






Abstract
摘 要
近日,扬州大学农学院张韬教授课题组在Molecular Plant在线发表了题为PDLLMs: A group of tailored DNA large language models for analyzing plant genomes的研究论文,开发了一系列基于植物基因组的基础DNA大语言模型,该研究构建的130M大小的plant DNAMamba模型仅以十分之一的参数量就打败了由InstaDeep、Google DeepMind顶尖机构联合开发的同类模型AgroNT。模型的开发填补了植物基因组研究中缺乏适宜本地化运行的基础DNA大语言模型的空白。

https://doi.org/10.1016/j.molp.2024.12.006
研究背景
Background
大语言模型(Large language models,LLMs)是一类利用大规模数据进行预训练的语言模型,在过去的几年间,LLMs已在生成式人工智能领域得到了广泛的应用,如ChatGPT、Stable Diffusion等。传统大语言模型最初被设计用于处理人类语言,近年来也逐渐被应用于DNA和氨基酸序列的分析中,它可以在复杂的生物大数据中学习到特定的模式或相关性,从而实现对基因组任务的预测。近年来,许多代表性的基础DNA大语言模型被开发出来,包括HyenaDNA (Nguyen et al., 2024)、DNABERT-2 (Zhou et al., 2023)和Nucleotide Transformer(NT)(Dalla-Torre et al., 2024)等,这些模型在组蛋白修饰,启动子,增强子,剪切位点等任务上都展现出了良好的预测能力。然而这些模型主要基于人类基因组或其他非植物的基因组进行构建,因此在植物基因组分析中存在限制。最近InstaDeep、Google DeepMind团队共同开发了一个植物的基础DNA大语言模型AgroNT (Mendoza-Revilla et al., 2024),在多个基因组任务中均表现优异,然而该模型较大,不适用于个人和缺乏计算资源的实验室。鉴于此,扬州大学张韬团队构建了一套专为植物基因组量身定制的DNA大型语言模型——Plant DNA Large Language Models (PDLLMs),能够在单张消费级显卡上实现高效的训练和推理。
研究内容
Contents
在该研究中,作者首先基于14个代表性的植物参考基因组,结合5种先进的基础架构设计,包括BERT, NT, GPT, Gemma和Mamba,构建了一系列大小在100M左右且适用于植物的基础DNA大语言模型。之后作者构建了一套植物基因组预测数据集,包含核心启动子、序列保守性、多种组蛋白修饰、lncRNAs、开放染色质和启动子活性的预测任务。将先前构建的不同DNA大语言模型应用到这些预测任务中,并与3个代表性DNA大语言模型(DNABERT-2、NTv2和AgroNT)进行比较,结果表明该研究构建的大语言模型整体上优于其他非植物的DNA大语言模型。除此之外,基于Mamba的植物DNA大语言模型几乎在所有预测任务中均强于比其参数量多10倍的植物基础模型AgroNT。说明基于新架构的DNA模型在效率和性能上都更有优势,并且能够更好地被个人用户使用。
考虑到不同分词方式(tokenizer)对模型性能的影响,作者也比较了不同分词方式的plant DNAMamba模型在预测不同基因组任务时的效果。结果发现基于K-mer的分词方法和基于BPE分词方法的模型在不同任务上的表现存在差异,这些差异很有可能来自于预测序列的长度,序列组成以及任务类型等。作者总结了单碱基分词,1-mer至6-mer分词以及BPE分词下模型在不同任务上的预测效果,供用户参考以选择最合适的分词方法。
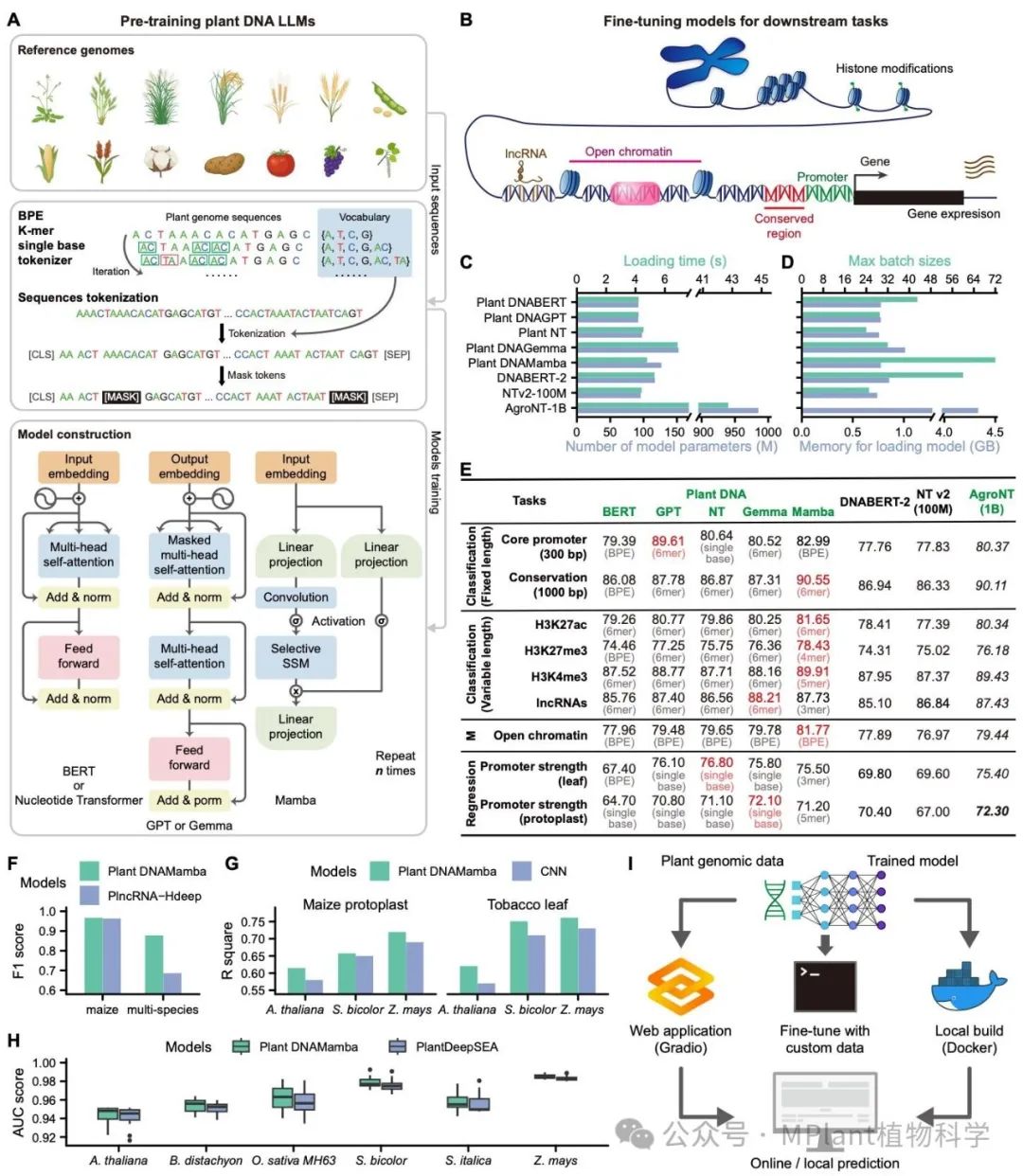
图1. 植物基础DNA大语言模型的构建和比较
该研究进一步比较了DNA大语言模型和非大语言模型在植物基因组预测任务中的性能。结果发现不论是在lncRNAs任务,启动子强度任务还是开放染色质预测任务上,plant DNAMamba模型表现都优于基于CNN或者LSTM架构的专用深度学习模型。该结果反映出了DNA大语言模型的高效和普适性,仅需要单个基础模型就可以实现多种基因组任务的预测和分析。
最后,作者基于所有构建的模型,开发了一个用户友好的在线预测平台,支持多种核心基因组任务的预测,同时提供了最优模型的推荐,方便湿试验人员快速进行序列分析。预测平台的访问地址为:
https://finetune.plantllm.org或https://bioinfor.yzu.edu.cn/llms/finetune。
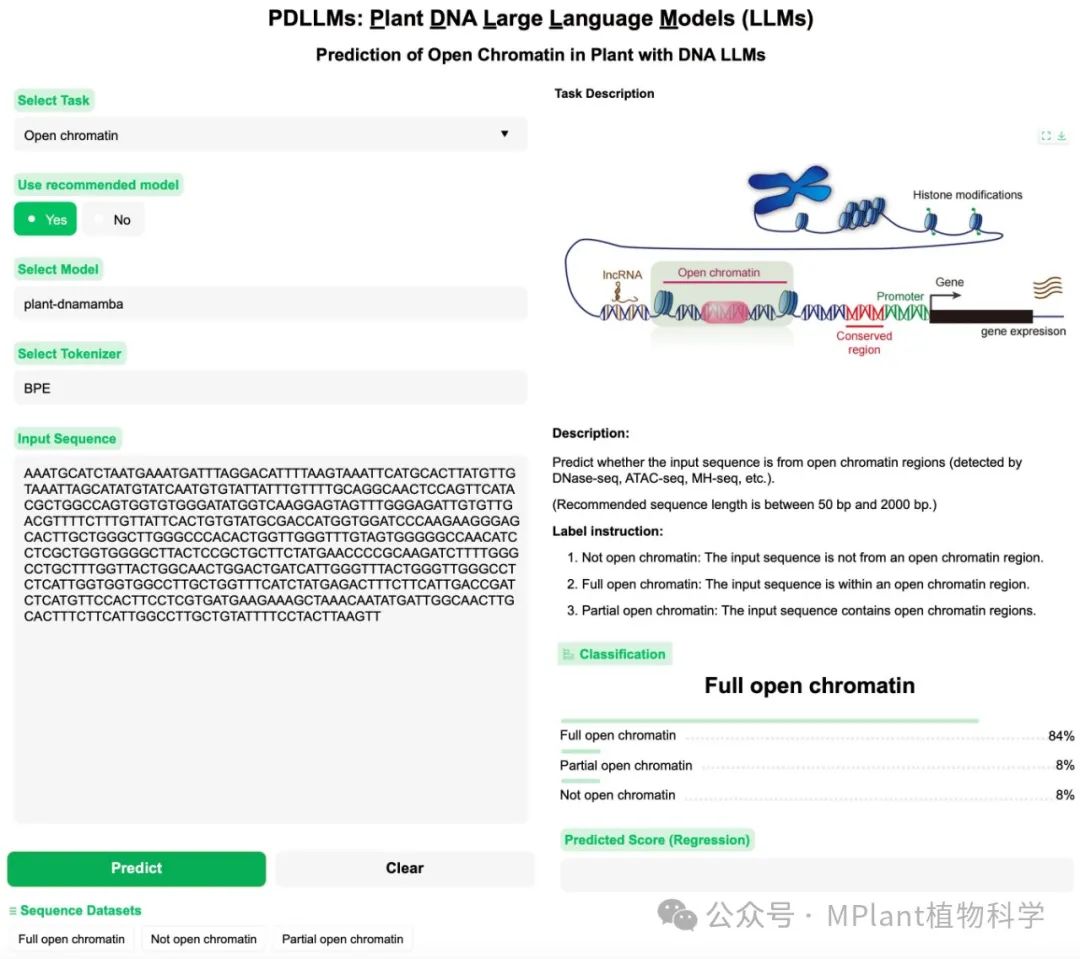
图2. PDLLMs在线预测平台
综上,该研究构建了一系列植物基础DNA大语言模型,能够在单块消费级显卡上进行训练和推理,为个人或缺乏计算资源的实验室提供了选择。此外研究展现了植物基础DNA大语言模型在基因组预测中的强大能力,构建的DNA大语言模型和植物基因组预测数据,为后续更高性能的DNA大语言模型的开发提供了参考。可以预见DNA大语言模型的完善将为解析复杂的生命现象、推动作物改良事业作出不可替代的贡献。
为了方便开发者使用相关模型,作者同时将模型的微调和推理代码上传到了GitHub (https://github.com/zhangtaolab/Plant_DNA_LLMs)和Gitee (https://gitee.com/zhangtaolabyzu/Plant_DNA_LLMs)上。同时已开放“植物大语言模型交流QQ群”(756369317),方便用户交流和讨论模型训练和推理时存在的问题。
扬州大学农学院张韬教授为该论文的通讯作者,扬州大学博士生刘冠卿为该论文的第一作者。该研究得到了国家自然科学基金、江苏省重点研发计划(现代农业)、钟山生物育种实验室课题、江苏省高校优势学科建设工程项目的资助。
参考文献:
Dalla-Torre, H., Gonzalez, L., Mendoza-Revilla, J., Lopez Carranza, N., Grzywaczewski, A.H., Oteri, F., Dallago, C., Trop, E., de Almeida, B.P., Sirelkhatim, H., et al. (2024). Nucleotide Transformer: building and evaluating robust foundation models for human genomics. Nat Methods 10.1038/s41592-024-02523-z.
Mendoza-Revilla, J., Trop, E., Gonzalez, L., Roller, M., Dalla-Torre, H., de Almeida, B.P., Richard, G., Caton, J., Lopez Carranza, N., Skwark, M., et al. (2024). A foundational large language model for edible plant genomes. Commun Biol 7:835. 10.1038/s42003-024-06465-2.
Nguyen, E., Poli, M., Faizi, M., Thomas, A.W., Sykes, C.B., Wornow, M., Patel, A., Rabideau, C., Massaroli, S., Bengio, Y., et al. (2024). HyenaDNA: long-range genomic sequence modeling at single nucleotide resolution. Proceedings of the 37th International Conference on Neural Information Processing Systems. Curran Associates Inc.
Zhou, Z., Ji, Y., Li, W., Dutta, P., Davuluri, R., and Liu, H. (2023). DNABERT-2: Efficient Foundation Model and Benchmark For Multi-Species Genome. arXiv 10.48550/arXiv.2306.15006.
来源:MPlant植物科学
高颜值免费 SCI 在线绘图(点击图片直达)
最全植物基因组数据库IMP (点击图片直达)

往期精品(点击图片直达文字对应教程)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
















































 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









