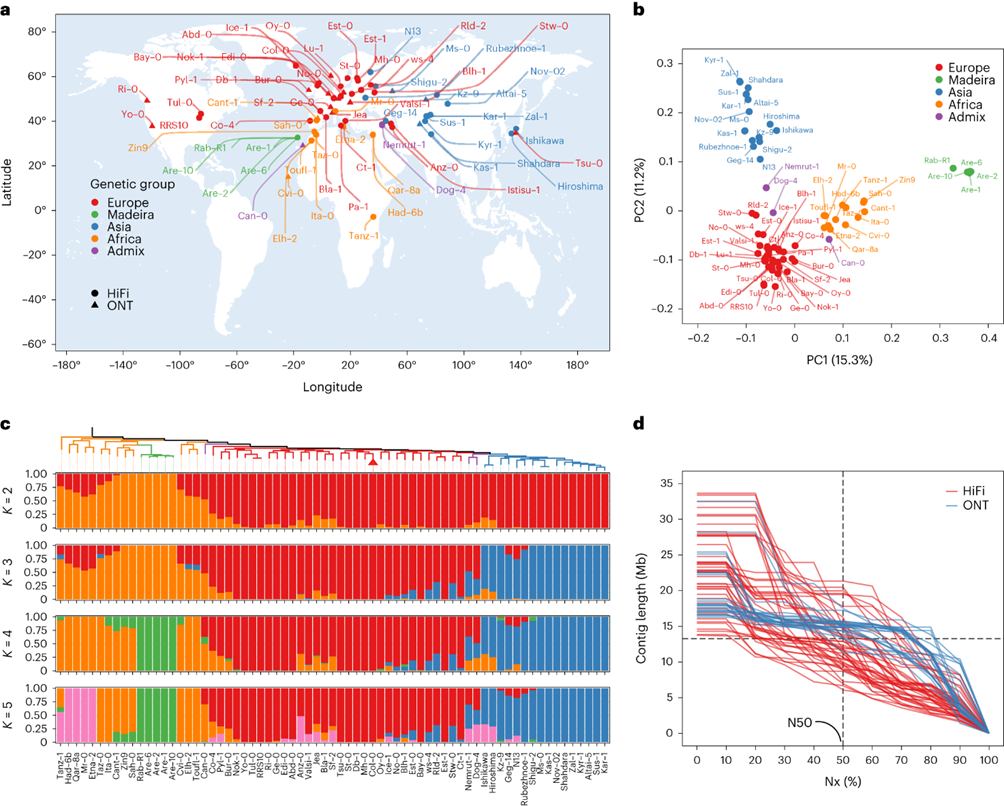
图1:72个拟南芥种质品种的地理分布和种群分析。
02
69 个拟南芥种质的染色体水平组装
使用了长读取(PacBio HiFi,平均深度为 45×,和牛津纳米孔,平均深度为 67×)和短读取测序,结合参考导向的拼接和手动修正,为 72 个种质生成了基因组组装。69 个种质经确认为纯合子品系,但 Lu-1、Pa-1 和 Istisu-1 显示出杂合性的迹象,因此在后续分析中被删除。剩余的 contig 组装具有 N50 值从 6.1 到 21.3 Mb,平均为 13.3 Mb,并且已组装到染色体水平。
69 个种质的组装大小范围从 128 Mb 到 148 Mb,平均长度为 135 Mb。以往使用流式细胞术估计的拟南芥基因组大小范围较高,但存在高估问题。最近对 89 个种质进行的短读取重新测序数据 k-mer 分析显示基因组大小范围为 138 Mb 到 175 Mb。也用 k-mers 估计了 69 个种质的基因组大小,并将其与组装大小进行了比较。一些基于 ONT 读取的组装明显较短,因为它们的 rDNA 数组和着丝粒没有完全组装。
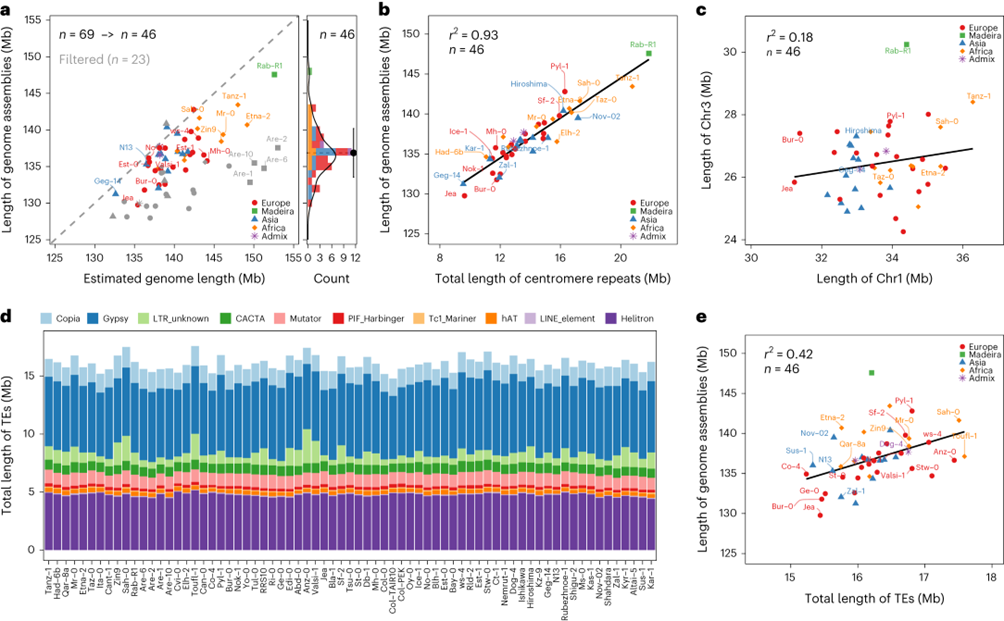
图2:69个拟南芥种质品种的组装和注释。
为了解释基因组大小变异的潜在基因组特征,选择了最完整的 46 个组装,并分析了组装与基因组大小估计的比值以及着丝粒重复长度与着丝粒大小估计的比值。这些种质的组装大小范围从 130 到 148 Mb。着丝粒重复序列平均长度为 14 Mb,与组装大小高度相关。通过从个体组装的初始 TE 注释生成的 pan-TE 库注释了转座元件。TE 空间大小在基因组之间非常相似,长末端重复序列和 Helitrons 占据了最大的 TE 分数。拟南芥基因组大小变异主要由着丝粒重复长度主导,而 TE 只是次要贡献者。单个染色体的大小独立于彼此地演化。
03
拟南芥的准固定核型在整个品种范围内保持稳定
染色体水平的基因组组装可以准确分析大规模基因组重排和基因组共线性。经过成对的全基因组比对,发现染色体臂保持了高度的同源性,即使比较来自世界不同地区的基因组。大型插入/删除多态性较少,主要小于20 kb,最大的约为55 kb。染色体臂上的倒位也相对较少,但是有一些较大的倒位,其中几个超过一百万碱基对。总共鉴定到七个倒位,几乎全部存在于单个种质中。染色体4上的1.2 Mb倒位在多个种质中广泛存在,包括Col-0,暗示了这种倒位的长期分离。
拟南芥的核型与十字花科估计的祖先核型相当不同,涉及了三个功能性着丝粒的物种特异性缺失以及主要的染色体重排和融合。69个基因组之间的高结构相似性意味着拟南芥的派生核型在物种分化期间或分化后不久形成,并且在该物种在全球范围内扩展过程中几乎没有改变。
与染色体臂相比,大型重排在着丝粒附近非常丰富,导致大量不同的着丝粒单倍型。
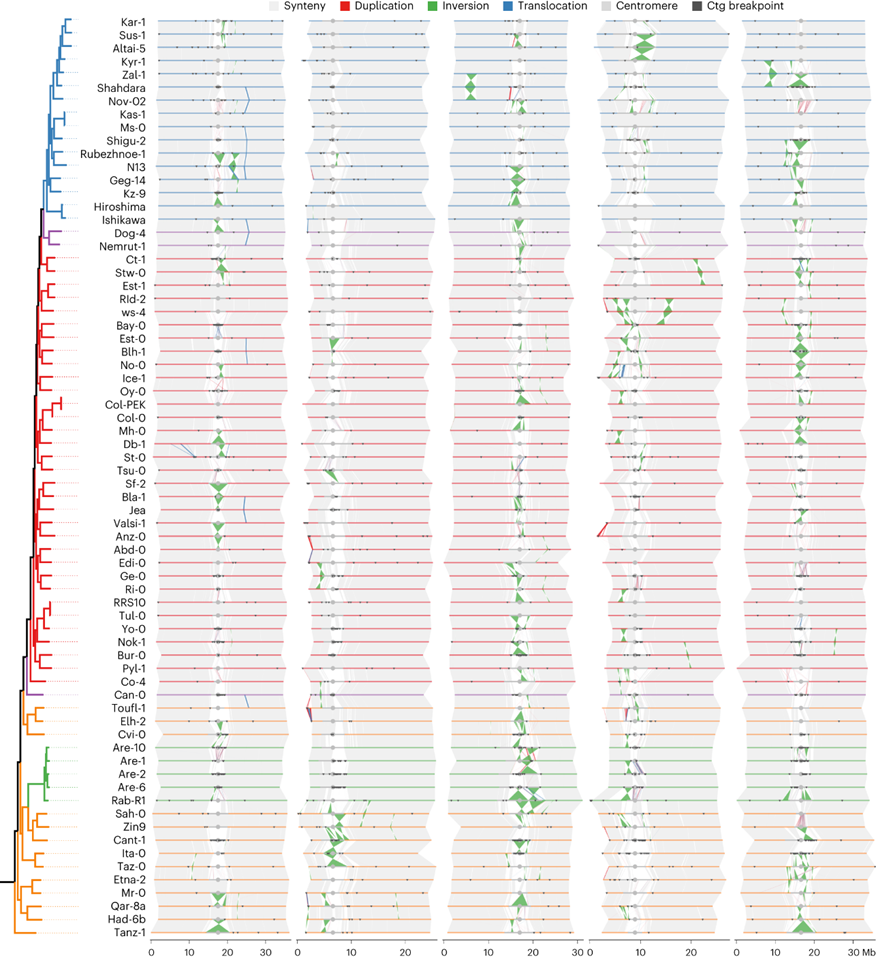
图3:69个拟南芥种质品种的全基因组比对。
为了更高分辨率地量化同源性,沿着染色体测量了滑动窗口中的同源性,并计算了每个新组装的基因组与Col-0最近的基因组组装之间的同源性的平均配对多样性。约50%的基因组高度同源,其同源性的平均配对多样性低于0.2,主要集中在染色体臂上。约33%的基因组同源性的平均配对多样性超过0.5,主要在靠近着丝粒的区域。染色体臂上的广泛同源性显示了一些异常,如染色体2和4的短臂显示高水平的重排,染色体4上的约1.2 Mb倒位标志着同源性的高多样性。此外,局部高度结构多样性的尖峰富集了R基因簇。
基因组范围的成对同源性关系反映了遗传和地理群体,少数群体之间的接近对应于地理群集。非洲群集之间的同源性低于欧洲或亚洲群集,可能反映了非洲的基因组多样性更高。
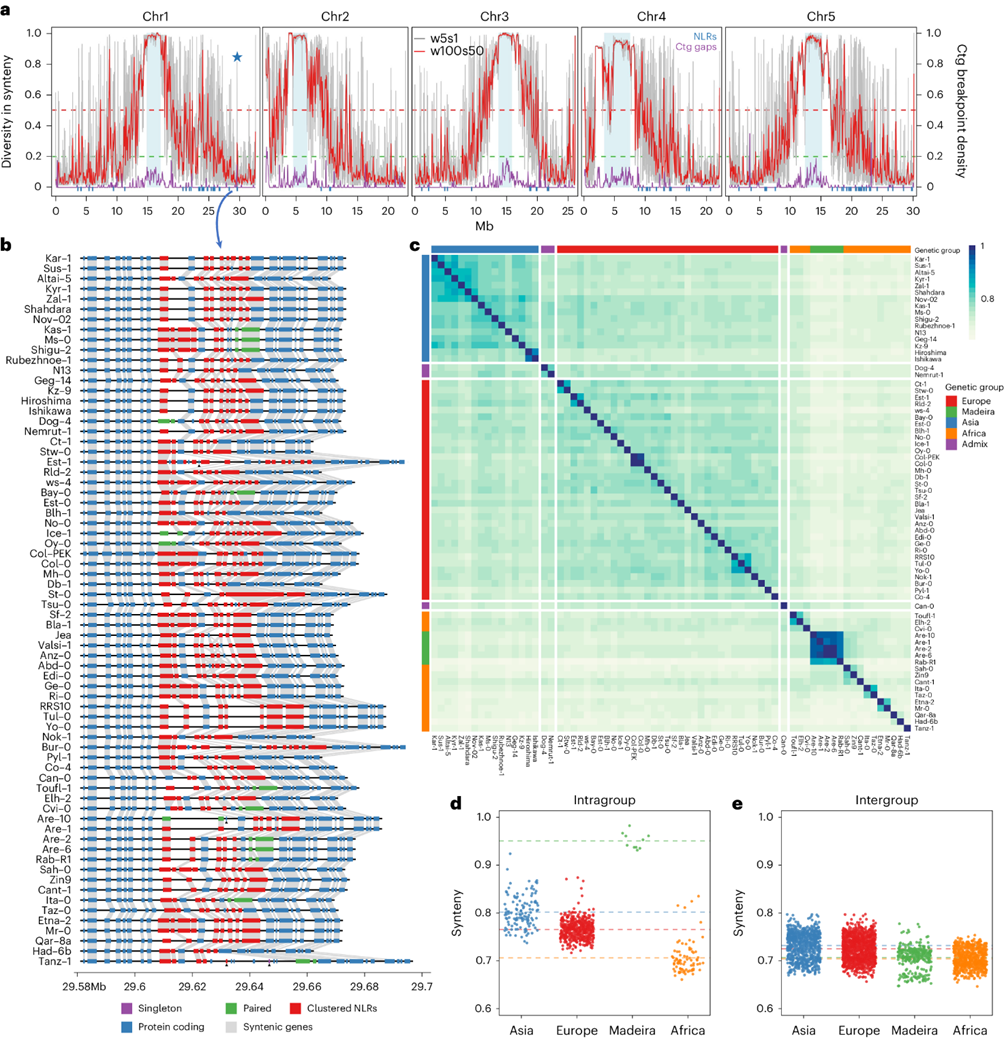
图4:69个拟南芥种质品种的同源景观特征。
04
拟南芥泛基因组
对拟南芥(A. thaliana)的泛基因组进行了分析,发现了大量的基因家族。这些基因家族在73个基因组中识别出了36,991个,其中包括核心、软核心、可选和私有基因家族。核心基因家族占大多数,其中有60%存在于所有69个基因组中,而软核心和可选基因家族则存在于不同程度的基因组中。私有基因家族数量较多,约占总数的18%,表明潜在的遗传多样性尚未完全发现。核心基因家族的编码蛋白序列长度更长,更频繁地匹配Pfam域,且在基因表达和功能约束方面与其他类型的基因有显著差异。辅助基因家族则富集于细胞杀伤和防御反应等生物过程。尽管种质集包含大量基因家族,但泛基因集尚未达到饱和状态,可能存在未发掘的遗传多样性。
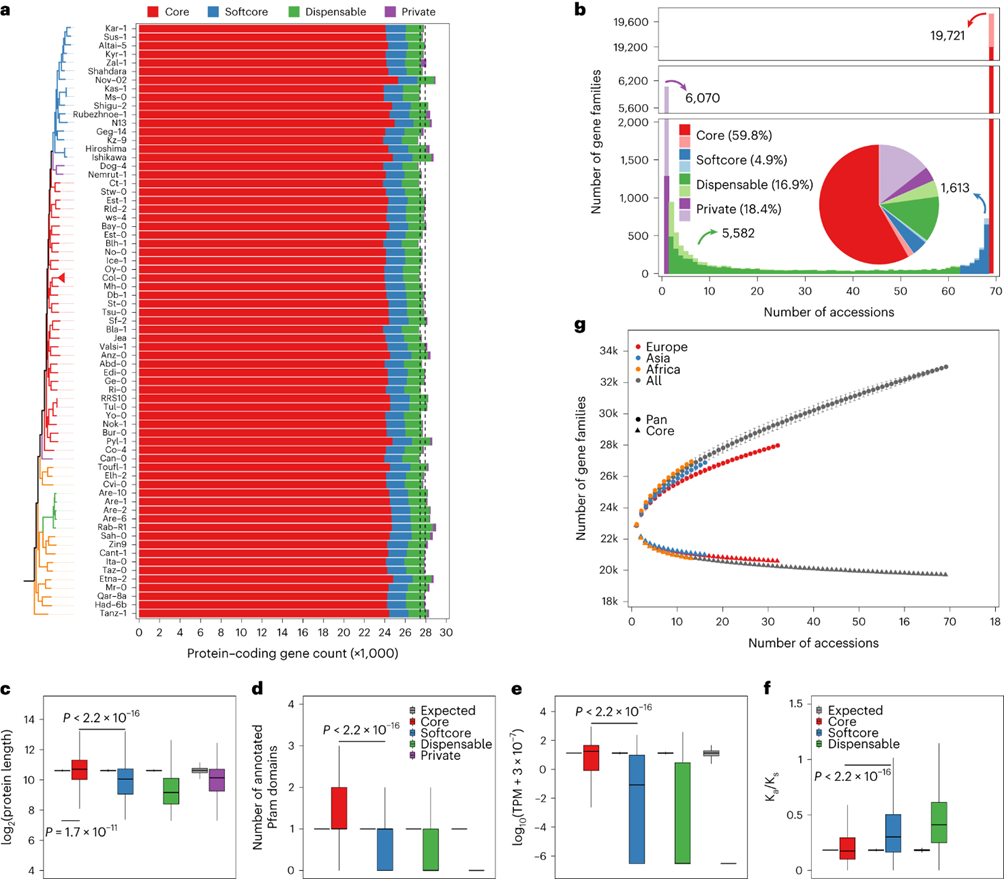
图5:69个拟南芥种质品种的泛基因组分析。
讨论
在这项研究中,生成了69个参考质量的拟南芥基因组组装,涵盖了拟南芥中大量的遗传多样性。这些组装是从来自非洲中部到冰岛,从北美到日本的不同地点选择的种质品种中生成的,但尽管这些巨大的地理距离,植物的基因组结构在植物之间高度保守。这些组装还揭示了总共10,420个新的蛋白质编码基因簇,这些基因簇在参考基因组(Col-0和Araport11)中不存在,为研究迄今未描述的变异的遗传基础提供了非常强大的资源。此外,基因组组装集合包含了一些强大且公开可用的材料的亲本品系,如重组近交系。基因组组装将有助于揭示依赖于复杂结构变异的重要性状的遗传基础。最后,这些69个基因组,与其他基因组一起,为研究基因组动态的机制,包括重组,提供了很好的资源。这些资源为进一步的功能基因组研究铺平了道路。
高颜值免费 SCI 在线绘图(点击图片直达)
最全植物基因组数据库IMP (点击图片直达)
往期精品(点击图片直达文字对应教程)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
















































 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









