






概要
论文:https://arxiv.org/pdf/2311.15010.pdf
代码:https://github.com/Leiyi-Hu/mona.git
此解析为本人逐字阅读理解后总结,才疏学浅,难免疏漏。
按照沐神读文章三步法:1.标题、摘要和结论;2.重要图表;3逐步精读后思考。
标题、摘要、结论
通过标题、摘要、结论,初步了解文章的研究领域、初步结论,是否有必要进一步研究。
标题:如同《Attention Is All You Need》,重点表达adapter可以很好应用于视觉任务微调。
摘要:
- 视觉预训练模型的微调能够增强视觉任务的迁移性能。目前的微调方法更多是针对分类任务,在密集型任务上,微调方法与全量微调仍有较大差距。为了取代全量微调,我们提出了Mona(multi-cognitive visual adapter,多维感知视觉适配器)。
- 在adapter内加入多个视觉滤波器,使其更好处理视觉任务,之前的adapter设计主要基于NLP,更多是线性结构。
- 在adapter中加入scaled normalization layer,调整视觉滤波器输入特征的分布。
- 秀结果,Mona在COCO实例分割、ADE20K语义分割、VOC目标检测、图像分类做了对比实验,Mona的结果均超过了全量微调。特别是实例分割与语义分割,Mona是唯一超过全量微调的方法,在COCO上Mona比全量微调性能+1%AP。
结论:
- 文章提出了一种新的视觉微调方法Mona,在实例分割、语义分割、目标检测、图像分类上,均超过传统的全量微调与其余微调方法。
- 在大模型时代,全量微调不再是最优选择,Mona微调能有效提高大模型的迁移性能,在更多任务上代来性能突破。
引言
分析现状,总结问题,引出研究课题与主要贡献。
现状:
- 大模型时代,预训练模型的微调很重要,而全量微调在CV任务应用更加广泛。因此,全量微调是视觉任务最好的微调方式吗?
- 受NLP启发,Delta Finetuning(同Parameter efficient Finetuning,PEFT)在CV上也开始研究,例如修改网络的部分参数,或者新增轻量化结构。之前的工作在分类任务上已经取得比全量微调更好的结果,如VPT、LoRand,然而现有方法在密集型任务上,仍然无法超越全量微调。
问题:
分析了最近的视觉adapter工作,总结了两个问题:
- 现有视觉adapter的设计主要是linear adapter。我们实验表明,基于卷积的adapter有更好的迁移效果。
- 现有adapter通过简单的非线性压缩上游特征到单一的维度。
研究:
- 综上,我们提出了Mona。Mona是基于多个卷积滤波器的adapter。使用基于ImageNet-22k的Swin作为预训练模型,实验表明,Mona在图像分类和密集型预测任务上,均优于传统的全量微调方式。
- 总结Mona的贡献:
- 基于adapter的微调可以取代全量微调,在视觉任务上有更好性能更少参数。
- Mona使用视觉滤波器取代传统linear adapter,提高视觉迁移能力。
- 在分类、检测、分割等视觉任务上,Mona均超越全量微调。
相关工作
个人认为,视觉大模型的微调工作可参考最新的综述《Parameter-Efficient Fine-Tuning for Pre-Trained Vision Models: A Survey》。大致分为:新增额外参数的、修改网络部分参数的、二者合一的。本文微调方法是Adapter Tuning,属于新增额外结构的。具体不在此赘述。
另外,之前的所有微调方法均不能完全取代全量微调,因此提出了Mona。

本文方法
具体分4部分进行阐述,从adapter tuning的基本概念、Mona的设计思路、Mona的设计过程(这点挺好,让读者明白研究过程)、参数计算(需要理解整个模块设计)。
- adapter-tuning
如图所示,以Swin-Block作为示例。左边是全量微调,更新预训练主干的所有参数,右边是adapter微调,只更新adapter的参数。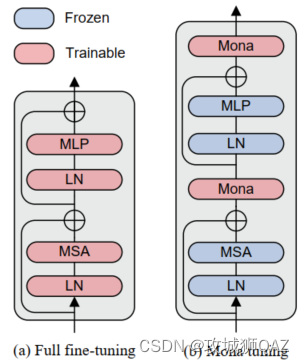
在数据集D上,上式是全量微调,下式是adapter微调。θ是模型的所有参数。θF是微调主干的部分参数,w是adapter参数。
上式表明,全量微调是微调模型所有参数θ,使其在新的任务D上损失最小。
下式表明,高效微调是仅微调部分参数θF,或者仅微调新增模块参数w,使其在新的任务D上损失最小。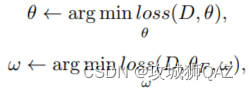
- Mona
基于adapter方法主要考虑:adapter的结构,adapter的位置,adapter的嵌入方式。
这里回顾几篇adapter的相关工作,与原文无关,仅本人从研究思路上进行分析。
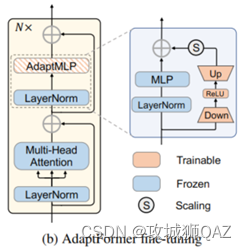
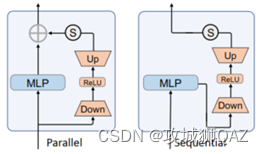
(1)NeurIPS22的AdapterFormer。第一,从结果看出,基于ViT的AdapterFormer性能无法超越全量微调。第二,adpter结构是传统的降维-->非线性映射-->升维。第三,adapter的位置与MLP并行,有意义的是,这里分析了并行性能更优的原因:a.并行结构不破坏原特征,使用独立分支合并新增的上下文信息。b.串行结构等同于在原有网络添加更多层,增加了优化难度。
(2)IJCV23的SCT。重点关注adapter结构与SCTM模块的嵌入位置。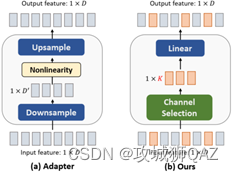
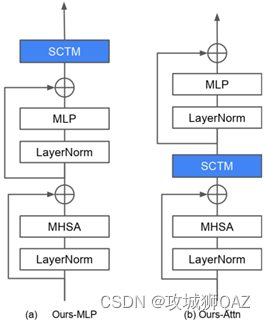
综上,之前的视觉adapter方法都是基于线性结构。而适用于NLP的线性adapter对视觉而言不是最优的。从视觉感知出发,多尺度处理会得到更好效果。因此,在adapter中加入多尺度的滤波器去增加感知维度。为了减少新增参数量,使用DWConv,分别使用卷积核3、5、7,求平均再通过1x1卷积核融合特征。非线性激活使用GELU。为了减少卷积导致的特征损失,在多处使用跳跃连接。
另外,文章认为对输入到adapter的特征也需要调整。输入优化:输入的特征来自不同的层级,需要调整特征的分布。通过设置s1和s2去实验LN的不同位置,LN是LayerNorm,实际测试比BatchNorm好,能够稳定前向和反向梯度传播。下图对比不同归一化方法的差异。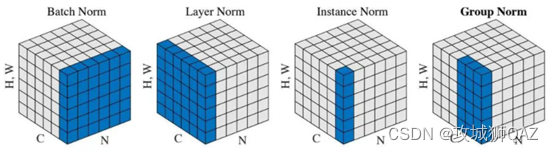
LayerNorm针对每个样本的完整特征去归一化。
而BatchNorm是对所有样本的某一维度特征进行归一化。
- 设计过程
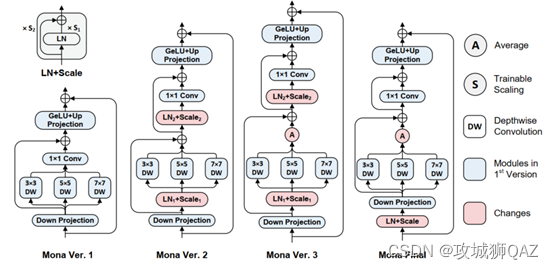
(1)初步版本就是加入了多尺度卷积滤波器增强视觉信号,这个设计在大多数任务上已经超过了很多其他adapter方法和全量微调。
(2)为了在所有任务上均达到最优,之前的工作表明LN能有效调整输入特征的分布,因此尝试把LN加在不同位置。然而,并不能获得期望的提升。
(3)在DWConv后面添加平均操作,能稍微提升第二版本性能,仍比第一版本差。
(4)最终版本,所有任务均超越全量微调。 - 参数分析
此节分析Mona有多少参数。(1)Mona的参数来自LN、缩放因子、全连接层、DWConv和PWConv。此处,Mona的输入维度为m,输出维度为n。
(2)LayerNorm层参数与输入维度m有关,包含参数均值、方差,共2m参数。
LayerNorm做了缩放叠加,包含参数s1和s2,共2个参数。因此,LN层是2m+2参数。
(3)DownProjection和UpProjection层由全连接层实现,其中DownProjection包含参数mn+m,UpProjection包含参数nm+n,共2mn+m+n。
(4)经过DownProjection后,维度降为n。
(5)深度可分离卷积由DWConv和PWConv组成。
(6)DWConv层参数与卷积核、输入维度有关,为卷积核w×卷积核h×输入维度,这里等于(32+52+72)×n=83n。
(7)PWConv层为1×1卷积核,参数与输入维度,输出维度有关,参数等于1×1×输入维度×输出维度,=1×1×nn=nn
(8)综上,Mona参数量为(2n+3)m+n2+84n+2
(9)由于文章使用Swin模型,Swin-block包括w-MSA和sw-MSA两个计算模块。因此总的参数为2((2n+3)m+n2+84n+2)
实验部分
具体分4部分进行阐述,从数据集、预训练模型、对比方法、结果4方面进行讨论。
1.数据集
在目标检测、语义分割、实例分割、图像分类上进行实验。
(1)目标检测:Pascal VOC 0712有16k/5k 训练/验证图像。使用Swin-L+RetinaNet训练,评价指标使用APbox。
(2)语义分割:ADE20K有20k/2k训练/验证图像。使用Swin-L+UperNet训练。评价指标使用mIOU。
(3)实例分割:COCO有118k/5k训练/验证图像。使用Swin-B+Cascade Mask RCNN训练。评价指标使用APbox和APmask。
(4)图像分类:Oxford 102 Flower有102类别,每类有40~258图像。Oxford-IIIT Pet有37类别,每类有200图像。VOC 2007有10k图像,20类别。评价指标使用top-1和top-5准确率。
2.预训练模型
使用Swin Transformer系列作为主干网络。
在ImageNet-22k上预训练,由openMMLab提供。预训练分辨率为224x224。在Nvidia Tesla V100s上进行实验。除COCO任务使用Swin-B外,其余使用Swin-L。
3.对比基线
无额外结构的方法:
FULL, FIXED, BITFIT, NORMTUNING, PARTIAL-1
有额外结构的方法:
ADAPTER, LORA, ADAPTERFORMER, LORAND
4.结果
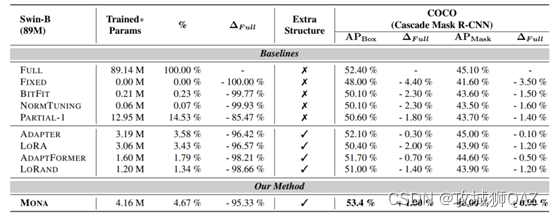
(1)实例分割是最有挑战的任务,而COCO是最大的实验数据集。因此,在COCO的结果可以更好的表明adapter微调在视觉任务上优于其余方法。
- 在COCO数据集上,Mona是唯一一个超过全量微调的方法,因此全量微调并不是视觉迁移学习的最有方法。
- 有额外结构的微调方法均优于无额外结构的微调方法,但是无额外结构的方法可以节省参数。
- Adapter方法均优于lora,因为lora更适用于NLP,不适用于视觉任务。
- 微调而言,更多的参数不一定有更好的结果。如partial-1参数量最大,但是比adapter方法结果差。因此,更好的模块设计能有效提升预训练模型的迁移性能,同时降低内存消耗。
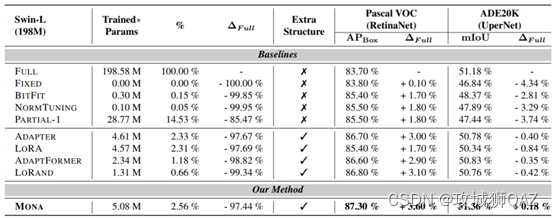
(2)目标检测和语义分割任务分析。 - 在VOC和ADE20K数据集上,Mona超过全量微调3.6%和0.18%,因此全量微调并不是视觉迁移学习的最有方法。
- 在VOC数据集上,所有微调方法均超过全量微调。因为VOC是小数据集,会导致198M的Swin-L过拟合。不同于全量微调,微调小部分参数不太可能导致训练严重奔溃。NLP学者也反应了同样的情况。
- 大多数微调方法的新增参数均低于5%,这是微调方法的优势。
-
(3)图像分类分析。 - 在Flowers102, OxfordPets和平均结果上,Mona均领先。
- 在数据集平均结果上,所有微调方法均超过全量微调。因为在ImageNet-22k上预训练的Swin-L,强大的知识使得Flowers102, OxfordPets有很高的分数。因此,更复杂的密集型预测任务,更适合用于比较不同的微调方法。
-

总结:全量微调并不是最优的微调方法,Mona在所有视觉任务上均超越全量微调。甚至在COCO实例分割上超过全量微调1%AP。
消融实验
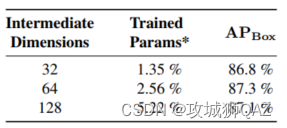
消融实验讨论adapter的中间维度,Mona微调的模型大小,所有消融实验在VOC数据集进行。
(1)中间维度:64维度最优,实验结论与AdapterFormer一致。实验表明,adapter中间维度的增加并不会带来性能的成比例提升。
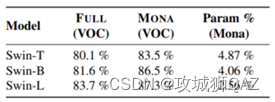
(2)Mona在不同模型大小时的性能对比。将Mona应用于Swin-T,Swin-B和Swin-L。
- 更大的骨干网,Mona参数的比例降低,因此PEFT在大模型时代,可以节省更多的内存。
- Mona在3个模型尺寸上均超过全量微调。因此,Mona微调可以帮助资源受限的研究者进行大模型的应用研究。
- 随着模型增大,Mona会带来更好的性能提升。
-

















 829
829

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









